Scenariosのサブセクション
ThousandEyes と Splunk Observability Cloud の統合
120 minutes Author Alec Chamberlainこのワークショップでは、ThousandEyes と Splunk Observability Cloud を統合し、シンセティックモニタリングとオブザーバビリティデータ全体にわたる統合的な可視性を提供する方法を紹介します。
学習内容
このワークショップを完了すると、以下のことができるようになります
- ThousandEyes Enterprise Agent を Kubernetes のコンテナ化されたワークロードとしてデプロイする
- OpenTelemetry を使用して ThousandEyes メトリクスを Splunk Observability Cloud に統合する
- ThousandEyes と Splunk APM が同じリクエストにリンクできるよう分散トレーシングを設定する
- 内部の Kubernetes サービスおよび外部依存関係に対するシンセティックテストを作成する
- Splunk Observability Cloud ダッシュボードでテスト結果を監視する
- ThousandEyes から Splunk APM トレースに移動し、元の ThousandEyes テストに戻る
セクション
コアパス
- 概要 - ThousandEyes のエージェントタイプとアーキテクチャを理解する
- デプロイ - Kubernetes に Enterprise Agent をデプロイする
- Splunk 統合 - ThousandEyes メトリクスを Splunk Observability Cloud にストリーミングする
- 分散トレーシング - ThousandEyes と Splunk APM 間のサポートされた双方向ドリルダウンを有効にする
シナリオ拡張
- Kubernetes テスト - シンセティックモニタリングとトレース相関の両方に有用な内部テストを作成する
- RUM - ThousandEyes のネットワークシグナルと Splunk RUM を関連付けてエンドユーザー調査に活用する
サポート
- トラブルシューティング - よくある問題と解決方法
ヒント
このシナリオは2つの連携した統合として考えてください:OpenTelemetry ストリームが ThousandEyes メトリクスを Splunk に取り込み、分散トレーシングが Splunk APM から ThousandEyes への逆方向のパスを提供します。
前提条件
- Kubernetes クラスター(v1.16以上)
- 選択した namespace にリソースをデプロイするための RBAC 権限
- Enterprise Agent トークンにアクセスできる ThousandEyes アカウント
- インジェストトークンへのアクセスと APM ルックアップ用の API トークンを作成する権限を持つ Splunk Observability Cloud アカウント
統合のメリット
ThousandEyes を Splunk Observability Cloud に接続することで、以下のメリットが得られます
- 🔗 統合的な可視性: シンセティックテスト結果を RUM、APM トレース、およびインフラストラクチャメトリクスと相関付ける
- 📊 強化されたダッシュボード: 既存の Splunk オブザーバビリティメトリクスと並べて ThousandEyes データを可視化する
- 🔄 双方向ドリルダウン: ThousandEyes Service Map から Splunk トレースへ、また Splunk APM からリクエストを生成した ThousandEyes テストへ移動する
- 🚨 一元化されたアラート: Splunk 内で ThousandEyes テスト結果に基づくアラートを設定する
- 🔍 根本原因分析: 問題がネットワーク関連(ThousandEyes)かアプリケーション関連(APM)かを迅速に特定する
- 📈 包括的な分析: Splunk の強力な分析エンジンでシンセティックモニタリングのトレンドを分析する
ThousandEyes 統合のサブセクション
概要
10 minutesThousandEyes エージェントタイプ
Enterprise Agent
Enterprise Agent は、自社のインフラストラクチャ内にデプロイするソフトウェアベースの監視エージェントです。以下の機能を提供します
- 内部からの可視性: 内部ネットワークから外部サービスへの監視とテスト
- カスタマイズ可能な配置: ユーザーとアプリケーションが存在する場所にデプロイ
- フルテスト機能: HTTP、ネットワーク、DNS、音声、その他のテストタイプ
- 永続的な監視: スケジュールされたテストを実行し続けるエージェント
このワークショップでは、Enterprise Agent を Kubernetes クラスター内のコンテナ化されたワークロードとしてデプロイします。
Endpoint Agent
Endpoint Agent は、エンドユーザーのデバイス(ラップトップ、デスクトップ)にインストールされる軽量なエージェントで、以下の機能を提供します
- 実際のユーザー視点: 実際のユーザーエンドポイントからの監視
- ブラウザベースの監視: リアルユーザーエクスペリエンスメトリクスのキャプチャ
- セッションデータ: ユーザーの視点からのアプリケーションパフォーマンスに関する詳細なインサイト
このワークショップでは、Enterprise Agent のデプロイのみに焦点を当てます。
アーキテクチャ
---
config:
theme: 'base'
---
graph LR
subgraph k8s["Kubernetes Cluster"]
secret["Secret<br/>te-creds"]
agent["ThousandEyes<br/>Enterprise Agent<br/>Pod"]
subgraph apps["Application Pods"]
api["API Gateway<br/>Pod"]
payment["Payment Service<br/>Pod"]
auth["Auth Service<br/>Pod"]
end
subgraph svcs["Services"]
api_svc["api-gateway<br/>Service"]
payment_svc["payment-svc<br/>Service"]
auth_svc["auth-service<br/>Service"]
end
api_svc --> api
payment_svc --> payment
auth_svc --> auth
secret -.-> agent
agent -->|"HTTP Tests"| api_svc
agent -->|"HTTP Tests"| payment_svc
agent -->|"HTTP Tests"| auth_svc
end
external["External<br/>Services"]
agent --> external
subgraph te["ThousandEyes Platform"]
te_cloud["ThousandEyes<br/>Cloud"]
te_api["API<br/>v7/stream"]
te_cloud <--> te_api
end
agent -->|"Test Results"| te_cloud
subgraph splunk["Splunk Observability Cloud"]
otel["OpenTelemetry<br/>Collector"]
metrics["Metrics"]
dashboards["Dashboards"]
apm["APM/RUM"]
alerts["Alerts"]
otel --> metrics
otel --> dashboards
metrics --> apm
dashboards --> alerts
end
te_cloud -->|"OTel/HTTP metrics"| otel
te_cloud -->|"Trace lookup"| apm
apm -->|"Deep links to test"| te_cloud
user["DevOps/SRE<br/>Team"]
user -.-> te_cloud
user -.-> dashboards
user -.-> agent
style k8s fill:#e1f5ff,stroke:#0288d1,stroke-width:2px
style apps fill:#f3e5f5,stroke:#7b1fa2,stroke-width:2px
style svcs fill:#f3e5f5,stroke:#7b1fa2,stroke-width:2px
style agent fill:#ffeb3b,stroke:#f57c00,stroke-width:2px
style secret fill:#ffcdd2,stroke:#c62828,stroke-width:2px
style api fill:#e1bee7,stroke:#7b1fa2,stroke-width:1px
style payment fill:#e1bee7,stroke:#7b1fa2,stroke-width:1px
style auth fill:#e1bee7,stroke:#7b1fa2,stroke-width:1px
style api_svc fill:#ce93d8,stroke:#7b1fa2,stroke-width:1px
style payment_svc fill:#ce93d8,stroke:#7b1fa2,stroke-width:1px
style auth_svc fill:#ce93d8,stroke:#7b1fa2,stroke-width:1px
style external fill:#c8e6c9,stroke:#388e3c,stroke-width:2px
style te fill:#fff9c4,stroke:#f57f17,stroke-width:2px
style te_cloud fill:#ffecb3,stroke:#f57f17,stroke-width:2px
style te_api fill:#ffe082,stroke:#f57f17,stroke-width:2px
style splunk fill:#ff6e40,stroke:#d84315,stroke-width:2px
style otel fill:#ff8a65,stroke:#d84315,stroke-width:2px
style metrics fill:#ffccbc,stroke:#d84315,stroke-width:1px
style dashboards fill:#ffccbc,stroke:#d84315,stroke-width:1px
style apm fill:#ffccbc,stroke:#d84315,stroke-width:1px
style alerts fill:#ffccbc,stroke:#d84315,stroke-width:1px
style user fill:#b2dfdb,stroke:#00695c,stroke-width:2pxアーキテクチャコンポーネント
1. Kubernetes クラスター
- Secret (te-creds): 認証用の base64 エンコードされた
TEAGENT_ACCOUNT_TOKENを保存します - ThousandEyes Enterprise Agent Pod:
- コンテナイメージ:
thousandeyes/enterprise-agent:latest - ホスト名:
te-agent-aleccham(カスタマイズ可能) - セキュリティケーパビリティ:
NET_ADMIN、SYS_ADMIN(ネットワークテストに必要) - メモリ割り当て: 2GB リクエスト、3.5GB リミット
- ネットワークモード: IPv4 のみ(環境変数
TEAGENT_INET: "4"で設定) - イメージプルポリシー:
Always(最新のイメージが確実にプルされます) - Init コマンド:
/sbin/my_init(エージェントの適切な初期化に必要)
- コンテナイメージ:
- 内部サービス: REST API、マイクロサービス、データベース、gRPC サービスを含む Kubernetes ワークロード
2. テスト対象
- 内部サービス: Kubernetes クラスター内のサービスを監視します
- 外部サービス: 以下のような外部依存関係をテストします
- 決済ゲートウェイ(Stripe、PayPal)
- サードパーティ API
- SaaS アプリケーション
- CDN エンドポイント
- パブリック Web サイト
3. ThousandEyes Platform
- ThousandEyes Cloud: 以下の機能を提供する中央プラットフォーム
- エージェントの登録と管理
- テストの設定とスケジューリング
- メトリクスの収集と集約
- 組み込みアラートエンジン
- ThousandEyes API: プログラマティックアクセスのための RESTful API(v7/stream エンドポイント)
4. テストタイプとメトリクス
Enterprise Agent は以下を実行します
- HTTP/HTTPS テスト: Web ページの可用性、レスポンスタイム、ステータスコード
- DNS テスト: 名前解決時間、レコード検証
- ネットワークレイヤーテスト: レイテンシー、パケットロス、パス可視化
- Voice/RTP テスト: 音声トラフィックの品質メトリクス
収集されるメトリクスは以下の通りです
- HTTP サーバー可用性(%)
- スループット(bytes/s)
- リクエスト時間(秒)
- ページロード完了率(%)
- エラーコードと失敗理由
5. Splunk Observability Cloud との統合
- OpenTelemetry Metrics Stream:
- エンドポイント:
https://ingest.{realm}.signalfx.com/v2/datapoint/otlp - プロトコル: HTTP または gRPC
- フォーマット: Protobuf
- 認証:
X-SF-Tokenヘッダー - シグナルタイプ: Metrics(OpenTelemetry v2)
- エンドポイント:
- 分散トレーシング統合:
- ThousandEyes テストタイプ: 分散トレーシングが有効な HTTP Server または API
- ThousandEyes コネクターターゲット:
https://api.{realm}.signalfx.com - 認証:
X-SF-Tokenヘッダーの Splunk API トークン - 結果: ThousandEyes から関連する Splunk APM トレースを開くことができ、Splunk APM トレースから元の ThousandEyes テストにリンクバックできます
- オブザーバビリティ機能:
- Metrics: ThousandEyes データのリアルタイム可視化
- Dashboards: 統合ビューを備えた構築済み ThousandEyes ダッシュボード
- APM/RUM 統合: シンセティックテストとアプリケーショントレースおよびリアルユーザーモニタリングの相関
- Alerting: 相関ルールを備えた一元的なアラート管理
6. データフロー
- エージェントが Kubernetes Secret のトークンを使用して認証します
- エージェントが内部および外部のターゲットに対してスケジュールされたテストを実行します
- テスト結果が ThousandEyes Cloud に送信されます
- ThousandEyes が OpenTelemetry プロトコル経由で Splunk にメトリクスをストリーミングします
- 分散トレーシングが有効な HTTP Server および API テストでは、ThousandEyes がリクエストに
b3、traceparent、tracestateヘッダーを挿入します - インストルメント済みアプリケーションが結果のトレースを Splunk APM に送信します
- ThousandEyes から関連する Splunk トレースを開くことができ、Splunk APM から元の ThousandEyes テストにリンクバックできます
- DevOps、ネットワーク、アプリケーションチームが調査中に両方のビューを使用して連携します
テスト機能
このデプロイにより、以下のことが可能になります
- ✅ 内部サービスのテスト: クラスター内から Kubernetes サービス、API、マイクロサービスを監視します
- ✅ 外部依存関係のテスト: 決済ゲートウェイ、サードパーティ API、SaaS プラットフォームへの接続性を検証します
- ✅ パフォーマンスの測定: クラスターの視点からレイテンシー、可用性、パフォーマンスメトリクスをキャプチャします
- ✅ 問題のトラブルシューティング: 問題がインフラストラクチャ、ネットワークパス、またはインストルメント済みアプリケーションサービスのいずれに起因するかを特定します
注意
これは ThousandEyes エージェントの公式にサポートされたデプロイ構成ではありません。ただし、本番環境に近い環境でテスト済みであり、非常にうまく動作します。
デプロイメント
20 minutesこのセクションでは、KubernetesクラスターにThousandEyes Enterprise Agentをデプロイする手順を説明します。
コンポーネント
デプロイメントは2つのファイルで構成されています:
1. シークレットファイル (credentialsSecret.yaml)
ThousandEyesエージェントトークン(base64エンコード済み)を含みます。このシークレットは、エージェントをThousandEyes Cloudで認証するためにデプロイメントから参照されます。
2. デプロイメントマニフェスト (thousandEyesDeploy.yaml)
以下の主要な設定でEnterprise AgentのPod構成を定義します:
- Namespace:
te-demo(必要に応じてカスタマイズ) - Image: Docker Hubの
thousandeyes/enterprise-agent:latest - Hostname:
te-agent-aleccham(ThousandEyesダッシュボードに表示されます) - Capabilities: ネットワークテストに
NET_ADMINとSYS_ADMINが必要 - Resources:
- メモリ制限: 3584Mi
- メモリ要求: 2000Mi
重要な注意事項
- エージェントはネットワークテストを実行するために昇格した権限(
NET_ADMIN、SYS_ADMIN)が必要です TEAGENT_INET: "4"環境変数はIPv4専用モードを強制します(一部のネットワーク構成で必要)/sbin/my_initコマンドは、エージェントの適切な初期化とサービス管理に必要ですimagePullPolicy: Alwaysは常に最新のイメージバージョンをプルすることを保証します- ThousandEyesダッシュボードでエージェントを一意に識別するために
hostnameフィールドを調整してください - Kubernetes環境に合わせて
namespaceを変更してください - ThousandEyes Enterprise Agentは比較的高いハードウェア要件があります。環境に応じてこれらを調整する必要がある場合があります
インストール手順
ステップ 1: ThousandEyes トークンの作成
app.thousandeyes.com/login でThousandEyesプラットフォームにログインします
Cloud & Enterprise Agents > Agent Settings > Add New Enterprise Agent に移動します
Account Group Token をコピーします
トークンをBase64エンコードします:
次のステップのためにbase64エンコードされた出力を保存します

ステップ 2: Namespace の作成
Namespaceを作成します(存在しない場合):
ステップ 3: シークレットの作成
base64エンコードされたトークンを含む credentialsSecret.yaml という名前のファイルを作成します:
シークレットを適用します:
ステップ 4: デプロイメントの作成
上記のデプロイメントマニフェストを含む thousandEyesDeploy.yaml という名前のファイルを作成します(必要に応じてhostnameとnamespaceをカスタマイズしてください)。
デプロイメントを適用します:
ステップ 5: デプロイメントの確認
エージェントが実行中であることを確認します:
期待される出力:
エージェントが接続していることを確認するためにログをチェックします:
ステップ 6: ThousandEyes ダッシュボードでの確認
ThousandEyesダッシュボードでエージェントが正常に登録されたことを確認します:
Cloud & Enterprise Agents > Agent Settings に移動して、新しく登録されたエージェントを確認します。
成功
ThousandEyes Enterprise AgentがKubernetesで実行されています!次に、Splunk Observability Cloudとの統合を行います。
背景
ThousandEyesは公式のKubernetesデプロイメントドキュメントを提供していません。標準的なデプロイメント方法は docker run コマンドを使用するため、再利用可能なKubernetesマニフェストに変換することが困難です。このガイドは、本番環境対応のKubernetes構成を提供することでそのギャップを埋めます。
Splunk 連携
15 minutesSplunk Observability Cloud について
Splunk Observability Cloudは、メトリクス、トレース、ログを大規模に監視するために構築されたリアルタイムのオブザーバビリティプラットフォームです。OpenTelemetryデータを取り込み、高度なダッシュボードと分析機能を提供して、チームがパフォーマンスの問題を迅速に検出し解決できるよう支援します。このセクションでは、OpenTelemetryを使用してThousandEyesデータをSplunk Observability Cloudと統合する方法を説明します。
このセクションの範囲
このセクションでは、ThousandEyesからSplunk Observability Cloudへのメトリクスストリーミングパスについて説明します。次のセクションでは、ThousandEyesとSplunk APM間の双方向リンクを作成する別の分散トレーシングワークフローを追加します。
ステップ 1: Splunk Observability Cloud アクセストークンを作成する
ThousandEyesメトリクスをSplunk Observability Cloudに送信するには、Ingest スコープを持つアクセストークンが必要です。以下の手順に従ってください:
- Splunk Observability Cloudプラットフォームで、Settings > Access Token に移動します
- Create Token をクリックします
- Name を入力します
- Ingest スコープを選択します
- Create を選択してアクセストークンを生成します
- アクセストークンをコピーし、安全に保管します
テレメトリデータをSplunk Observability Cloudに送信するには、アクセストークンが必要です。
ステップ 2: 連携を作成する
この連携は、ThousandEyesメトリクスをSplunk Observability Cloudのダッシュボードとディテクターに送信する一方向のテレメトリストリームです。
ThousandEyes UI を使用する
Splunk Observability CloudとThousandEyesを連携するには:
ThousandEyesプラットフォームでアカウントにログインし、Manage > Integration > Integration 1.0 に移動します
New Integration をクリックし、OpenTelemetry Integration を選択します
連携の Name を入力します
Target を HTTP に設定します
Endpoint URL を入力します:
https://ingest.{REALM}.signalfx.com/v2/datapoint/otlp{REALM}をSplunk環境に置き換えます(例:us1、eu0)
Preset Configuration で Splunk Observability Cloud を選択します
Auth Type で Custom を選択します
以下の Custom Headers を追加します:
X-SF-Token: {TOKEN}(ステップ1で作成したSplunk Observability Cloudアクセストークンを入力)Content-Type: application/x-protobuf
OpenTelemetry Signal で Metric を選択します
Data Model Version で v2 を選択します
テストを選択します
Save をクリックして連携の設定を完了します

これでThousandEyesデータとSplunk Observability Cloudの連携が正常に完了しました。
ThousandEyes API を使用する
プログラムによる連携には、以下のAPIコマンドを使用します:
HTTP Protocol
gRPC Protocol
streamEndpointUrl と X-SF-Token の値を、お使いのSplunk Observability Cloudインスタンスの正しい値に置き換えてください。
注意
{REALM} をSplunk環境のRealm(例:us1、us2、eu0)に、{TOKEN} を実際のSplunkアクセストークンに置き換えてください。
次のステップ
メトリクス連携が完了したら、分散トレーシングに進み、ThousandEyesからSplunk APMへの、そしてその逆の調査パスを追加します。
ステップ 3: Splunk Observability Cloud の ThousandEyes ダッシュボード
連携が設定されると、Splunk Observability Cloud内のThousandEyes Network Monitoring Dashboardでリアルタイムの監視データを表示できます。ダッシュボードには以下が含まれます:
- HTTP Server Availability (%):監視対象のHTTPサーバーの可用性を表示します
- HTTP Throughput (bytes/s):時間の経過に伴うデータ転送速度を表示します
- Client Request Duration (seconds):クライアントリクエストのレイテンシを測定します
- Web Page Load Completion (%):ページ読み込み成功の割合を表示します
- Page Load Duration (seconds):ページの読み込み時間を表示します
ダッシュボードテンプレート
ダッシュボードテンプレートは以下のリンクからダウンロードできます:ThousandEyes Splunk Observability Cloud ダッシュボードテンプレートをダウンロード (Google Drive)。
完了
ThousandEyesデータがSplunk Observability Cloudにストリーミングされるようになりました。次に、分散トレーシングコネクタを追加して、トラブルシューティング中にThousandEyesとSplunk APMの間を移動できるようにします。
分散トレーシングと双方向ドリルダウン
25 minutesこのセクションでは、ThousandEyesとSplunkの統合を真の調査ワークフローに変えます。前のセクションでは、ThousandEyesが合成メトリクスをSplunk Observability Cloudにストリーミングしました。このセクションでは、サポートされている ThousandEyes <-> Splunk APM 分散トレーシング統合 を有効にし、ネットワーク、プラットフォーム、アプリケーションチームが同じリクエストを見ながら両方のツール間を行き来できるようにします。
これが重要な理由
これは、2つの環境間で 双方向アクセス を可能にする部分です。ThousandEyesからSplunk APMの関連トレースを開くことができ、Splunk APMから元のThousandEyesテストに戻ることができます。
学習内容
このセクションを終了すると、以下のことができるようになります:
- 内部サービスを計装してSplunk APMにトレースを送信する
- ThousandEyesの HTTP Server または API テストで分散トレーシングを有効にする
- Splunk APM用のThousandEyes Generic Connector を設定する
- ThousandEyesの Service Map を開き、対応するSplunkトレースに直接ジャンプする
- Splunk APMのThousandEyesメタデータを使用して、元のThousandEyesテストに戻る
サポートされているワークフロー
この学習シナリオは、ThousandEyesとSplunkがドキュメント化しているサポートされたワークフローに従います:
- ThousandEyesは、分散トレーシングが有効になっている場合、HTTP Server および API テストに
b3、traceparent、tracestateヘッダーを自動的に挿入します。 - 監視対象のエンドポイントは、ヘッダーを受け入れ、OpenTelemetryで計装され、トレースコンテキストを伝播し、オブザーバビリティバックエンドにトレースを送信する必要があります。
- Splunk APMの場合、ThousandEyesは
https://api.<REALM>.signalfx.comを指し、API スコープ のSplunkトークンで認証する Generic Connector を使用します。 - Splunk APMは、
thousandeyes.test.idやthousandeyes.permalinkなどのThousandEyes属性で一致するトレースを強化し、ThousandEyesへの逆ジャンプを可能にします。
これらのヘッダーの実際の意味
この部分は見落としがちですが、そうすべきではありません。トレース相関は、サービスがThousandEyesが挿入するヘッダーを理解し、トレースを正しく継続する場合にのみ機能します。
traceparentとtracestateはW3C Trace Contextヘッダーです。b3はZipkin B3シングルヘッダー形式です。- ThousandEyesは両方を挿入します。これは、実際の環境には、同じ伝播形式を好まないプロキシ、メッシュ、ゲートウェイ、アプリランタイムが混在していることが多いためです。
OpenTelemetryの用語では、重要な設定はプロパゲーターリストです:
これは2つのことを行います:
- サービスが受信ThousandEyesリクエストから B3 または W3C コンテキストのいずれかを抽出できるようにします。
tracecontextを有効にしておくことで、W3Ctracestateを保持します。
重要な詳細
tracestate を別のOpenTelemetryプロパゲーターとして追加する必要は ありません。tracecontext プロパゲーターが traceparent と tracestate の両方を処理します。
「正しく行う」とはどういうことか
コレクターはこのセットアップの一部に過ぎません。Kubernetesでの正しいThousandEyesトレーシングデプロイメントには 3 つのレイヤー があります:
- Deployment アノテーション - OpenTelemetry Operatorがランタイム固有の計装を挿入するため。
- Instrumentation リソース - 挿入されたSDKがトレースの送信先と使用するプロパゲーターを知るため。
- Collector トレースパイプライン - OTLPトレースが実際に受信され、Splunk APMにエクスポートされるため。
最も一般的な間違いは、コレクターだけに焦点を当てることです。コレクターは生の b3、traceparent、または tracestate リクエストヘッダーを直接見ることはありません。アプリケーションまたは自動計装ライブラリがまずそれらのヘッダーを抽出し、スパンコンテキストを継続し、次にOTLP経由でコレクターにスパンを送信する必要があります。
現在のクラスターからの実際の設定
以下の例は、このワークショップを現在実行しているライブクラスターからトリミングされたものです。これらは、今日Kubernetesで実際に機能しているパターンを示しています。
1. Deployment アノテーション
ライブクラスターでは、teastore アプリケーションは teastore/default Instrumentationリソースを指しています:
これは、ThousandEyesリクエストがトレースに変換されない場合に最初に確認する場所です。
2. Instrumentation リソース
これは teastore からのライブ Instrumentation オブジェクトで、ThousandEyesに関係するフィールドにトリミングされています:
これがThousandEyesシナリオの重要な部分です:
endpointはクラスターローカルのOTelエージェントサービスにスパンを送信します。b3はThousandEyes B3ヘッダーの抽出を可能にします。tracecontextはtraceparentとtracestateを保持します。parentbased_always_onは、ThousandEyesがリクエストを開始するとトレースが継続することを保証します。
3. 挿入された Pod が実際に取得するもの
実行中の teastore-webui-v1 Podでは、オペレーターが以下の環境変数を挿入しました:
これは有用な検証チェックポイントです。プロパゲーターが抽象的な設定オブジェクトで宣言されているだけでなく、ワークロードに適用されていることを証明するためです。
4. Agent Collector トレースパイプライン
otel-splunk のライブエージェントコレクターは、OTLP、Jaeger、Zipkinトラフィックを受信し、上流にトレースを転送しています。これは実行中のConfigMapからのトリミングされた抜粋です:
ThousandEyesの場合、重要な部分はコレクターの特別なB3オプションではありません。重要な部分は、コレクターが 4317 と 4318 でOTLPを公開していること、およびサービスがそこにスパンをエクスポートしていることです。
5. Gateway Collector の Splunk APM へのエクスポート
ライブゲートウェイコレクターは、トレースをSplunk Observability Cloudに転送します。これは実行中のゲートウェイConfigMapの関連部分です:
これは、スパンをSplunk APMに送信する部分です。このパイプラインが壊れている場合、ThousandEyesはリクエストにヘッダーを挿入できますが、相関トレースがSplunkに表示されることはありません。
現在のクラスターのポイント
ライブクラスターでは、teastore/default InstrumentationリソースがThousandEyesで従うべきパターンです。これは b3 と tracecontext を明示的に含んでいるためです。これが、このシナリオで複製したい設定です。
重要
このセクションではブラウザページのURLを使用 しないでください。ThousandEyesのドキュメントによると、ブラウザはこのワークフローに必要なカスタムトレースヘッダーを受け入れません。代わりに、HTTP Server または API テストの背後にある計装されたバックエンドエンドポイントを使用してください。
ステップ 1:ワークロードが Splunk APM にトレースを送信していることを確認する
アプリケーションがすでに計装されていて、トレースがSplunk APMに表示されている場合は、ステップ2にスキップできます。そうでない場合、Kubernetesでの最速の学習パスは、ゼロコード計装用のオペレーターを有効にしたSplunk OpenTelemetry Collectorを使用することです。
Splunk OpenTelemetry Collector とオペレーターをインストールする
自動計装用に Deployment にアノテーションを付ける
Javaワークロードの場合、一般的な例は次のようになります:
他のランタイムの場合は、言語に合ったアノテーションを使用してください:
instrumentation.opentelemetry.io/inject-nodejsinstrumentation.opentelemetry.io/inject-pythoninstrumentation.opentelemetry.io/inject-dotnet
コレクターがアプリケーションと同じ名前空間にインストールされている場合、公式のSplunkドキュメントでは "true" をアノテーション値として使用することもサポートしています。
このワークショップ環境の ライブクラスターパターン に従いたい場合、アノテーション値は名前空間修飾され、teastore/default Instrumentationオブジェクトを指します:
トレースが存在することを検証する
デプロイメントのロールアウトが完了するまで待ちます:
複数のサービスを横断するバックエンドエンドポイントに対していくつかのリクエストを生成します。例:
現在のワークショップクラスターでは、
http://teastore-webui.teastore.svc.cluster.local:8080/のようなサービスが適切なターゲットです。これは、いくつかの下流アプリケーションサービスをフロントエンドし、単純なヘルスチェックよりも有用なエンドツーエンドトレースを生成するためです。続行する前に、Splunk APM にトレースが到着していることを確認してください。
学習のヒント
トレーシング演習には、純粋な /health エンドポイントではなく、ビジネストランザクションを使用してください。マルチサービスリクエストは、ThousandEyesでより良いService Mapを提供し、Splunk APMでより有用なトレースを提供します。
ステップ 2:ThousandEyes テストで分散トレーシングを有効にする
ステップ1の計装されたバックエンドエンドポイントをターゲットとする HTTP Server または API テストを作成または編集します。
- ThousandEyesで、HTTP Server または API テストを作成します。
- Advanced Settings を開きます。
- Distributed Tracing を有効にします。
- テストを保存し、すでにSplunk APMにトレースを送信しているのと同じエンドポイントに対して実行します。

テストが実行された後、ThousandEyesはトレースヘッダーを挿入し、そのリクエストのトレースコンテキストをキャプチャします。
ステップ 3:ThousandEyes で Splunk APM コネクターを作成する
前のセクションのメトリックストリーミング統合は Ingest トークンを使用します。このステップは異なります:ThousandEyesはSplunk APMにクエリを実行してトレースリンクを構築する必要があるため、代わりにSplunk API トークンを使用します。
- Splunk Observability Cloudで、API スコープを持つアクセストークンを作成します。
- ThousandEyesで、Manage > Integrations > Integrations 2.0 に移動します。
- 以下の設定で Generic Connector を作成します:
- Target URL:
https://api.<REALM>.signalfx.com - Header:
X-SF-Token: <your-api-scope-token>
- Target URL:
- 新しい Operation を作成し、Splunk Observability APM を選択します。
- オペレーションを有効にして、統合を保存します。


ステップ 4:双方向調査ループを検証する
テストが実行され、コネクターが有効になったら、両方向でワークフローを検証します。
ThousandEyes から始める
- ThousandEyesでテストを開きます。
- Service Map タブに移動します。
- トレースパス、サービスレイテンシー、下流のエラーが表示されることを確認します。
- ThousandEyesから Splunk APM へのリンクを使用して、完全なトレースを検査します。

Splunk APM で続ける
Splunk APM内で、トレースに以下のようなThousandEyesメタデータが含まれていることを確認します:
thousandeyes.account.idthousandeyes.test.idthousandeyes.permalinkthousandeyes.source.agent.id
thousandeyes.permalink フィールドまたはトレースウォーターフォールビューの Go to ThousandEyes test ボタンを使用して、元のThousandEyesテストに戻ります。

推奨される学習シナリオ
ワークショップ中に以下のフローを使用してください:
- 複数のサービスを呼び出す内部APIルートに対するThousandEyesテストを作成します。
- ThousandEyesに最初に問題を表示させ、クラスがネットワークと合成モニタリングの観点から始められるようにします。
- ThousandEyesで Service Map を開き、レイテンシーやエラーがどこから始まるかを特定します。
- スパンレベルの分析のために Splunk APM にジャンプします。
- テスト、エージェント、ネットワークパスを再度検査するために ThousandEyes に戻ります。
これは、異なるチームが実際に作業する方法を反映しているため、強力な教育ループです:
- ネットワークおよびエッジチームは、ThousandEyesから始めることが多いです。
- SREおよびプラットフォームチームは、Splunkダッシュボードまたはアラートから始めることが多いです。
- アプリケーションチームは、通常Splunk APMのトレースを求めます。
この統合が整っていれば、全員がコンテキストを失うことなく切り替えることができます。
よくある落とし穴
- テストがSplunkダッシュボードに表示されていても、トレース相関がない場合があります。これは通常、メトリクス ストリームのみが設定されており、Splunk APM Generic Connector が設定されていないことを意味します。
- 監視対象のエンドポイントがトレースヘッダーを下流に伝播しない場合、トレースがSplunk APMに存在してもThousandEyesに表示されない場合があります。
/healthのような浅いエンドポイントは、設定が正しくても限られたトレース価値しか生成しないことがよくあります。
参考資料
Kubernetes サービステストと相関
20 minutesAppDynamics テスト推奨機能の再現
AppDynamicsには、アプリケーションのエンドポイントに対するシンセティックテストを自動的に提案する「Test Recommendations」という機能があります。ThousandEyesをKubernetesクラスター内にデプロイすることで、KubernetesのサービスディスカバリとSplunk Observability Cloudの統合ビューを組み合わせて、この機能を再現できます。
ThousandEyes Enterprise Agentはクラスター内部で実行されるため、サービス名をホスト名として使用して内部Kubernetesサービスを直接テストできます。これにより、外部に公開されていないバックエンドサービスを監視する強力な方法が得られます。
仕組み
- サービスディスカバリ:
kubectl get svcを使用してクラスター内のサービスを列挙します - ホスト名の構築: Kubernetes DNS命名規則を使用してテストURLを構築します:
<service-name>.<namespace>.svc.cluster.local - テストの作成: 内部サービスに対して可用性テストとトレース対応トランザクションテストの両方を作成します
- Splunk での相関: シンセティックテストの結果をAPMトレースおよびインフラストラクチャメトリクスと並べて表示します
クラスター内テストのメリット
- 内部サービス監視: インターネットに公開されていないバックエンドサービスをテストできます
- サービスメッシュ対応: Istio、Linkerd、その他のサービスメッシュの背後にあるサービスを監視できます
- DNS 解決テスト: Kubernetes DNSとサービスディスカバリを検証できます
- ネットワークポリシー検証: ネットワークポリシーが適切な通信を許可していることを確認できます
- レイテンシベースライン: クラスター内部のネットワークパフォーマンスを測定できます
- 本番前テスト: Ingress/LoadBalancer経由で公開する前にサービスをテストできます
ステップバイステップガイド
1. Kubernetes サービスの検出
クラスター内または特定のnamespace内のすべてのサービスを一覧表示します:
出力例:
2. テストホスト名の構築
Kubernetesサービスは、以下の命名パターンを使用してDNS経由でアクセスできます:
上記のサービスの場合:
api-gateway.production.svc.cluster.local:8080payment-svc.production.svc.cluster.local:8080auth-service.production.svc.cluster.local:9000
同じ namespace 内での省略形: ThousandEyesエージェントと同じnamespace内のサービスをテストする場合は、サービス名のみを使用できます:
api-gateway:8080payment-svc:8080
3. 内部サービス用の ThousandEyes テストの作成
最良の学習成果を得るために、2 種類のテストを作成します:
/healthまたは/readinessエンドポイントに対する可用性テストで、到達可能性と応答時間を検証します- 複数のサービスを横断するビジネスエンドポイントに対するトレース対応トランザクションテスト
最初のテストはシンセティック監視を学ぶためのものです。2番目のテストはSplunk APMを使用したクロスツールトラブルシューティングを学ぶためのものです。
ThousandEyes UI 経由
- Cloud & Enterprise Agents > Test Settings に移動します
- Add New Test → HTTP Server をクリックします
- 可用性テストを設定します:
- Test Name:
[K8s] API Gateway Health - URL:
http://api-gateway.production.svc.cluster.local:8080/health - Interval: 2 minutes
- Agents: KubernetesにデプロイされたEnterprise Agentを選択します
- HTTP Response Code:
200
- Test Name:
- トレース対応トランザクションテストを設定します:
- Test Name:
[Trace] API Gateway Orders - URL:
http://api-gateway.production.svc.cluster.local:8080/api/v1/orders - Interval: 2 minutes
- Agents: KubernetesにデプロイされたEnterprise Agentを選択します
- Advanced Settings > Distributed Tracing: Enabled
- Test Name:
- Create Test をクリックします
ThousandEyes API 経由
トレース対応バージョンの場合は、url をビジネストランザクションエンドポイントに切り替え、ThousandEyesテスト設定でdistributed tracingを有効にします。
ベストプラクティス
distributed tracingを教えることが目的の場合、/health だけを例として使用することは避けてください。ヘルスチェックは稼働時間の監視には便利ですが、ThousandEyesとSplunk APMの統合を魅力的にするマルチサービストレースを生成することはほとんどありません。
4. アラートルールの設定
一般的な障害シナリオに対するアラートを設定します:
- 可用性アラート: HTTPレスポンスが200でない場合にトリガーします
- パフォーマンスアラート: レスポンスタイムがベースラインを超えた場合にトリガーします
- DNS 解決アラート: サービスDNSが解決できない場合にトリガーします
5. Splunk Observability Cloud での結果表示
テストが実行され、Splunkと統合されたら:
- Splunk Observability Cloudで ThousandEyes Dashboard に移動します
- テスト名でフィルターします(例:
[K8s]プレフィックス)、すべてのKubernetes内部テストを表示します - トレース対応テストの場合は、まず ThousandEyes から開始します:
- Service Map を開きます
- サービスレベルのレイテンシとダウンストリームエラーを調べます
- Splunk APM へのリンクをたどります
- APM データとの相関:
- シンセティックテストの失敗をAPMエラー率と並べて表示します
- 問題がネットワーク関連(ThousandEyes)かアプリケーション関連(APM)かを特定します
- Splunkトレースメタデータを使用して、元のThousandEyesテストに戻ります
- 以下を組み合わせたカスタムダッシュボードを作成します:
- ThousandEyes HTTP可用性メトリクス
- APMサービスレイテンシとエラー率
- Kubernetesインフラストラクチャメトリクス(CPU、メモリ、Pod再起動)
ユースケース例
ユースケース 1: マイクロサービスヘルスチェック
複数のマイクロサービスヘルスエンドポイントをテストします:
ユースケース 2: API Gateway エンドポイントテスト
有用なトレースを生成する可能性が高いAPI Gatewayルートをテストします:
ユースケース 3: データベース接続テスト
ThousandEyesは主にHTTPテスト用ですが、データベースプロキシをテストできます:
ユースケース 4: 外部サービス依存関係
クラスター内ThousandEyesエージェントの最も価値のある機能の1つは、サービスと同じネットワークの視点からアプリケーションの外部依存関係を監視することです。これにより、問題がインフラストラクチャ、ネットワークパス、または外部サービス自体のいずれに起因するかを特定できます。
決済ゲートウェイのテスト
重要な決済ゲートウェイエンドポイントの可用性とパフォーマンスを確保するためのテストを作成します:
Stripe API:
PayPal API:
ThousandEyes API 経由:
なぜ外部依存関係を監視するのか?
- プロアクティブな問題検出: 顧客から報告される前に決済ゲートウェイの障害を把握できます
- ネットワークパス検証: Kubernetesエグレスネットワークが外部サービスに到達できることを確認します
- パフォーマンスベースライン: クラスターから外部APIへのレイテンシを追跡します
- コンプライアンスと SLA 監視: サードパーティサービスがSLAコミットメントを満たしていることを確認します
- 根本原因分析: 問題がネットワーク関連か、インフラストラクチャか、外部プロバイダーかを迅速に判断します
監視を推奨する外部サービス
- 決済プロセッサ: Stripe、PayPal、Square、Braintree
- 認証プロバイダー: Auth0、Okta、Azure AD
- メールサービス: SendGrid、Mailgun、AWS SES
- SMS/コミュニケーション: Twilio、MessageBird
- CDN エンドポイント: Cloudflare、Fastly、Akamai
- クラウドストレージ: AWS S3、Google Cloud Storage、Azure Blob Storage
- サードパーティ API: 重要なビジネスパートナー API
ベストプラクティス
テスト名に [External] プレフィックスを使用して、ダッシュボードで内部Kubernetesサービスと外部依存関係を簡単に区別できるようにします。
ベストプラクティス
- 一貫した命名を使用する: フィルタリングを容易にするため、テスト名に
[K8s]または[Internal]プレフィックスを付けます - まずヘルスエンドポイントをテストする: ビジネスロジックをテストする前に
/healthまたは/readinessエンドポイントから始めます - 適切な間隔を設定する: 重要なサービスには短い間隔(1〜2分)を使用します
- テストにタグを付ける: ThousandEyesのラベル/タグを使用してテストをグループ化します:
- 環境(dev、staging、production)
- サービスタイプ(API、database、cache)
- チームオーナーシップ
- テストエージェントの健全性を監視する: ThousandEyesエージェントPodが健全で、十分なリソースがあることを確認します
- 両方のテストタイプを使用する: 各重要なサービスパスに対して、シンプルな可用性テストとトレース対応ビジネストランザクションテストをペアにします
- APM との相関: シンセティックデータとAPMデータを並べて表示するSplunkダッシュボードを作成します
- トレースラボには計装されたバックエンドを使用する: distributed tracingは、ThousandEyesのターゲットがOpenTelemetryで計装されたサービスによってバックアップされたHTTP ServerまたはAPIエンドポイントである場合に最も効果的です
ヒント
内部サービスを外部に公開する前にテストすることで、問題を早期に発見し、ユーザートラフィックが到達する前にインフラストラクチャが健全であることを確認できます。
ThousandEyes と Splunk RUM
10 minutesThousandEyesとSplunk RUMを統合して、ネットワークの問題がエンドユーザーの問題と関連しているかどうかを把握します。
前提条件
- Splunk Observability CloudとThousandEyes両方の管理者権限
- Splunk RUMにデータを送信しているアプリケーションが少なくとも1つ
- Splunk RUMのアプリと同じドメインで、ThousandEyesで以下のタイプのテストが少なくとも1つ実行されていること:
統合手順
- ThousandEyesでOAuth Bearerトークンを作成します:
- 右上隅のユーザー名を選択し、
Profileを選択します。 - User API Tokensの下で
Createを選択してOAuth Bearer Tokenを生成します。 - Observability Cloudのデータ統合ウィザードで使用するため、トークンをコピーまたはメモしておきます。
- 右上隅のユーザー名を選択し、
- Splunk Observability Cloudで、Data Management > Available Integrations > ThousandEyes Integration with RUMを開きます。
- 前回の Splunk 統合で使用したものと同じ
Ingestトークンを使用するか、RUM統合のデータ使用量をより適切に追跡するために専用のIngestトークンを作成して選択します。 - ThousandEyesからのOAuth Bearerトークンを入力します。
- テストのマッチングを確認し、必要に応じて選択を変更し、推定データ取り込み量を確認してから
Doneを選択します。
- 前回の Splunk 統合で使用したものと同じ
統合の確認
ThousandEyesテストが実行されているRUMアプリケーションに移動し、Mapを表示します。
ThousandEyesテストも実行されているロケーションにカーソルを合わせると、ThousandEyesメトリクスのプレビューが表示されます:

ThousandEyesでアクティブなアラートがある場合、RUMの該当するロケーションのバブル上にThousandEyesアイコンが表示されます:

該当するリージョンをクリックすると、RUMの他のメトリクスと一緒にネットワークメトリクスが表示されます。View ThousandEyes Tests を開いてThousandEyesの関連テストに移動できます:

カスタムダッシュボードで RUM と ThousandEyes のメトリクスを表示する
これで、関連するThousandEyesテストからのシグナルと他のObservability CloudのKPIを関連付けることができます!
- Dashboards > “RUM” で検索 >
RUM applicationsグループ内のすぐに使えるRUMダッシュボードの1つをクリックします。 - 興味のあるRUM KPIのチャートをコピーするか、右上のダッシュボードのアクションメニューを開いて
Save Asで自分のダッシュボードグループにコピーを作成します。 - 新しいダッシュボードで、シグナル
network.latencyを使用して新しいチャートを作成します。- extrapolation policyを
Last valueに変更します。 - 測定単位をTime >
Millisecondに変更します。 - Chart Optionsで、
Show on-chart legendを選択し、値をthousandeyes.source.agent.nameにします。これにより、ThousandEyesのエージェントロケーション別にチャートが分割されます。
- extrapolation policyを
- 新しいチャートに名前を付けて保存し、それをコピーして
network.jitterとnetwork.lossの類似チャートを作成します。コピーしたチャートのシグナルでメトリクスを変更し、必要に応じて測定単位と可視化オプションを調整します。
カスタムダッシュボードとチャートの作成に関する詳細なガイダンスは、Dashboard Workshop を参照してください。
ヒント
ThousandEyesのテストメトリクスと並べて表示すると便利なObservability Cloudの他のメトリクスについて考えてみてください。
例えば、SyntheticsでAPIテストを実行している場合は、ロケーション別のAPIテスト成功率のヒートマップを追加することを検討してください。
トラブルシューティング
15 minutesこのセクションでは、KubernetesでThousandEyes Enterprise Agentをデプロイおよび使用する際に遭遇する可能性のある一般的な問題について説明します。
DNS 解決エラーでテストが失敗する
テストがDNS解決エラーで失敗している場合は、ThousandEyes Pod内からDNSを確認してください:
一般的な原因:
- 指定されたnamespaceにサービスが存在しない
- サービス名またはnamespaceの入力ミス
- CoreDNSが正常に機能していない
接続拒否エラー
接続拒否エラーが発生している場合は、以下を確認してください:
一般的な原因:
- サービスをバックアップするPodがない(endpointsが空)
- PodがReady状態でない
- テストURLで間違ったポートが指定されている
- サービスセレクターがPodラベルと一致しない
Network Policy がトラフィックをブロックしている
Network PolicyがThousandEyesエージェントからのトラフィックをブロックしている場合:
解決策:
te-demo namespaceからサービスへのトラフィックを許可するNetwork Policyを作成します:
エージェント Pod が起動しない
ThousandEyesエージェントPodが起動しない場合は、Podのステータスとイベントを確認してください:
一般的な原因:
- リソース不足(memory/CPU)
- 無効または欠落しているTEAGENT_ACCOUNT_TOKENシークレット
- Pod Security Policyによってセキュリティコンテキストのケイパビリティが許可されていない
- イメージプルエラー
解決策:
- OOMKilledの場合はメモリ制限を増やす
- シークレットが正しく作成されているか確認する:
kubectl get secret te-creds -n te-demo -o yaml - Pod Security PolicyがNET_ADMINおよびSYS_ADMINケイパビリティを許可しているか確認する
- イメージプルを確認する:
kubectl describe pod -n te-demo <pod-name>
エージェントが ThousandEyes ダッシュボードに表示されない
エージェントは実行中だがThousandEyesダッシュボードに表示されない場合:
一般的な原因:
- 無効または不正なTEAGENT_ACCOUNT_TOKEN
- ネットワークのEgressがブロックされている(ファイアウォールまたはNetwork Policy)
- エージェントがThousandEyes Cloudサーバーに到達できない
解決策:
- トークンが正しく、適切にbase64エンコードされているか確認する
*.thousandeyes.comへのEgressが許可されているか確認する- エージェントがインターネットに到達できるか確認する:
データが Splunk Observability Cloud に表示されない
ThousandEyesのデータがSplunkに表示されない場合:
統合の設定を確認:
- ThousandEyesでOpenTelemetry統合が正しく設定されているか確認する
- SplunkインジェストエンドポイントURLがお使いのRealmに対して正しいか確認する
X-SF-Tokenヘッダーに有効なSplunkアクセストークンが含まれているか確認する- テストが統合に割り当てられているか確認する
テストの割り当てを確認:
一般的な原因:
- エンドポイントURLのSplunk Realmが間違っている
- 無効または期限切れのSplunkアクセストークン
- テストがOpenTelemetry統合に割り当てられていない
- 統合が適切に有効化または保存されていない
分散トレーシングが ThousandEyes に表示されない
メトリクスストリームは機能しているが、ThousandEyesの Service Map が空であるか、トレースが見つからない場合:
監視対象のエンドポイントを確認:
- HTTPヘッダーを受け入れること
- OpenTelemetryで計装されていること
- トレースコンテキストを下流に伝播すること
- Splunk APMにトレースを送信すること
一般的な原因:
- エンドポイントがHTTP ServerまたはAPIターゲットではなくページURLである
- サービスが計装されていないため、ThousandEyesはヘッダーを注入できるがトレースは出力されない
- エンドポイントがローカルのヘルスレスポンスのみを返し、下流サービスを実行しない
推奨される修正:
- ThousandEyesテストを計装されたバックエンドAPIルートに切り替える
- そのルートのトレースが既にSplunk APMに存在することを確認する
- ThousandEyes分散トレーシングを有効にした後、テストを再実行する
Splunk APM に ThousandEyes リンクが表示されない
トレースがSplunk APMで開くが、ThousandEyesのバックリンクやメタデータが表示されない場合:
一般的な原因:
b3 プロパゲーターが trace_state を上書きし、ThousandEyesがリバースリンクのために保持することを期待している値をクリアする可能性があります。
修正:
計装されたサービスでプロパゲーターを明示的に設定します:
環境変数を変更した後、計装されたワークロードを再起動し、新しいトラフィックを生成します。
Splunk APM Connector の認証エラー
ThousandEyesの Generic Connector がSplunk APMにクエリできない場合:
以下を確認してください:
- コネクターのターゲットが
https://api.<REALM>.signalfx.comであること - コネクターで使用されているトークンが API スコープを持っていること
- トークンを作成するユーザーがSplunk Observability Cloudで必要なロールを持っていること
トークンに関する注意
OpenTelemetryメトリクスストリームはSplunk Ingest トークンを使用します。APM用のThousandEyes Generic Connector はSplunk API トークンを使用します。これらを混同することは、部分的な統合の最も一般的な原因の一つです。
メモリ使用量が高い
ThousandEyesエージェントPodが過剰なメモリを消費している場合:
解決策:
- デプロイメントでメモリ制限を増やす:
- エージェントに割り当てられた同時テストの数を減らす
- エージェントが不要なサービスを実行していないか確認する
Permission Denied エラー
エージェントのログにPermission Deniedエラーが表示される場合:
セキュリティコンテキストを確認:
解決策: Podに必要なケイパビリティがあることを確認します:
注意
厳格なPod Security Policyを持つ一部のKubernetesクラスターでは、これらのケイパビリティが許可されない場合があります。適切なポリシー例外を作成するために、クラスター管理者と協力する必要があるかもしれません。
サポートを受ける
このガイドでカバーされていない問題に遭遇した場合:
- ThousandEyes Support: support.thousandeyes.com でThousandEyesサポートに連絡してください
- Splunk Support: Splunk Observability Cloudの問題については、Splunk Support をご覧ください
- コミュニティフォーラム:
ヒント
サポートを求める際は、より効果的にトラブルシューティングできるよう、関連するログ、Podの説明、エラーメッセージを必ず含めてください。
Isovalent Enterprise Platform と Splunk Observability Cloud の統合
105 minutes Author Alec Chamberlainこのワークショップでは、Isovalent Enterprise Platform と Splunk Observability Cloud を統合し、eBPF テクノロジーを使用して Kubernetes のネットワーキング、セキュリティ、およびランタイム動作に対する包括的な可視性を提供する方法を紹介します。
学習内容
このワークショップを完了すると、以下のことができるようになります
- ENI モードで Cilium を CNI として使用する Amazon EKS のデプロイ
- L7 可視性を備えたネットワークオブザーバビリティのための Hubble の設定
- ランタイムセキュリティモニタリングのための Tetragon のインストール
- OpenTelemetry を使用した eBPF ベースのメトリクスと Splunk Observability Cloud の統合
- 統合ダッシュボードでのネットワークフロー、セキュリティイベント、インフラストラクチャメトリクスのモニタリング
- eBPF を活用したオブザーバビリティと kube-proxy の置き換えの理解
セクション
- 概要 - Cilium アーキテクチャと eBPF の基礎を理解する
- 前提条件 - 必要なツールとアクセス
- EKS セットアップ - Cilium 用の EKS クラスターを作成する
- Cilium インストール - Cilium、Hubble、Tetragon をデプロイする
- Splunk 統合 - メトリクスを Splunk Observability Cloud に接続する
- 検証 - 統合を検証する
- デモスクリプト - エンドツーエンドの DNS 調査シナリオを実施する
ヒント
この統合では、Linux カーネル内で直接動作する高パフォーマンス・低オーバーヘッドのオブザーバビリティのために eBPF(Extended Berkeley Packet Filter)を活用しています。
前提条件
- 適切な認証情報が設定された AWS CLI
- kubectl、eksctl、および Helm 3.x がインストール済みであること
- EKS クラスター、VPC、EC2 インスタンスを作成する権限を持つ AWS アカウント
- アクセストークンを持つ Splunk Observability Cloud アカウント
- 完全なセットアップに約90分
統合のメリット
Isovalent Enterprise Platform を Splunk Observability Cloud に接続することで、以下のメリットが得られます
- 🔍 詳細な可視性: ネットワークフロー、L7 プロトコル(HTTP、DNS、gRPC)、およびランタイムセキュリティイベント
- 🚀 高パフォーマンス: 最小限のオーバーヘッドによる eBPF ベースのオブザーバビリティ
- 🔐 セキュリティインサイト: プロセスモニタリング、システムコールトレーシング、およびネットワークポリシーの適用
- 📊 統合ダッシュボード: インフラストラクチャおよび APM データと並んだ Cilium、Hubble、Tetragon のメトリクス
- ⚡ 効率的なネットワーキング: kube-proxy の置き換えと ENI モードによるネイティブ VPC ネットワーキング
ソースリポジトリ
このワークショップで参照されるすべての設定ファイル、Helm values、およびダッシュボード JSON ファイルは、以下のリポジトリで利用できます
- isovalent_splunk_o11y — Helm values、OTel Collector 設定、Splunk ダッシュボード JSON ファイル、および完全な統合ガイド
- isovalent-demo-jobs-app — デモシナリオで使用される jobs-app Helm チャート(エラーインジェクションおよび修復スクリプトを含む)
Isovalent Splunk Observability 統合のサブセクション
Cilium のインストール
ステップ 1: Cilium Enterprise の設定
cilium-enterprise-values.yaml という名前のファイルを作成します。<YOUR-EKS-API-SERVER-ENDPOINT> を前のステップで取得したエンドポイントに置き換えてください(https:// プレフィックスは除きます)。
ラベルコンテキストが重要な理由
各Hubbleメトリクスの labelsContext および sourceContext/destinationContext パラメータは、メトリクスをどのディメンションで分割するかを制御します。labelsContext=source_namespace,destination_namespace を設定すると、すべてのメトリクスにこれら2つのラベルが付与され、カーディナリティの爆発を起こすことなくSplunkでnamespaceによるフィルタリングが可能になります。workload-name|reserved-identity のフォールバックチェーンは、利用可能な場合はワークロード名を使用し、利用できない場合はセキュリティIDにフォールバックすることを意味します。
ステップ 2: Cilium Enterprise のインストール
新しいノードがEKSクラスターに参加すると、そのノードのkubeletはすぐにCNIプラグインを探してネットワーキングをセットアップします。/etc/cni/net.d/ に存在するCNI設定を読み取り、それを使用してノードを初期化します。ノードグループを先に作成すると、AWS VPC CNI が最初に到達します — そして一度ノードが特定のCNIで初期化されると、別のCNIに切り替えるにはノードをドレインして再初期化する必要があります。
ノードが存在する前にCiliumをインストールすることで、CiliumのCNI設定が kube-system に既に存在し、ノードが起動した瞬間にピックアップされる準備ができていることを保証します。EC2インスタンスが起動すると、CiliumのDaemonSet Podがすぐにスケジュールされ、eBPFプログラムがロードされ、ノードは最初の瞬間からCiliumの制御下で Ready 状態になります。
これは、EKSセットアップのステップ3でクラスターが disableDefaultAddons: true で作成された理由でもあります — これがないと、AWS VPC CNIが自動的にインストールされ、Ciliumと競合することになります。
Helmを使用してCiliumをインストールします:
Pending状態のジョブは正常です
インストール後、いくつかのジョブがPending状態になっているのが見えます — これは正常です。CiliumのHelmチャートにはHubble用のTLS証明書を生成するジョブが含まれており、そのジョブを実行するにはノードが必要です。次のステップでノードが利用可能になると、自動的に完了します。
ステップ 3: ノードグループの作成
nodegroup.yaml という名前のファイルを作成します:
ノードグループを作成します(5〜10分かかります):
ステップ 4: Cilium インストールの確認
ノードの準備ができたら、すべてのコンポーネントを確認します:
期待される出力:
- 2つのノードが
Ready状態 - Cilium Podが実行中(ノードごとに1つ)
- Hubble relayとtimescapeが実行中
- Cilium operatorが実行中
ステップ 5: 拡張ネットワークオブザーバビリティを備えた Tetragon のインストール
Tetragonはそのままでもランタイムセキュリティとプロセスレベルの可視性を提供します。Splunkとの統合 — 特にNetwork Explorerダッシュボード — には、TCP/UDPソケット統計、RTT、接続イベント、DNSをカーネルレベルで追跡する拡張ネットワークオブザーバビリティモードも有効にする必要があります。
tetragon-network-values.yaml という名前のファイルを作成します:
これらの値でTetragonをインストールします:
インストールを確認します:
表示される内容: TetragonはDaemonSet(ノードごとに1つのPod)とオペレーターとして実行されます。
拡張ネットワークオブザーバビリティが追加するもの
layer3.tcp.rtt.enabled: true を設定すると、TetragonはカーネルのTCPソケット状態にフックし、ラウンドトリップタイム、再送回数、送受信バイト数、セグメント数を含む接続ごとのメトリクスを記録します。これらはSplunkのNetwork Explorerのレイテンシとスループットビューを動かす tetragon_socket_stats_* メトリクスに供給されます。これがないとイベントカウントのみが取得されますが、これがあると接続品質データが取得できます。
TracingPolicies(TCP接続追跡、HTTP可視性など)は、上記のHelm valuesで tetragonOperator.tracingPolicy.enabled: true が設定されている場合、Tetragon Operatorによって自動的に管理されます。
ステップ 6: Cilium DNS Proxy HA のインストール
cilium-dns-proxy-ha-values.yaml という名前のファイルを作成します:
DNS Proxy HAをインストールします:
確認します:
成功
これでCilium CNI、Hubbleオブザーバビリティ、Tetragonセキュリティを備えた完全に機能するEKSクラスターが完成しました!
Splunk Integration
概要
Splunk OpenTelemetry Collectorは、Prometheusレシーバーを使用してすべてのIsovalentコンポーネントからメトリクスをスクレイプします。各コンポーネントは異なるポートでメトリクスを公開しており、CiliumとHubbleは同じPodを共有しています(ポートが異なるだけです)。そのため、Podアノテーションに依存するのではなく、各コンポーネントに対して個別のレシーバーを設定します。
| コンポーネント | ポート | 提供する情報 |
|---|---|---|
| Cilium Agent | 9962 | eBPF データパス、ポリシー適用、IPAM、BPF マップ統計 |
| Cilium Envoy | 9964 | L7 プロキシメトリクス(HTTP、gRPC) |
| Cilium Operator | 9963 | クラスター全体のアイデンティティとエンドポイント管理 |
| Hubble | 9965 | ネットワークフロー、DNS、HTTP L7、TCP フラグ、ポリシー判定 |
| Tetragon | 2112 | ランタイムセキュリティ、ソケット統計、ネットワークフローイベント |
ステップ 1: 設定ファイルの作成
splunk-otel-collector-values.yaml という名前のファイルを作成します。認証情報のプレースホルダーを実際の値に置き換えてください。
重要: 以下を置き換えてください:
<YOUR-SPLUNK-ACCESS-TOKEN>をSplunk Observability Cloudのアクセストークンに<YOUR-SPLUNK-REALM>をレルム(例: us1、us2、eu0)に
厳格なメトリクス許可リストを使用する理由
Ciliumは、ワークロード、名前空間、プロトコルの詳細に関するすべてのラベルの組み合わせを考慮すると、数千のユニークなメトリクスシリーズを出力する可能性があります。filter/includemetrics 許可リストがないと、負荷の高いクラスターでは50,000以上のアクティブシリーズが簡単に生成され、Splunkのインジェストに過負荷をかける可能性があります。上記のリストは、CiliumとHubbleのダッシュボードを動作させるために必要なメトリクスと、Network Explorerに必要なTetragonソケット統計を正確に含むようにキュレートされています。後で新しいダッシュボードを追加する場合は、このリストにメトリクスを追加できます。
Tetragonソケット統計で可能になること
tetragon_socket_stats_* メトリクスは、SplunkのNetwork Explorerで接続ごとのレイテンシとスループット分析を可能にするものです。srtt_count/srtt_sum は、ワークロードごとの平均TCPラウンドトリップタイムを提供します。retransmitsegs_total は、パケットロスと輻輳を表面化します。txbytes/rxbytes は、接続ごとの帯域幅を示します。これらはAPMや標準のインフラストラクチャメトリクスでは確認できません。
ステップ 2: Splunk OpenTelemetry Collector のインストール
コレクターをインストールします:
ロールアウトが完了するまで待ちます:
ステップ 3: メトリクス収集の確認
コレクターがメトリクスをスクレイプしていることを確認します:
各コンポーネントのスクレイプが成功していることを示すログエントリが表示されるはずです。
次のステップ
メトリクスがSplunk Observability Cloudに送信されています!ダッシュボードを確認するには、検証に進んでください。
デモ — Isovalent と Splunk を使用した DNS 問題の調査
このデモで示すこと
このデモは、すべての運用チームやプラットフォームチームが経験したことのあるストーリーを語ります。何かが壊れていて、ユーザーが不満を訴えていて、どこから始めればよいかわからない状況です。調査は通常の最初のステップを経由します — APMは問題なさそう、インフラストラクチャも問題なさそう — そしてネットワーク層へとピボットします。そこでIsovalentのHubbleオブザーバビリティがSplunkに流れ込み、本当の問題を明らかにします。それは他のすべてのツールからは完全に見えなかったDNS過負荷です。
アプリケーションは jobs-app で、tenant-jobs namespaceで実行されるシミュレートされたマルチサービスの採用プラットフォームです。フロントエンド(recruiter、jobposting)、中央API(coreapi)、バックグラウンドデータパイプライン(Kafka + resumes + loader)、および定期的にインターネットへHTTP呼び出しを行う crawler サービスがあります。このcrawlerがこのストーリーの悪役になります。
重要なポイント
APMとインフラストラクチャのメトリクスは正常に見えます。根本原因であるDNS過負荷は、アプリケーション層より下に存在するため、SplunkのIsovalent Hubbleダッシュボードを通じてのみ見ることができます。
開始前の準備
これは誰もいない状態で行ってください。デモが始まるときには、クリーンで正常なダッシュボードの前に座っていたいものです — 人々が見ている中でkubectlをいじっているのではなく。
Jobs App のデプロイ
まだ行っていない場合は、isovalent-demo-jobs-app リポジトリからjobs-app Helm chartをデプロイします。
すべてが実行中であることを確認
デモ中に驚かないよう、これらのチェックを実行します。
重要
続行する前に、すべてのPodが Running 状態である必要があります。OTel Collectorが起動していない場合、Splunkにメトリクスが表示されず、デモが成功しません。
アプリを正常なベースラインにリセット
crawlerが穏やかで通常のペースで実行されていることを確認します — 1レプリカ、0.5から5秒ごとにクロール:
その後、少なくとも 5 分待ちます。Splunkがクリーンなベースラインを取り込む時間が必要で、これから作成するスパイクが視覚的に明らかになります。これをスキップすると、チャートが明確なストーリーを伝えません。
問題を注入
デモ開始の約5〜10分前(または効果を出すためにデモ中にライブで)、以下を実行します:
これによりcrawlerが1 Podから5にスケールアップし、クロール間隔が0.2〜0.3秒に短縮されます。各crawler Podは api.github.com にHTTPリクエストを行い、それらのリクエストごとに最初にDNSルックアップが必要です。5つのPodが毎秒複数回DNSを叩くと、約15〜25のDNSクエリが持続的に発生します — DNSプロキシを飽和させ、応答レイテンシを蓄積させるのに十分な量です。DNSに依存するnamespace内の他のサービスが断続的な障害を経験し始めます。これがまさにチケットに記載されている内容です。
Act 1 — チケットが届く
まず状況を描写します。まだ何もクリックする必要はありません — シーンを設定するだけです。
「普通の午後で、ITSM チケットが届きました。jobs アプリケーションチームから、エンドユーザーが recruiter と job posting ページで断続的な 500 エラーを報告していて、過去 15 分ほどでロード時間が明らかに悪化したと言っています。P2 にエスカレートされました。調査しましょう。」
| チケット | INC-4072 |
| 優先度 | P2 — 高 |
| 概要 | jobs-app での断続的な障害と応答時間の遅延 |
| 説明 | Recruiter と job posting ページが断続的に 500 エラーを返しています。ユーザーは過去 15 分間でページロードが大幅に遅くなったと報告しています。エンジニアリングは最近のデプロイメントを行っていません。 |
| 報告者 | アプリケーションサポートチーム |
| 影響を受ける namespace | tenant-jobs |
「最近のデプロイメントはない — これが実は興味深い点です。責めるべき明らかな変更イベントがありません。だから自分たちで何が変わったかを把握する必要があります。どこから始めましょう?APM です。」
Act 2 — APM を確認(行き止まり)
ここはほとんどの人が最初に行くところで、それがポイントです。APMを表示し、役に立たないことを見つけ、それを使ってより深いものが必要であるケースを構築します。
移動先: Splunk Observability Cloud → APM → Service Map
tenant-jobs 環境のサービスマップはトポロジーを示します:recruiter と jobposting は両方とも coreapi を呼び出し、coreapiはElasticsearchに接続します。resumes と loader サービスはバックグラウンドでKafkaを介して通信します。
「これがサービスマップです。すべてのサービスが点灯しています — すべて応答していて、すべて接続されています。数字が実際に何を示しているか見てみましょう。
リクエストレートは正常に見えます。レイテンシはわずかに上昇しているかもしれませんが、ユーザー向けのエラーを説明するほどのものではありません。coreapi のエラーレートを見てください — 約 10% です。これが問題だと思うかもしれませんが、そうではありません。このアプリはセットアップの一部として設定可能なエラーレートが組み込まれています。10 パーセントはベースラインであり、リグレッションではありません。
つまり APM が教えてくれるのは:サービスは生きていて、トラフィックは流れていて、エラーレートは変化していないということです。アプリケーショントレースには根本原因を示すものがありません。インフラストラクチャを試してみましょう。」
なぜAPMではこれが見えないのか
APMはアプリケーションコードを計装します — サービス内部で何が起こっているかを観察します。接続が確立される前にネットワーク層で何が起こっているかは見えません。DNS解決、接続の切断、パケットレベルのイベントは、設計上APMからは見えません。
Act 3 — インフラストラクチャを確認(行き止まり)
インフラを表示し、クリーンであることを見つけ、聴衆にまだ答えがないフラストレーションを感じさせます。
移動先: Splunk Observability Cloud → Infrastructure → Kubernetes → Cluster: isovalent-demo
「クラスター自体を見てみましょう。何かリソースが制約されているかもしれません — ノードが高負荷、Pod が OOMKilled されている、そのようなことです。
両方のノードは正常に見えます。CPU とメモリは正常範囲内です。Pod を掘り下げると — すべて Running 状態で、再起動なし、退去もされていません。コンテナ自体もリソース制限に達していません。
これで少し不快な状況になりました。チケットにはユーザーがエラーを見ていると書いてあります。APM はアプリが実行中だと言っています。インフラストラクチャはクラスターが正常だと言っています。これでどうなりますか?
これは実際に非常によくある状況です。アプリケーション層より下、インフラストラクチャ層より下に存在する問題のクラス全体があります — 従来のモニタリングツールでは単純に見えないネットワークレベルで起こっていること。DNS 障害、接続の切断、ポリシー拒否、トラフィックの非対称性。これらはトレースや Pod メトリクスには現れません。ネットワーク自体を観察できるものが必要です。そこで Isovalent の出番です。」
Act 4 — ネットワークが真実を語る
これがデモの核心です。ここはゆっくり時間をかけてください。
移動先: Splunk Observability Cloud → Dashboards → Hubble by Isovalent
「Cilium — 私たちの CNI、すべてのノードで実行されているネットワーキング層 — には Hubble という組み込みのオブザーバビリティコンポーネントがあります。Hubble は eBPF を使用してクラスター内のすべてのネットワークフローをリアルタイムで監視します。サンプリングではなく、近似でもなく — すべての接続、すべての DNS リクエスト、すべてのパケットドロップ。そして OpenTelemetry Collector がそれらの Hubble メトリクスをスクレイプして Splunk に転送するように設定しているので、APM やインフラストラクチャを見ていたのと同じプラットフォームでそれらすべてを見ることができます。
Hubble ダッシュボードを表示しましょう。」
DNS クエリが制御不能
DNS Queries チャートを指し、次に DNS Overview タブに移動します。
「ありました。DNS クエリ量を見てください — 約 15 分前に急激にスパイクしています。このタイムスタンプはチケットが開かれた時間とぴったり一致します。
見ているのは
hubble_dns_queries_totalで、ソース namespace ごとに分類されています。スパイクは完全にtenant-jobs— アプリケーション namespace から来ています。アプリケーション内の何かが大量の DNS トラフィックを生成し始め、DNS プロキシが追いつくのに苦労し始めました。しかし右下を見てください — Missing DNS Responses チャートです。これはアラートが発火しているものです。値が深くマイナスになっています。これは DNS クエリが送信されているのに、応答が一度も戻ってこないことを意味します。DNS プロキシが圧倒され、接続は静かにタイムアウトしています。これがユーザーの 500 エラーとして現れている波及効果です。」
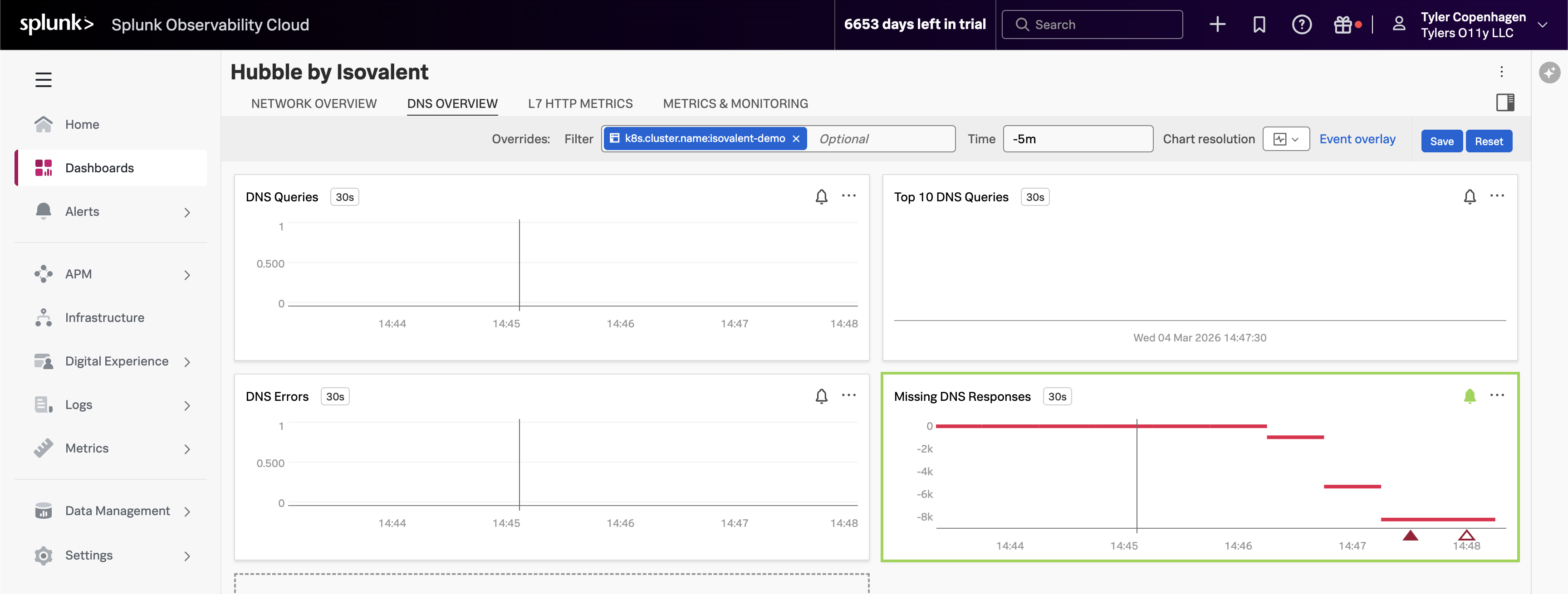
トップ DNS クエリが原因を明らかに
Top 10 DNS Queries チャートを指します。
「これらすべての DNS リクエストを行っているものを特定しましょう。Top 10 DNS Queries チャートは最も頻繁にクエリされるドメインを分類しており、1 つの名前が圧倒的に目立っています:
api.github.com。これはクラスター内部のサービスではありません — 外部エンドポイントです。そしてアプリ内で外部エンドポイントと通信するのは crawler サービスだけです。crawler はジョブシミュレーションの一部として外部 URL への HTTP 呼び出しを行います。その HTTP 呼び出しを行うたびに、最初に DNS を通じて
api.github.comを解決する必要があります。通常これは問題ありません。1 つの crawler Pod が数秒ごとにリクエストを行うのは完全に管理可能です。しかし、どれだけ積極的に実行されているかについて何かが明らかに変化しています。」
ドロップされたフローが影響範囲を示す
Dropped Flows チャートを指します。
「Dropped Flows チャートは別の注目すべきことを示しています。Hubble は成功した接続だけを追跡するのではありません — 拒否またはドロップされたすべての接続と、その理由コードをキャプチャします。DNS スパイクと全く同じ時間にドロップの増加が見られます。
これらのドロップは DNS 過負荷の下流の結果です。namespace 内のサービスが接続を試み、DNS が遅すぎるか失敗すると、それらの接続試行はタイムアウトしてドロップされます。これが APM がレイテンシの上昇として見ていたものです — しかし APM にはその下に DNS 問題があることは全くわかりませんでした。」
ネットワークフロー量がパターンを確認
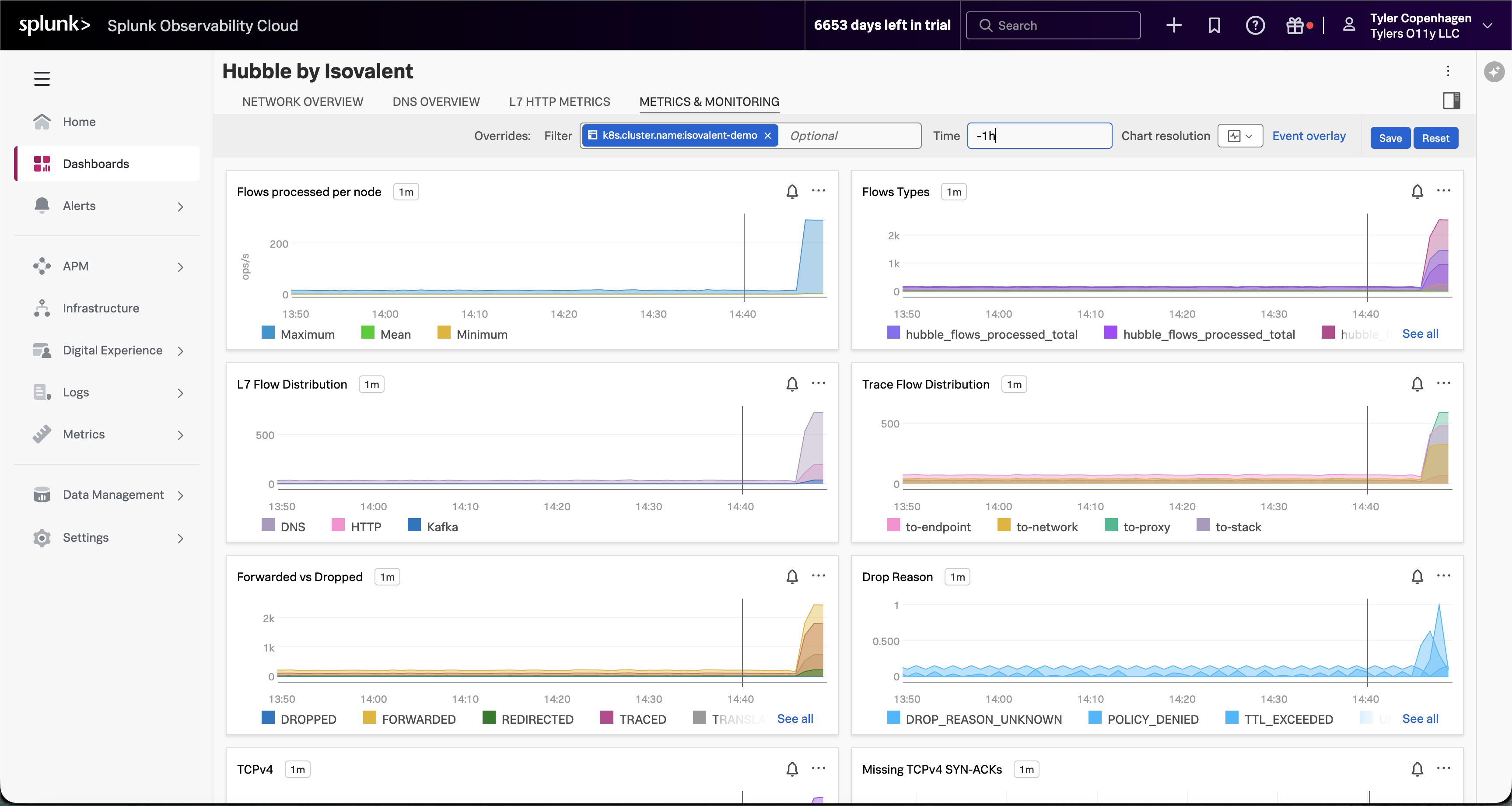
Metrics & Monitoring タブに移動します。
「そして Metrics & Monitoring タブを見ると、全体像がさらに明確になります。ノードごとの処理フロー数が垂直に上昇しています — これは生のネットワークトラフィック量です。Forwarded vs Dropped チャートは、それらのフローのかなりの割合が転送されずにドロップされていることを示しています。そして Drop Reason の内訳は、TTL_EXCEEDED と DROP_REASON_UNKNOWN の混合であることを教えてくれます — DNS タイムアウトがカスケードし始めたときにまさに予想されるものです。特定の時点で何かが変わり、その時点以降のすべてがベースラインとは異なって見えます。」
L7 HTTP トラフィックが興味深いストーリーを語る
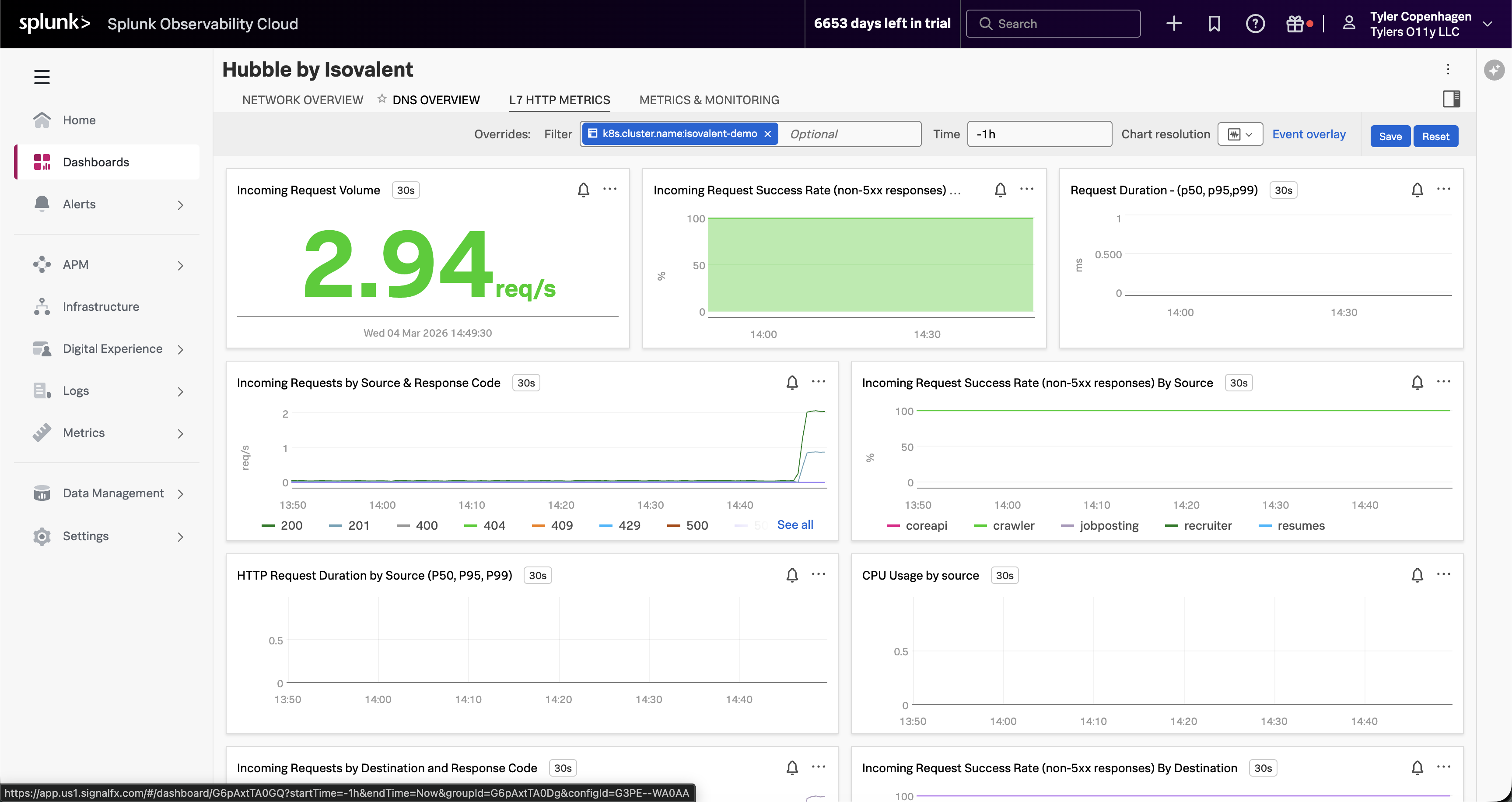
L7 HTTP Metrics タブに移動します。
「L7 HTTP Metrics タブで指摘する価値のあることがあります。これは実際に APM が役に立たなかった理由を補強するからです。受信リクエスト量はゼロではありません — トラフィックはまだ流れています。成功率チャートはほとんど緑に見えます。HTTP レベルの可視性だけを見ていた場合、アプリは問題ないと結論づけるかもしれません。
しかし Incoming Requests by Source チャートを見てください。crawler が不釣り合いなシェアのトラフィックを生成しています — 他のサービスから分離しているのが見えます。HTTP 呼び出しを成功させているので、APM はフラグを立てません。問題は 1 つ下の層、DNS で、HTTP 接続が確立される前に起こっています。」
Act 5 — 根本原因の確認
ここで点と点をつなぎ、証明します。
「これが全体像です:ある時点で、crawler サービスが 1 レプリカから 5 にスケールアップされ、クロール間隔が非常に積極的に設定されました — 0.2 から 0.3 秒ごと。これは 5 つの Pod が、それぞれ
api.github.comを解決するために DNS ルックアップを毎秒複数回発火させています。合計すると、毎秒 15 から 25 の DNS クエリが持続的に発生します。DNS プロキシは単一のワークロードからそのような負荷を処理するようには作られていないので、キューイング、スローダウン、そして最終的にはリクエストのドロップを開始します。DNS 解決を必要とする namespace 内の他のすべてのサービスが巻き添えを食います。それが何を見ているか確認しましょう。」
オプションとして、Cilium by Isovalent dashboard → Policy: L7 Proxy タブに切り替えます。
「Hubble 側ではなく Cilium 側からこれを見たい場合は、Cilium by Isovalent dashboard に切り替えて Policy: L7 Proxy タブを見てください。FQDN の L7 Request Processing Rate — これが DNS です — が 21,000 リクエストを超えています。これは分あたりではありません。DNS プロキシは非常に大量の FQDN ルックアップを処理しており、すべて受信されて転送されているため、バックアップし始めました。このビューは DNS Proxy Upstream Reply レイテンシも表示しており、プロキシが圧力下にあることを確認できます。」
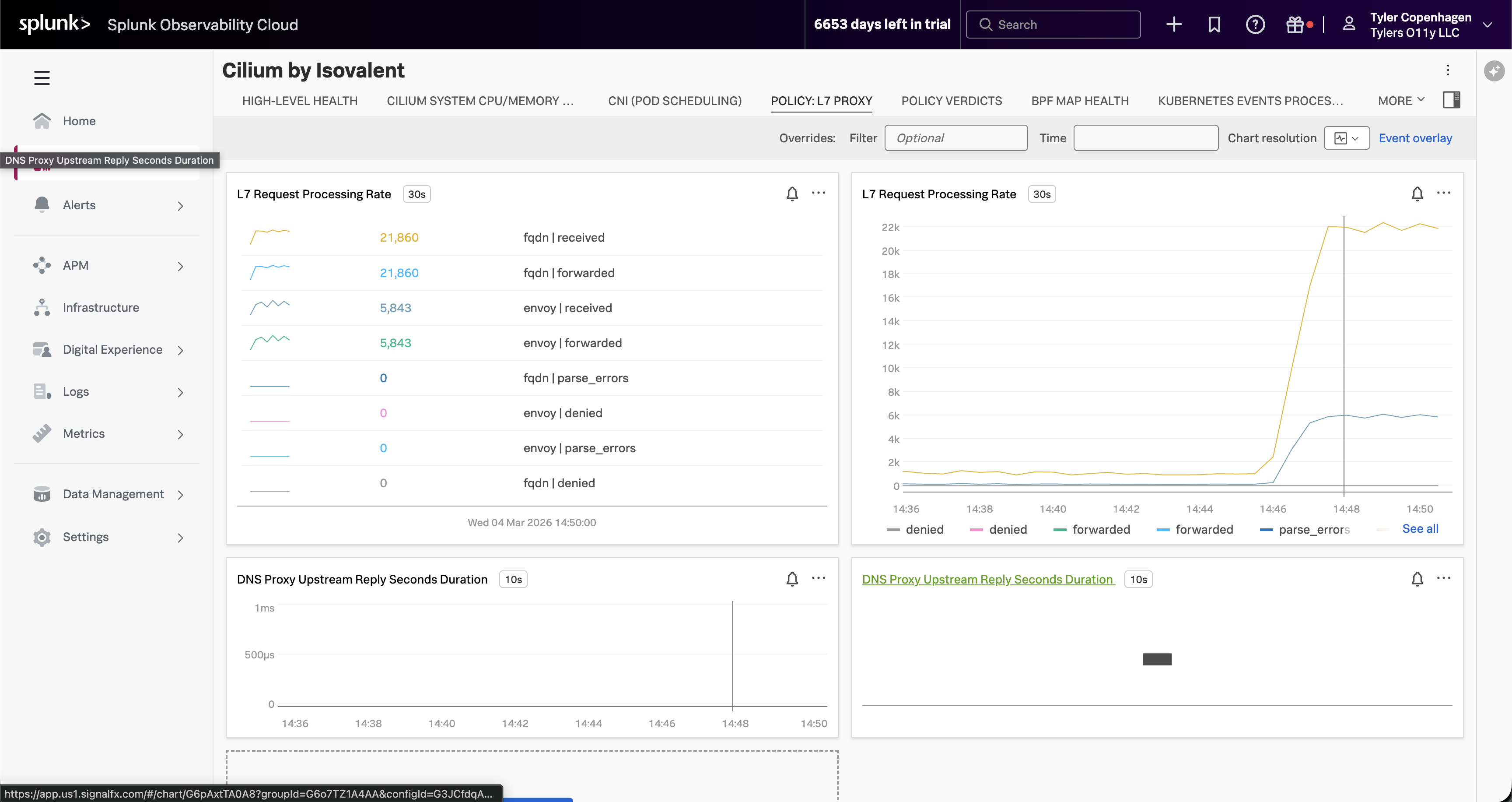
「ありました。5 レプリカ、0.2 から 0.3 秒ごとにクロール。
APM ではこれが見えません。コードを計装しているのであって、DNS ではないからです。インフラストラクチャモニタリングでもこれは見えません。Pod は正常です — 設定されたとおりに正確に動作しています。これをキャッチできる唯一のツールは、eBPF レベルで動作し、すべてのパケット、すべての DNS リクエスト、すべての接続試行をリアルタイムで監視するものです。それが Hubble です。そして Splunk に接続しているので、他のすべてに使用しているのと同じダッシュボードでキャッチしました。」
Act 6 — ライブで修正
この部分は満足感があります。チャートがリアルタイムで回復するのを見ることができるからです。
「修正は簡単です — crawler をスケールダウンして、通常のクロール間隔を復元します。」
Hubble by Isovalent ダッシュボードに戻り、1分ほど待ちます。
「DNS Queries チャートを見てください — ほぼ即座に下がってくるのが見えます。1〜2 分以内にベースラインに戻ります。ドロップされたフローはゼロになります。ネットワークフロー量は通常に戻ります。
そして今 APM に戻ると、レイテンシが正常化し、エラーレートが予想される 10% のベースラインに落ち着くのが見えるでしょう。
チケットをクローズできます。根本原因:crawler の設定ミスによる DNS 飽和。解決策:Helm を使用して crawler のレプリカ数とクロール間隔を元に戻す。解決までの時間:チケットが開かれてから約 15 分。」
修復完了
DNSクエリレートがベースラインに戻り、ドロップされたフローがクリアされ、アプリケーションの健全性が回復します — すべてHubbleダッシュボードでライブで確認できます。
Act 7 — これが実際に意味すること
ズームアウトして、価値のステートメントを具体的に感じさせて終わります。
「ここで何が起こったか考えてみましょう。本番スタイルの本当の問題がありました — エンドユーザーにとって何かが壊れていて — 標準的なプレイブックを経由しました。APM は何も問題ないと言いました。インフラストラクチャも何も問題ないと言いました。Hubble がなければ、次のステップはおそらく戦争部屋の通話、ログを見つめる人々、namespace 全体の再起動を期待して行うことだったでしょう。
代わりに、Hubble ダッシュボードを開いた瞬間から 3 分以内に見つけました。私たちが賢いからではなく、正しい層への可視性があったからです。
これが機能する理由は eBPF です。Cilium の Hubble コンポーネントは Linux カーネルにフックし、ソースでネットワークイベントを観察します — アプリケーションコードに到達する前に、Pod ログに現れる前に、APM のトレースになる前に。そして OpenTelemetry Collector を通じてそれらのメトリクスを Splunk に送信することで、APM データやインフラストラクチャデータと同じプラットフォームに並んでいます。ツールを切り替えたり、5 つの異なるダッシュボード間でコンテキストスイッチする必要はありません。以前なかった可視性の層を追加し、チームがすでに知っているワークフローに保持します。
これがストーリーです。ネットワークオブザーバビリティはニッチなニーズではありません — APM とインフラストラクチャモニタリングが残すギャップです。Isovalent がそのギャップを埋め、Splunk でそれを見ることができます。」
クイックリファレンス
問題を注入(デモの約10分前に実行):
修復(Act 6でライブ実行):
設定ミスを確認:
Splunk ナビゲーションパス: APM → Service Map → (クリーンであることを表示) → Infrastructure → Kubernetes → (クリーンであることを表示) → Dashboards → Hubble by Isovalent → (DNS スパイクを表示)
タイミングガイド
| セクション | 概算時間 |
|---|---|
| Act 1 — チケット | 約 1 分 |
| Act 2 — APM(行き止まり) | 約 2〜3 分 |
| Act 3 — インフラストラクチャ(行き止まり) | 約 1〜2 分 |
| Act 4 — Hubble ダッシュボード | 約 4〜5 分 |
| Act 5 — 根本原因の確認 | 約 2 分 |
| Act 6 — ライブで修正 | 約 2 分 |
| Act 7 — 価値のまとめ | 約 2 分 |
| 合計 | 約 14〜17 分 |