デモ — Isovalent と Splunk を使用した DNS 問題の調査
このデモで示すこと
このデモは、すべての運用チームやプラットフォームチームが経験したことのあるストーリーを語ります。何かが壊れていて、ユーザーが不満を訴えていて、どこから始めればよいかわからない状況です。調査は通常の最初のステップを経由します — APMは問題なさそう、インフラストラクチャも問題なさそう — そしてネットワーク層へとピボットします。そこでIsovalentのHubbleオブザーバビリティがSplunkに流れ込み、本当の問題を明らかにします。それは他のすべてのツールからは完全に見えなかったDNS過負荷です。
アプリケーションは jobs-app で、tenant-jobs namespaceで実行されるシミュレートされたマルチサービスの採用プラットフォームです。フロントエンド(recruiter、jobposting)、中央API(coreapi)、バックグラウンドデータパイプライン(Kafka + resumes + loader)、および定期的にインターネットへHTTP呼び出しを行う crawler サービスがあります。このcrawlerがこのストーリーの悪役になります。
重要なポイント
APMとインフラストラクチャのメトリクスは正常に見えます。根本原因であるDNS過負荷は、アプリケーション層より下に存在するため、SplunkのIsovalent Hubbleダッシュボードを通じてのみ見ることができます。
開始前の準備
これは誰もいない状態で行ってください。デモが始まるときには、クリーンで正常なダッシュボードの前に座っていたいものです — 人々が見ている中でkubectlをいじっているのではなく。
Jobs App のデプロイ
まだ行っていない場合は、isovalent-demo-jobs-app リポジトリからjobs-app Helm chartをデプロイします。
すべてが実行中であることを確認
デモ中に驚かないよう、これらのチェックを実行します。
重要
続行する前に、すべてのPodが Running 状態である必要があります。OTel Collectorが起動していない場合、Splunkにメトリクスが表示されず、デモが成功しません。
アプリを正常なベースラインにリセット
crawlerが穏やかで通常のペースで実行されていることを確認します — 1レプリカ、0.5から5秒ごとにクロール:
その後、少なくとも 5 分待ちます。Splunkがクリーンなベースラインを取り込む時間が必要で、これから作成するスパイクが視覚的に明らかになります。これをスキップすると、チャートが明確なストーリーを伝えません。
問題を注入
デモ開始の約5〜10分前(または効果を出すためにデモ中にライブで)、以下を実行します:
これによりcrawlerが1 Podから5にスケールアップし、クロール間隔が0.2〜0.3秒に短縮されます。各crawler Podは api.github.com にHTTPリクエストを行い、それらのリクエストごとに最初にDNSルックアップが必要です。5つのPodが毎秒複数回DNSを叩くと、約15〜25のDNSクエリが持続的に発生します — DNSプロキシを飽和させ、応答レイテンシを蓄積させるのに十分な量です。DNSに依存するnamespace内の他のサービスが断続的な障害を経験し始めます。これがまさにチケットに記載されている内容です。
Act 1 — チケットが届く
まず状況を描写します。まだ何もクリックする必要はありません — シーンを設定するだけです。
「普通の午後で、ITSM チケットが届きました。jobs アプリケーションチームから、エンドユーザーが recruiter と job posting ページで断続的な 500 エラーを報告していて、過去 15 分ほどでロード時間が明らかに悪化したと言っています。P2 にエスカレートされました。調査しましょう。」
| チケット | INC-4072 |
| 優先度 | P2 — 高 |
| 概要 | jobs-app での断続的な障害と応答時間の遅延 |
| 説明 | Recruiter と job posting ページが断続的に 500 エラーを返しています。ユーザーは過去 15 分間でページロードが大幅に遅くなったと報告しています。エンジニアリングは最近のデプロイメントを行っていません。 |
| 報告者 | アプリケーションサポートチーム |
| 影響を受ける namespace | tenant-jobs |
「最近のデプロイメントはない — これが実は興味深い点です。責めるべき明らかな変更イベントがありません。だから自分たちで何が変わったかを把握する必要があります。どこから始めましょう?APM です。」
Act 2 — APM を確認(行き止まり)
ここはほとんどの人が最初に行くところで、それがポイントです。APMを表示し、役に立たないことを見つけ、それを使ってより深いものが必要であるケースを構築します。
移動先: Splunk Observability Cloud → APM → Service Map
tenant-jobs 環境のサービスマップはトポロジーを示します:recruiter と jobposting は両方とも coreapi を呼び出し、coreapiはElasticsearchに接続します。resumes と loader サービスはバックグラウンドでKafkaを介して通信します。
「これがサービスマップです。すべてのサービスが点灯しています — すべて応答していて、すべて接続されています。数字が実際に何を示しているか見てみましょう。
リクエストレートは正常に見えます。レイテンシはわずかに上昇しているかもしれませんが、ユーザー向けのエラーを説明するほどのものではありません。coreapi のエラーレートを見てください — 約 10% です。これが問題だと思うかもしれませんが、そうではありません。このアプリはセットアップの一部として設定可能なエラーレートが組み込まれています。10 パーセントはベースラインであり、リグレッションではありません。
つまり APM が教えてくれるのは:サービスは生きていて、トラフィックは流れていて、エラーレートは変化していないということです。アプリケーショントレースには根本原因を示すものがありません。インフラストラクチャを試してみましょう。」
なぜAPMではこれが見えないのか
APMはアプリケーションコードを計装します — サービス内部で何が起こっているかを観察します。接続が確立される前にネットワーク層で何が起こっているかは見えません。DNS解決、接続の切断、パケットレベルのイベントは、設計上APMからは見えません。
Act 3 — インフラストラクチャを確認(行き止まり)
インフラを表示し、クリーンであることを見つけ、聴衆にまだ答えがないフラストレーションを感じさせます。
移動先: Splunk Observability Cloud → Infrastructure → Kubernetes → Cluster: isovalent-demo
「クラスター自体を見てみましょう。何かリソースが制約されているかもしれません — ノードが高負荷、Pod が OOMKilled されている、そのようなことです。
両方のノードは正常に見えます。CPU とメモリは正常範囲内です。Pod を掘り下げると — すべて Running 状態で、再起動なし、退去もされていません。コンテナ自体もリソース制限に達していません。
これで少し不快な状況になりました。チケットにはユーザーがエラーを見ていると書いてあります。APM はアプリが実行中だと言っています。インフラストラクチャはクラスターが正常だと言っています。これでどうなりますか?
これは実際に非常によくある状況です。アプリケーション層より下、インフラストラクチャ層より下に存在する問題のクラス全体があります — 従来のモニタリングツールでは単純に見えないネットワークレベルで起こっていること。DNS 障害、接続の切断、ポリシー拒否、トラフィックの非対称性。これらはトレースや Pod メトリクスには現れません。ネットワーク自体を観察できるものが必要です。そこで Isovalent の出番です。」
Act 4 — ネットワークが真実を語る
これがデモの核心です。ここはゆっくり時間をかけてください。
移動先: Splunk Observability Cloud → Dashboards → Hubble by Isovalent
「Cilium — 私たちの CNI、すべてのノードで実行されているネットワーキング層 — には Hubble という組み込みのオブザーバビリティコンポーネントがあります。Hubble は eBPF を使用してクラスター内のすべてのネットワークフローをリアルタイムで監視します。サンプリングではなく、近似でもなく — すべての接続、すべての DNS リクエスト、すべてのパケットドロップ。そして OpenTelemetry Collector がそれらの Hubble メトリクスをスクレイプして Splunk に転送するように設定しているので、APM やインフラストラクチャを見ていたのと同じプラットフォームでそれらすべてを見ることができます。
Hubble ダッシュボードを表示しましょう。」
DNS クエリが制御不能
DNS Queries チャートを指し、次に DNS Overview タブに移動します。
「ありました。DNS クエリ量を見てください — 約 15 分前に急激にスパイクしています。このタイムスタンプはチケットが開かれた時間とぴったり一致します。
見ているのは
hubble_dns_queries_totalで、ソース namespace ごとに分類されています。スパイクは完全にtenant-jobs— アプリケーション namespace から来ています。アプリケーション内の何かが大量の DNS トラフィックを生成し始め、DNS プロキシが追いつくのに苦労し始めました。しかし右下を見てください — Missing DNS Responses チャートです。これはアラートが発火しているものです。値が深くマイナスになっています。これは DNS クエリが送信されているのに、応答が一度も戻ってこないことを意味します。DNS プロキシが圧倒され、接続は静かにタイムアウトしています。これがユーザーの 500 エラーとして現れている波及効果です。」
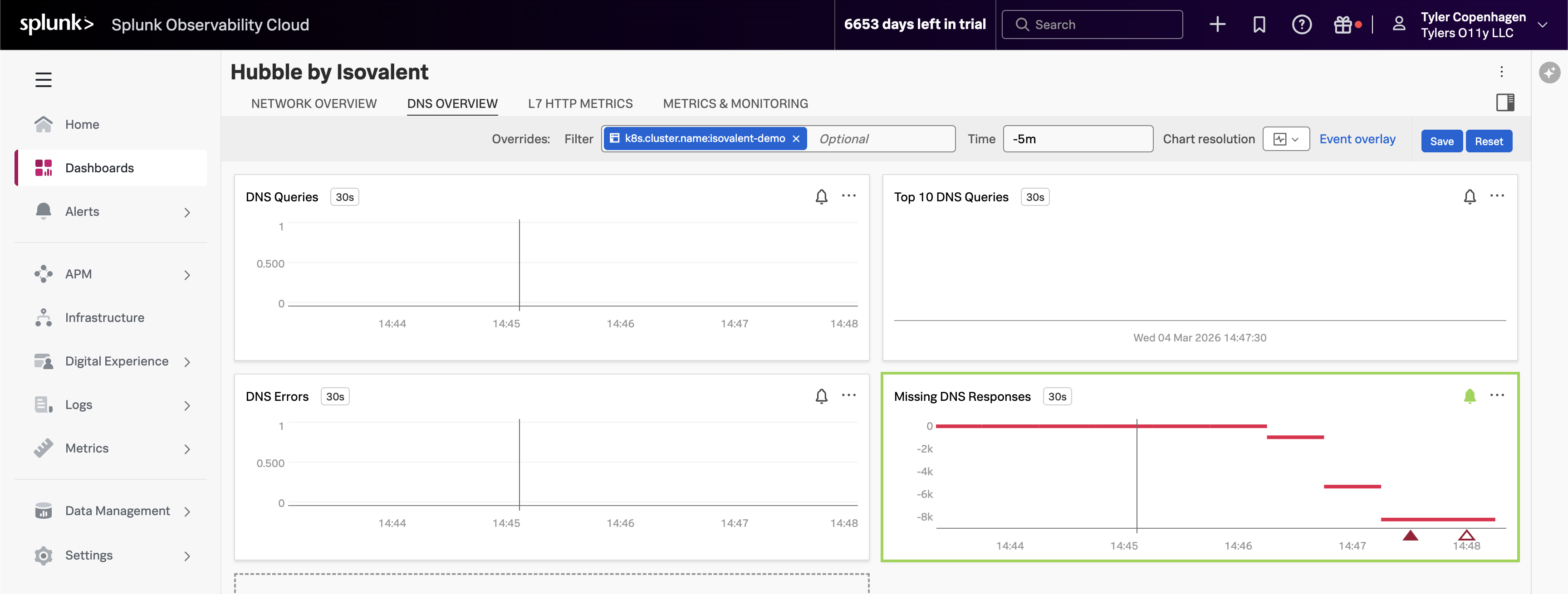
トップ DNS クエリが原因を明らかに
Top 10 DNS Queries チャートを指します。
「これらすべての DNS リクエストを行っているものを特定しましょう。Top 10 DNS Queries チャートは最も頻繁にクエリされるドメインを分類しており、1 つの名前が圧倒的に目立っています:
api.github.com。これはクラスター内部のサービスではありません — 外部エンドポイントです。そしてアプリ内で外部エンドポイントと通信するのは crawler サービスだけです。crawler はジョブシミュレーションの一部として外部 URL への HTTP 呼び出しを行います。その HTTP 呼び出しを行うたびに、最初に DNS を通じて
api.github.comを解決する必要があります。通常これは問題ありません。1 つの crawler Pod が数秒ごとにリクエストを行うのは完全に管理可能です。しかし、どれだけ積極的に実行されているかについて何かが明らかに変化しています。」
ドロップされたフローが影響範囲を示す
Dropped Flows チャートを指します。
「Dropped Flows チャートは別の注目すべきことを示しています。Hubble は成功した接続だけを追跡するのではありません — 拒否またはドロップされたすべての接続と、その理由コードをキャプチャします。DNS スパイクと全く同じ時間にドロップの増加が見られます。
これらのドロップは DNS 過負荷の下流の結果です。namespace 内のサービスが接続を試み、DNS が遅すぎるか失敗すると、それらの接続試行はタイムアウトしてドロップされます。これが APM がレイテンシの上昇として見ていたものです — しかし APM にはその下に DNS 問題があることは全くわかりませんでした。」
ネットワークフロー量がパターンを確認
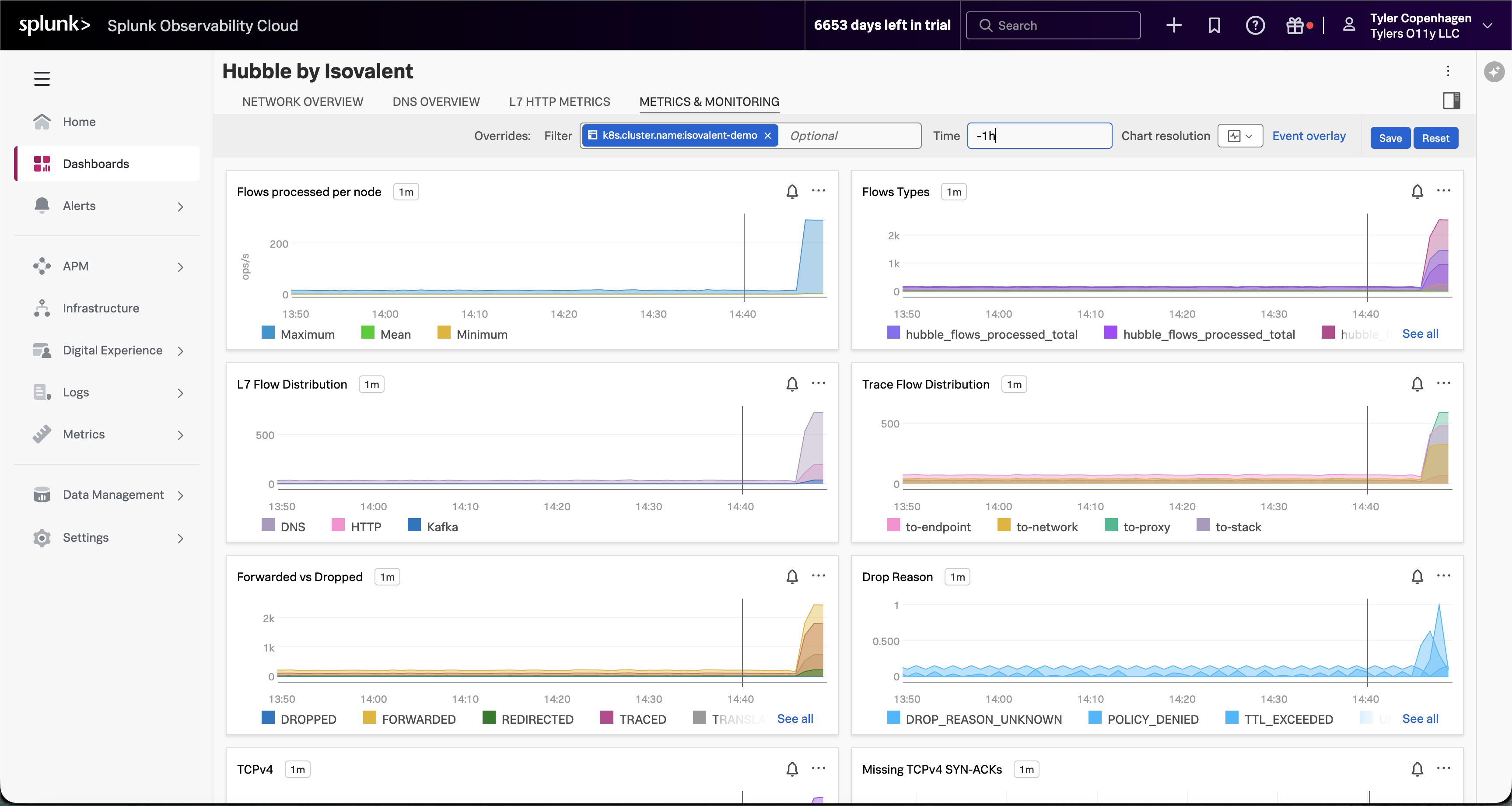
Metrics & Monitoring タブに移動します。
「そして Metrics & Monitoring タブを見ると、全体像がさらに明確になります。ノードごとの処理フロー数が垂直に上昇しています — これは生のネットワークトラフィック量です。Forwarded vs Dropped チャートは、それらのフローのかなりの割合が転送されずにドロップされていることを示しています。そして Drop Reason の内訳は、TTL_EXCEEDED と DROP_REASON_UNKNOWN の混合であることを教えてくれます — DNS タイムアウトがカスケードし始めたときにまさに予想されるものです。特定の時点で何かが変わり、その時点以降のすべてがベースラインとは異なって見えます。」
L7 HTTP トラフィックが興味深いストーリーを語る
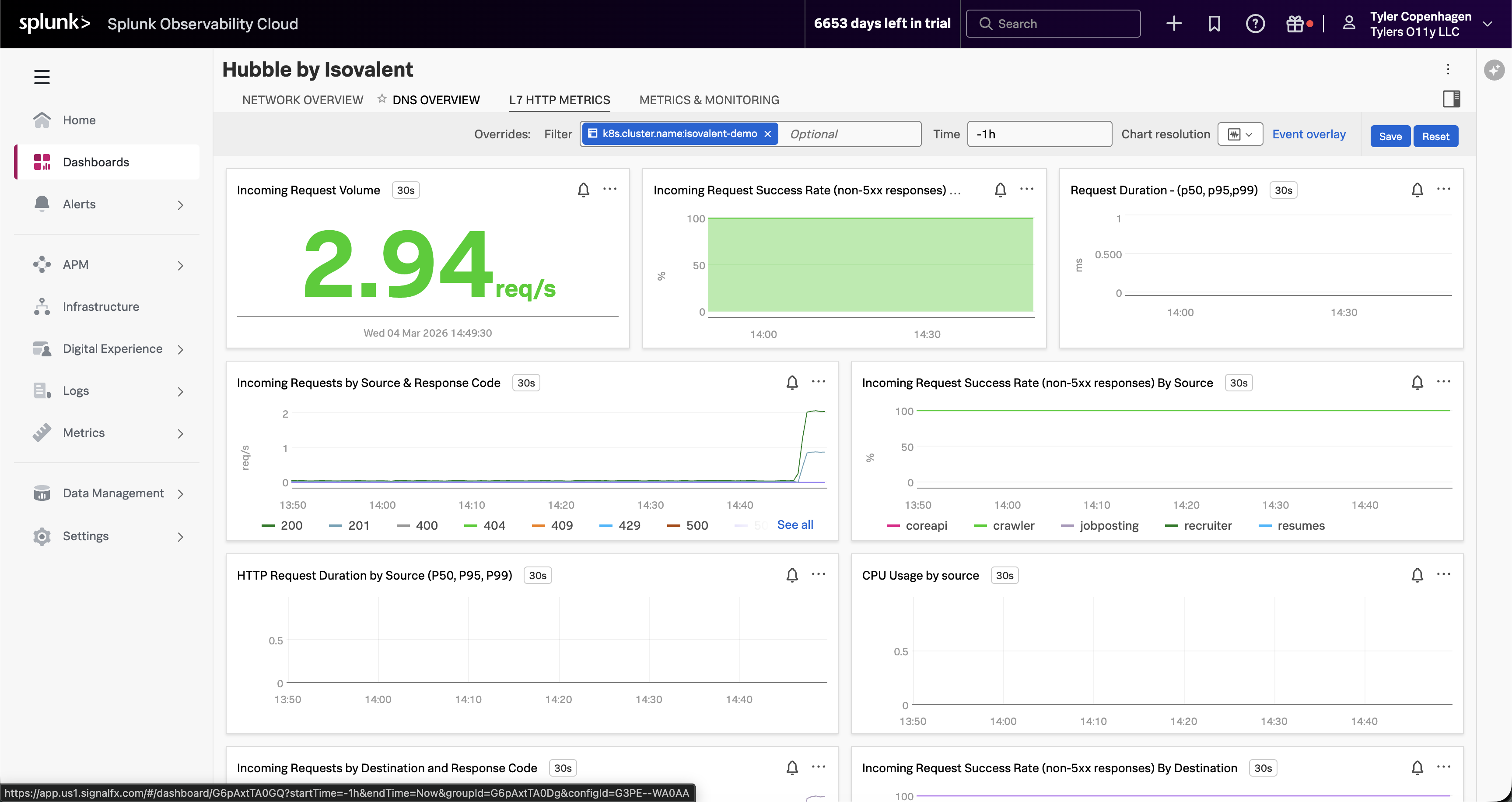
L7 HTTP Metrics タブに移動します。
「L7 HTTP Metrics タブで指摘する価値のあることがあります。これは実際に APM が役に立たなかった理由を補強するからです。受信リクエスト量はゼロではありません — トラフィックはまだ流れています。成功率チャートはほとんど緑に見えます。HTTP レベルの可視性だけを見ていた場合、アプリは問題ないと結論づけるかもしれません。
しかし Incoming Requests by Source チャートを見てください。crawler が不釣り合いなシェアのトラフィックを生成しています — 他のサービスから分離しているのが見えます。HTTP 呼び出しを成功させているので、APM はフラグを立てません。問題は 1 つ下の層、DNS で、HTTP 接続が確立される前に起こっています。」
Act 5 — 根本原因の確認
ここで点と点をつなぎ、証明します。
「これが全体像です:ある時点で、crawler サービスが 1 レプリカから 5 にスケールアップされ、クロール間隔が非常に積極的に設定されました — 0.2 から 0.3 秒ごと。これは 5 つの Pod が、それぞれ
api.github.comを解決するために DNS ルックアップを毎秒複数回発火させています。合計すると、毎秒 15 から 25 の DNS クエリが持続的に発生します。DNS プロキシは単一のワークロードからそのような負荷を処理するようには作られていないので、キューイング、スローダウン、そして最終的にはリクエストのドロップを開始します。DNS 解決を必要とする namespace 内の他のすべてのサービスが巻き添えを食います。それが何を見ているか確認しましょう。」
オプションとして、Cilium by Isovalent dashboard → Policy: L7 Proxy タブに切り替えます。
「Hubble 側ではなく Cilium 側からこれを見たい場合は、Cilium by Isovalent dashboard に切り替えて Policy: L7 Proxy タブを見てください。FQDN の L7 Request Processing Rate — これが DNS です — が 21,000 リクエストを超えています。これは分あたりではありません。DNS プロキシは非常に大量の FQDN ルックアップを処理しており、すべて受信されて転送されているため、バックアップし始めました。このビューは DNS Proxy Upstream Reply レイテンシも表示しており、プロキシが圧力下にあることを確認できます。」
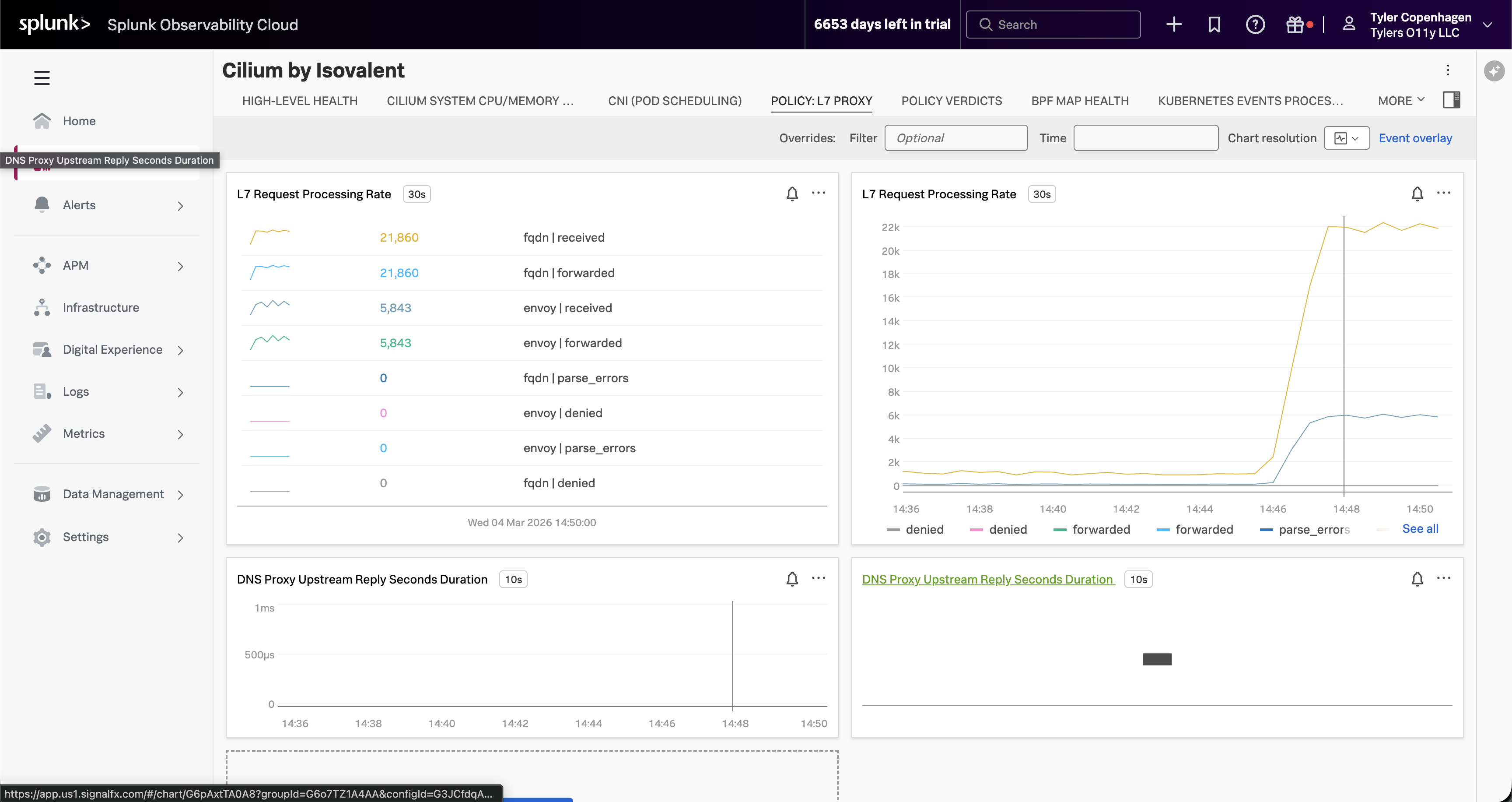
「ありました。5 レプリカ、0.2 から 0.3 秒ごとにクロール。
APM ではこれが見えません。コードを計装しているのであって、DNS ではないからです。インフラストラクチャモニタリングでもこれは見えません。Pod は正常です — 設定されたとおりに正確に動作しています。これをキャッチできる唯一のツールは、eBPF レベルで動作し、すべてのパケット、すべての DNS リクエスト、すべての接続試行をリアルタイムで監視するものです。それが Hubble です。そして Splunk に接続しているので、他のすべてに使用しているのと同じダッシュボードでキャッチしました。」
Act 6 — ライブで修正
この部分は満足感があります。チャートがリアルタイムで回復するのを見ることができるからです。
「修正は簡単です — crawler をスケールダウンして、通常のクロール間隔を復元します。」
Hubble by Isovalent ダッシュボードに戻り、1分ほど待ちます。
「DNS Queries チャートを見てください — ほぼ即座に下がってくるのが見えます。1〜2 分以内にベースラインに戻ります。ドロップされたフローはゼロになります。ネットワークフロー量は通常に戻ります。
そして今 APM に戻ると、レイテンシが正常化し、エラーレートが予想される 10% のベースラインに落ち着くのが見えるでしょう。
チケットをクローズできます。根本原因:crawler の設定ミスによる DNS 飽和。解決策:Helm を使用して crawler のレプリカ数とクロール間隔を元に戻す。解決までの時間:チケットが開かれてから約 15 分。」
修復完了
DNSクエリレートがベースラインに戻り、ドロップされたフローがクリアされ、アプリケーションの健全性が回復します — すべてHubbleダッシュボードでライブで確認できます。
Act 7 — これが実際に意味すること
ズームアウトして、価値のステートメントを具体的に感じさせて終わります。
「ここで何が起こったか考えてみましょう。本番スタイルの本当の問題がありました — エンドユーザーにとって何かが壊れていて — 標準的なプレイブックを経由しました。APM は何も問題ないと言いました。インフラストラクチャも何も問題ないと言いました。Hubble がなければ、次のステップはおそらく戦争部屋の通話、ログを見つめる人々、namespace 全体の再起動を期待して行うことだったでしょう。
代わりに、Hubble ダッシュボードを開いた瞬間から 3 分以内に見つけました。私たちが賢いからではなく、正しい層への可視性があったからです。
これが機能する理由は eBPF です。Cilium の Hubble コンポーネントは Linux カーネルにフックし、ソースでネットワークイベントを観察します — アプリケーションコードに到達する前に、Pod ログに現れる前に、APM のトレースになる前に。そして OpenTelemetry Collector を通じてそれらのメトリクスを Splunk に送信することで、APM データやインフラストラクチャデータと同じプラットフォームに並んでいます。ツールを切り替えたり、5 つの異なるダッシュボード間でコンテキストスイッチする必要はありません。以前なかった可視性の層を追加し、チームがすでに知っているワークフローに保持します。
これがストーリーです。ネットワークオブザーバビリティはニッチなニーズではありません — APM とインフラストラクチャモニタリングが残すギャップです。Isovalent がそのギャップを埋め、Splunk でそれを見ることができます。」
クイックリファレンス
問題を注入(デモの約10分前に実行):
修復(Act 6でライブ実行):
設定ミスを確認:
Splunk ナビゲーションパス: APM → Service Map → (クリーンであることを表示) → Infrastructure → Kubernetes → (クリーンであることを表示) → Dashboards → Hubble by Isovalent → (DNS スパイクを表示)
タイミングガイド
| セクション | 概算時間 |
|---|---|
| Act 1 — チケット | 約 1 分 |
| Act 2 — APM(行き止まり) | 約 2〜3 分 |
| Act 3 — インフラストラクチャ(行き止まり) | 約 1〜2 分 |
| Act 4 — Hubble ダッシュボード | 約 4〜5 分 |
| Act 5 — 根本原因の確認 | 約 2 分 |
| Act 6 — ライブで修正 | 約 2 分 |
| Act 7 — 価値のまとめ | 約 2 分 |
| 合計 | 約 14〜17 分 |