Optimize Cloud Monitoring
3 minutes Author Tim HardThe elasticity of cloud architectures means that monitoring artifacts must scale elastically as well, breaking the paradigm of purpose-built monitoring assets. As a result, administrative overhead, visibility gaps, and tech debt skyrocket while MTTR slows. This typically happens for three reasons:
- Complex and Inefficient Data Management: Infrastructure data is scattered across multiple tools with inconsistent naming conventions, leading to fragmented views and poor metadata and labelling. Managing multiple agents and data flows adds to the complexity.
- Inadequate Monitoring and Troubleshooting Experience: Slow data visualization and troubleshooting, cluttered with bespoke dashboards and manual correlations, are hindered further by the lack of monitoring tools for ephemeral technologies like Kubernetes and serverless functions.
- Operational and Scaling Challenges: Manual onboarding, user management, and chargeback processes, along with the need for extensive data summarization, slow down operations and inflate administrative tasks, complicating data collection and scalability.
To address these challenges you need a way to:
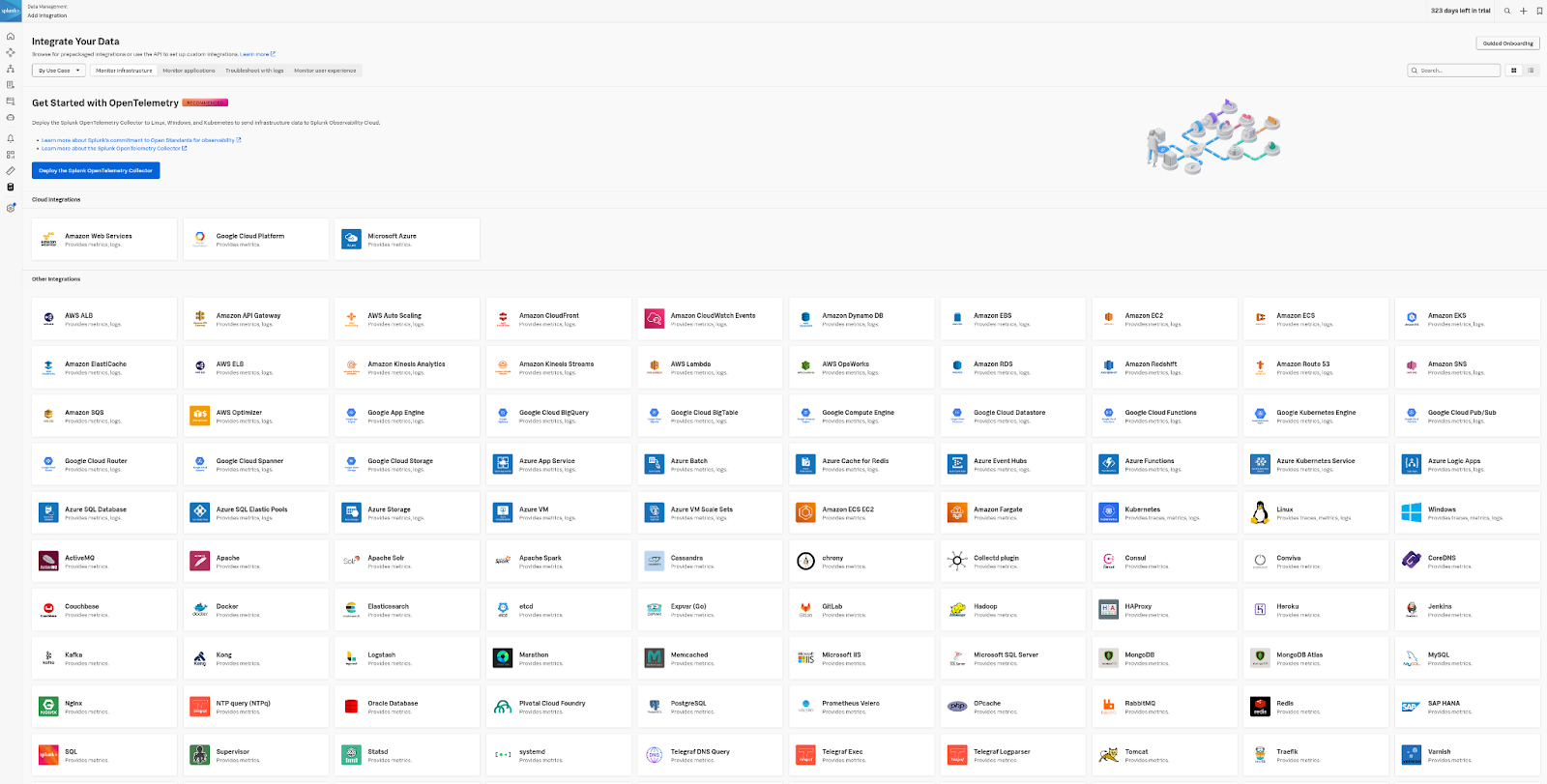
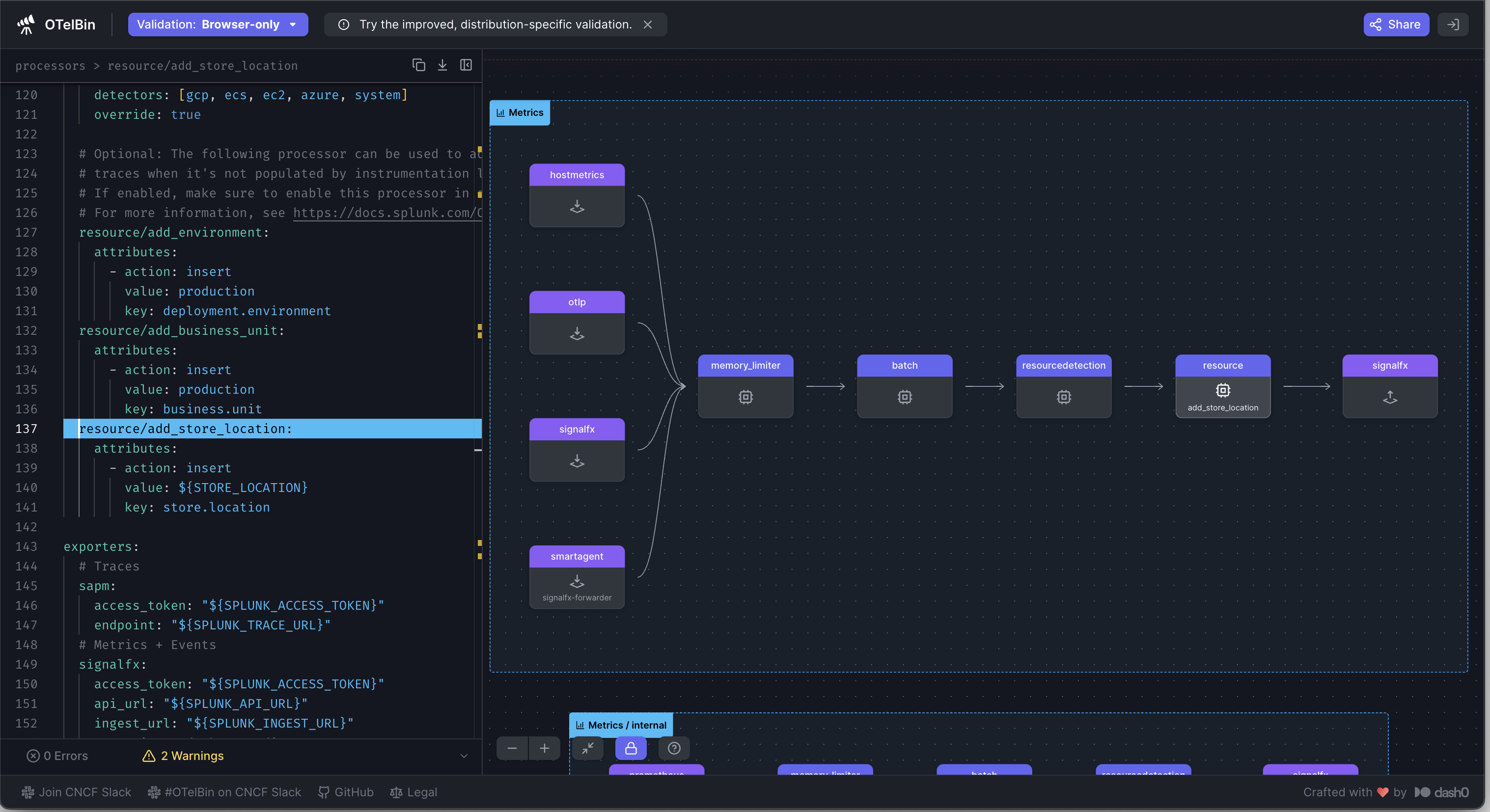
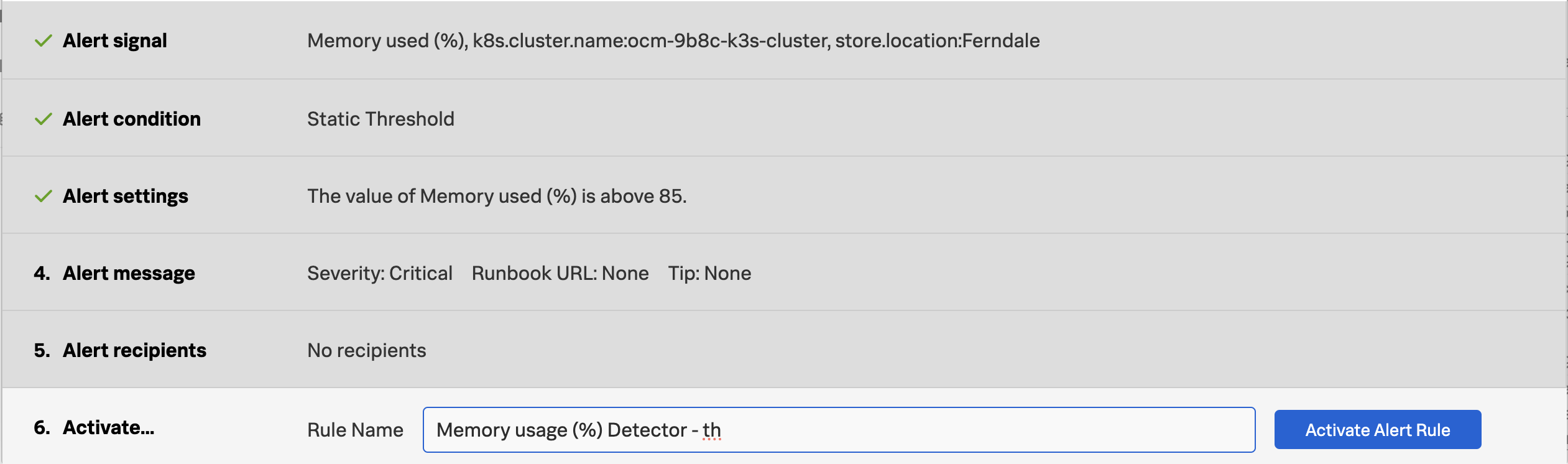
- Standardize Data Collection and Tags: Centralized monitoring with a single, open-source agent to apply uniform naming standards and ensure metadata for visibility. Optimize data collection and use a monitoring-as-code approach for consistent collection and tagging.
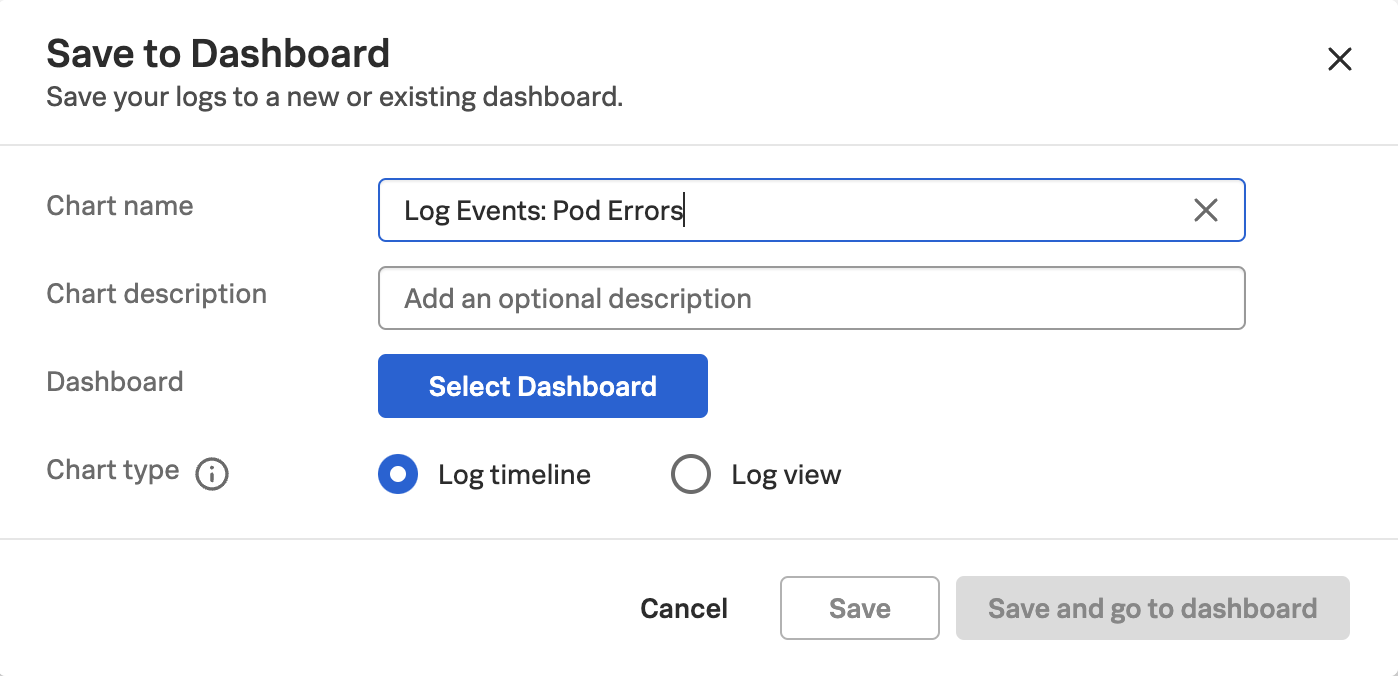
- Reuse Content Across Teams: Streamline new IT infrastructure onboarding and user management with templates and automation. Utilize out-of-the-box dashboards, alerts, and self-service tools to enable content reuse, ensuring uniform monitoring and reducing manual effort.
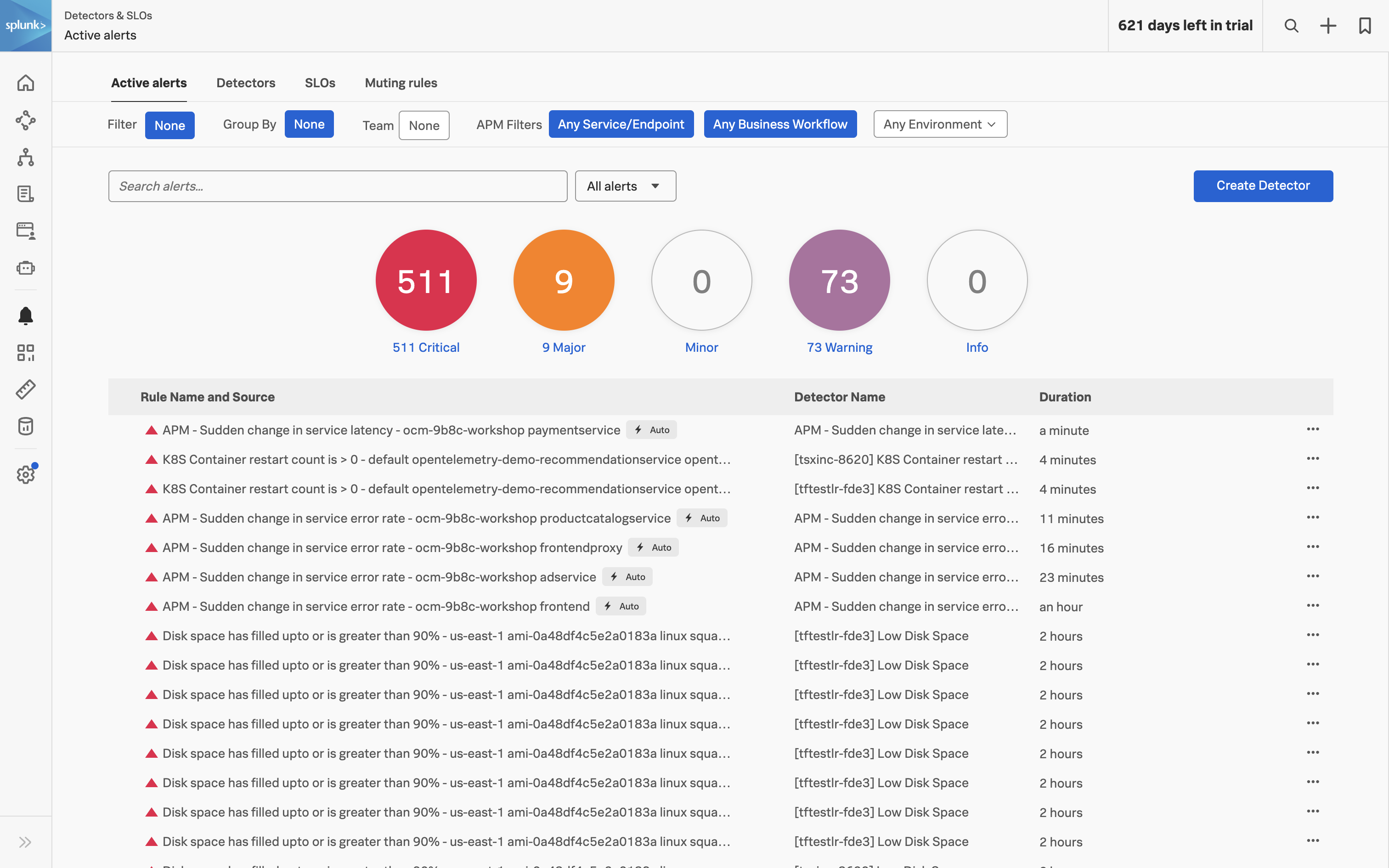
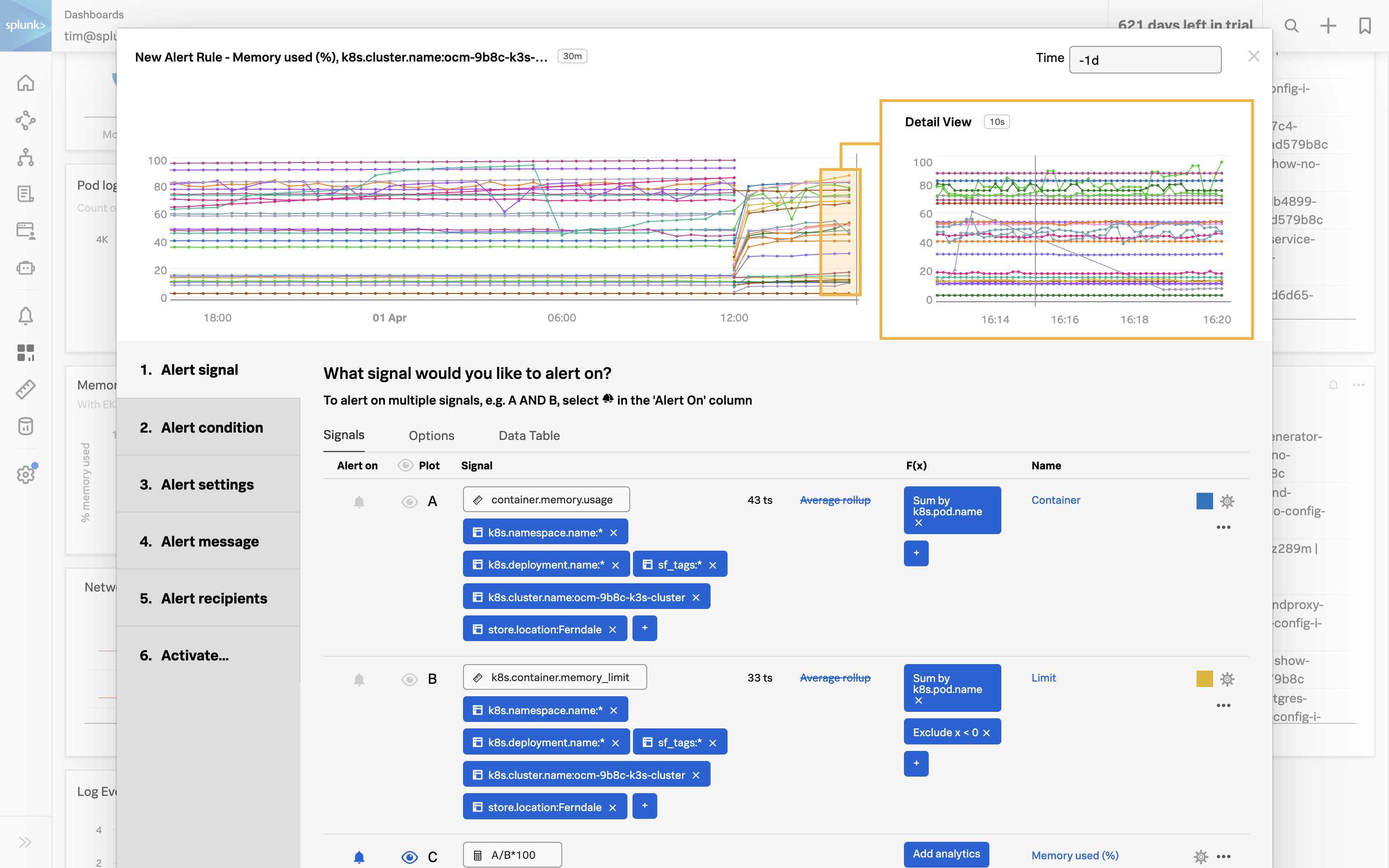
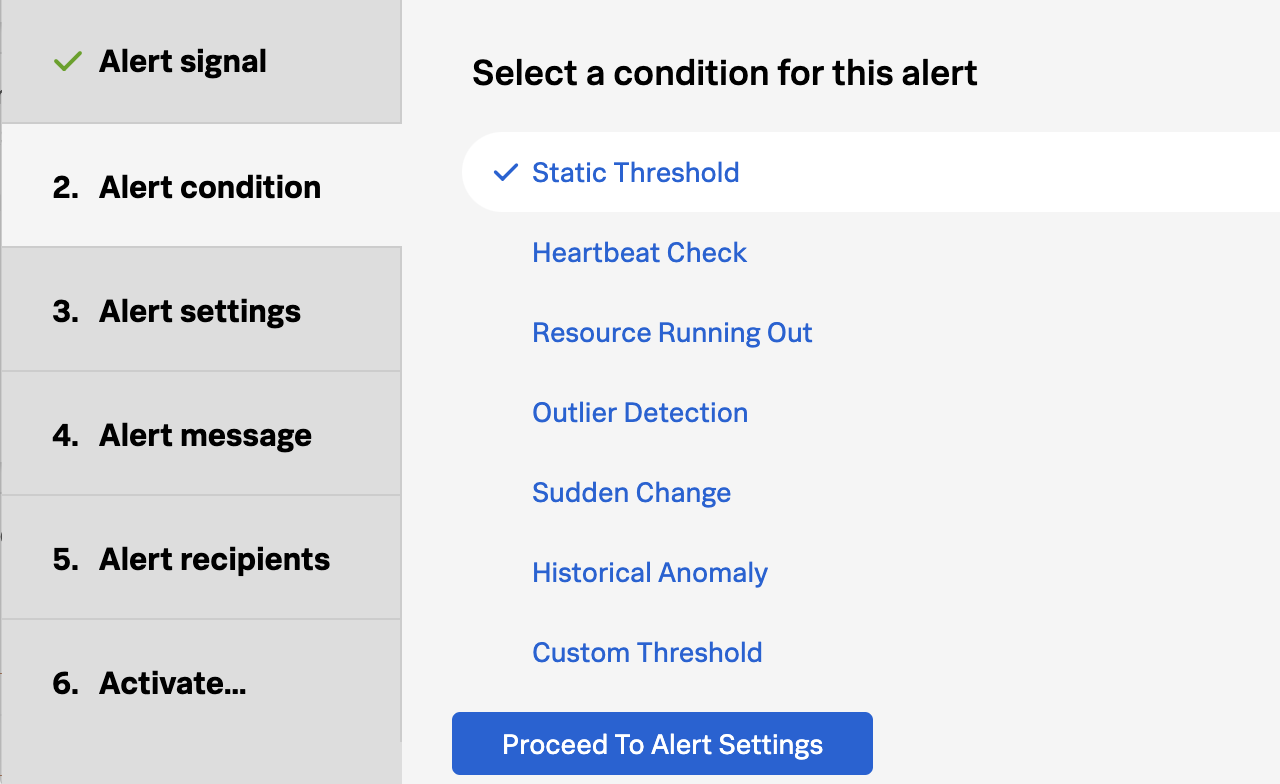
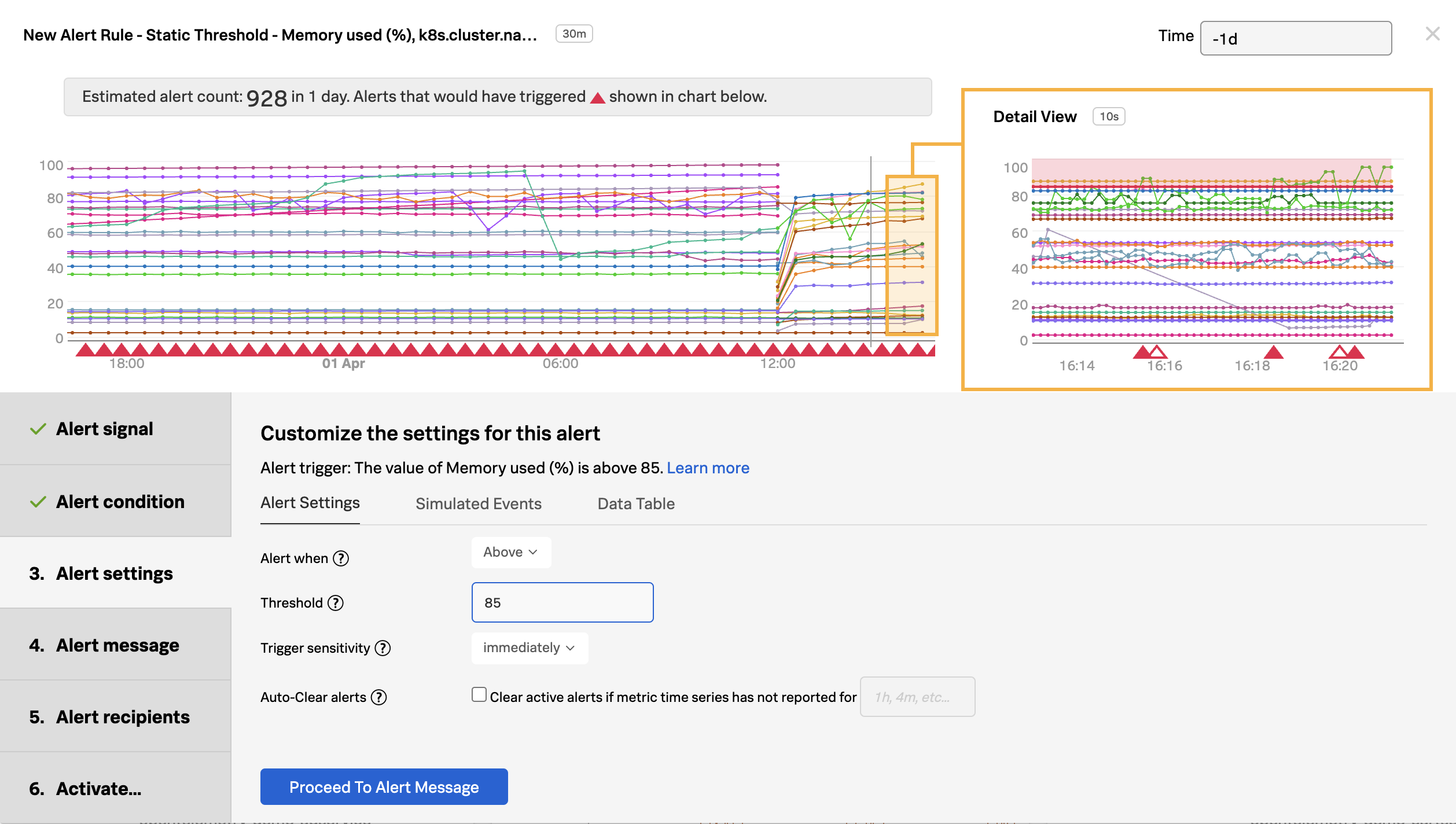
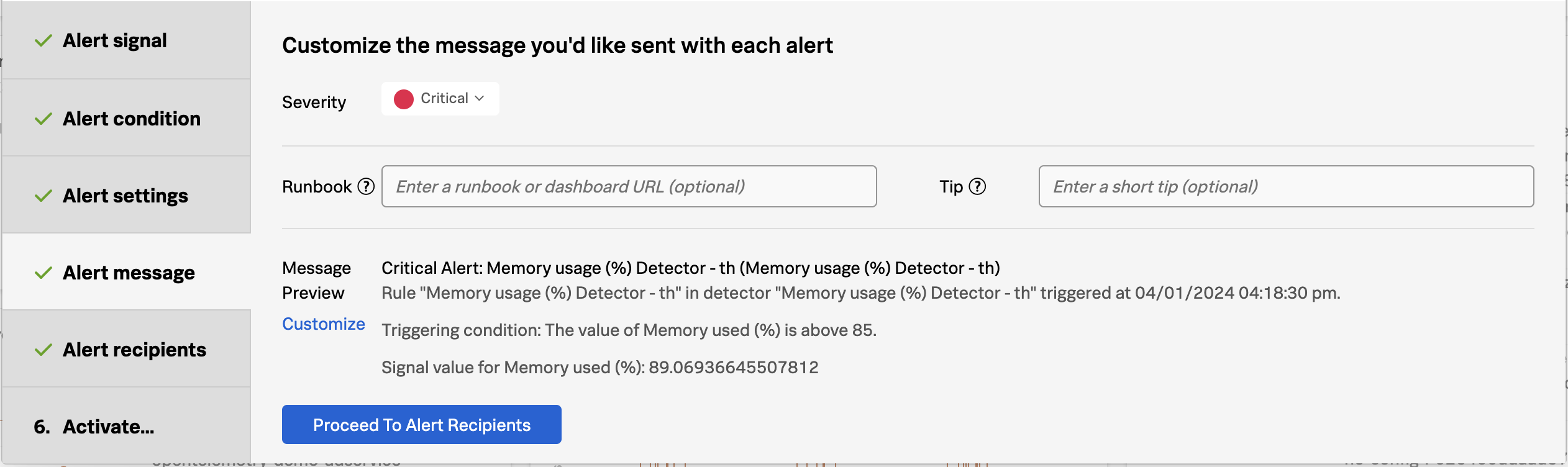
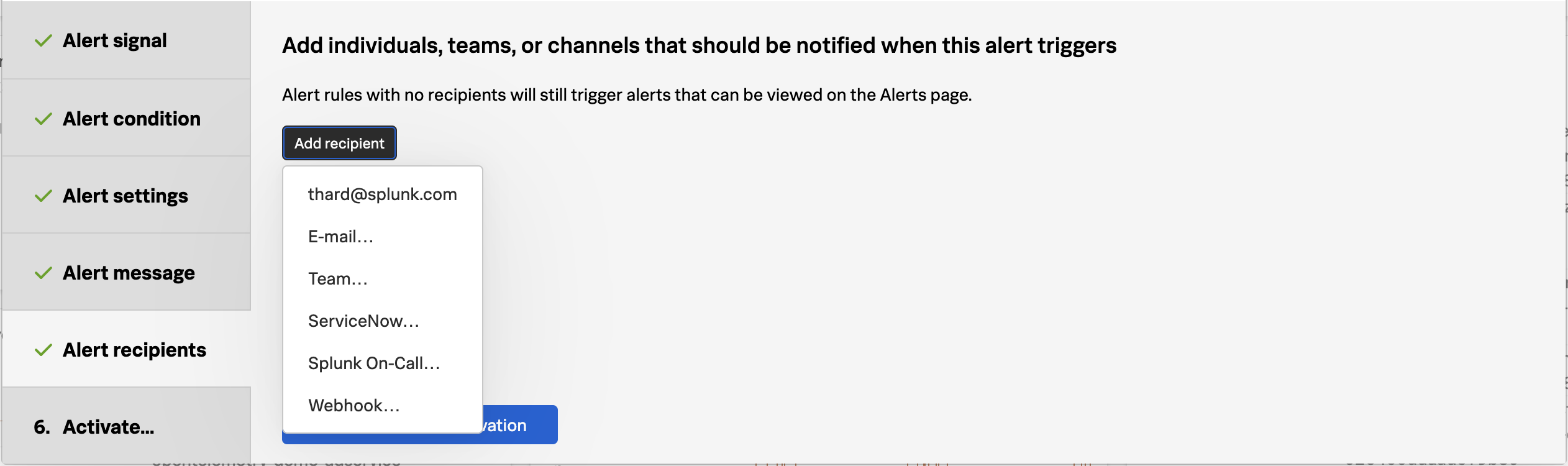
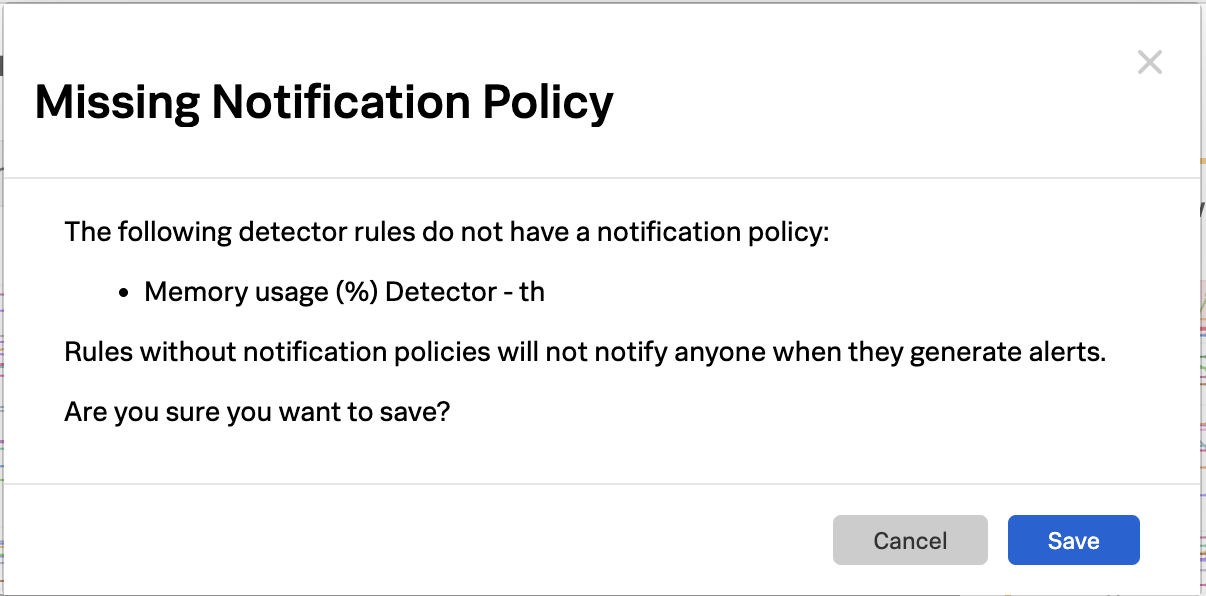
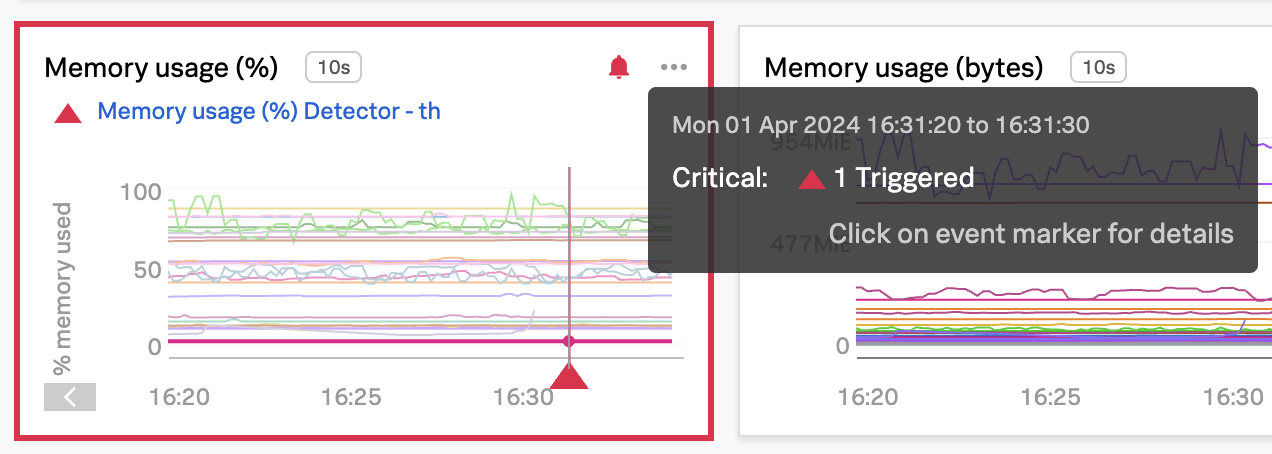
- Improve Timeliness of Alerts: Utilize highly performant open source data collection, combined with real-time streaming-based data analytics and alerting, to enhance the timeliness of notifications. Automatically configured alerts for common problem patterns (AutoDetect) and minimal yet effective monitoring dashboards and alerts will ensure rapid response to emerging issues, minimizing potential disruptions.
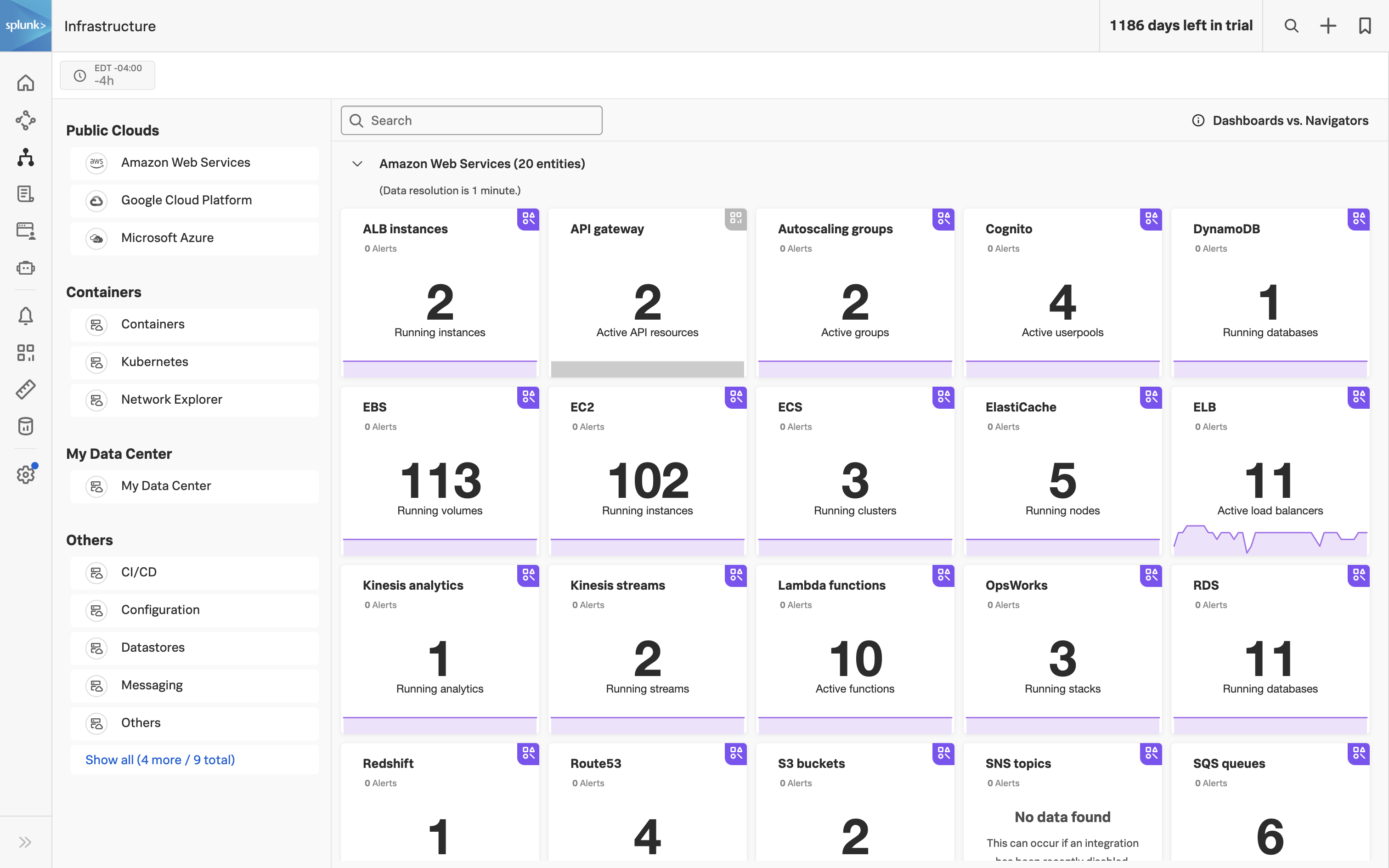
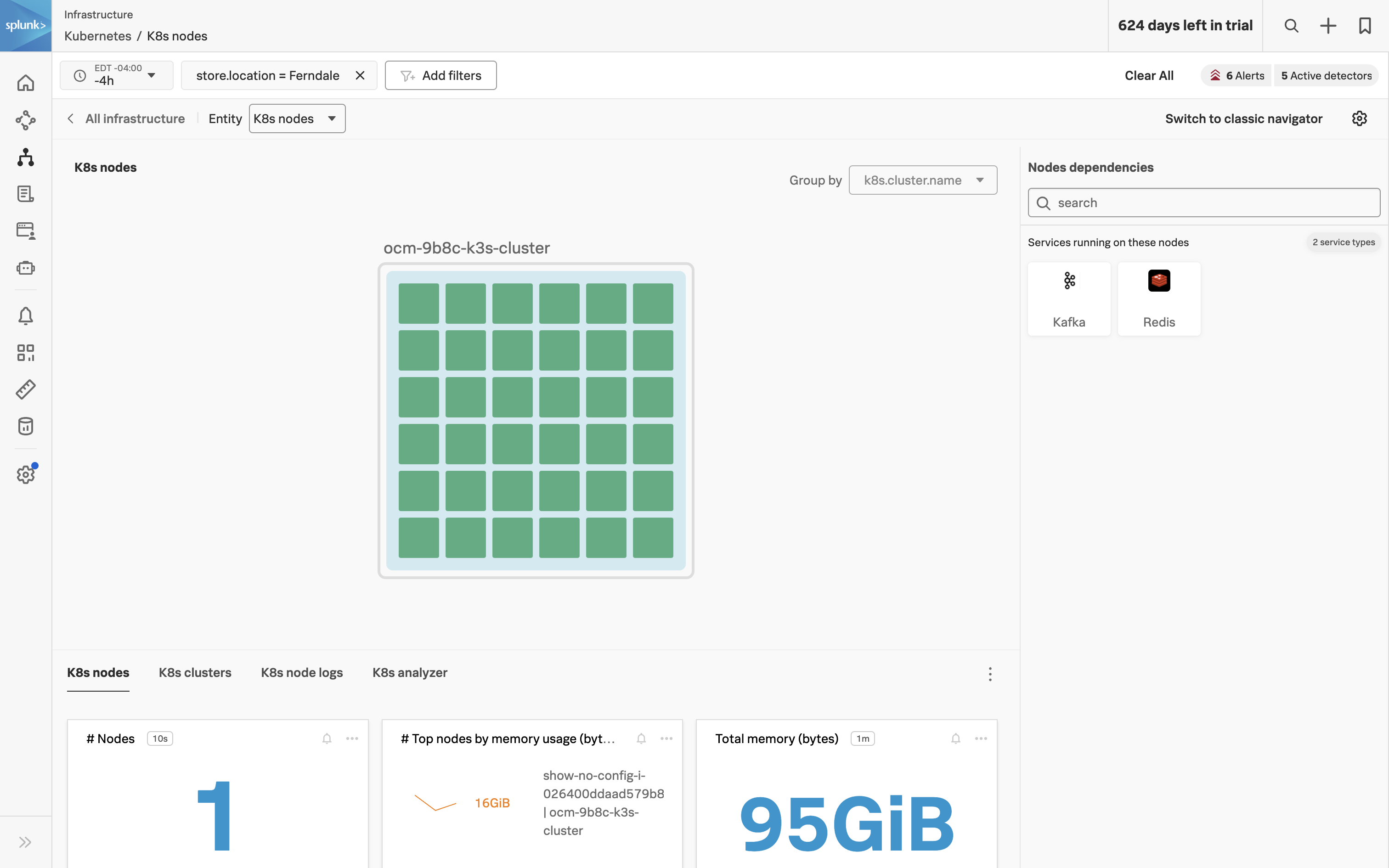
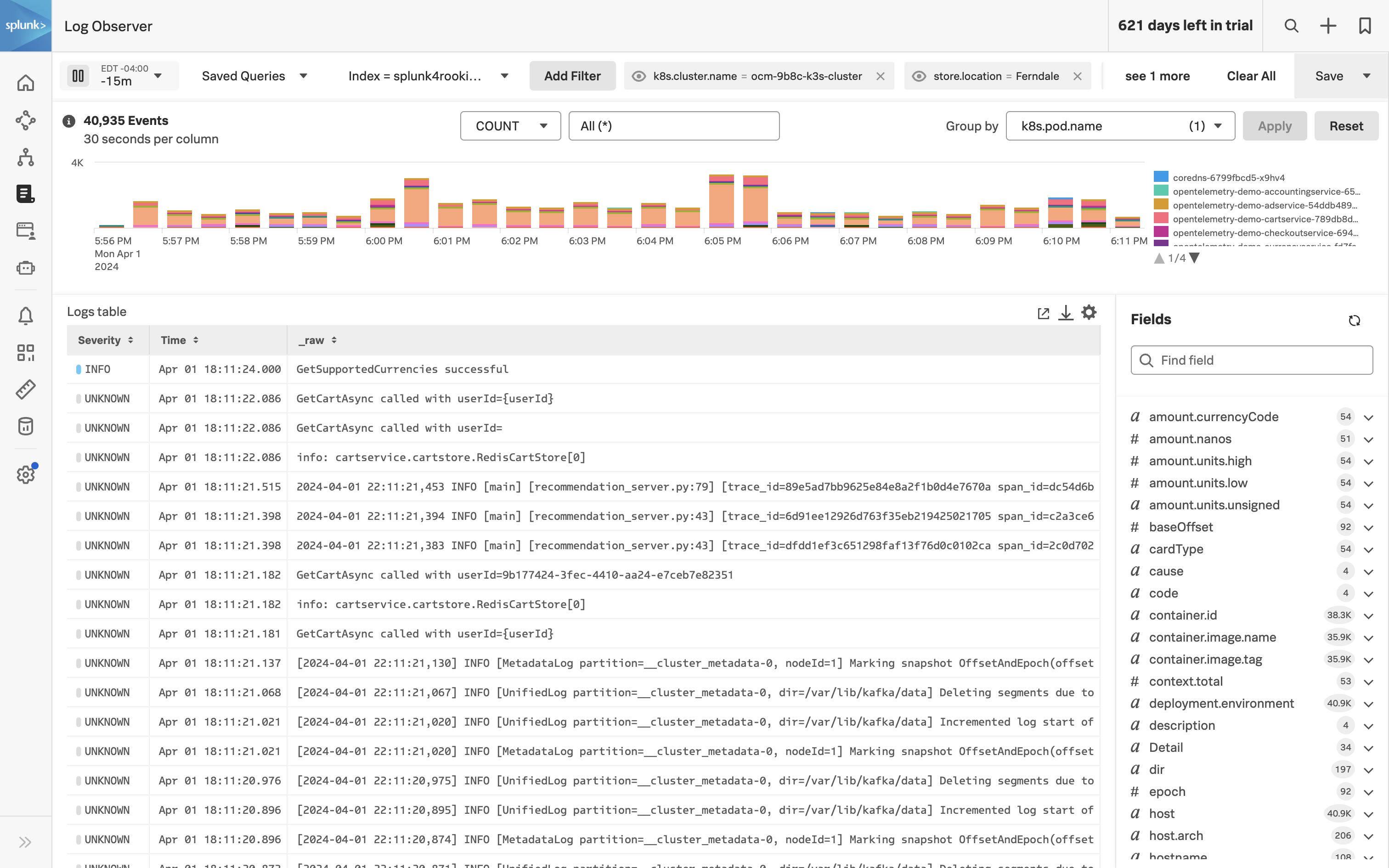
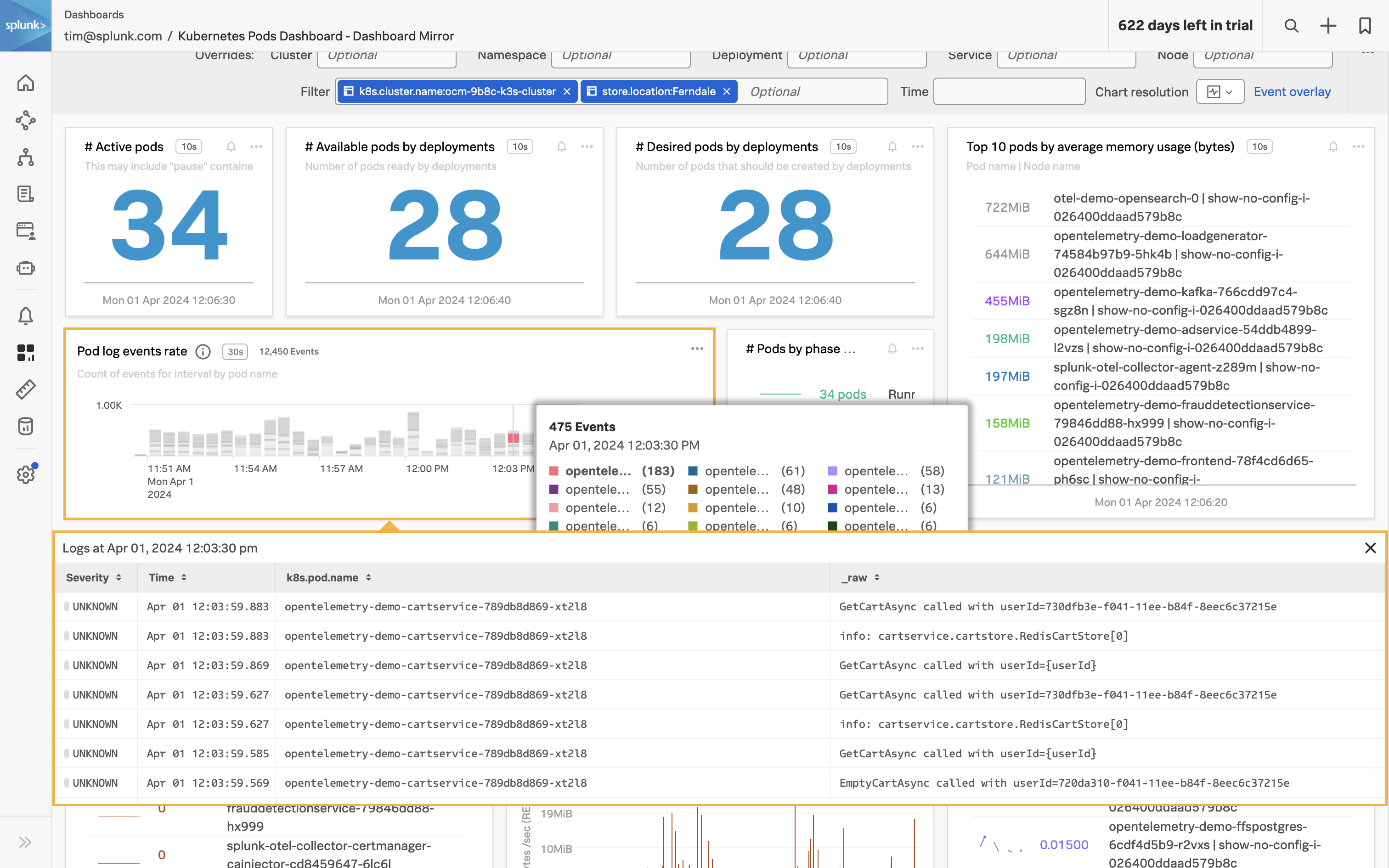
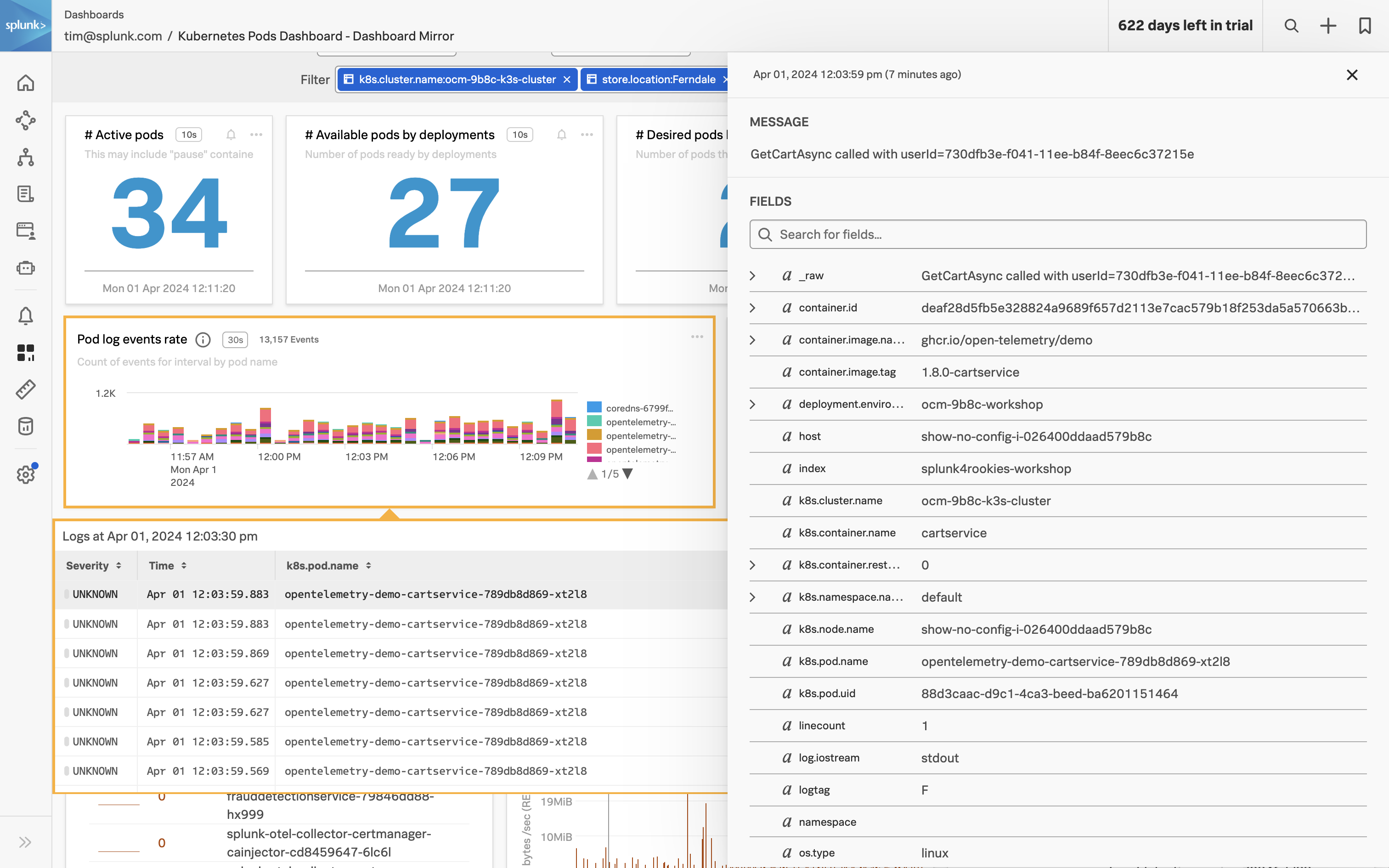
- Correlate Infrastructure Metrics and Logs: Achieve full monitoring coverage of all IT infrastructure by enabling seamless correlation between infrastructure metrics and logs. High-performing data visualization and a single source of truth for data, dashboards, and alerts will simplify the correlation process, allowing for more effective troubleshooting and analysis of the IT environment.
In this workshop, we’ll explore:
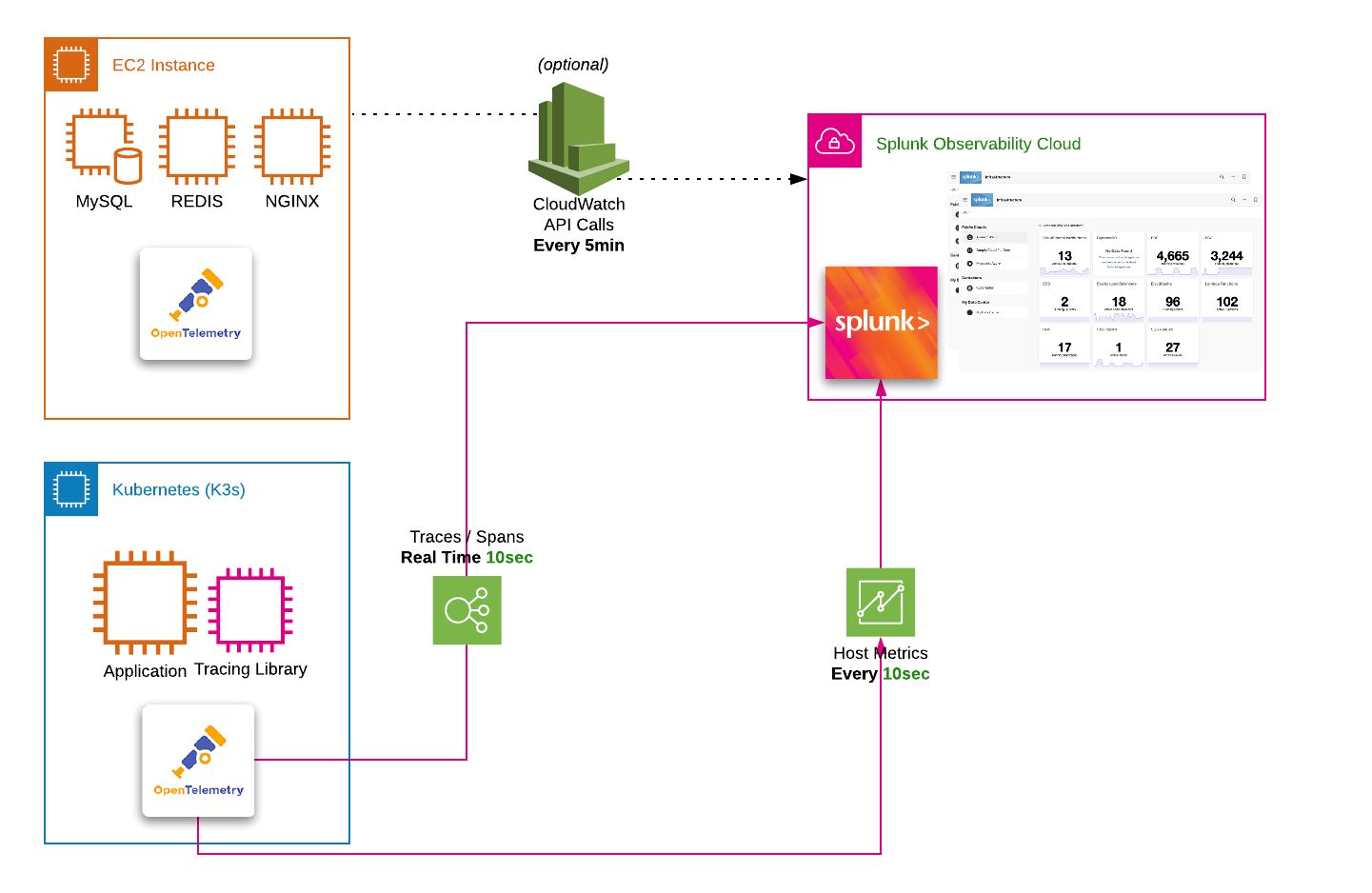
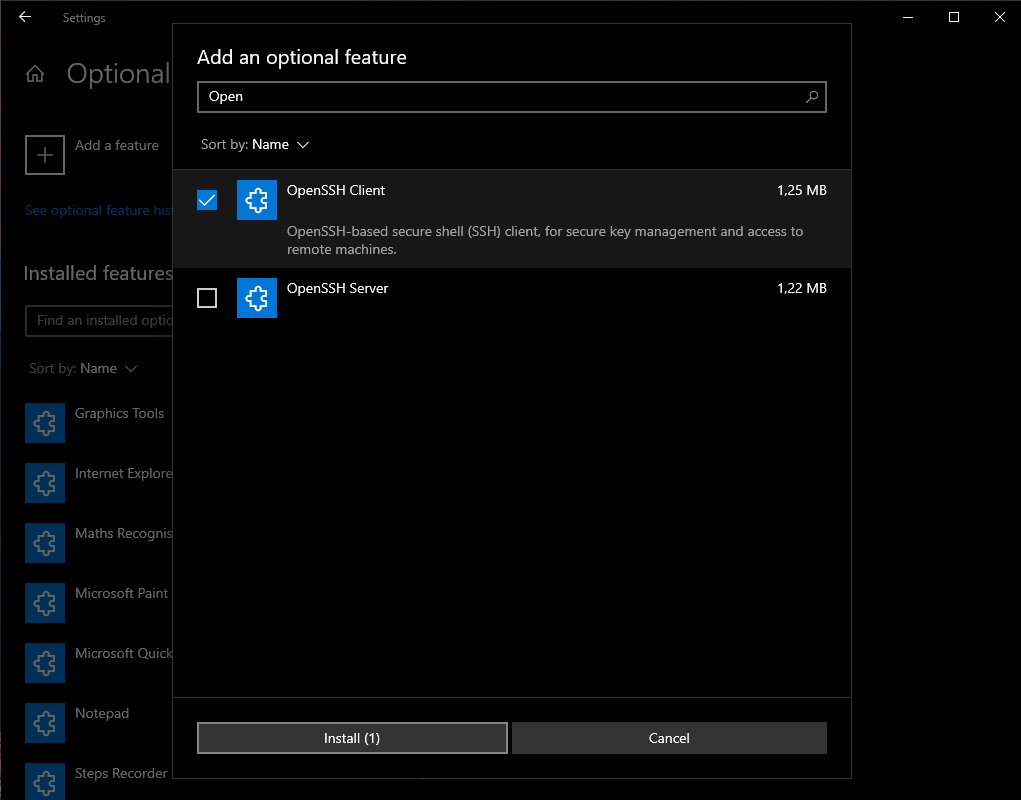
- How to standardize data collection and tags using OpenTelemetry.
- How to reuse content across teams.
- How to improve timelines of alerts.
- How to correlate infrastructure metrics and logs.
Tip
The easiest way to navigate through this workshop is by using:
- the left/right arrows (< | >) on the top right of this page
- the left (◀️) and right (▶️) cursor keys on your keyboard