Splunk4Rookies ワークショップ
このワークショップでは、Splunk Observability Cloudがフロントエンドアプリケーションからバックエンドサービスまで、ユーザー体験の視点からどのように即座に可視性を提供するかをお見せします - Splunk Observability Cloudの最も魅力的な機能と差別化要因を体験していただきます。 {class=“children children-type-tree children-sort-”}
このワークショップでは、Splunk Observability Cloudがフロントエンドアプリケーションからバックエンドサービスまで、ユーザー体験の視点からどのように即座に可視性を提供するかをお見せします - Splunk Observability Cloudの最も魅力的な機能と差別化要因を体験していただきます。 {class=“children children-type-tree children-sort-”}
このワークショップでは、Splunk Observability Cloudがフロントエンドアプリケーションからバックエンドサービスまで、ユーザー体験に関する即時の可視性をどのように提供するかをデモンストレーションします。他の可観測性ソリューションと一線を画す、プラットフォームの最も強力な機能をいくつか体験していただきます
Splunk Observability Cloudのコアとなる強みの一つは、テレメトリデータを統合し、エンドユーザーエクスペリエンスとアプリケーションスタック全体の包括的な全体像を作成する能力です。
このワークショップでは、AWS EC2インスタンス上にデプロイされたマイクロサービスベースのeコマースアプリケーションに焦点を当てます。ユーザーは商品を閲覧し、カートに商品を追加し、注文を完了できます。このアプリケーションは、詳細なパフォーマンスデータを取得するためにOpenTelemetryで計装されています。
OpenTelemetry とは?
OpenTelemetry は、メトリクス、トレース、ログなどのテレメトリデータの計装、生成、収集、エクスポートを支援するために設計されたオープンソースのツール、API、ソフトウェア開発キット(SDK)のコレクションです。このデータにより、ソフトウェアのパフォーマンスと動作の詳細な分析が可能になります。
OpenTelemetryコミュニティは急速に成長しており、Splunk、Google、Microsoft、Amazonなどの大手企業からのサポートを受けています。現在、Cloud Native Computing Foundationにおいて、Kubernetesに次いで2番目に多くのコントリビューターを抱えています。

はじめに
このワークショップの目的は、Splunk Observability Cloudを使用して問題のトラブルシューティングを行い、根本原因を特定する実践的な経験を提供することです。私たちは、Kubernetes上で動作する完全に計装されたマイクロサービスベースのアプリケーションを用意しており、これがメトリクス、トレース、ログをSplunk Observability Cloudにリアルタイム分析のために送信します。
対象者
このワークショップは、Splunk Observability Cloudの実践的な知識を得たいと考えている方を対象としています。Observability Cloudを含むSplunk Platformに関する事前知識がほとんど、または全くない方向けに設計されています。
必要なもの
ノートパソコンと外部ウェブサイトにアクセスできるブラウザが必要です。ワークショップは対面またはZoomを通じて参加できます。Zoomクライアントをインストールしていない場合でも、ブラウザを使用して参加できます。
ワークショップ概要
この3時間のセッションでは、ストリーミング分析とNoSampleで完全に忠実な分散トレースを提供する唯一のプラットフォームであるSplunk Observabilityの基礎を、インタラクティブなハンズオン形式で説明します。以下が期待できる内容です
OpenTelemetry
最新のObservabilityにOpenTelemetryが不可欠である理由と、システムの可視性をどのように向上させるかを学びます。
Splunk Observability ユーザーインターフェイスツアー
Splunk Observability Cloudのインターフェイスのガイド付きツアーで、APM、RUM、Log Observer、Synthetics、Infrastructureという5つの主要コンポーネントの操作方法を紹介します。
実際のユーザーデータを生成
オンラインブティックというウェブサイトでシミュレートされた小売体験に飛び込みます。ブラウザ、モバイル、またはタブレットを使用して、サイトを探索し、メトリクス(問題はありますか?)、トレース(問題はどこにありますか?)、ログ(何が問題を引き起こしていますか?)を含む実際のユーザーデータを生成します。
Splunk Real User Monitoring(RUM)
参加者のブラウザセッションから収集された実際のユーザーデータを分析します。あなたの課題は、パフォーマンスの悪いセッションを特定し、トラブルシューティングプロセスを開始することです。
Splunk Application Performance Monitoring(APM)
RUMトレース(フロントエンド)をAPMトレース(バックエンド)にリンクすることで、End to End を可視化する能力を理解しましょう。様々なサービスからのテレメトリがSplunk Observability Cloudでどのように取得され、視覚化されるかを探り、異常とエラーを検出します。
Splunk Log Observer(LO)
Related Content 機能を活用してコンポーネント間を簡単に移動する方法を学びます。このワークショップでは、APMトレースから関連するログに移動して、問題についてより深い洞察を得ます。
Splunk Synthetics
Syntheticsがアプリケーションの24時間365日のモニタリングにどのように役立つかを発見します。オンラインブティックウェブサイトのパフォーマンスと可用性を監視するために、毎分実行される簡単な合成テストの設定方法を説明します。
このセッションを終えると、Splunk Observability Cloudの実践的な経験と、アプリケーションスタック全体の問題をトラブルシューティングして解決する方法についての確かな理解が得られるでしょう。
クラウドコンピューティング、マイクロサービスアーキテクチャ、そして複雑化するビジネス要件の増加に伴い、可観測性の必要性はかつてないほど高まっています。可観測性とは、システムの出力を調査することで、そのシステムの内部状態を理解する能力です。ソフトウェアの文脈では、これはメトリクス、トレース、ログを含むテレメトリデータを調査することでシステムの内部状態を理解できることを意味します。
システムを観測可能にするには、計装が必要です。つまり、コードはトレース、メトリクス、ログを発行する必要があります。この計装データは、Splunk Observability Cloudなどの可観測性バックエンドに送信される必要があります。
| メトリクス | トレース | ログ |
|---|---|---|
| 問題がありますか? | 問題はどこですか? | 問題は何ですか? |
OpenTelemetryは2つの重要なことを行います
これら2つの要素が組み合わさることで、今日の現代的なコンピューティング環境で必要な柔軟性をチームや組織に提供します。
可観測性を始めるにあたっては、重要な質問を含め多くの変数を考慮する必要があります: 「どのようにしてデータを可観測性ツールに取り込むのか?」 OpenTelemetryの業界全体での採用は、この質問に答えることをこれまで以上に容易にしています。
OpenTelemetryは完全にオープンソースで無料で使用できます。過去のモニタリングや可観測性ツールは、独自のエージェントに大きく依存していたため、追加のツールを変更したり設定したりするために必要な労力は、インフラレベルからアプリケーションレベルまで、システム全体に大規模な変更を必要としていました。
OpenTelemetryはベンダー中立であり、可観測性分野の多くの業界リーダーにサポートされているため、採用者は計装にわずかな変更を加えるだけで、サポートされている可観測性ツール間をいつでも切り替えることができます。これは、Linuxのように様々なディストリビューションが設定やアドオンをバンドルしていても、基本的にはすべてがコミュニティ主導のOpenTelemetryプロジェクトに基づいているため、どのOpenTelemetryディストリビューションを使用しても変わりません。
Splunkは完全にOpenTelemetryにコミットしており、お客様があらゆる種類、あらゆる構造、あらゆるソースから、あらゆる規模で、すべてリアルタイムですべてのデータを収集して使用できるようにしています。OpenTelemetryは基本的にモニタリングの環境を変え、ITチームやDevOpsチームがすべての質問とすべてのアクションにデータをもたらすことを可能にしています。これらのワークショップでこれを体験することになります。

Splunk Observability Cloudの様々なコンポーネントについて簡単な説明から始めます。これはUIに慣れてもらうことを目的としています。
このワークショップを進める最も簡単な方法は以下を使用することです:
Splunkが主催するワークショップの場合、Workshop Orgに招待するメールを受け取っているはずです。このメールは下のスクリーンショットのようになっています。見つからない場合は、迷惑メールフォルダを確認するか、インストラクターにお知らせください。また、ログイン FAQで他の解決策を確認することもできます。
進めるには、Join Now(参加する)ボタンをクリックするか、メールに記載されているリンクをクリックしてください。
登録プロセスをすでに完了している場合は、残りの手順をスキップして直接Splunk Observability Cloudにログインできます
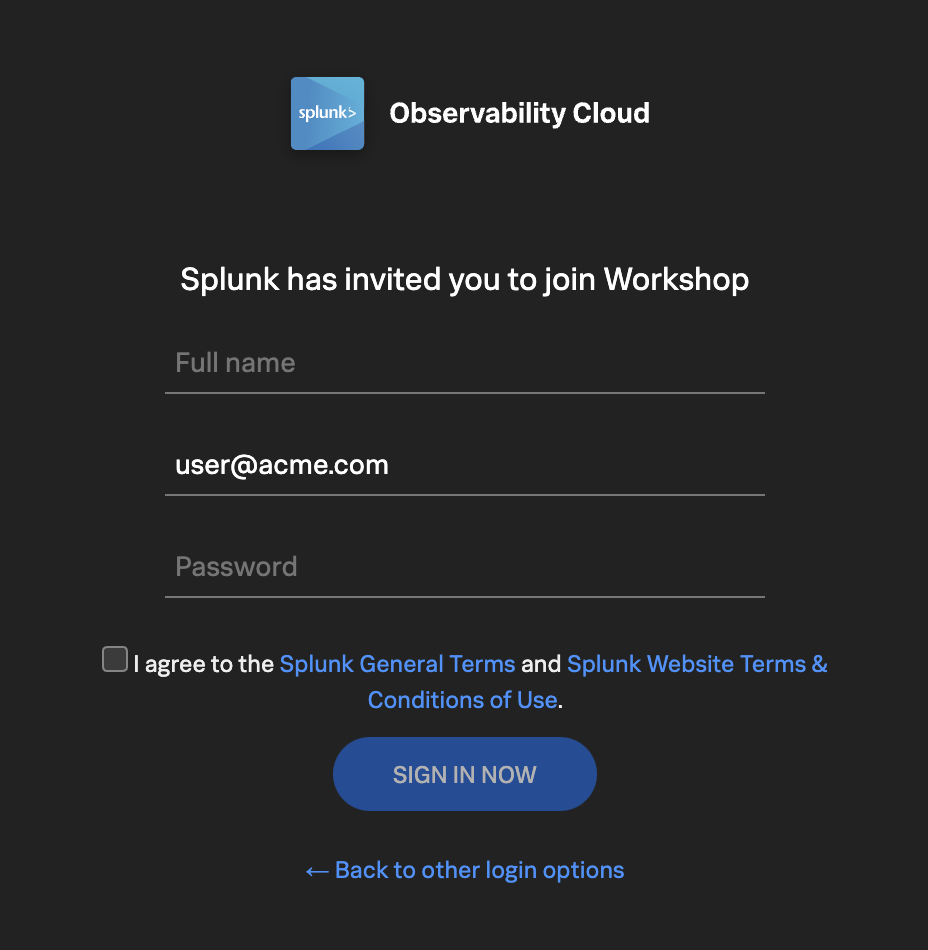
Splunk Observability Cloudを初めて使用する場合は、登録フォームが表示されます。フルネームと希望するパスワードを入力してください。パスワードの要件は次のとおりです
利用規約に同意するためのチェックボックスをクリックし、SIGN IN NOW(今すぐサインイン)ボタンをクリックします。
Splunk Observability Cloudに登録してログインすると、ホームページ(ランディングページ)に移動します。ここでは、開始に役立ついくつかの便利な機能が見つかります。

最初の演習から始めましょう
以前にSplunk Observabilityを使用したことがある場合は、以前に使用した組織に配置されている可能性があります。正しいワークショップ組織にいることを確認してください。複数の組織へのアクセス権がある場合は、インストラクターに確認してください。
次に、Splunk Real User Monitoring (RUM) を確認しましょう。
Splunk RUMは業界で唯一のエンドツーエンドのNoSample(サンプリングなし)RUMソリューションで、すべてのWebおよびモバイルセッションの完全なユーザーエクスペリエンスに関する可視性を提供し、発生時にすべてのフロントエンドトレースとバックエンドのメトリクス、トレース、ログを独自に組み合わせます。ITオペレーションとエンジニアリングチームは、エラーの範囲を迅速に特定し、優先順位を付け、分離し、パフォーマンスが実際のユーザーにどのように影響するかを測定し、すべてのユーザー操作のビデオ再構築とともにパフォーマンスメトリクスを相関させることでエンドユーザーエクスペリエンスを最適化できます。
完全なユーザーセッション分析: ストリーミング分析により、シングルページおよびマルチページアプリからの完全なユーザーセッションをキャプチャし、すべてのリソース、画像、ルート変更、APIコールの顧客への影響を測定します。
問題をより迅速に関連付ける: 無限のカーディナリティと完全なトランザクション分析により、複雑な分散システム全体で問題をより迅速に特定し関連付けることができます。
レイテンシーとエラーの分離: 各コード変更とデプロイメントに対するレイテンシー、エラー、パフォーマンスの低下を簡単に特定します。コンテンツ、画像、サードパーティの依存関係がお客様にどのように影響するかを測定します。
ページパフォーマンスのベンチマークと改善: コアウェブバイタルを活用して、ページ読み込み体験、インタラクティビティ、視覚的安定性を測定し改善します。影響力のあるJavaScriptエラーを見つけて修正し、最初に改善すべきページを簡単に理解します。
意味のあるメトリクスの探索: 特定のワークフロー、カスタムタグ、未インデックス化タグの自動提案に関するメトリクスを使用して、顧客への影響を即座に視覚化し、問題の根本原因をすばやく見つけます。
エンドユーザーエクスペリエンスの最適化: すべてのユーザー操作のビデオ再構築とともにパフォーマンスメトリクスを相関させて、エンドユーザーエクスペリエンスを最適化します。
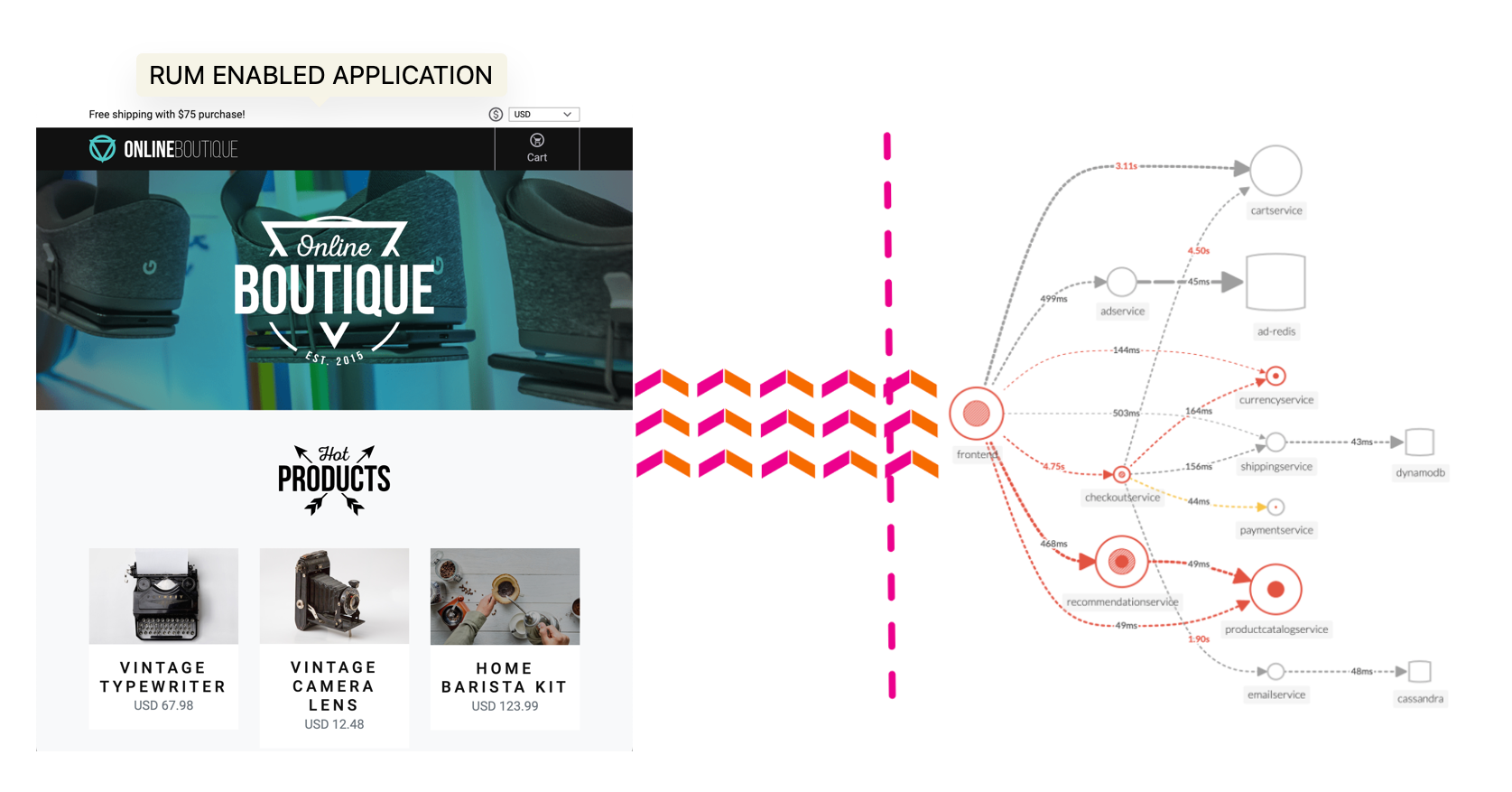
メインメニューのRUMをクリックすると、RUMのメインホームページ(ランディングページ)に移動します。このページの主な概念は、選択したすべてのRUMアプリケーションの全体的な状態を、フルダッシュボードまたはコンパクトビューのいずれかで一目で提供することです。
使用する状態ダッシュボードのタイプに関係なく、RUMホームページは3つの明確なセクションで構成されています

Web Vitals メトリクスに基づいて、現在のウェブサイトのパフォーマンスをどのように評価しますか?
Web Vitals メトリクスによれば、サイトの初期読み込みは良好であり、Goodと評価されています
次に、Splunk Application Performance Monitoring(APM) を確認しましょう。
Splunk APMは、モノリスとマイクロサービス全体で問題をより迅速に解決するために、すべてのサービスとその依存関係のNoSample(サンプリングなし)エンドツーエンドの可視性を提供します。チームは新しいデプロイメントからの問題をすぐに検出し、問題の原因の範囲を特定して分離することで自信を持ってトラブルシューティングを行い、バックエンドサービスがエンドユーザーとビジネスワークフローにどのように影響するかを理解することでサービスのパフォーマンスを最適化できます。
リアルタイム監視とアラート: Splunkは標準でサービスダッシュボードを提供し、急激な変化があった場合にREDメトリクス(レート、エラー、期間)を自動的に検出してアラートを発します。
動的テレメトリマップ: 現代の本番環境でのサービスパフォーマンスをリアルタイムで簡単に視覚化できます。インフラストラクチャ、アプリケーション、エンドユーザー、およびすべての依存関係からのサービスパフォーマンスのエンドツーエンドの可視性により、新しい問題の範囲をすばやく特定し、より効果的にトラブルシューティングを行うことができます。
インテリジェントなタグ付けと分析: ビジネス、インフラストラクチャ、アプリケーションからのすべてのタグを1か所で表示し、レイテンシーやエラーの新しい傾向を特定のタグ値と簡単に比較できます。
AI によるトラブルシューティングが最も影響の大きい問題を特定: 個々のダッシュボードを手動で掘り下げる代わりに、より効率的に問題を分離します。サービスと顧客に最も影響を与える異常とエラーの原因を自動的に特定します。
完全な分散トレースがすべてのトランザクションを分析: クラウドネイティブ環境の問題をより効果的に特定します。Splunk分散トレースは、バックエンドとフロントエンドからのすべてのトランザクションをインフラストラクチャ、ビジネスワークフロー、アプリケーションのコンテキストで視覚化し相関付けます。
フルスタック相関: Splunk Observability内では、APMがトレース、メトリクス、ログ、プロファイリングをリンクし、スタック全体のすべてのコンポーネントとその依存関係のパフォーマンスを簡単に理解できるようにします。
データベースクエリパフォーマンスの監視: SQLおよびNoSQLデータベースからの遅いクエリと高実行クエリがサービス、エンドポイント、ビジネスワークフローにどのように影響するかを簡単に特定できます — 計装は不要です。
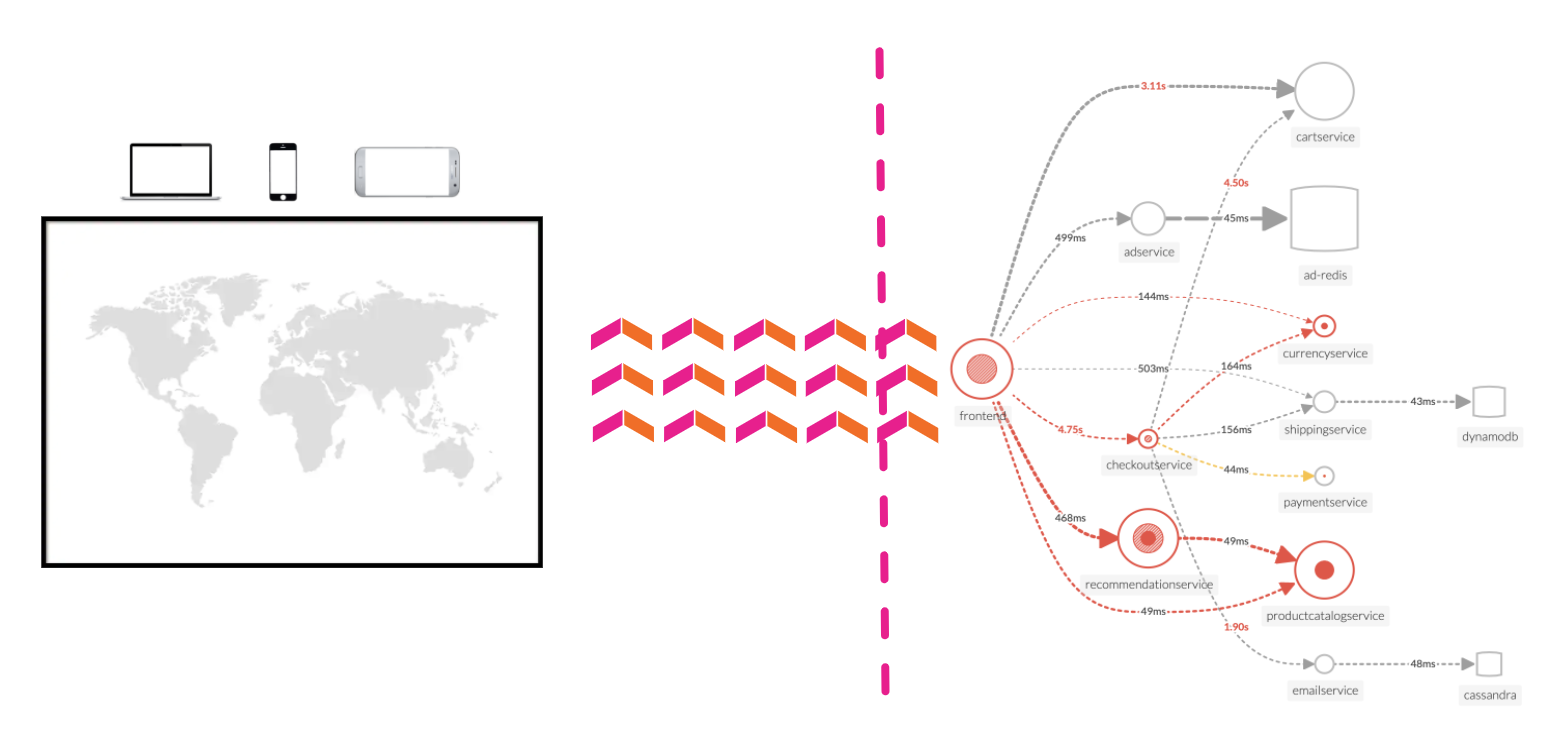
メインメニューのAPMをクリックすると、APMホームページが表示されます。APMホームページは3つの明確なセクションで構成されています

APM 概要ペインは、アプリケーションの健全性の高レベルの概要を提供します。これにはアプリケーション内のサービス、レイテンシー、エラーの概要が含まれます。また、エラー率別のトップサービスとエラー率別のトップビジネスワークフローのリストも含まれています(ビジネスワークフローは、特定のアクティビティやトランザクションに関連するトレースコレクションの開始から終了までの旅程であり、エンドツーエンドのKPIの監視やルート原因とボトルネックの特定を可能にします)。
複数のアプリケーションを簡単に区別するために、Splunkは Environment を使用します。ワークショップ環境の命名規則は [ワークショップ名]-workshop です。インストラクターが選択する正しい環境を提供します。
エラー率別のトップサービスチャートから何を結論づけることができますか?
paymentserviceはエラー率が高い
概要ページを下にスクロールすると、一部のサービスの横にInferred Serviceと表示されていることに気づくでしょう。
Splunk APMは、リモートサービスを呼び出すスパンが必要な情報を持っている場合、リモートサービスまたは推測されたサービスの存在を推測できます。推測されるサービスの例としては、データベース、HTTPエンドポイント、メッセージキューなどがあります。推測されたサービスは計装されていませんが、サービスマップとサービスリストに表示されます。
次に、Splunk ログオブザーバー(LO) を確認しましょう。
Log Observer Connectを使用すると、Splunkプラットフォームからの同じログデータをシームレスに直感的でコード不要のインターフェースに取り込み、問題を迅速に見つけて修正するのに役立ちます。ログベースの分析を簡単に実行し、Splunk Infrastructure MonitoringのリアルタイムメトリクスとSplunk APMトレースを1か所でシームレスに関連付けることができます。
エンドツーエンドの可視性: Splunkプラットフォームの強力なロギング機能とSplunk Observability Cloudのトレースおよびリアルタイムメトリクスを組み合わせることで、ハイブリッド環境のより深い洞察とより多くのコンテキストを得ることができます。
迅速かつ簡単なログベースの調査を実行: すでにSplunk Cloud PlatformまたはEnterpriseに取り込まれているログを、シンプルで直感的なインターフェース(SPLを知る必要はありません!)でカスタマイズ可能な標準搭載のダッシュボードとともに再利用することによって実現します。
より高いスケールの経済性と運用効率を実現: チーム間でログ管理を一元化し、データとチームのサイロを壊し、全体的により良いサポートを得ることによって実現します。
![]()
![]()
メインメニューのLog Observerをクリックすると、Log Observerホームページが表示されます。Log Observerホームページは4つの明確なセクションで構成されています

一般的に、Splunkでは、「Index」はデータが保存される指定された場所を指します。これはデータのフォルダやコンテナのようなものです。Splunkでは、「Index」はデータが保存される指定された場所を指します。これはデータのフォルダやコンテナのようなものです。Splunk内のデータは、検索や分析が容易になるように整理され構造化されています。特定のタイプのデータを保存するために異なるインデックスを作成できます。たとえば、Webサーバーログ用のインデックス、アプリケーションログ用の別のインデックスなどがあります。
以前にSplunk EnterpriseまたはSplunk Cloudを使用したことがある場合は、おそらくログから調査を開始することに慣れているでしょう。以下の演習で見るように、Splunk Observability Cloudでも同様のことができます。ただし、このワークショップでは、調査にOpenTelemetryのすべてのシグナルを使用します。
簡単な検索演習を行いましょう
時間枠を -15m に設定します。
フィルターバーでをクリックし、ダイアログでFieldをクリックします。
cardTypeと入力して選択します。
トップ値の下でvisaをクリックし、次に = をクリックしてフィルターに追加します。

ログテーブルのログエントリの1つをクリックして、エントリに cardType: "visa" が含まれていることを確認します。
出荷されたすべての注文を見つけましょう。フィルターバーのClear Allをクリックして、前のフィルターを削除します。
フィルターバーで再びをクリックし、キーワードを選択します。次に**キーワードを入力…**ボックスに order: と入力し、Enterキーを押します。
これで「order:」という単語を含むログ行のみが表示されるはずです。まだたくさんのログ行があるので、さらにフィルタリングしましょう。
別のフィルターを追加します。今回はFieldボックスを選択し、Find a field … 検索ボックスに severity と入力して選択します。

注文ログ行には重要度が割り当てられていないため、ダイアログボックスの下部にあるをクリックしてください。これにより、他のログが削除されます。
上部にオンボーディングコンテンツがまだ表示されている場合は、Exclude all logs with this fieldボタンを見るためにページを下にスクロールする必要があるかもしれません。
これで、過去15分間に販売された注文のリストが表示されるはずです。
次に、Splunk Syntheticsを確認しましょう。
Splunk Synthetic Monitoringは、URL、API、重要なWebサービス全体に可視性を提供し、問題をより迅速に解決します。ITオペレーションとエンジニアリングチームは、問題の検出、アラート、優先順位付けを簡単に行い、複数ステップのユーザージャーニーをシミュレートし、新しいコードデプロイメントからのビジネスへの影響を測定し、ステップバイステップのガイド付き推奨事項を使用してWebパフォーマンスを最適化し、より良いデジタルエクスペリエンスを確保できます。
可用性の確保: ユーザーエクスペリエンスを構成する複数ステップのワークフローをシミュレートするカスタマイズ可能なブラウザテストで、重要なサービス、URL、APIの健全性と可用性を事前に監視し、アラートを出します。
メトリクスの改善: コアウェブバイタルとモダンパフォーマンスメトリクスにより、ユーザーはすべてのパフォーマンス欠陥を1か所で表示し、ページ読み込み、インタラクティビティ、視覚的安定性を測定して改善し、JavaScriptエラーを見つけて修正してページパフォーマンスを向上させることができます。
フロントエンドからバックエンドまで: Splunk APM、Infrastructure Monitoring、On-Call、ITSIとの統合により、チームはエンドポイントの稼働時間をバックエンドサービス、基盤となるインフラストラクチャ、およびインシデント対応の調整との関連で表示し、単一のUI内で環境全体をトラブルシューティングできます。
検出とアラート: エンドユーザー体験を監視してシミュレートし、顧客に影響を与える前にAPI、サービスエンドポイント、重要なビジネストランザクションの問題を検出、通信、解決します。
ビジネスパフォーマンス: 主要なビジネストランザクションの複数ステップのユーザーフローを簡単に定義し、数分で重要なユーザージャーニーの記録とテストを開始します。稼働時間とパフォーマンスのSLAとSLOを追跡・報告します。
フィルムストリップとビデオ再生: 画面録画、フィルムストリップ、スクリーンショットを、最新のパフォーマンススコア、競合ベンチマーキング、メトリクスとともに表示して、人工的なエンドユーザー体験を視覚化します。ビジュアルコンテンツを配信する速度を最適化し、ページの安定性とインタラクティビティを向上させて、より良いデジタルエクスペリエンスをデプロイします。
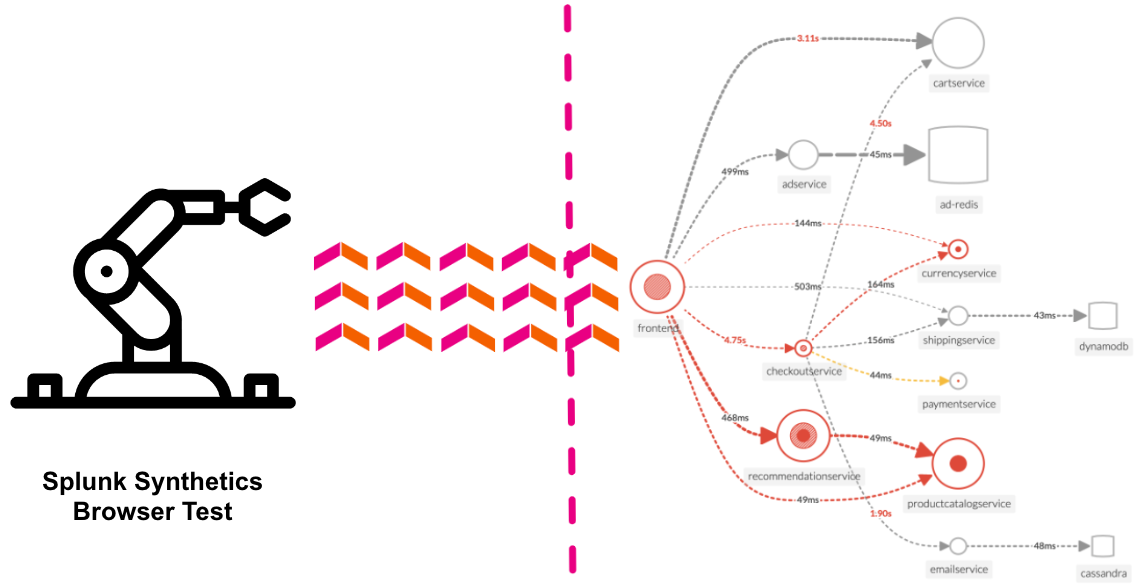
メインメニューのSyntheticsをクリックします。これにより、Syntheticsホームページに移動します。このページには、役立つ情報を提供するか、Syntheticテストを選択または作成できる3つの明確なセクションがあります。

ワークショップの一環として、実行しているアプリケーションに対するデフォルトのブラウザテストを作成しています。テストペイン(2)でそれを見つけることができます。名前はWorkshop Browser Test forで、その後にワークショップの名前が続きます(インストラクターがそれを提供しているはずです)。
ツアーを続けるために、ワークショップの自動ブラウザテストの結果を見てみましょう。

テストはどのくらいの頻度で、どこから実行されていますか?
テストは1 分間隔でラウンドロビン方式によりフランクフルト、ロンドン、パリから実行されています
次に、Splunk インフラストラクチャモニタリング(IM) を使用して、アプリケーションが実行されているインフラストラクチャを調べてみましょう。
Splunk Infrastructure Monitoring(IM)は、ハイブリッドクラウド環境向けの市場をリードする監視および可観測性サービスです。特許取得済みのストリーミングアーキテクチャに基づいて構築されており、従来のソリューションよりもはるかに短時間で、より高い精度でインフラストラクチャ、サービス、アプリケーション全体のパフォーマンスを視覚化および分析するためのリアルタイムソリューションをエンジニアリングチームに提供します。
OpenTelemetry 標準化: データの完全な制御を提供し、ベンダーロックインから解放し、独自のエージェントの実装から解放します。
Splunk の OTel コレクター: シームレスなインストールと動的な構成により、スタック全体を数秒で自動検出し、クラウド、サービス、システム全体の可視性を提供します。
300 以上の使いやすい標準コンテンツ: 事前構築されたナビゲーターとダッシュボードにより、環境全体の即時の視覚化を提供し、すべてのデータとリアルタイムで対話できます。
Kubernetes ナビゲーター: ノード、ポッド、コンテナの包括的な標準的な階層ビューを即座に提供します。わかりやすいインタラクティブなクラスターマップで、最も初心者のKubernetesユーザーでもすぐに使いこなせます。
AutoDetect アラートとディテクター: 最も重要なメトリクスを標準で自動的に識別し、テレメトリデータが取り込まれた瞬間から正確にアラートを出すディテクターのアラート条件を作成し、重要な通知のために数秒でリアルタイムのアラート機能を使用します。
ダッシュボード内のログビュー: 共通のフィルターと時間制御を使用して、ログメッセージとリアルタイムメトリクスを1ページに組み合わせ、より迅速なコンテキスト内トラブルシューティングを実現します。
メトリクスパイプライン管理: 再計装なしに取り込み時点でメトリクスの量を制御し、必要なデータのみを保存して分析するための集約およびデータ削除ルールのセットを使用します。メトリクスの量を削減し、可観測性のコストを最適化します。
あなたは次の目新しいアイテムを有名なオンラインブティックショップで購入したいと思っているおしゃれな都会人です。オンラインブティックはあなたのヒップスターな要求すべてを満たすための場所だと聞いています。
この演習の目的は、オンラインブティックウェブアプリケーションと対話することです。これはSplunk Observability Cloudの機能を実演するために使用されるサンプルアプリケーションです。このアプリケーションは簡単なEコマースサイトで、商品の閲覧、カートへの追加、そして精算が可能です。
このアプリケーションはすでにデプロイされており、インストラクターがオンラインブティックウェブサイトへのリンクを提供します。例
ページの読み込みを待っている間は、ページ上でマウスカーソルを動かしてください。これにより、このワークショップの後半で探索するためのより多くのデータが生成されます。
これは、ユーザーエクスペリエンスが悪い場合の感覚で、これは潜在的な顧客満足度の問題であるため、すぐにトラブルシューティングを行う必要があります。
Splunk RUMでデータがどのように見えるか確認してみましょう。
あなたはフロントエンドエンジニアまたはSREで、パフォーマンス問題の最初のトリアージを行うよう任されています。オンラインブティックアプリケーションに関する潜在的な顧客満足度の問題を調査するよう依頼されました。
すべての参加者のブラウザセッションから受信したテレメトリによって提供された実際のユーザーデータを調査します。目標は、パフォーマンスの悪かったブラウザ、モバイル、またはタブレットセッションを見つけて、トラブルシューティングプロセスを開始することです。
Splunk Observability Cloudのメインメニューから、RUMをクリックします。RUMホームページに到着します。このビューについては、先ほどの短い紹介ですでに説明しました。


「Custom Events」タブのチャートを調べると、どのチャートがレイテンシースパイクを明確に示していますか?
それは 「Custom Event Latency」 チャートです
Custom Eventsタブを選択して、そのタブにいることを確認します。
Custom Event Latencyチャートを見てください。ここに表示されているメトリクスはアプリケーションのレイテンシーを示しています。横の比較メトリクスは、1時間前(上部のフィルターバーで選択されています)と比較したレイテンシーを示しています。
チャートタイトルの下にあるすべて表示リンクをクリックします。

このダッシュボードビューでは、RUMデータに関連付けられたすべてのタグが表示されます。タグはデータを識別するために使用されるキーと値のペアです。この場合、タグはOpenTelemetry計装によって自動的に生成されます。タグはデータをフィルタリングし、チャートやテーブルを作成するために使用されます。Tag Spotlightビューでは、ユーザーセッションを詳しく調べることができます。
これで、最も長い期間の降順でソートされたユーザーセッションテーブルができました。このテーブルには、サイトでショッピングしたすべてのユーザーの都市も含まれています。OSバージョン、ブラウザバージョンなど、さらにフィルターを適用してデータを絞り込むこともできます。

セッションは、ユーザーがアプリケーションと対話する際に実行するアクションに対応するトレースの集まりです。デフォルトでは、セッションはセッションでキャプチャされた最後のイベントから15分経過するまで続きます。最大セッション時間は4時間です。

RUMセッションリプレイでは情報を編集することができます。デフォルトではテキストが編集されます。画像も編集することができます(このワークショップ例では実施済み)。これは、機密情報が含まれるセッションを再生する場合に役立ちます。また、再生速度を変更したり、再生を一時停止したりすることもできます。
セッションを再生する際、マウスの動きがキャプチャされていることに注目してください。これは、ユーザーがどこに注意を向けているかを確認するのに役立ちます。
/cart/checkout があるもの)まで移動し、その上にカーソルを置きます。
これによりAPMパフォーマンスサマリーが表示されます。このエンドツーエンド(RUMからAPM)のビューは、問題のトラブルシューティングを行う際に非常に便利です。
front-end:/cart/checkout をクリックすると、APM サービスマップが表示されます。
あなたはバックエンド開発者で、SREが発見した問題の調査を手伝うよう依頼されました。SREはユーザーエクスペリエンスの低下を特定し、あなたにその問題を調査するよう依頼しました。
RUMトレース(フロントエンド)からAPMトレース(バックエンド)にジャンプすることで、完全なエンドツーエンドの可視性の力を発見します。すべてのサービスはテレメトリ(トレースとスパン)を送信しており、Splunk Observability Cloudはこれを視覚化、分析し、異常やエラーを検出するために使用できます。
RUMとAPMは同じコインの表と裏です。RUMはアプリケーションのクライアント側からの視点であり、APMはサーバー側からの視点です。このセクションでは、APMを使用して掘り下げ、問題がどこにあるかを特定します。
APMサービスマップは、APMで計装された(インストルメンテーション)サービスと推測されるサービスの間の依存関係と接続を表示します。このマップは、時間範囲、環境、ワークフロー、サービス、タグフィルターでの選択に基づいて動的に生成されます。
RUMウォーターフォールでAPMリンクをクリックすると、そのワークフロー名(frontend:/cart/checkout)に関連するサービスを表示するために、サービスマップビューに自動的にフィルターが追加されました。
ワークフローに関連するサービスはService Mapで確認できます。サイドペインのBusiness Workflowの下には、選択したワークフローのチャートが表示されています。Service Mapとビジネスワークフローチャートは同期しています。Service Mapでサービスを選択すると、Business Workflowペインのチャートが更新され、選択したサービスのメトリクスが表示されます。

Splunk APMはまた、リアルタイムで発生している問題を確認し、問題がサービス、特定のエンドポイント、または基盤となるインフラストラクチャに関連しているかどうかを迅速に判断するのに役立つ組み込みの Service Centric View(サービス中心ビュー) も提供しています。より詳しく見てみましょう。

サービスオーナーとして、Splunk APMのサービスビューを使用して、単一のパネルでサービスの健全性の完全なビューを取得できます。サービスビューには、可用性、依存関係、リクエスト、エラー、および期間(RED)メトリクス、ランタイムメトリクス、インフラストラクチャメトリクス、Tag Spotlight、エンドポイント、および選択したサービスのログのためのサービスレベルインジケーター(SLI)が含まれています。また、サービスビューからサービスのコードプロファイリングとメモリプロファイリングにすぐにアクセスすることもできます。

サービスマップでpaymentserviceの上にカーソルを置いてください。ポップアップサービスチャートからどのような結論を導き出せますか?
エラーの割合が非常に高い。

このエラー率にパターンがあるかどうかを理解する必要があります。そのための便利なツール、Tag Spotlightがあります。

Tag Spotlightのビューは、チャートとカードの両方で設定可能です。デフォルトではリクエストとエラーに設定されています。
また、カードに表示されるタグメトリクスを設定することも可能です。以下の任意の組み合わせを選択できます
改めて、フィルターアイコンからShow tags with no valuesチェックボックスがオフになっていることを確認してください。
どのカードが問題を特定するタグを明らかにしていますか?
「Version」カードです。v350.10 に対するリクエスト数がエラー数と一致しています(つまり 100%)
paymentserviceの問題を引き起こしているバージョンを特定したので、エラーについてさらに詳しい情報が見つかるか確認してみましょう。ページ上部の ← Tag Spotlight をクリックして、サービスマップに戻ります。
tenant.level を選択します。version を選択します。これはサービスバージョンを表示するタグです。表示されている内容からどのような結論が導き出せますか?
すべての tenant.level が v350.10 の影響を受けています
これでpaymentserviceがgold、silver、bronzeの3つのサービスに分解されているのが確認できます。各テナントは2つのサービスに分解されており、それぞれのバージョン(v350.10 と v350.9)に対応しています。

スパンタグを使用してサービスを分解することは非常に強力な機能です。これにより、異なる顧客、異なるバージョン、異なる地域などに対して、サービスがどのようにパフォーマンスを発揮しているかを確認できます。この演習では、paymentserviceの v350.10 がすべての顧客に問題を引き起こしていることを特定しました。
次に、何が起きているかを確認するためにトレースを詳しく調べる必要があります。
Splunk APMはすべてのサービスのNoSample(サンプリングなし)エンドツーエンドの可視性を提供するため、Splunk APMはすべてのトレースをキャプチャします。このワークショップでは、Order Confirmation IDがタグとして利用可能です。これは、ワークショップの前半で遭遇した不良なユーザー体験の正確なトレースを検索するためにこれを使用できることを意味します。
Splunk Observability Cloudは、アプリケーション監視データを探索するためのいくつかのツールを提供しています。Trace Analyzerは、未知または新しい問題を調査するための高カーディナリティ、高粒度の検索と探索が必要なシナリオに適しています。
1:10 ではなく 1:1 に設定されていることを確認します。
Trace & Error countビューは、積み上げ棒グラフで合計トレース数とエラーのあるトレース数を表示します。マウスを使用して、利用可能な時間枠内の特定の期間を選択できます。

Trace Durationビューは、期間ごとのトレースのヒートマップを表示します。ヒートマップは3次元のデータを表しています
マウスを使ってヒートマップ上の領域を選択し、特定の時間帯とトレース期間の範囲にフォーカスすることができます。
1:10 ではなく 1:1 に設定されていることを確認します。orderId と入力してリストからorderIdを選択します。
これで、非常に長いチェックアウト待ちという不良なユーザーエクスペリエンスに遭遇した正確なトレースまでフィルタリングできました。
このトレースを表示することの二次的な利点は、トレースが最大13か月間アクセス可能であることです。これにより、開発者は後の段階でこの問題に戻り、このトレースを引き続き表示することができます。
次に、トレースウォーターフォールを確認していきます。
トレースアナライザーからトレースウォーターフォールに到達しました。トレースは同じトレースIDを共有するスパンの集まりで、アプリケーションとその構成サービスによって処理される一意のトランザクションを表します。
Splunk APMの各スパンは、単一の操作をキャプチャします。Splunk APMは、スパンがキャプチャする操作がエラーになった場合、そのスパンをエラースパンとみなします。

スパン詳細で報告されているエラーメッセージとバージョンは何ですか?問題を引き起こしているpaymentserviceのバージョンを特定したので、エラーについてさらに詳しい情報が見つかるか確認してみましょう。ここで関連ログの出番です。
演習
paymentservice:grpc.hipstershop.PaymentService/Charge スパンの横にあるをクリックします。
Invalid request(無効なリクエスト)と v350.10 です。
関連コンテンツ(Related Contents)は、APM、インフラストラクチャモニタリング、およびLog Observerが可観測性クラウド全体でフィルターを渡すことを可能にする特定のメタデータに依存しています。関連ログが機能するためには、ログに以下のメタデータが必要です
service.namedeployment.environmenthost.nametrace_idspan_id
次に、ログのエラーについてさらに詳しく調べてみましょう。
バックエンド開発者の役割を継続して、アプリケーションのログを調査して問題の根本原因を特定する必要があります。
APMトレースに関連するコンテンツ(ログ)を使用して、Splunk Log Observerでさらに掘り下げ、問題が正確に何であるかを理解します。
関連コンテンツは、あるコンポーネントから別のコンポーネントにジャンプできる強力な機能で、メトリクス、トレース、ログで利用可能です。
Log Observer (LO)は、複数の方法で使用できます。クイックツアーでは、LO のコード不要インターフェースを使用して、ログ内の特定のエントリを検索しました。しかし、このセクションでは、関連コンテンツリンクを使用してAPMのトレースからLOに到達したと想定しています。
これの利点は、RUMとAPM間のリンクと同様に、以前のアクションのコンテキスト内でログを見ていることです。この場合、コンテキストはトレースの時間枠(1)とtrace_idに設定されたフィルター(2)です。

このビューには、エンドユーザーとオンラインブティックのやり取りによって開始されたバックエンドトランザクションに参加したすべてのアプリケーションまたはサービスからのすべてのログ行が含まれます。
私たちのオンラインブティックのような小さなアプリケーションでさえ、見つかるログの膨大な量により、調査している実際のインシデントに関連する特定のログ行を見つけることが難しくなる場合があります。
ログ内のエラーメッセージだけに焦点を当てる必要があります

sf_service=paymentservice などのサービス名もフィルターに追加できますが、今回のケースでは必要ありません。

次に、ログエントリの詳細を見ていきます。
特定のログ行を見る前に、これまでに行ったことと、可観測性の3本柱に基づいてなぜここにいるのかを簡単に振り返ってみましょう
| メトリクス | トレース | ログ |
|---|---|---|
| 問題がありますか? | 問題はどこですか? | 問題は何ですか? |
v350.9 と v350.10 の2つのバージョンがあり、v350.10 のエラー率は 100% でした。v350.10 からのこのエラーが、複数の再試行とオンラインブティックのチェックアウトからの応答の長い遅延を引き起こしたことを確認しました。hostname: "paymentservice-xxxx" と表示されていることを確認してください)。メッセージに基づいて、問題を解決するために開発チームに何を伝えますか?
開発チームは、有効な API トークンでコンテナを再構築してデプロイするか、v350.9 にロールバックする必要があります。

Splunk Observability Cloudを正常に使用して、オンラインブティックでショッピング中に不良なユーザーエクスペリエンスを体験した理由を理解しました。RUM、APM、ログを使用して、サービス環境で何が起こったかを理解し、その後、可観測性の3本柱であるメトリクス、トレース、ログに基づいて根本原因を見つけました。
また、アプリケーションの動作パターンを検出するためにTag Spotlightでインテリジェントなタグ付けと分析を使用する方法と、問題のコンテキストを維持しながら異なるコンポーネント間を迅速に移動するために関連コンテンツのフルスタック相関パワーを使用する方法も学びました。
ワークショップの次のパートでは、問題発見モードから緩和、防止、プロセス改善モードに移行します。
次は、カスタムダッシュボードでのログチャートの作成です。
Log Observerで特定のビューを持った後、そのビューをダッシュボードで使用できると、将来的に問題の検出や解決にかかる時間を短縮するのに非常に役立ちます。ワークショップの一環として、これらのチャートを使用する例示的なカスタムダッシュボードを作成します。
ログタイムラインチャートの作成を見ていきましょう。ログタイムラインチャートは、時間経過に伴うログメッセージを視覚化するために使用されます。ログメッセージの頻度を確認し、パターンを特定するための優れた方法です。また、環境全体でのログメッセージの分布を確認するための素晴らしい方法でもあります。これらのチャートはカスタムダッシュボードに保存できます。
まず、関心のある列のみに情報量を減らします
_raw のチェックを外し、次のフィールドが選択されていることを確認します:k8s.pod.name、message、version。

trace_id を削除し、フィールド sf_service=paymentservice と sf_environment=[WORKSHOPNAME] を追加します。
ログタイムライン を使用します。イニシャル - サービスヘルスダッシュボード、そしてをクリックします。

次に、ログビューチャートを作成します。
ログで使用できる次のチャートタイプはログビューチャートタイプです。このチャートでは、事前定義されたフィルターに基づいてログメッセージを確認できます。
前回のログタイムラインチャートと同様に、このチャートのバージョンをカスタマーヘルスサービスダッシュボードに追加します
sf_service=paymentservice、sf_environment=[WORKSHOPNAME] でフィルタリングされている必要があります。



次のセッションでは、Splunk Syntheticsを見て、Webベースのアプリケーションのテストを自動化する方法を確認します。
SREの帽子を再び被って、オンラインブティックの監視を設定するよう依頼されました。アプリケーションが24時間365日、利用可能で良好なパフォーマンスを発揮していることを確認する必要があります。
アプリケーションを24時間365日監視し、問題が発生したときにアラートを受け取ることができたらいいと思いませんか?ここでSyntheticsの出番です。オンラインブティックを通じて典型的なユーザージャーニーのパフォーマンスと可用性を毎分チェックする簡単なテストを紹介します。
Splunk Observability Cloudのメインメニューから、Syntheticsをクリックします。AllまたはBrowser testsをクリックして、アクティブなテストのリストを表示します。
RUMセクションでの調査中に、Place orderトランザクションに問題があることがわかりました。Syntheticsテストからもこれを確認できるか見てみましょう。テストの4ページ目のFirst byte timeというメトリクスを使用します。これはPlace orderステップです。

現在、単一のSynthetic Browserテストの結果を見ています。このテストはビジネストランザクションに分割されています。これは、ビジネス上重要なユーザーフローを表す、論理的に関連する1つ以上の操作のグループと考えてください。
以下のスクリーンショットにはエラーを示す赤いバナーは含まれていませんが、あなたの実行結果には表示されている場合があります。これは、場合によってはテスト実行が失敗することがあり、ワークショップに影響しないため予期されることです。

デフォルトでは、Splunk Syntheticsはテストのスクリーンショットとビデオキャプチャを提供します。これは問題のデバッグに役立ちます。例えば、大きな画像の読み込みが遅い、ページのレンダリングが遅いなどを確認できます。
今、以下のような表示が見えているはずです。


これらのテストを24時間365日実行できるため、テストが失敗したり、合意したSLAよりも長く実行され始めた場合に、ソーシャルメディアやアップタイムウェブサイトから通知される前に、早期に警告を受けるための理想的なツールです。

そのような事態を防ぐために、テストが1.1分以上かかっているかどうかを検知しましょう。
左側のメニューからSyntheticsホームページに戻ります
ワークショップのテストを再度選択し、ページ上部のボタンをクリックします。
New Synthetics Detectorというテキスト(1)を編集し、イニシャル -[ワークショップ名]に置き換えます。
とが選択されていることを確認します。
Trigger threasholt(2)を 65,000〜68,000 に設定し、Enterキーを押してチャートを更新します。上図のように、しきい値ラインを切る複数のスパイクがあることを確認してください(実際のレイテンシーに合わせてしきい値を少し調整する必要があるかもしれません)。
残りはデフォルトのままにします。
スパイクの下に赤と白の三角形の列が表示されるようになったことに注意してください(3)。赤い三角形は、テストが指定されたしきい値を超えたことをDetectorが検出したことを知らせ、白い三角形は結果がしきい値を下回ったことを示します。各赤い三角形がアラートをトリガーします。
アラートの重大度(4)は、ドロップダウンを別のレベルに変更することで変更できます。また、アラート方法も変更できます。受信者を追加しないでください。アラートストームの対象になる可能性があります!
をクリックして、 Detectorをデプロイします。
新しく作成したDetectorを見るには、ボタンをクリックします。
ページの下部にアクティブなDetectorのリストがあります。

あなたのDetectorが見つからず、新しい Synthetics Detectorという名前のものが表示されている場合は、あなたの名前で正しく保存されていない可能性があります。新しい Synthetics Detectorのリンクをクリックして、名前の変更をやり直してください。
ボタンをクリックして編集モードを終了します。
SREの帽子が似合っているので、引き続き着用してpaymentservice用のカスタムサービスヘルスダッシュボードの構築を依頼されたと想定します。要件はREDメトリクス、ログ、Syntheticテスト期間の結果を表示することです。
開発チームとSREチームが、アプリケーションやサービスの健全性の概要を必要とすることは一般的です。これらは多くの場合、壁に取り付けられたTVに表示されます。Splunk Observability Cloudは、カスタムダッシュボードを作成することでこれに最適なソリューションを提供しています。
このセクションでは、チームのモニターやTVに表示するためのサービスヘルスダッシュボードを構築します。
Log Observer演習ですでにいくつかの便利なログチャートをダッシュボードに保存したので、そのダッシュボードを拡張していきます。



これは素晴らしいですね。引き続き、より意味のあるチャートを追加していきましょう。
ワークショップのこのパートでは、ダッシュボードに追加するチャートを作成し、また以前に構築したディテクターにリンクします。これにより、テストの動作を確認し、1つ以上のテスト実行がSLAを違反した場合にアラートを受け取ることができます。

synthetics.run.duration.time.ms(これはテストの実行時間です)と入力し、Enterキーを押します。mean:aggregation を選択してダイアログボックスの外をクリックします。メトリクスが集計されるため、チャートが単色に変わることに注目してください。


時間があれば、RUMメトリクスを使用してダッシュボードにもう1つのカスタムチャートを追加してみてください。既製のRUM アプリケーションダッシュボードグループからチャートをコピーすることができます。または、RUMメトリクス rum.client_error.count を使用して、アプリケーションのクライアントエラー数を表示するチャートを作成することもできます。
最後に、ワークショップのまとめを行います。
おめでとうございます。Splunk4Rookies - Observability Cloud ワークショップを修了しました。今日はSplunk Observability Cloudを使用してアプリケーションとインフラストラクチャを監視する方法に慣れました。
この修了証をあなたのLinkedIn プロフィールに追加して成果をアピールしましょう。
私たちが学んだことと次にできることを振り返ってみましょう。
このワークショップを通じて、Splunk Observability CloudとOpenTelemetryシグナル(メトリクス、トレース、ログ)の組み合わせが、検出までの平均時間(MTTD)と解決までの平均時間(MTTR)をどのように短縮できるかを見てきました。




次に、WebとモバイルトラフィックをシミュレートできるSyntheticsを調べ、利用可能なSyntheticsテストを使用して、まずRUM/APMとLog Observerでの発見を確認し、次にテストの実行時間がSLAを超えた場合にアラートを受け取るためのディテクターを作成しました。
最後の演習では、開発者とSREのためにTVスクリーンで継続的に表示するヘルスダッシュボードを作成しました
