6. 遅いトランザクションのトラブルシューティング
この演習では、以下のタスクを完了します
- アプリケーションダッシュボードとフローマップを監視する
- 遅いトランザクションスナップショットをトラブルシューティングする
アプリケーションダッシュボードとフローマップの監視
前の演習では、Application Flow Mapの基本的な機能をいくつか見てきました。Application DashboardとFlow Mapを使用してアプリケーション内の問題を即座に特定する方法をより深く見ていきましょう。
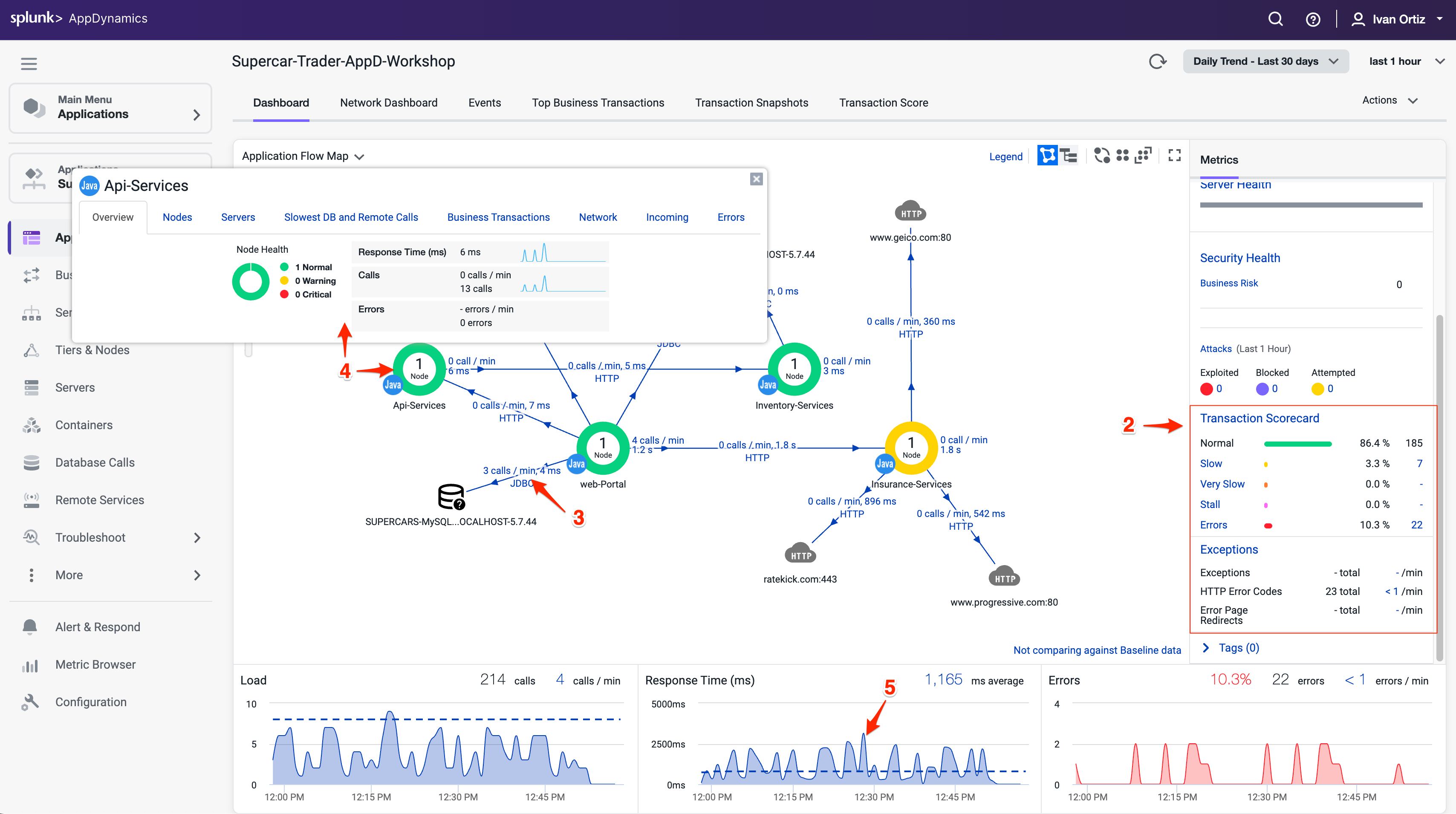
Health Rule Violations、Node Healthの問題、およびBusiness Transactionsの健全性は、選択した時間枠についてこのエリアに常に表示されます。ここで利用可能なリンクをクリックして詳細にドリルダウンできます。
Transaction Scorecardは、正常、遅い、非常に遅い、停止、エラーのあるトランザクションの数と割合を表示します。スコアカードには、例外タイプの高レベルのカテゴリも表示されます。ここで利用可能なリンクをクリックして詳細にドリルダウンできます。
異なるアプリケーションコンポーネントを接続する青い線のいずれかを左クリック(シングルクリック)すると、2つのコンポーネント間のインタラクションの概要が表示されます。
Tierの色付きリング内を左クリック(シングルクリック)すると、Flow Mapに留まりながらそのTierに関する詳細情報が表示されます。
ダッシュボードの下部にある3つのチャート(Load、Response Time、Errors)のいずれかの時系列にマウスを合わせると、記録されたメトリクスの詳細が表示されます。
次に、Dynamic Baselinesとダッシュボードの下部にあるチャートのオプションを見てみましょう。
チャートのメトリクスを、各メトリクスに対して自動的に計算されたDynamic Baselineと比較します。
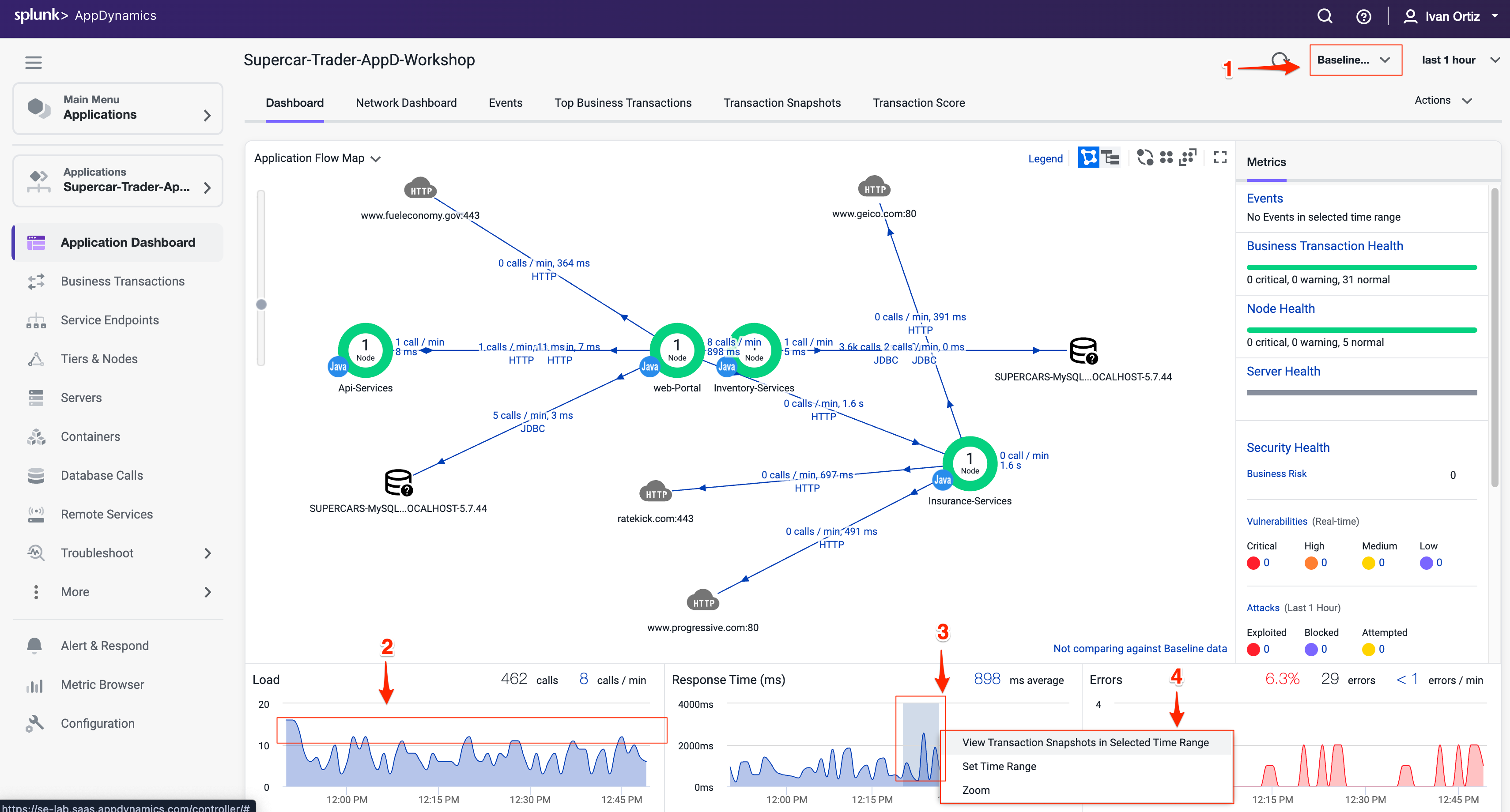
Dynamic Baselineは、以下の画像に示すように、負荷と応答時間のチャートに青い点線で表示されます。
ダッシュボードの下部にある3つのチャートのいずれかでスパイクを強調表示するには、マウスボタンを押したまま左から右にドラッグします。
マウスボタンを離し、ポップアップメニューの3つのオプションのいずれかを選択します。
AppDynamics独自のDynamic Baseliningの精度は時間の経過とともに向上し、アプリケーション、そのコンポーネント、およびビジネストランザクションの状態を正確に把握できるようになります。これにより、事態が深刻な状態になる前にプロアクティブにアラートを受け取り、エンドユーザーに影響が及ぶ前に対処できます。
AppDynamics Dynamic Baselinesの詳細についてはこちらをご覧ください。
遅いトランザクションスナップショットのトラブルシューティング
以下の手順に従って、Business Transactionsを確認し、非常に遅いトランザクションが最も多いものを見つけましょう。
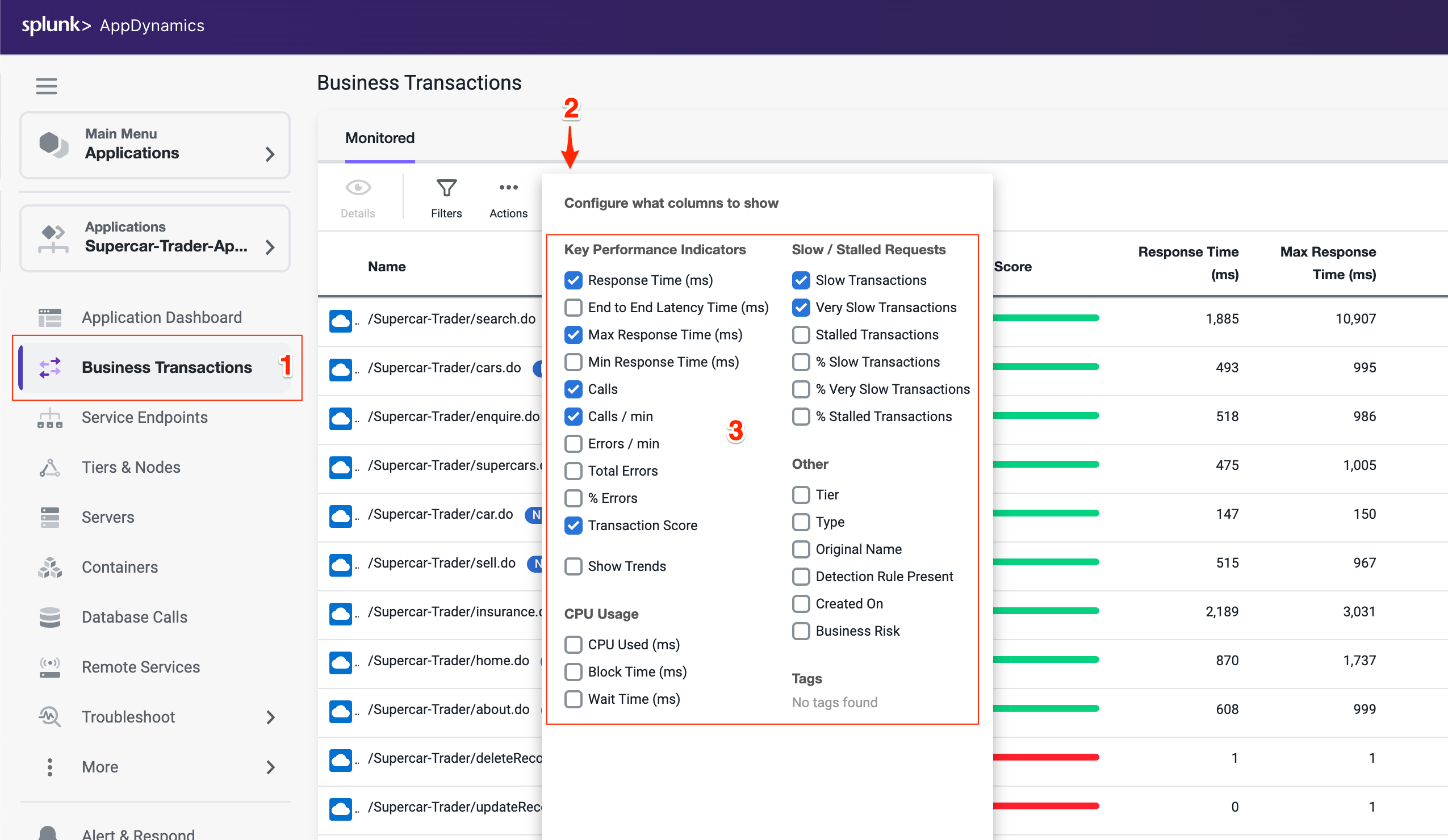
左側のメニューで Business Transactions オプションをクリックします。
View Options ボタンをクリックします。
以下の画像と一致するようにオプションのボックスのチェックを入れたり外したりします
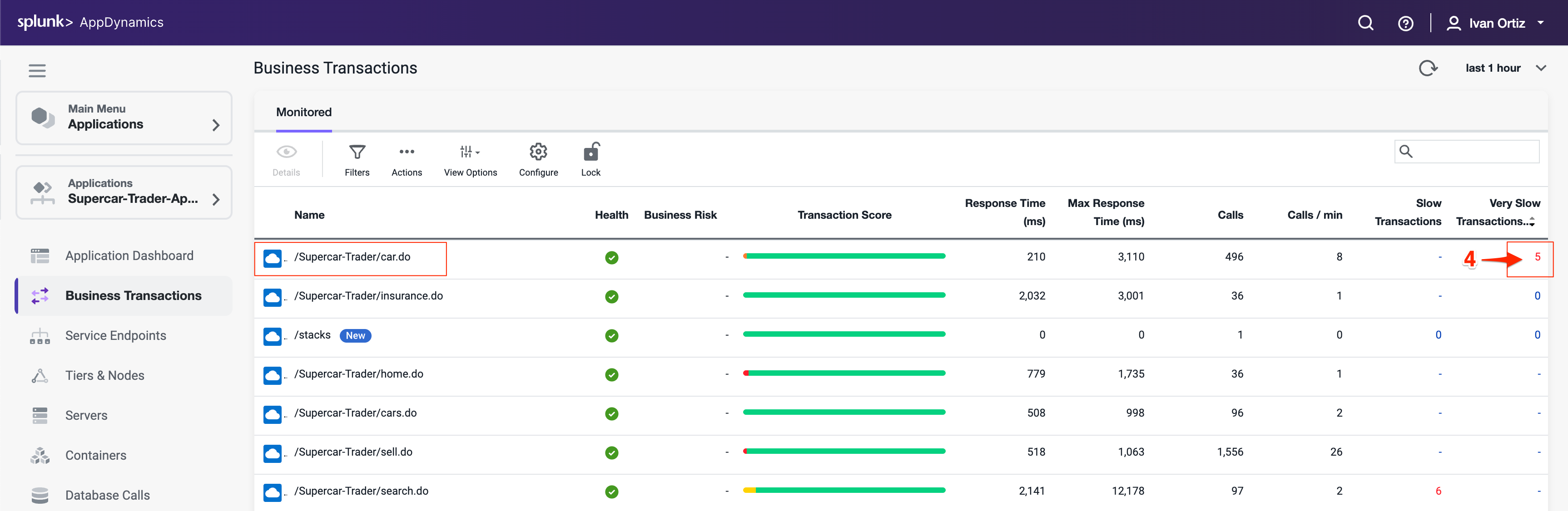
/Supercar-Trader/car.doという名前のBusiness Transactionを見つけ、そのBusiness TransactionのVery Slow Transactionsの数をクリックして、非常に遅いトランザクションスナップショットにドリルダウンします。
Tip
/Supercar-Trader/car.do BTにVery Slow Transactionsがない場合は、それがあるBusiness Transactionを見つけて、その列の数字をクリックしてください。今後のスクリーンショットは若干異なる場合がありますが、概念は同じです。
非常に遅いトランザクションスナップショットのリストが表示されるはずです。以下に示すように、最も応答時間が長いスナップショットをダブルクリックします。
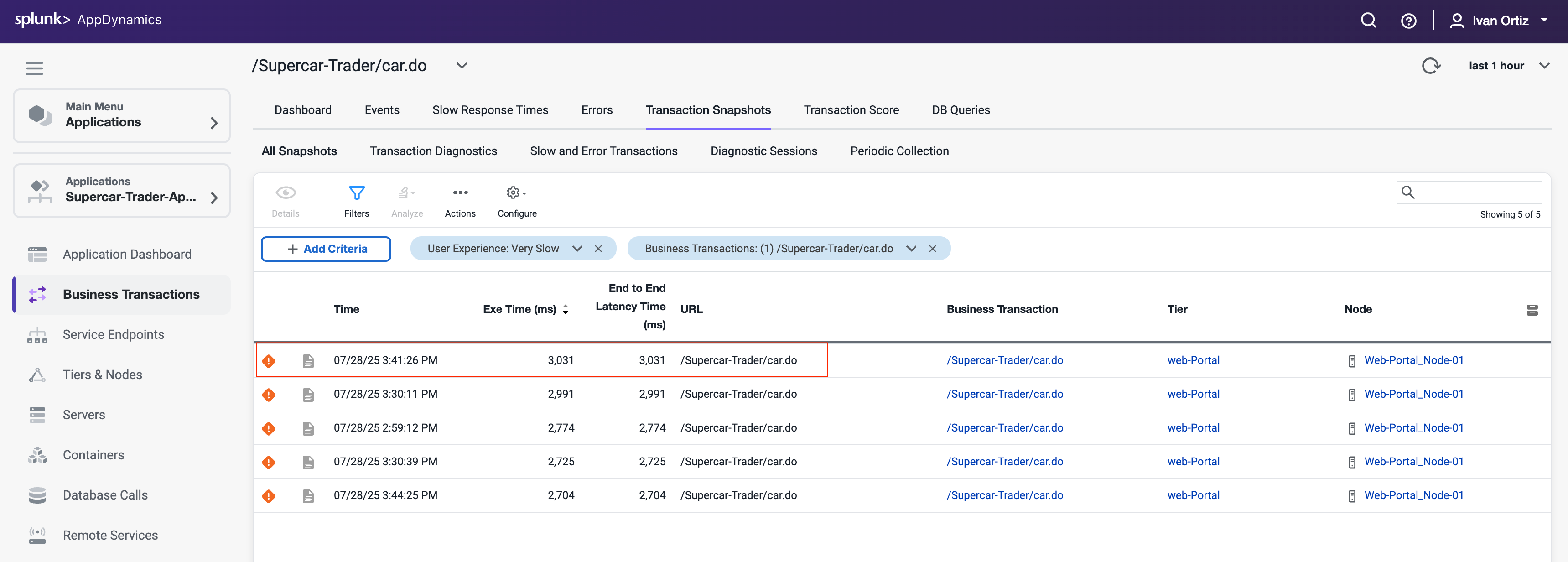
トランザクションスナップショットビューアが開くと、この特定のトランザクションの一部であったすべてのコンポーネントのフローマップビューが表示されます。このスナップショットは、トランザクションが以下のコンポーネントを順番に通過したことを示しています。
- Web-Portal Tier
- Api-Services Tier
- Enquiry-Services Tier
- MySQL Database
左側のPotential Issuesパネルは、遅いメソッドと遅いリモートサービスを強調表示します。Potential Issuesパネルを使用してcall graphに直接ドリルダウンすることもできますが、この例ではスナップショット内のFlow Mapを使用して完全なトランザクションを追跡します。
スナップショットのFlow Mapに表示されているWeb-Portal Tierの Drill Down をクリックします。
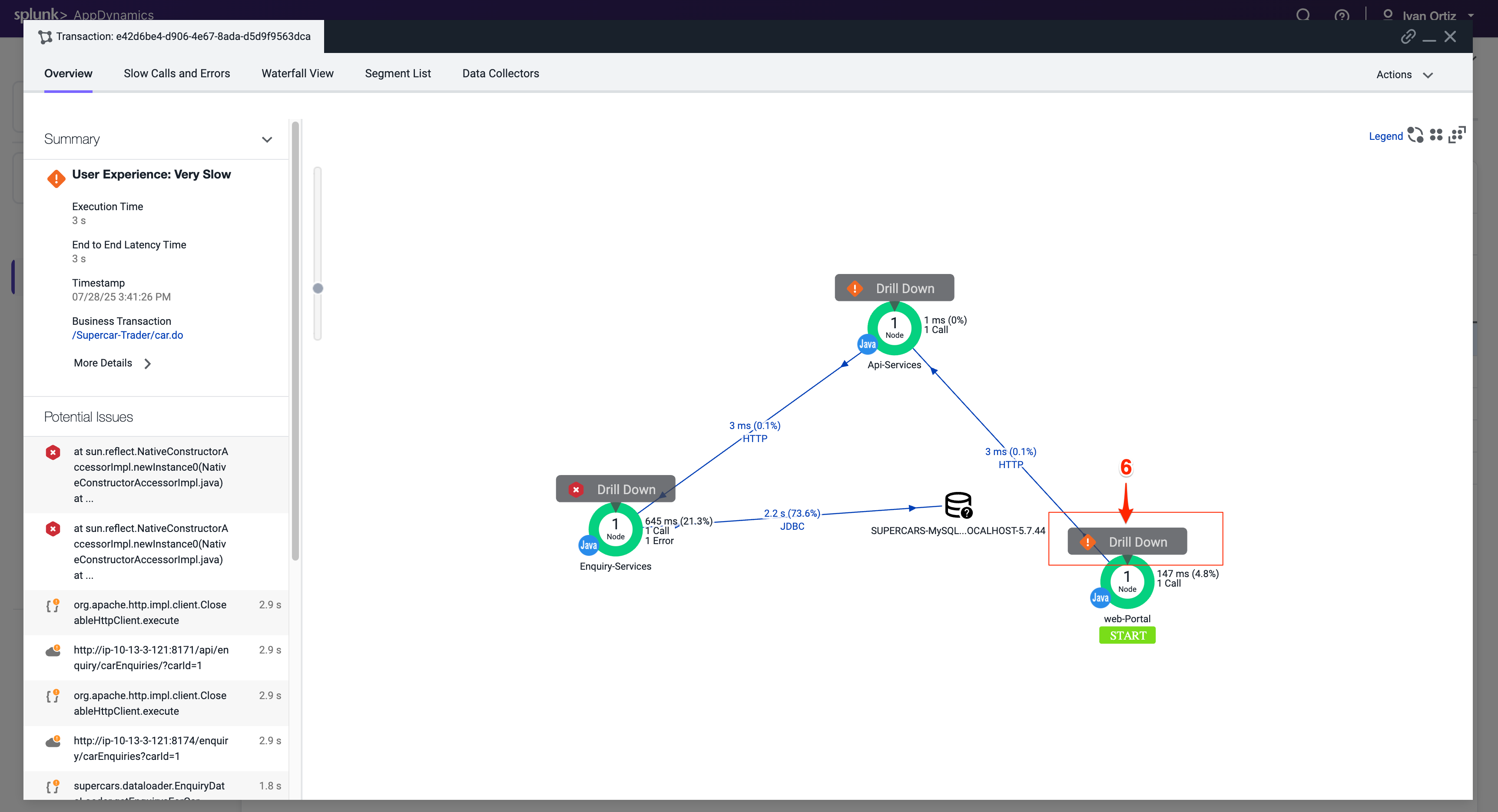
開いたタブにはWeb-Portal Tierのcall graphが表示されます。ほとんどの時間がアウトバウンドHTTPコールによるものであることがわかります。
ブロックをクリックして、問題が発生しているセグメントにドリルダウンします。HTTPリンクをクリックしてダウンストリームコールの詳細を表示します。
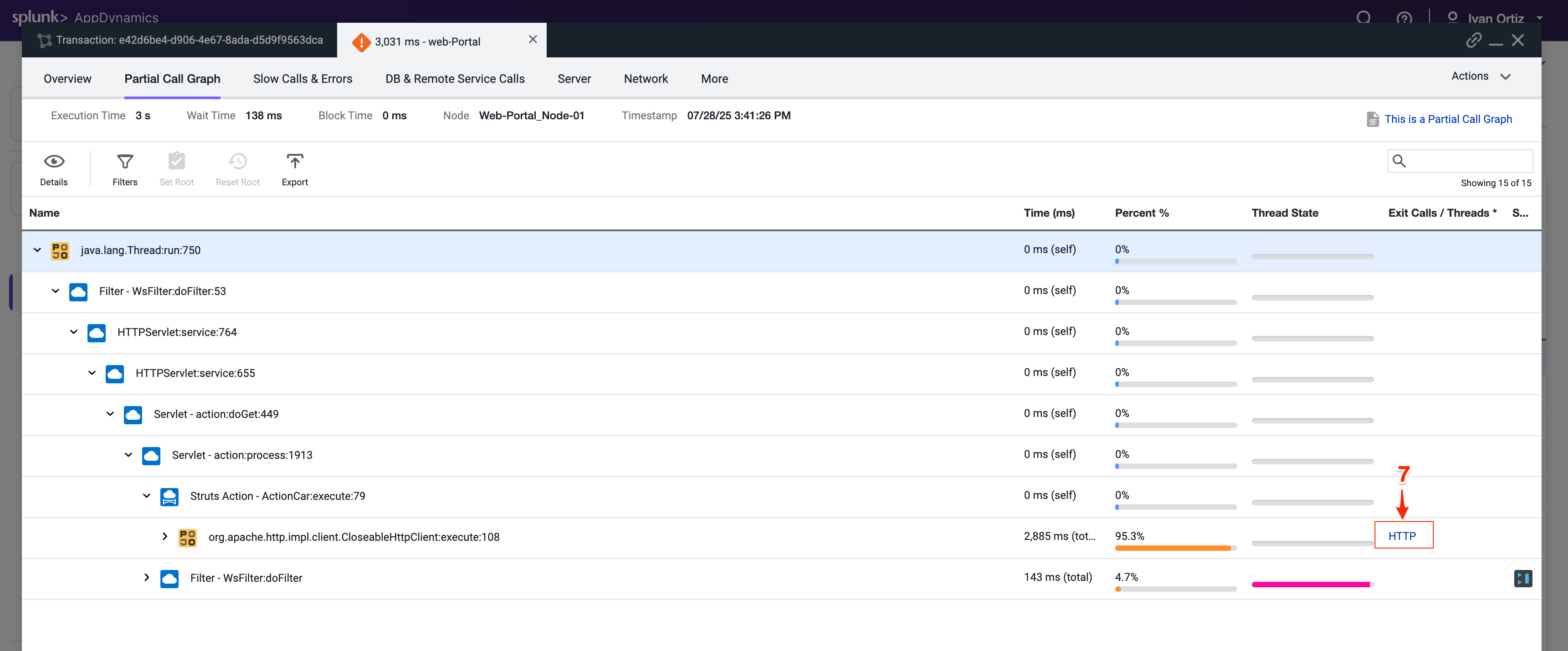
ダウンストリームコールの詳細パネルは、Web-Portal TierがApi-Services TierへのアウトバウンドHTTPコールを行ったことを示しています。HTTPコールを追跡してApi-Services Tierに進みます。
Drill Down into Downstream Call をクリックします。
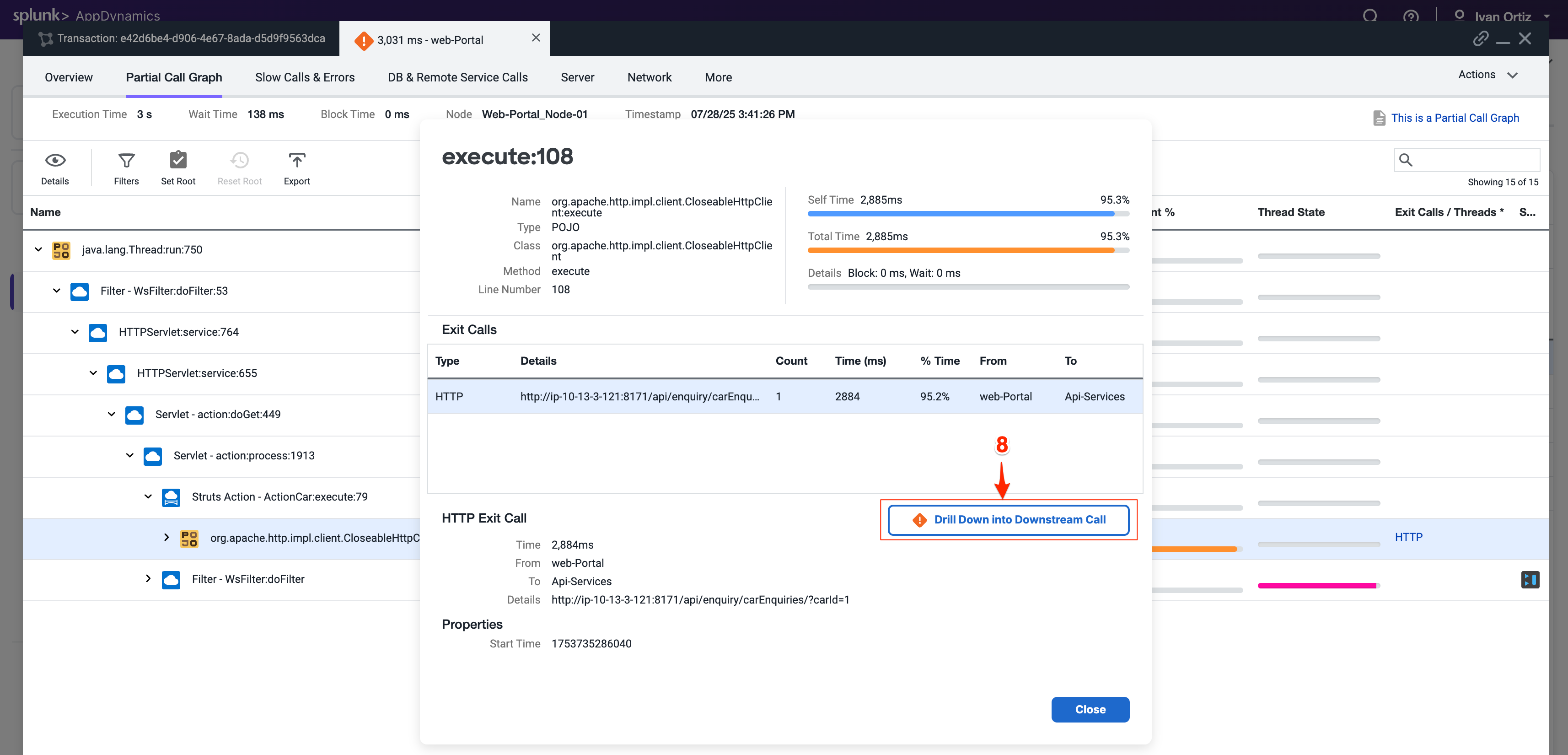
次に開くタブにはApi-Services Tierのcall graphが表示されます。時間の100%がアウトバウンドHTTPコールによるものであることがわかります。
HTTPリンクをクリックしてダウンストリームコールの詳細パネルを開きます。
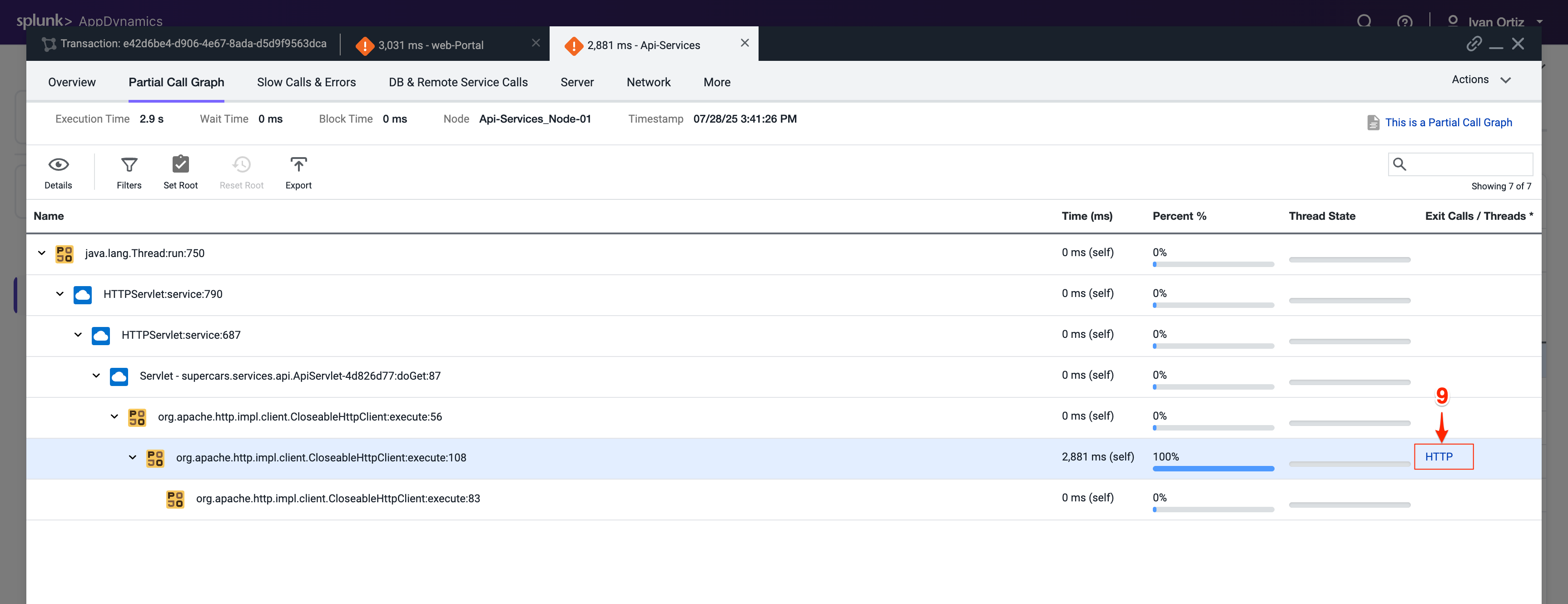
ダウンストリームコールの詳細パネルは、Api-Services TierがEnquiry-Services TierへのアウトバウンドHTTPコールを行ったことを示しています。HTTPコールを追跡してEnquiry-Services Tierに進みます。
Drill Down into Downstream Call をクリックします。
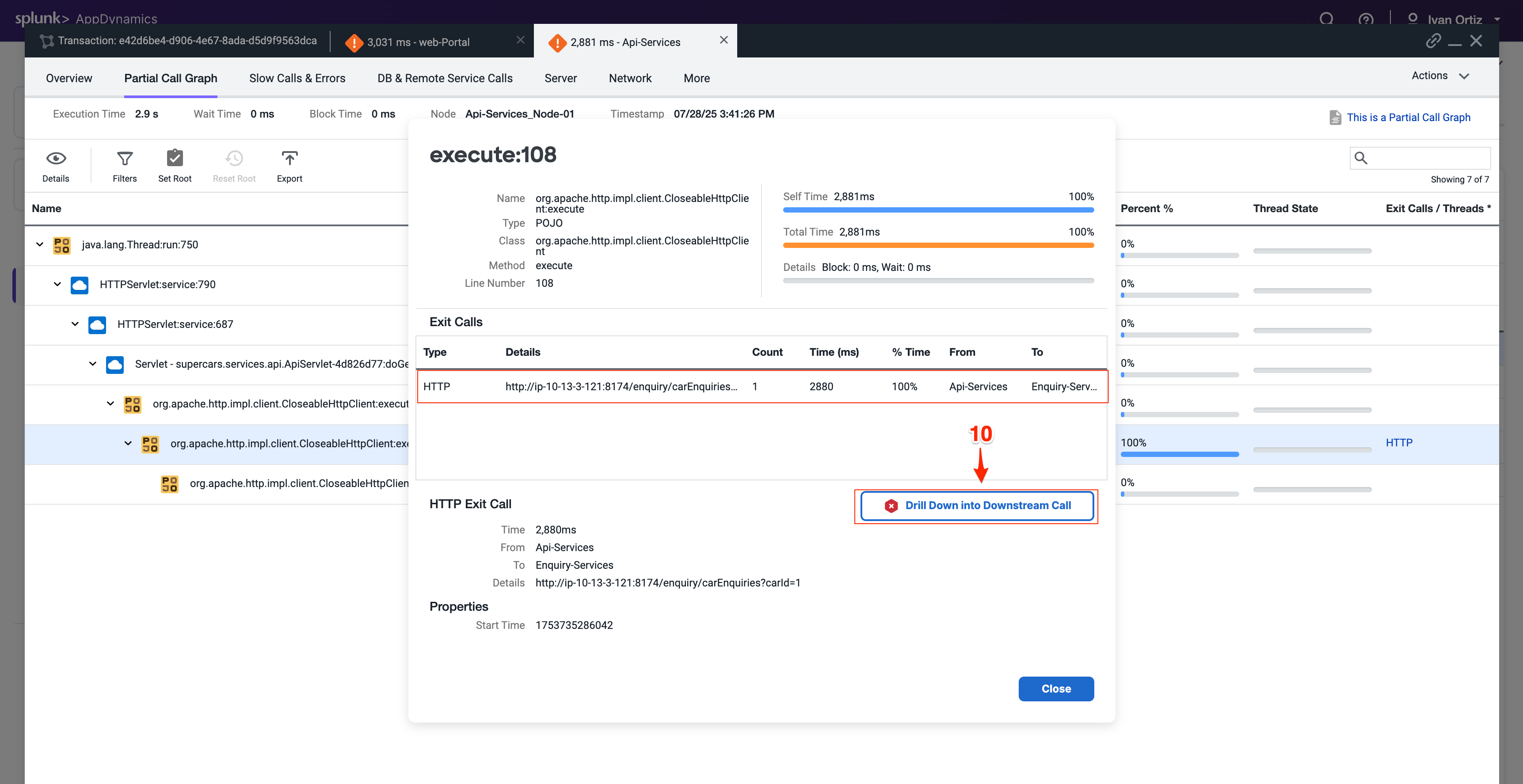
次に開くタブにはEnquiry-Services Tierのcall graphが表示されます。トランザクションに問題を引き起こしたデータベースへのJDBCコールがあったことがわかります。
最も時間がかかったJDBCリンクをクリックして、JDBCコールの詳細パネルを開きます。
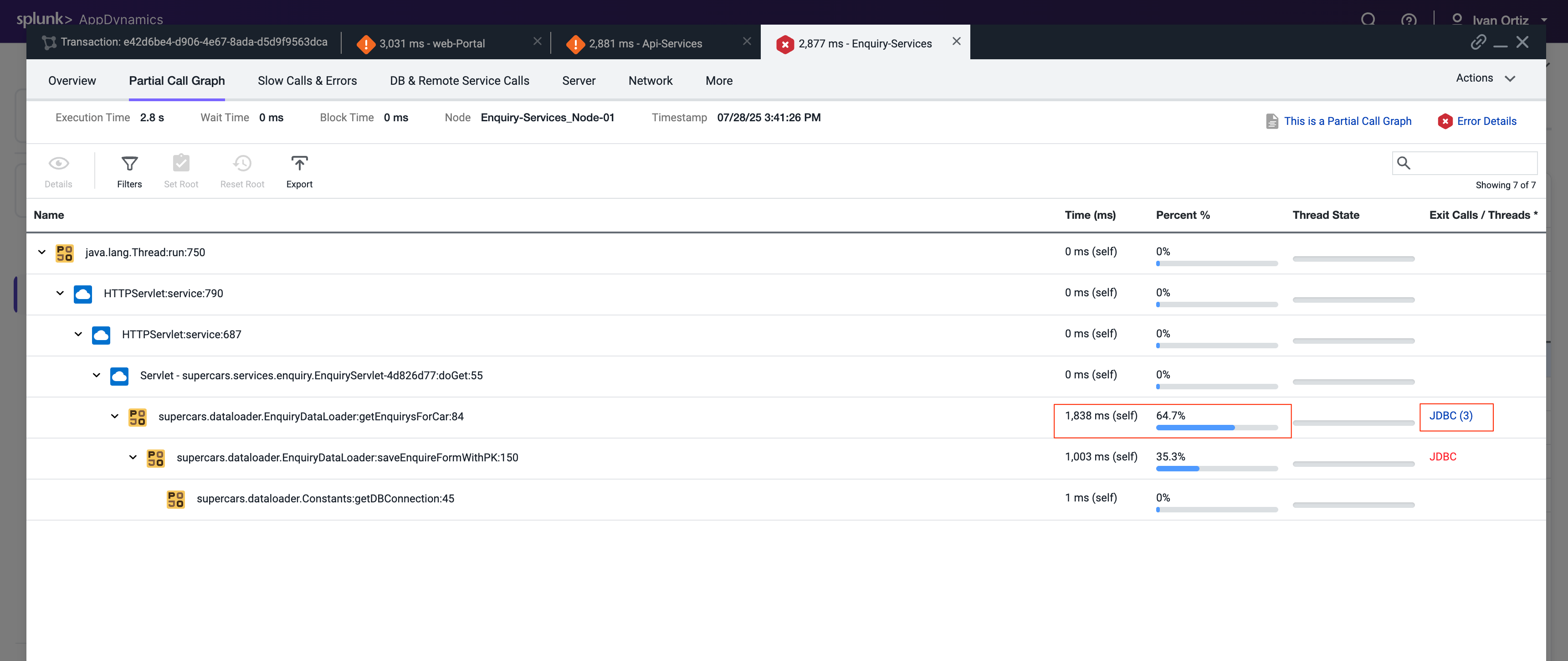
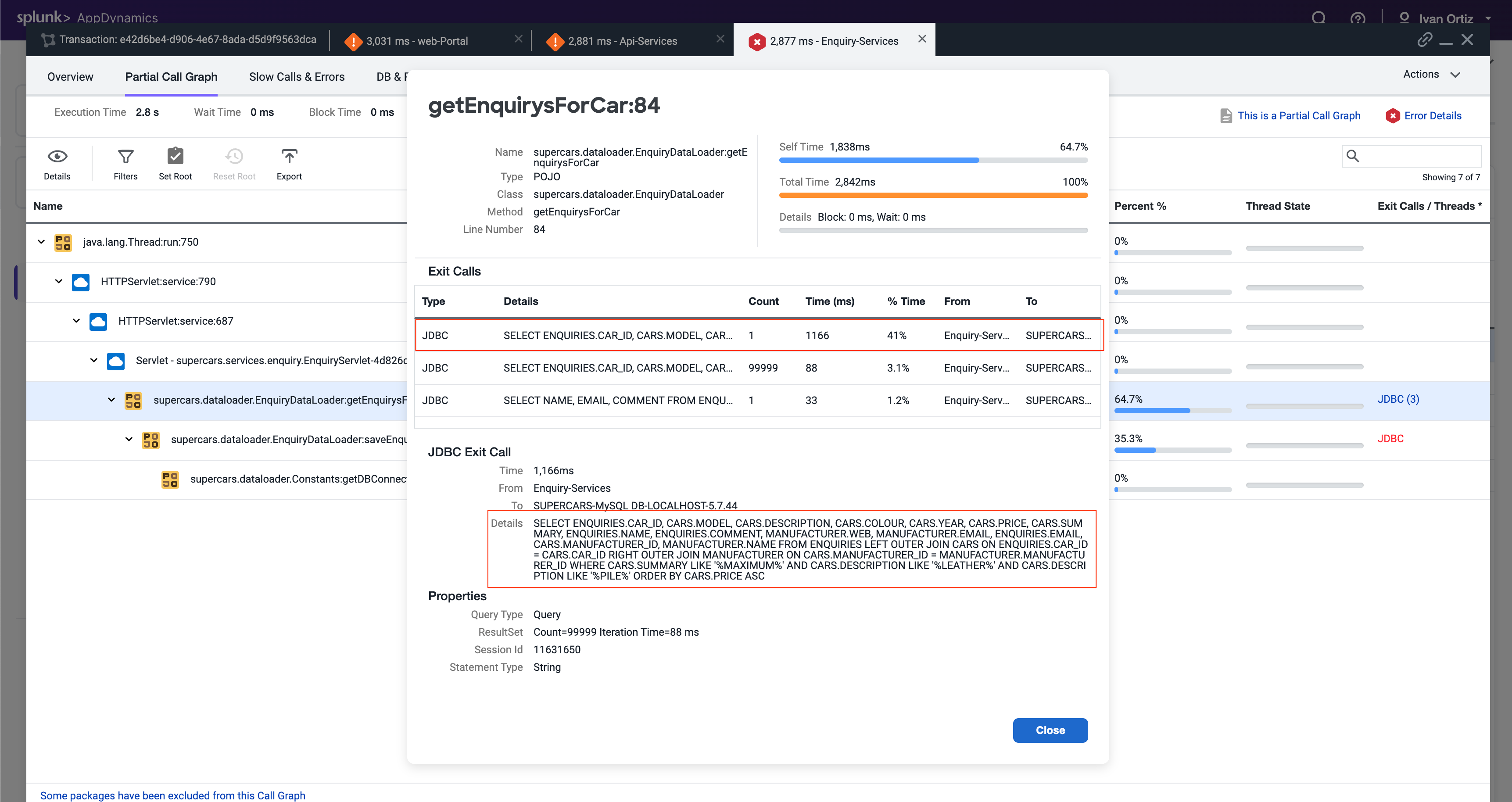
JDBC exitコールの詳細パネルには、最も時間がかかった特定のクエリが表示されます。SQLパラメータ値とともに完全なSQLステートメントを確認できます。
まとめ
このラボでは、まずBusiness Transactionsを使用して、トラブルシューティングが必要な非常に遅いトランザクションを特定しました。次に、call graphを調べて、遅延を引き起こしているコードの特定の部分を特定しました。その後、ダウンストリームサービスとデータベースにドリルダウンして、遅延の根本原因をさらに分析しました。最後に、パフォーマンスの問題の原因となっている非効率なSQLクエリを正確に特定することに成功しました。この包括的なアプローチは、AppDynamicsがトランザクションのボトルネックを効果的に分離して解決するのにどのように役立つかを示しています。