Making Your Observability Cloud Native With OpenTelemetry
1 hour Author Robert CastleyAbstract
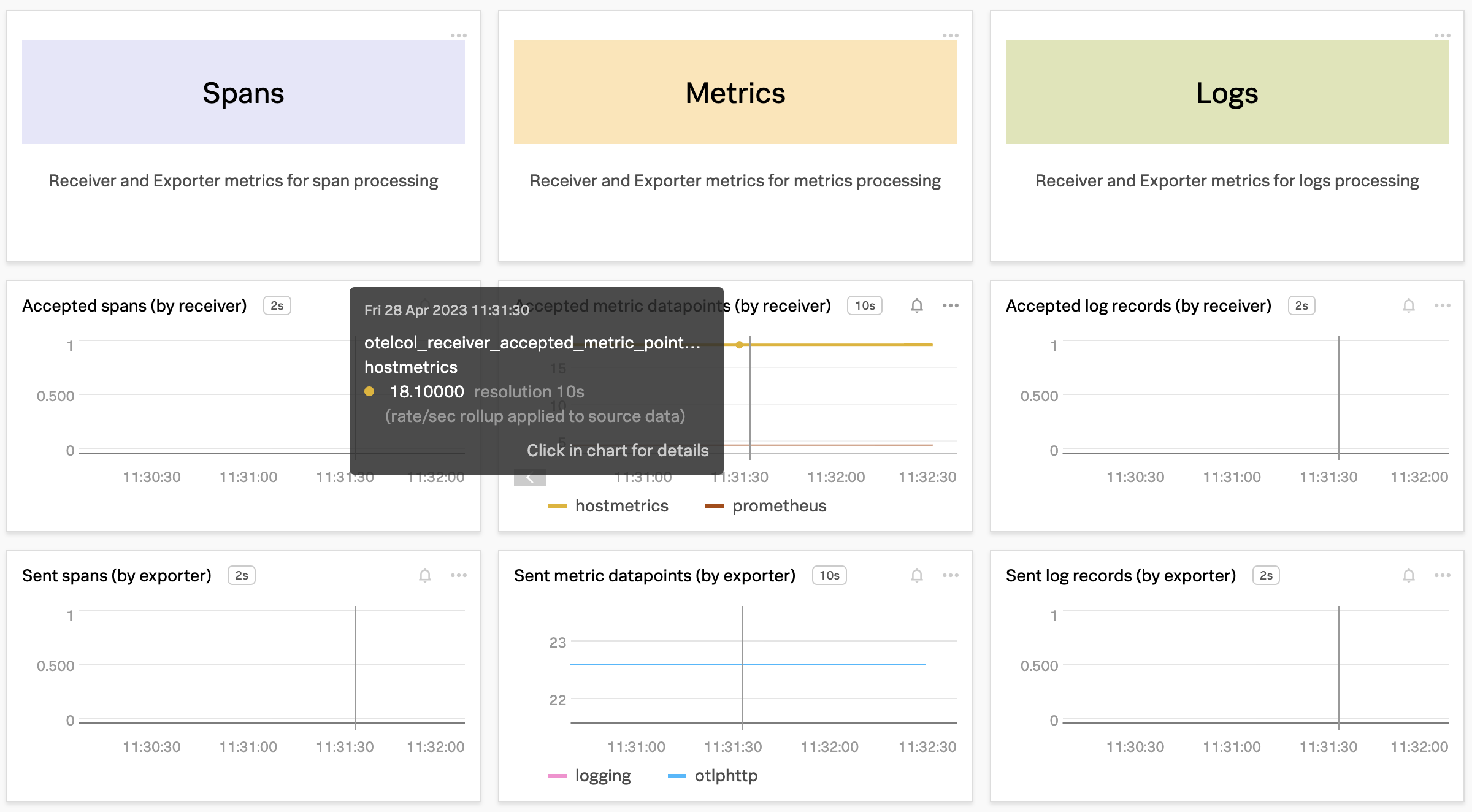
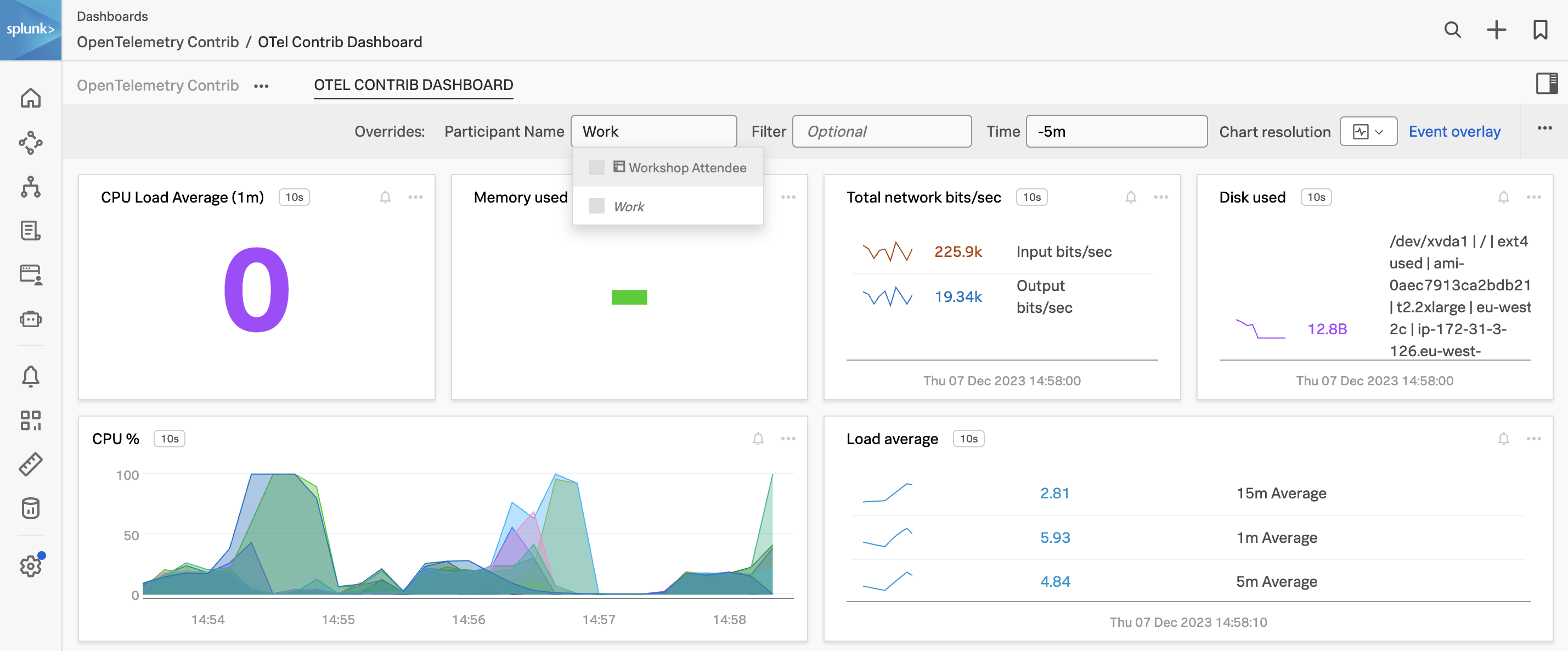
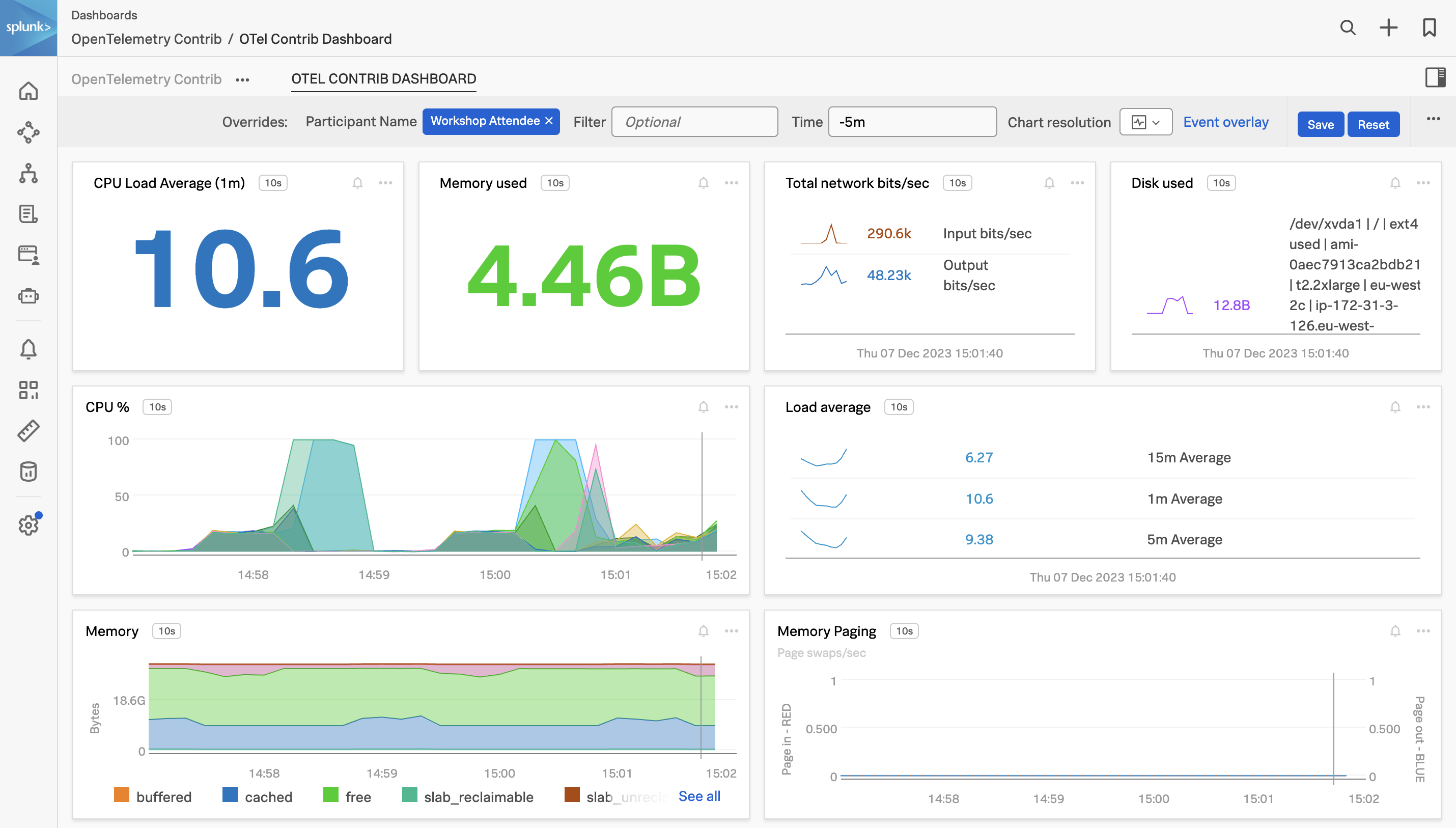
Organizations getting started with OpenTelemetry may begin by sending data directly to an observability backend. While this works well for initial testing, using the OpenTelemetry collector as part of your observability architecture provides numerous benefits and is recommended for any production deployment.
In this workshop, we will be focusing on using the OpenTelemetry collector and starting with the fundamentals of configuring the receivers, processors, and exporters ready to use with Splunk Observability Cloud. The journey will take attendees from novices to being able to start adding custom components to help solve for their business observability needs for their distributed platform.
Ninja Sections
Throughout the workshop there will be expandable Ninja Sections, these will be more hands on and go into further technical detail that you can explore within the workshop or in your own time.
Please note that the content in these sections may go out of date due to the frequent development being made to the OpenTelemetry project. Links will be provided in the event details are out of sync, please let us know if you spot something that needs updating.
Target Audience
This interactive workshop is for developers and system administrators who are interested in learning more about architecture and deployment of the OpenTelemetry Collector.
Prerequisites
- Attendees should have a basic understanding of data collection
- Command line and vim/vi experience.
- A instance/host/VM running Ubuntu 20.04 LTS or 22.04 LTS.
- Minimum requirements are an AWS/EC2 t2.micro (1 CPU, 1GB RAM, 8GB Storage)
Learning Objectives
By the end of this talk, attendees will be able to:
- Understand the components of OpenTelemetry
- Use receivers, processors, and exporters to collect and analyze data
- Identify the benefits of using OpenTelemetry
- Build a custom component to solve their business needs
OpenTelemetry Architecture
%%{
init:{
"theme":"base",
"themeVariables": {
"primaryColor": "#ffffff",
"clusterBkg": "#eff2fb",
"defaultLinkColor": "#333333"
}
}
}%%
flowchart LR;
subgraph Collector
A[OTLP] --> M(Receivers)
B[JAEGER] --> M(Receivers)
C[Prometheus] --> M(Receivers)
end
subgraph Processors
M(Receivers) --> H(Filters, Attributes, etc)
E(Extensions)
end
subgraph Exporters
H(Filters, Attributes, etc) --> S(OTLP)
H(Filters, Attributes, etc) --> T(JAEGER)
H(Filters, Attributes, etc) --> U(Prometheus)
end