まとめ
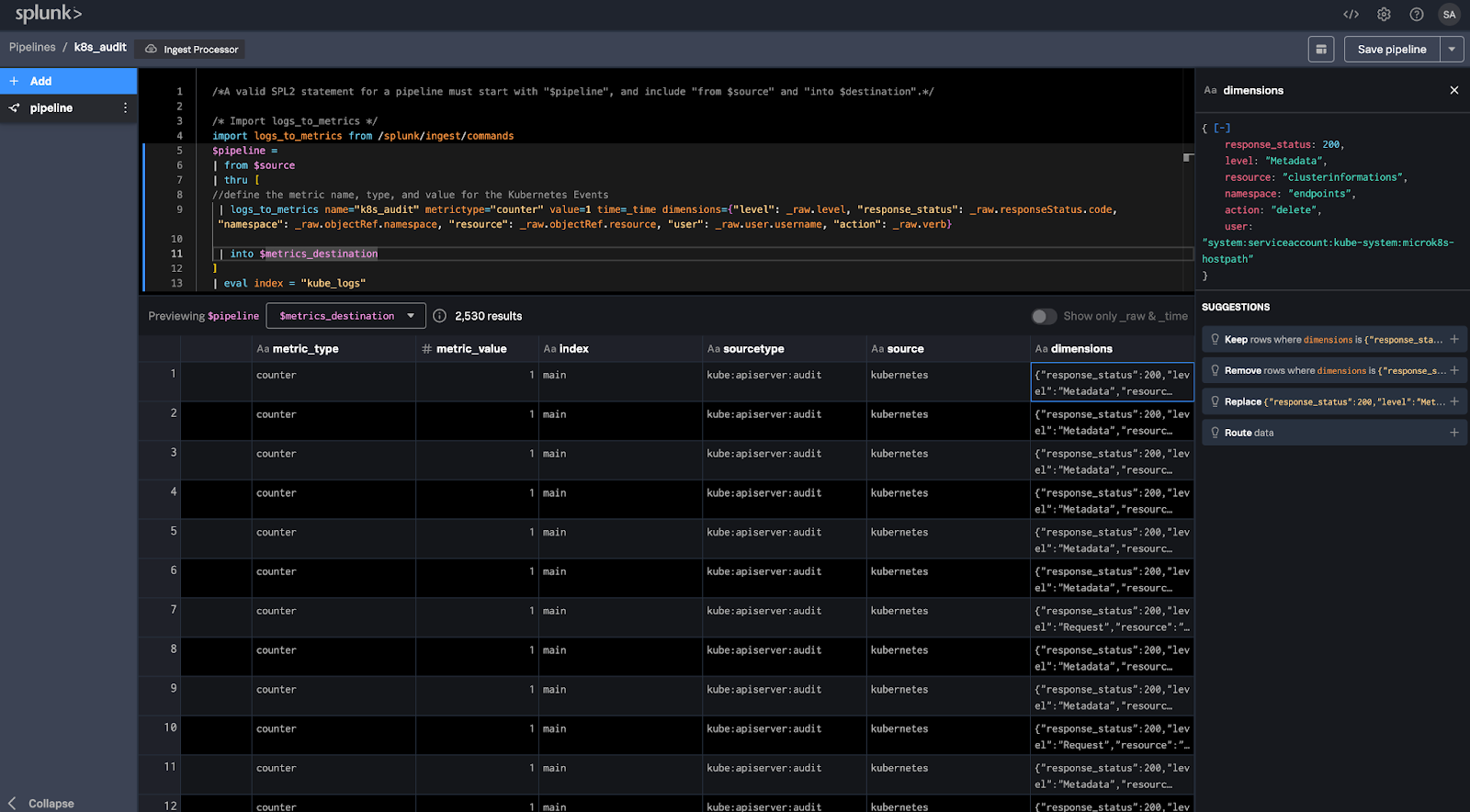
このワークショップでは、Splunk Ingest Pipelines を使用して詳細なログイベントを実用的なメトリクスに変換することで、Kubernetesログ管理を最適化するプロセス全体を体験しました。まず、Kubernetes Auditログをメトリクスに効率的に変換するパイプラインを定義し、重要な情報を保持しながらデータ量を大幅に削減しました。次に、生のログイベントが長期保持とより深い分析のためにS3に安全に保存されることを確認しました。
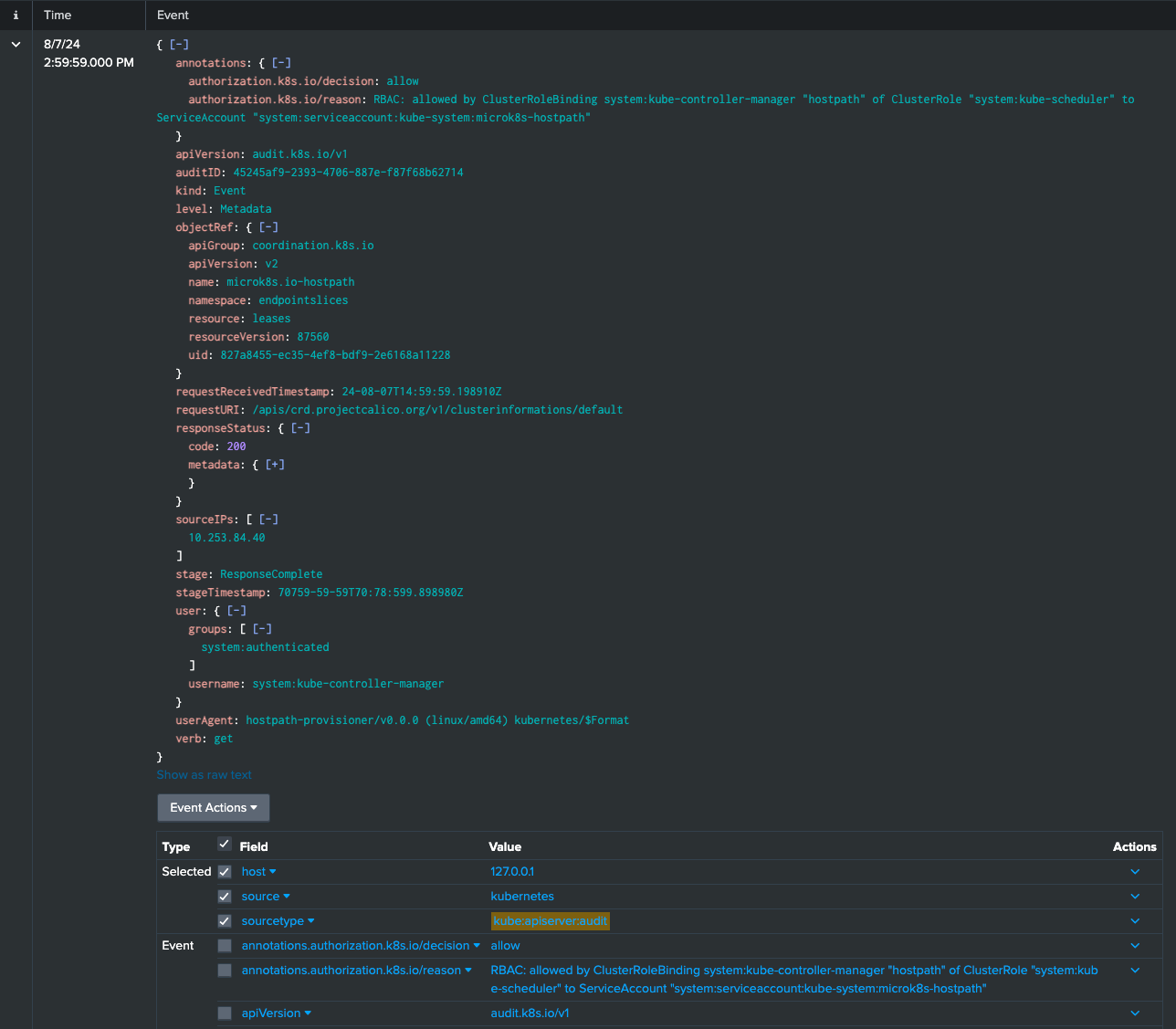
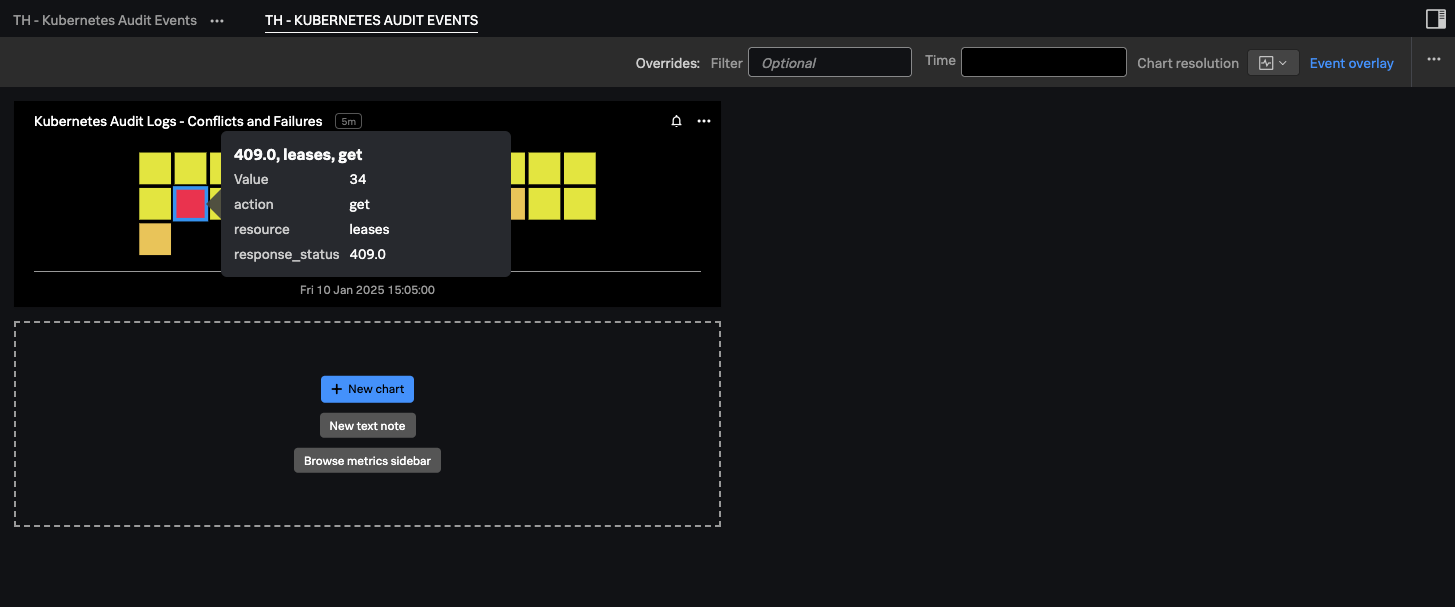
次に、生のイベントから主要なディメンションを追加してこれらのメトリクスを強化する方法を示し、特定のアクションとリソースにドリルダウンできるようにしました。エラーに焦点を当てるためにメトリクスをフィルタリングし、リソースとアクションごとに分類するチャートを作成しました。これにより、問題が発生している場所をリアルタイムで正確に特定できるようになりました。
Splunk Observability Cloud のリアルタイムアーキテクチャにより、これらのメトリクスは問題が検出された瞬間にアラートをトリガーでき、平均検出時間(MTTD)を大幅に短縮できます。さらに、このチャートを新規または既存のダッシュボードに簡単に保存して、重要なメトリクスの継続的な可視性と監視を確保する方法を示しました。
このアプローチの価値は明確です:Ingest Processor を使用してログをメトリクスに変換することで、データ処理を効率化し、ストレージコストを削減するだけでなく、Splunk Observability Cloud を使用してリアルタイムで問題を監視し対応する能力も得られます。これにより、コンプライアンスやより深い分析のために元のログを保持してアクセスする能力を維持しながら、問題解決の高速化、システム信頼性の向上、およびより効率的なリソース利用が実現します。
Happy Splunking!
