Observability Cloud (Shortened 1h)
60 minutes Authors Robert Castley & Pieter HagenIntroduction
Gain hands-on experience troubleshooting issues using Splunk Observability Cloud. You’ll work with a fully instrumented microservices application on Kubernetes that sends metrics, traces, and logs for real-time analysis.
Workshop Overview
In this 1-hour hands-on session, you’ll cover:
- Generate Real User Data - Browse the Online Boutique website to generate metrics, traces, and logs
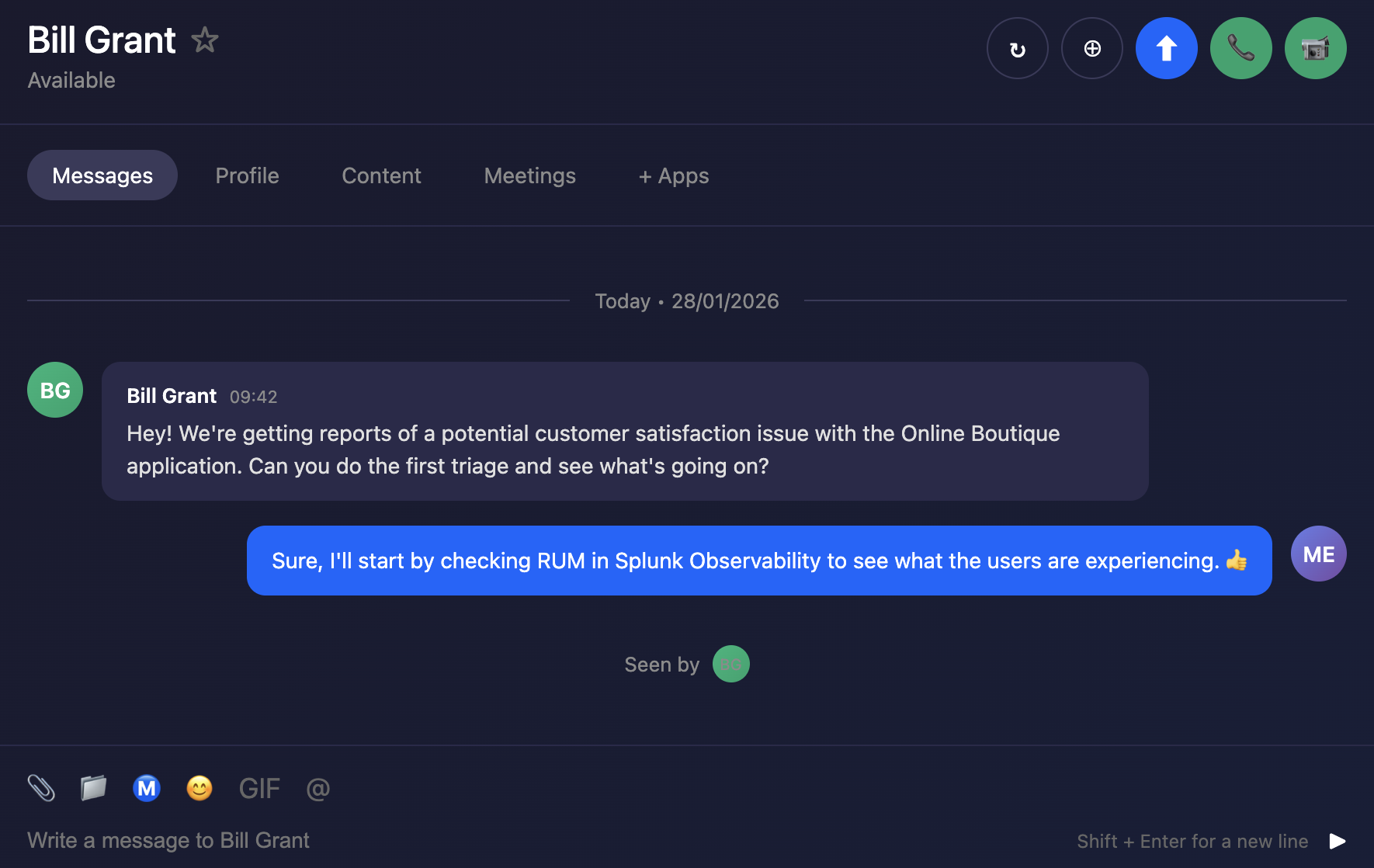
- RUM - Identify poorly performing browser sessions and begin troubleshooting
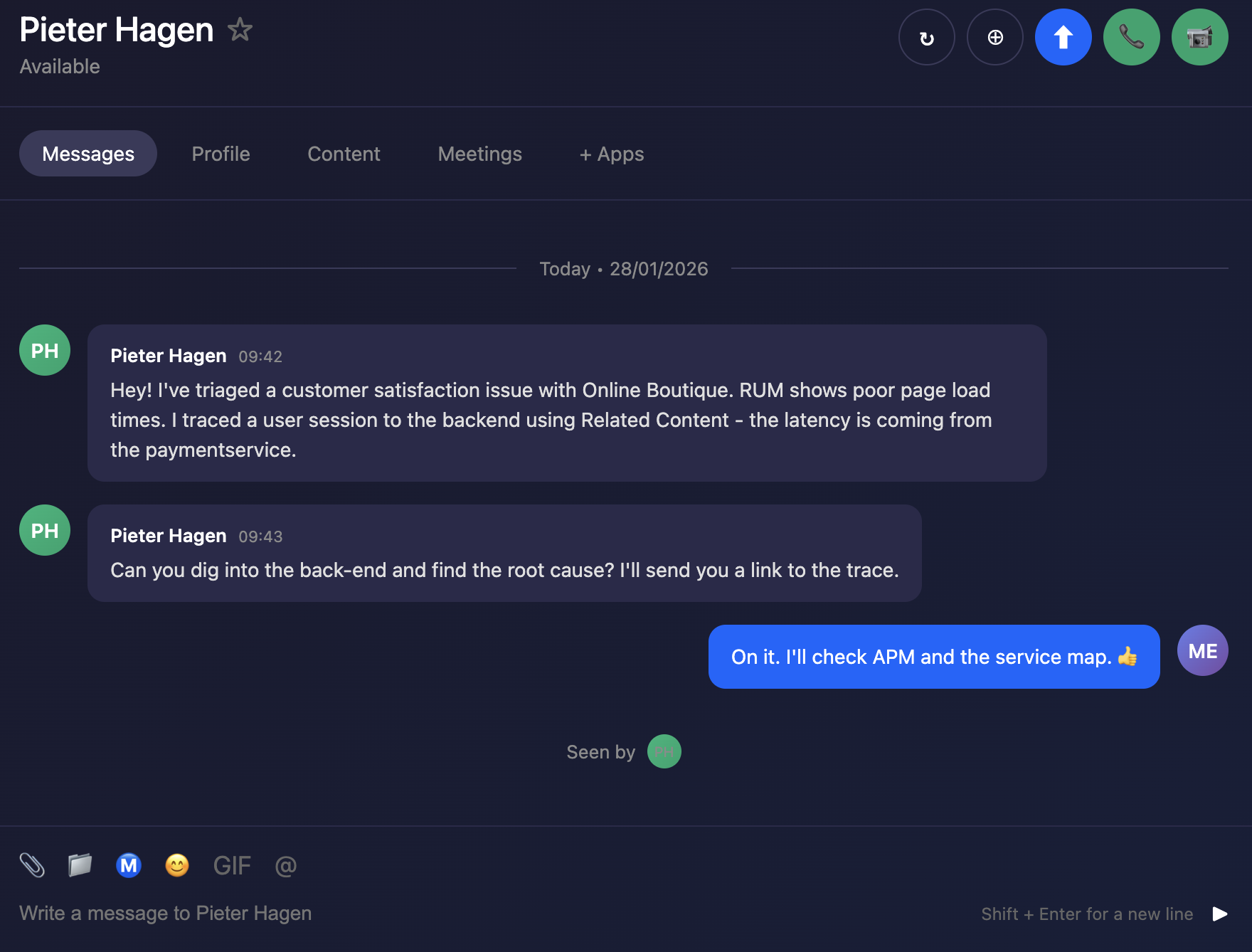
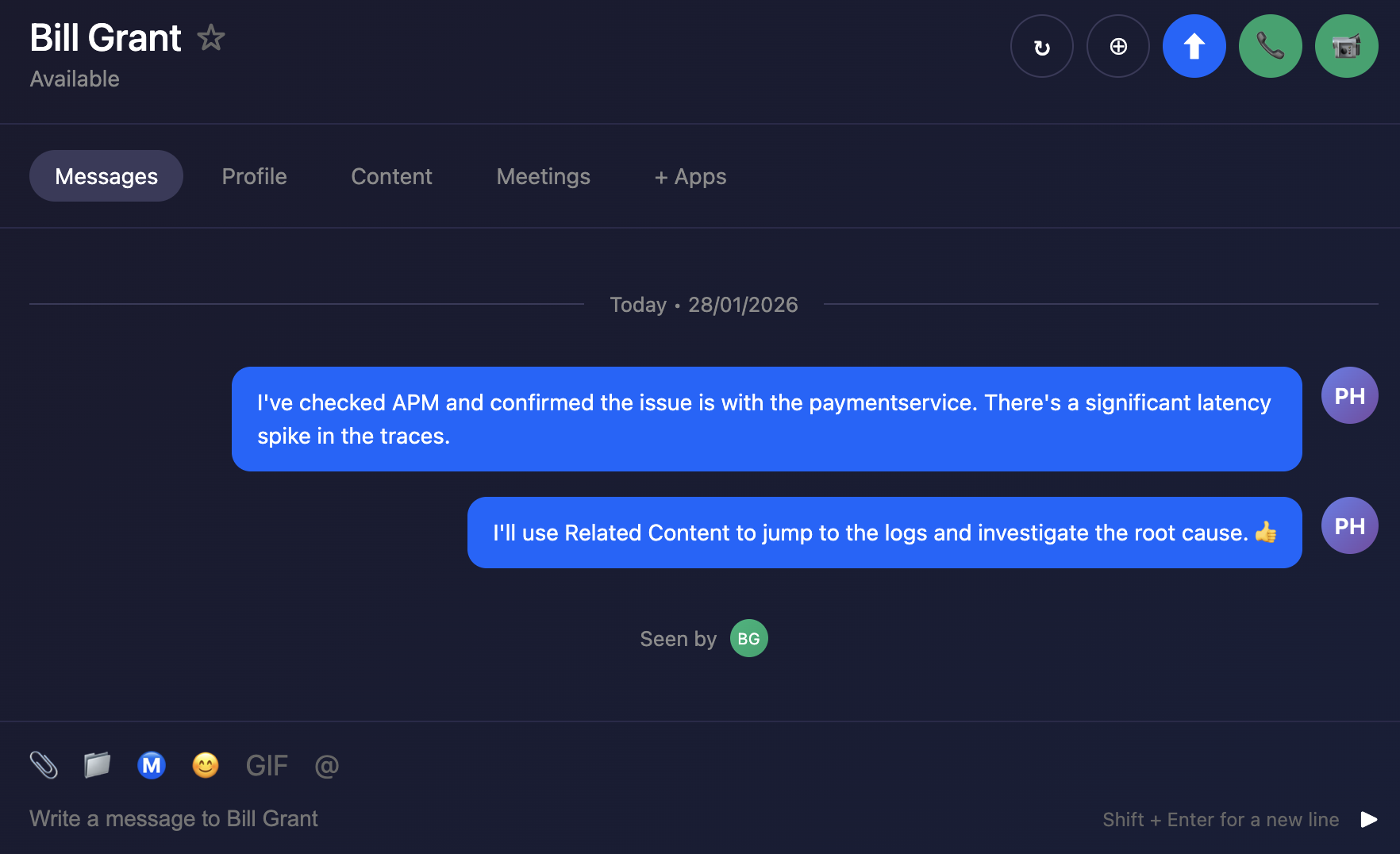
- APM - Link front-end RUM traces to back-end APM traces to detect anomalies and errors
- Log Observer - Use “Related Content” to navigate from APM traces to related logs
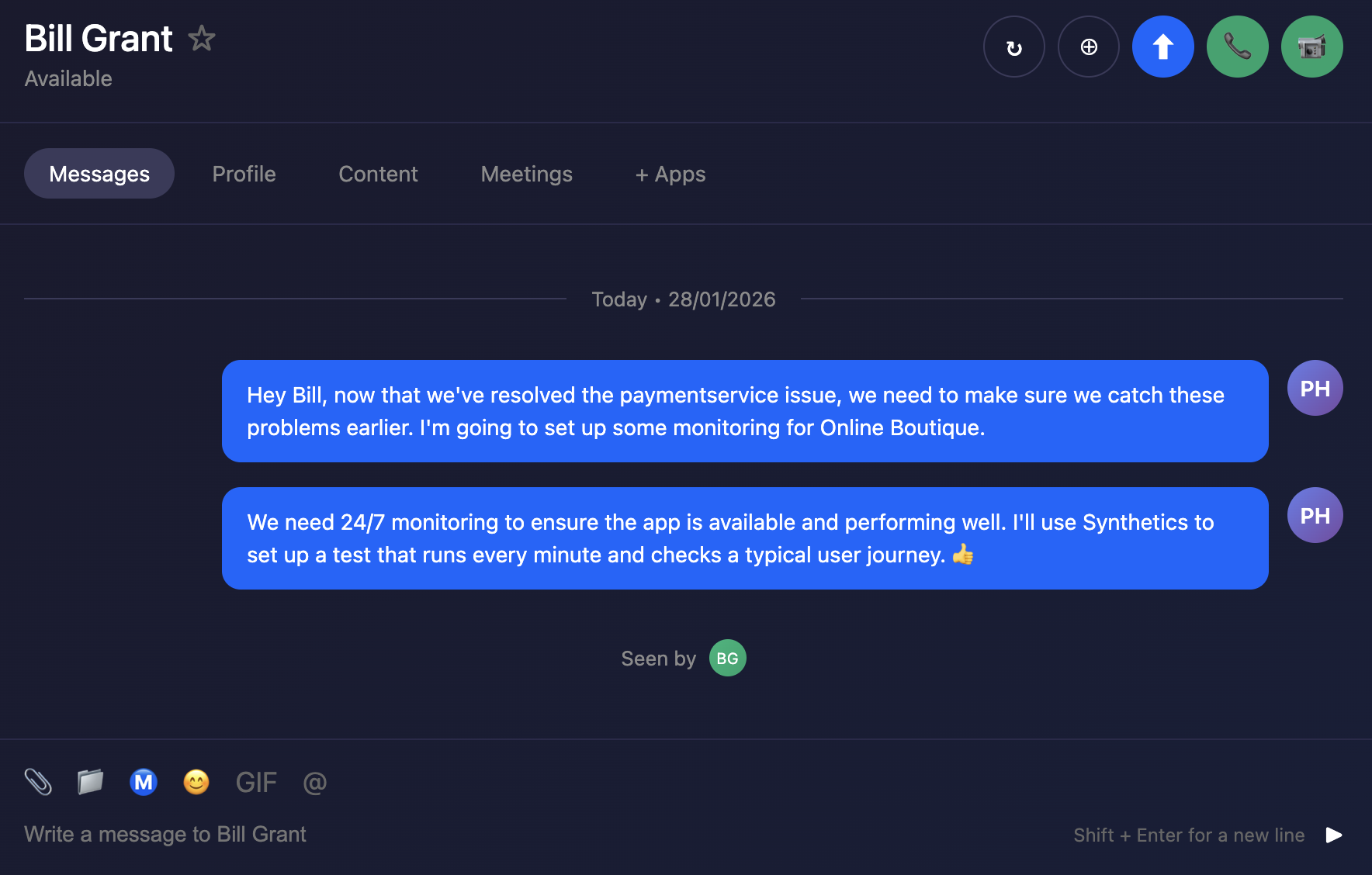
- Synthetics - Set up 24/7 monitoring with synthetic tests running every minute

Let’s go shopping!