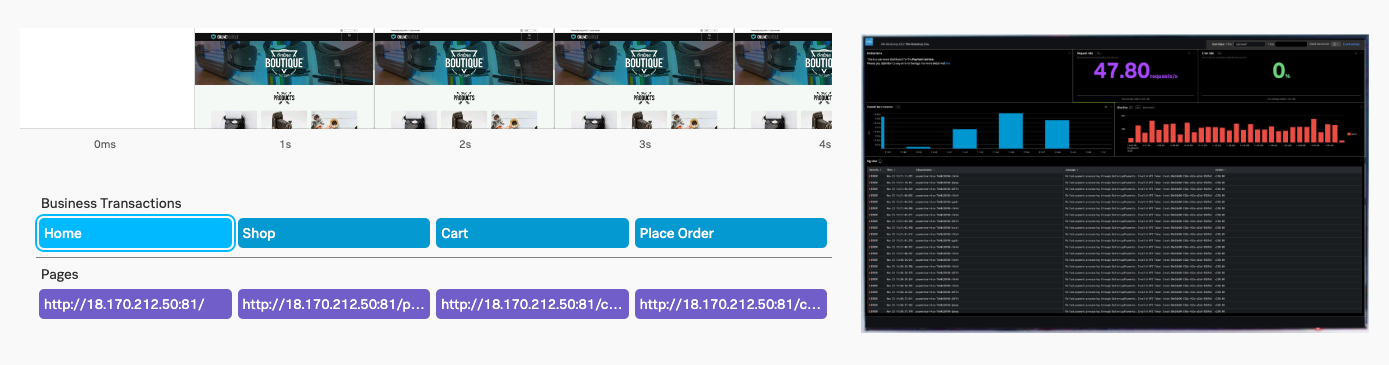
主要なポイント
このワークショップを通じて、Splunk Observability CloudとOpenTelemetryシグナル(メトリクス、トレース、ログ)の組み合わせが、検出までの平均時間(MTTD)と解決までの平均時間(MTTR)をどのように短縮できるかを見てきました。
- メインユーザーインターフェイスとそのコンポーネント、ランディング、インフラストラクチャ、APM、RUM、Synthetics、ダッシュボードページ、そして設定ページについて理解を深めました。
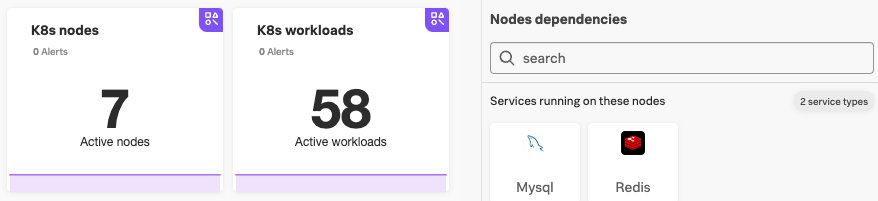
- 時間に応じて、インフラストラクチャの演習を行い、Kubernetesナビゲーターで使用されるメトリクスを確認し、Kubernetesクラスターで見つかった関連サービスを見ました
- ユーザーが何を体験しているかを理解し、RUMとAPMを使用して特に長いページ読み込みのトラブルシューティングを行いました。フロントエンドとバックエンド全体でトレースをたどり、ログエントリーまで追跡しました。 RUMのセッション再生とAPMの依存関係マップを使用し、ブレークダウン機能を使って問題の原因を発見しました
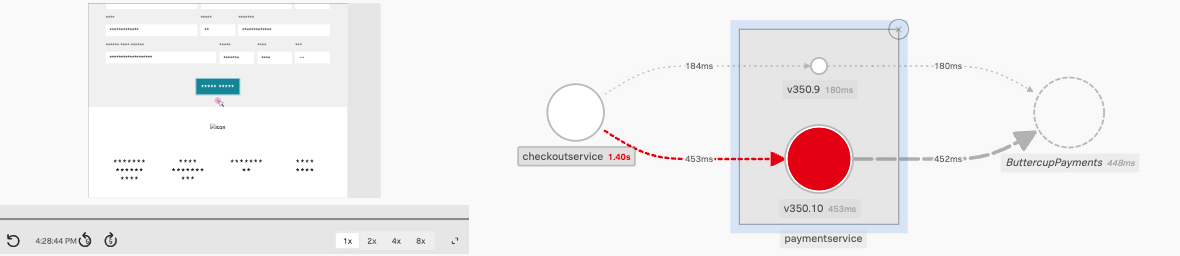
- RUMとAPMの両方でTag Spotlightを使用して、影響範囲を理解し、パフォーマンス問題とエラーのトレンドやコンテキストを検出しました。APMのトレースウォーターフォールでスパンを詳しく調べ、サービスがどのように相互作用し、エラーを見つけました

- 関連コンテンツ機能を使用して、トレースからトレースに関連するログへの直接のリンクをたどり、フィルターを使用して問題の正確な原因まで掘り下げました。

次に、WebとモバイルトラフィックをシミュレートできるSyntheticsを調べ、利用可能なSyntheticsテストを使用して、まずRUM/APMとLog Observerでの発見を確認し、次にテストの実行時間がSLAを超えた場合にアラートを受け取るためのディテクターを作成しました。
最後の演習では、開発者とSREのためにTVスクリーンで継続的に表示するヘルスダッシュボードを作成しました