Logs
20 minutesPersona
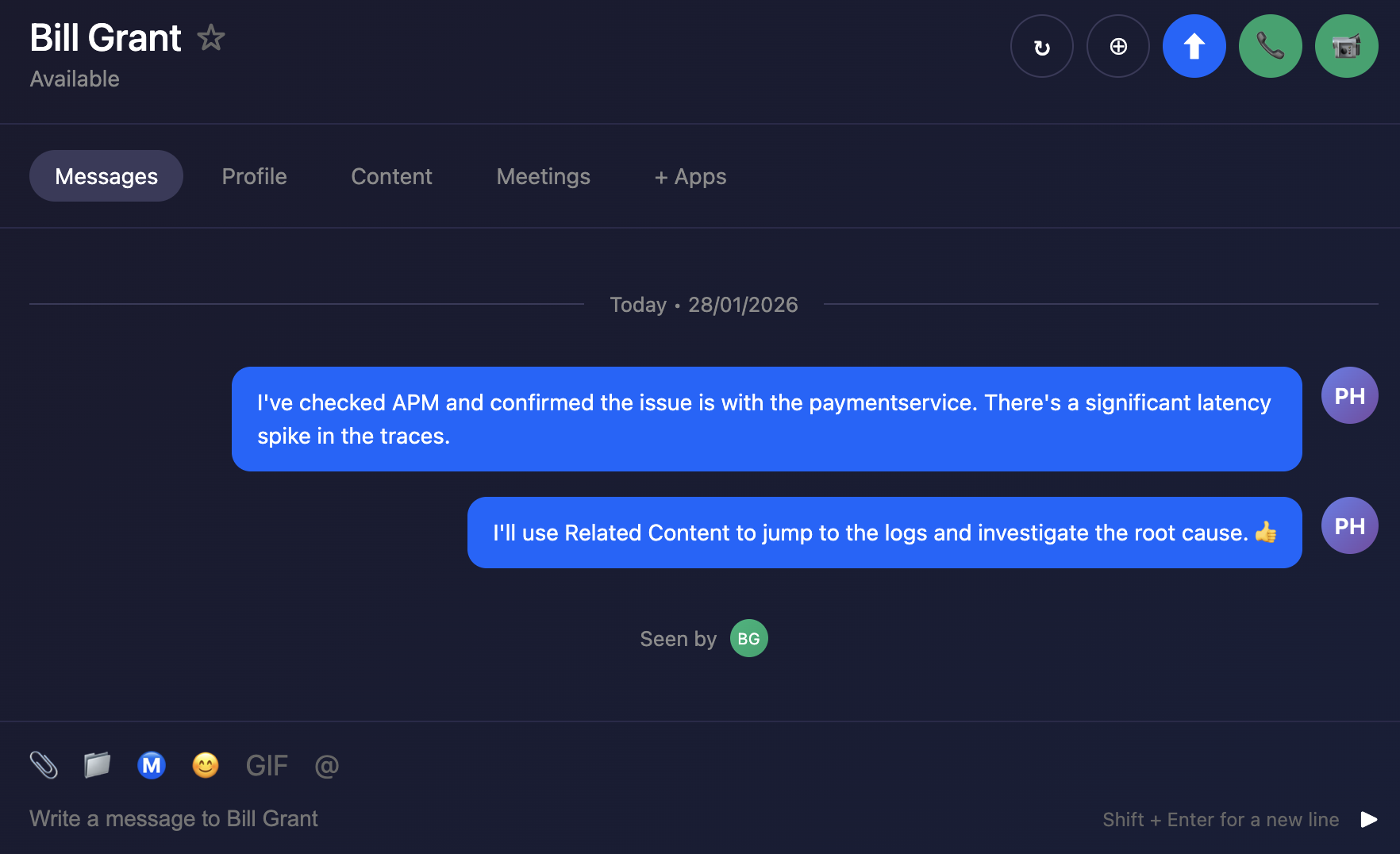
Remaining in your back-end developer role, you need to inspect the logs from your application to determine the root cause of the issue.
Using the content related to the APM trace (logs) we will now use Logs to drill down further to understand exactly what the problem is. Related Content is a powerful feature that allows you to jump from one component to another and is available for metrics, traces and logs.