ワークショップの概要
2分イントロダクション
このワークショップのゴールは、ある問題を体験し、Splunk Observability Cloud を使用してトラブルシューティングを行い、根本原因を特定することです。これを実現するために、私たちは Kubernetes で動作する完全なマイクロサービスベースのアプリケーションを提供し、それが Splunk Observability Cloud にメトリクス、トレース、ログを送信するように計装しています。
参加対象者は?
Splunk Observability をハンズオンの環境で理解したいと考えている方。このワークショップは、ほとんど、または、まったく Splunk Observability の経験がない人向けに設計されています。
必要なものは何ですか?
皆様自身の参加と、パソコン、外部のウェブサイトにアクセスできるブラウザがあれば十分です。私たちはこれらのワークショップを対面、または、Zoom で実施しています。あなたのデバイスに Zoom クライアントがない場合でも、ウェブブラウザを通じてワークショップ環境にアクセスすることができます。
このワークショップで何がカバーされていますか?
この3時間のセッションでは、ハンズオンの環境でストリーミング分析、NoSample™ で完全忠実な分散トレーシングを備えた唯一の可観測性プラットフォームである Splunk Observability の基本を学びます。
OpenTelemetry
なぜ OpenTelemetry が必要なのか、そして、それが可観測性にとってなぜ重要なのかについて簡単に紹介します。
Splunk Observability ユーザーインターフェースのツアー
Splunk Observability Cloud のさまざまなコンポーネントを渡り歩きながら、5つの主要なコンポーネント(APM、RUM、Log Observer、Synthetics、Infrastructure)を操作する方法を紹介します。
リアルユーザーデータの生成
オンラインブティックというウェブサイトを使用してお買い物を楽しみます。ブラウザ、モバイル、タブレットを使用し、架空の通貨で買い物を行っていただきます。これを通じて、 メトリクス(問題があるのか?)、トレース(問題はどこにあるのか?)、ログ(問題は何か?) を送信します。
Splunk Real User Monitoring (RUM)
すべての参加者のブラウザセッションから受信するテレメトリーデータに基づいて実際のユーザーのデータを調査します。ここでのゴールは、パフォーマンスが悪かったブラウザ、モバイル、タブレットのセッションを見つけて、トラブルシューティングのプロセスを開始することです。
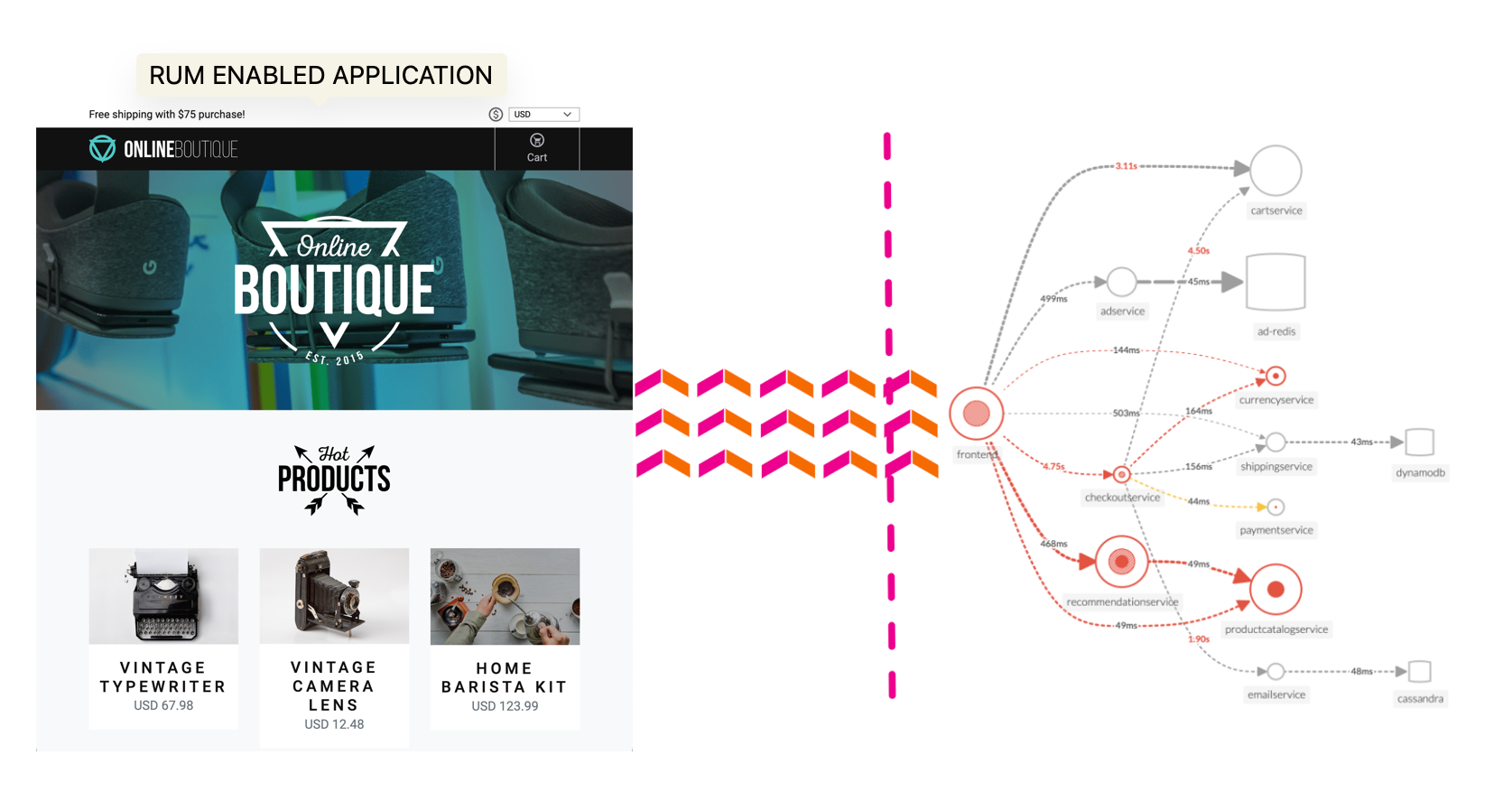
RUM トレース(フロントエンド)から APM トレース(バックエンド)へとジャンプすることで、End to End 全体を可視化する能力を理解しましょう。すべてのサービスはテレメトリー(トレースとスパン)を送信しており、Splunk Observability Cloud はそれを可視化・分析し、異常やエラーを検出するために使用することができます。
Splunk Log Observer (LO)
Related Content の強力な機能を使うと、あるコンポーネントから別のコンポーネントにジャンプすることが可能になります。ここでは、私たちは APM トレースから、そのトレースに関連するログにジャンプします。
Splunk Synthetics
私たちのアプリケーションを24時間365日で監視し、問題が発生したときにアラートを受け取ることができたら素晴らしいことではないでしょうか? これが Synthetics の役割です。オンラインブティックサイトでの典型的なユーザージャーニーのパフォーマンスと可用性を1分ごとにチェックするシンプルなテストをご紹介します。
OpenTelemetry とは何か、なぜ注目するべきなのか?
2分OpenTelemetry
クラウドコンピューティングやマイクロサービスアーキテクチャ、更に、ますます複雑になりつつあるビジネス要件の台頭により、可観測性へのニーズはこれまで以上に高まっています。可観測性とは、システムの内部状態をその出力を調べることで理解する能力のことです。ソフトウェアの文脈では、メトリクス、トレース、およびログを含むテレメトリーデータに基づいてシステムの内部状態を理解する能力を意味します。
システムを観測可能にするためには、計装が必要です。つまり、コードはトレース、メトリクス、およびログを出力する必要があります。その上で、計装によって出力されたデータが、Splunk Observability Cloud などの可観測性バックエンドに送信される必要があります。
| メトリクス | トレース | ログ |
|---|
| 問題があるのか? | 問題はどこにあるのか? | 問題は何か? |
OpenTelemetry は2つの重要な側面を持ちます。
- プロプライエタリなデータ形式やツールに縛られることなく、自分が生成するデータを自分のものとすることを可能にします。
- 単一の API と規約を学ぶことを可能にします
この2つが組み合わさることで、チームや組織は今日の現代的なコンピューティングの世界で必要な柔軟性を得ることができます。
可観測性に取りかかるときに考慮すべきことはたくさんありますが、その中でも重要な質問は 「どのようにして可観測性ツールにデータを取り込むのか?」 というものです。OpenTelemetry の業界全体での採用により、これまで以上に簡単に、この質問に答えることができるようになっています。
なぜ注目するべきなのか?
OpenTelemetry は完全にオープンソースで、無料で使用することができます。過去には、監視および可観測性ツールはプロプライエタリなエージェントに大きく依存していました。つまり、追加のツールを設定・変更するために、インフラストラクチャレベルからアプリケーションレベルに至るまで、システム全体で大量の変更が必要になってしまうということです。
OpenTelemetry はベンダーニュートラルであり、可観測性に関わる多くの業界のリーダーによってサポートされています。そのため、利用者はいつでも、わずかな計装に対する変更だけで、サポートされている可観測性ツールを切り替えることができます。これは、どの OpenTelemetry のディストリビューションが使用されているかを問わず真実です。Linux と同様に、さまざまなディストリビューションがあり、設定とアドオンがバンドルされていますが、根本的に、これらはすべてコミュニティ主導の OpenTelemetry プロジェクトに基づいているものなのです。
Splunk は OpenTelemetry に完全にコミットしています。これにより、お客様は、いかなるタイプ、いかなるアーキテクチャ、いかなるソース、いかなる規模感であっても、すべてのデータをリアルタイムに収集し活用することができます。OpenTelemetry は監視のありかたを根本的に変えつつあり、IT チームと DevOps チームがあらゆる疑問やあらゆるアクションに対してデータを活用することを可能にしています。このワークショップ中に、こういった特徴について体験することができるはずです。

UI - クイックツアー 🚌のサブセクション
はじめに
2分1. Splunk Observability Cloud にサインインする
Splunk からワークショップの組織への招待メールが届くはずです。下のスクリーンショットのようなメールです。もし見つけられない場合は、スパム/ごみ箱フォルダを確認するか、講師に知らせてください。また、ログイン - よくある質問で他の解決策を確認いただくことも可能です。
Join Now ボタンをクリックするか、メールに記載されているリンクをクリックして、次に進んでください。
すでに登録プロセスを完了している場合は、残りをスキップして直接 Splunk Observability Cloud に進み、ログインすることができます。
Splunk Observability Cloud を初めて使用する場合は、登録フォームが表示されます。あなたのフルネームと希望のパスワードを入力してください。パスワードの要件は以下の通りです
- 必須 8文字から32文字の間でなければなりません
- 必須 少なくとも1つの大文字を含む必要があります
- 必須 少なくとも1つの数字を含む必要があります
- 必須 少なくとも1つの記号を含む必要があります(例:!@#$%^&*()_+)
利用規約に同意するためのチェックボックスをクリックし、SIGN IN NOW ボタンをクリックしてください。
はじめにのサブセクション
ホームページ
5分Splunk Observability Cloud に登録しログインすると、ホーム画面であるランディングページに移動します。ここでは、使用開始にあたって役に立つ機能を確認できます。
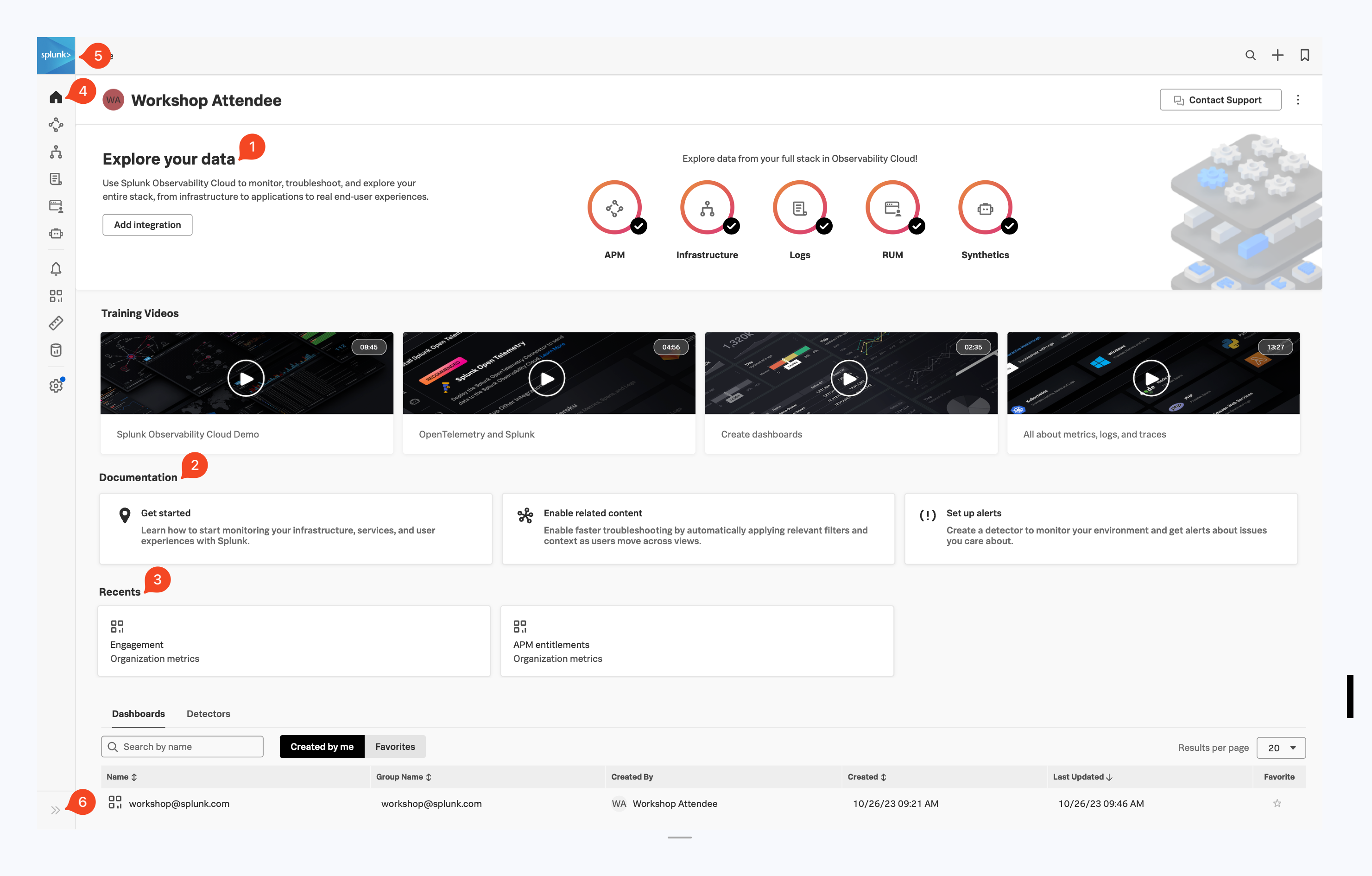
- “Explorer your data” : 有効になっているインテグレーションを表示しています。管理者であればさらにインテグレーションを追加できます。
- “Documentation” : Splunk Observability Cloud に取り組み始める際に利用できるトレーニングビデオやドキュメンテーションへのリンクです。
- “Recents” : 最近作成・使用したダッシュボードや Detector にすぐにアクセスすることができます。
- メインメニュー: Splunk Observability Cloud の各機能に移動できます。
- 組織(Org)切り替え: 組織間を簡単に切り替えることができます(複数の組織のメンバーである場合)。
- メインメニューの展開/縮小: 画面サイズに応じて、メインメニューを展開 » / 縮小 « できます。
最初の Exercise に取り組んでみましょう。
Exercise
- メインメニューを展開し、Settings をクリックします。
- 組織切り替えで、複数の組織にアクセスできるかどうかを確認します。
Hint
これまでに Splunk Observability を使用したことがある場合、以前使用した組織のページを開いている可能性があります。正しいワークショップの組織にいることを確認してください。複数の組織にアクセスできる場合は、講師に確認してください。
Exercise
- Onboarding Guidance をクリックします(ここでは、オンボーディングパネルの表示を切り替えることができます。これは、製品を十分に理解していて、より多くの情報を表示できるようにスペースを使用したい場合に便利です)。
- Home Page のオンボーディングコンテンツを非表示にします。
- メニューの下部で、好みの外観を選択します。Light、Dark、または Auto モードが選択できます。
- Sign Out ボタンが表示されていることに気付きましたか? でも、押さないでくださいね!😊
- メインメニューに戻るために < をクリックします。
次に、Splunk Real User Monitoring (RUM) をチェックしましょう。
RUMの概要
5分Splunk RUM は業界唯一の End to End の, NoSample™ RUM ソリューションです。すべての Web およびモバイルセッションに関するユーザーエクスペリエンス全体を可視化し、フロントエンドの全てのトレースをバックエンドのメトリクス、トレース、ログと一意に組み合わせることができます。IT 運用チームとエンジニアリングチームは、迅速にエラー範囲の特定、対処の優先度付け、他の問題との切り分け、実際のユーザーに対する影響の測定を行うことができます。また、すべてのユーザー操作をビデオでリプレイしながらパフォーマンス指標と相関させることでエンドユーザー体験を最適化することができます。
全てのユーザーセッションを分析する: ストリーミング分析によって、シングルページおよびマルチページアプリまで、全てのユーザーセッションをキャプチャし、すべてのリソース、画像、ルート変更、API 呼び出しが与える顧客への影響を測定します。
問題をより迅速に関連付ける: 無限のカーディナリティと完全なトランザクション分析により、複雑な分散システム全体で問題をより迅速に特定し、相関付けることができます。
遅延とエラーを特定する: それぞれのコード変更やデプロイに対して遅延、エラー、パフォーマンスが悪い状態を簡単に特定します。コンテンツ、画像、およびサードパーティの依存関係が顧客にどのような影響を与えるかを測定します。
ページパフォーマンスを取得し改善する: Core Web Vitals を活用してページロード体験、対話性、視覚的安定性を測定し、改善します。影響を及ぼす JavaScript エラーを見つけて修正し、最初に改善すべきページを簡単に理解できます。
意味のあるメトリクスを探索する: 特定のワークフロー、カスタムタグ、およびインデックス化されていないタグに関する自動提案に基づいたメトリクスによって、顧客への影響を即座に視覚化し、問題の根本原因を迅速に特定します。
エンドユーザー体験を最適化する: すべてのユーザーインタラクションをビデオリプレイで確認しながらパフォーマンスメトリクスと関連付け、エンドユーザー体験を最適化することができます。
RUMの概要のサブセクション
RUM ホームページ
メインメニューで RUM をクリックすると、RUM のメインとなるホーム画面、ランディングページに移動します。このページでは、選択したすべての RUM アプリケーション全体のステータスを一目で確認できることに主眼が置かれています。フルサイズ、あるいは、コンパクトビューのいずれかの形式で表示することができます。
ステータスダッシュボードの表示タイプがいずれの場合でも、RUM ホームページは3つのセクションで構成されています。
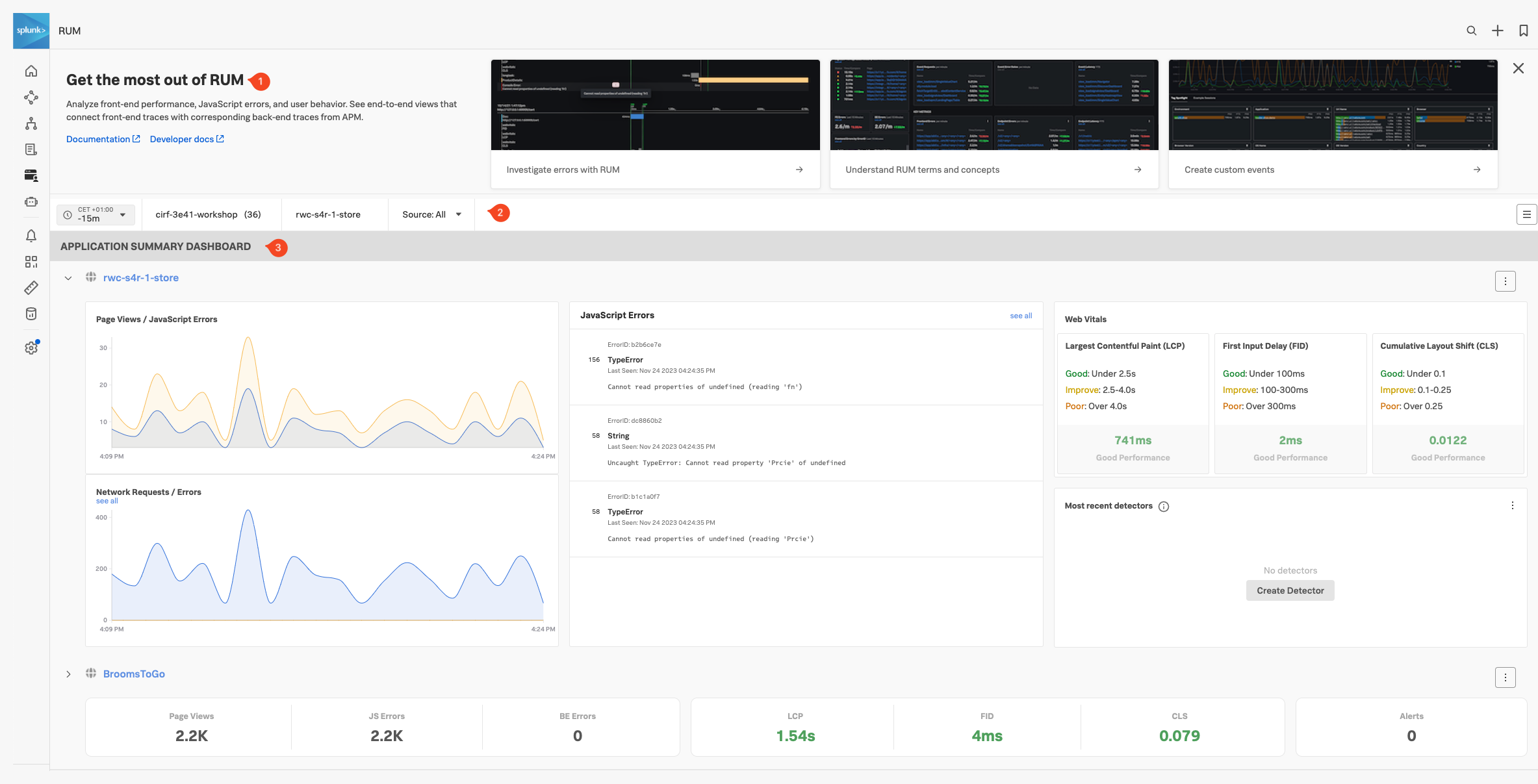
- オンボーディングパネル: Splunk RUM を始めるためのトレーニングビデオとドキュメンテーションへのリンク(画面のスペースが必要な場合は、このパネルを非表示にできます)
- フィルターパネル: 時間枠、環境、アプリケーション、ソースタイプでフィルタリングすることができます
- アプリケーションサマリーパネル: RUM データを送信するすべてのアプリケーションのサマリーが表示されます
RUM における 環境(Environment),アプリケーション(App),ソースタイプ(Source)
- Splunk Observability は、RUM トレースの一部として送信される Environment タグを使用して、“Production” や “Development” などの異なる環境からのデータを区分します。
- さらに App タグによる区分も可能です。これにより、同じ環境で動作する別々のブラウザ/モバイルアプリケーションを区別することができます。
- Splunk RUM はブラウザとモバイルアプリケーションの両方で利用可能であり、Source を使用してそれらを区別することができます。このワークショップでは、ブラウザベースの RUM のみを使用します。
Exercise
- 時間枠が -15m に設定されていることを確認してください
- ドロップダウンボックスからワークショップの Environment を選択してください。命名規則は [ワークショップの名前]-workshop です(これを選択すると、ワークショップの RUM アプリケーションが表示されるはずです)
- App を選択します。命名規則は [ワークショップの名前]-store です。Source は All に設定したままにしてください。
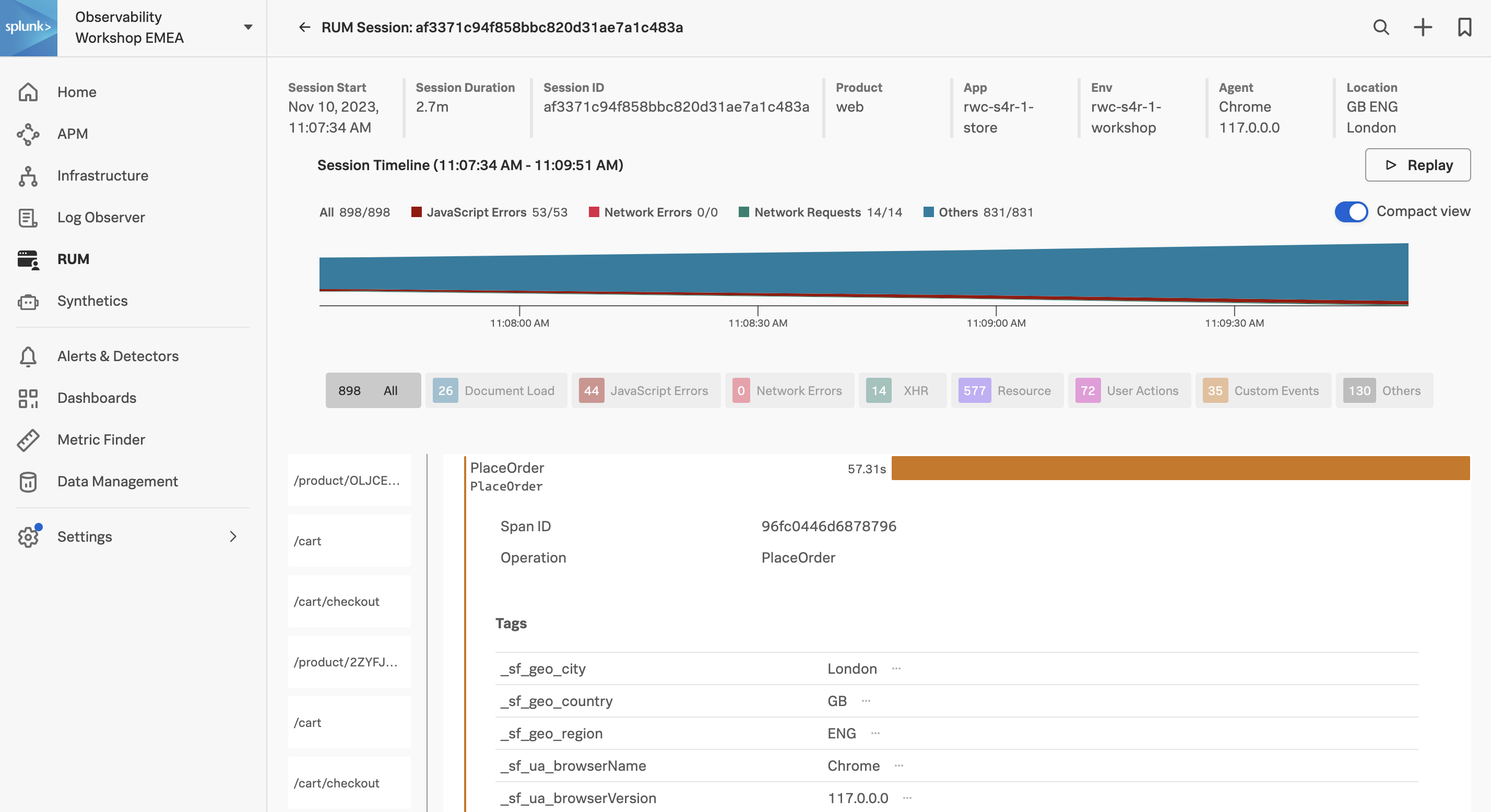
- JavaScript Errors タイルで Cannot read properties of undefined (reading ‘Prcie’) と表示される TypeError エントリをクリックし、詳細を確認してください。エラーが発生したウェブサイトのどの部分か、すぐに見つけることができるはずです。これにより迅速に問題を修正することができます。
- パネルを閉じます。
- 3列目のタイルには Web Vitals が表示されています。これはユーザーエクスペリエンスの3つの重要な側面であるページのローディング、対話性、および視覚的安定性に焦点を当てたメトリックです。
Web Vitals メトリクスに基づいて、現在のウェブサイトのパフォーマンスをどのように評価しますか?
Web Vitals メトリクスによれば、サイトの初期ロードはOKで、良好 と評価できます
- 最後のタイル、Most recent detectors タイルは、アプリケーションでトリガーされたアラートがあるかどうかを表示します。
- アプリケーション名の前の下向き ⌵ 矢印をクリックして、ビューをコンパクトスタイルに切り替えます。このビューでも主要な情報がすべて利用可能です。コンパクトビューの任意の場所をクリックしてフルビューに戻ります。
Additional Exercise
RUM ホームページではフロントエンドの概要をシンプルに確認することができますが、詳細なステータス確認や問題調査が必要になるケースもあるはずです。
フロントエンドの問題特定・原因調査を行う方法は、5. Splunk RUM を見てみましょう。
お時間がある方は、更にいくつかの機能を確認してみましょう。
- [ワークショップの名前]-store をクリックします。詳細なダッシュボードビューが表示されます。
- UX Metrics, Front-end Health, Back-end Health, Custom Events というメニュータブをそれぞれ開いてみましょう。
- それぞれのページで、どんなメトリクスが表示されているか確認してみてください
- Custom Events をクリックします。
- Custom Events は、特定の操作(例:カートに商品を追加するボタンを押す、商品詳細ページを開く、など)をイベントとして記録し、集計したものです。
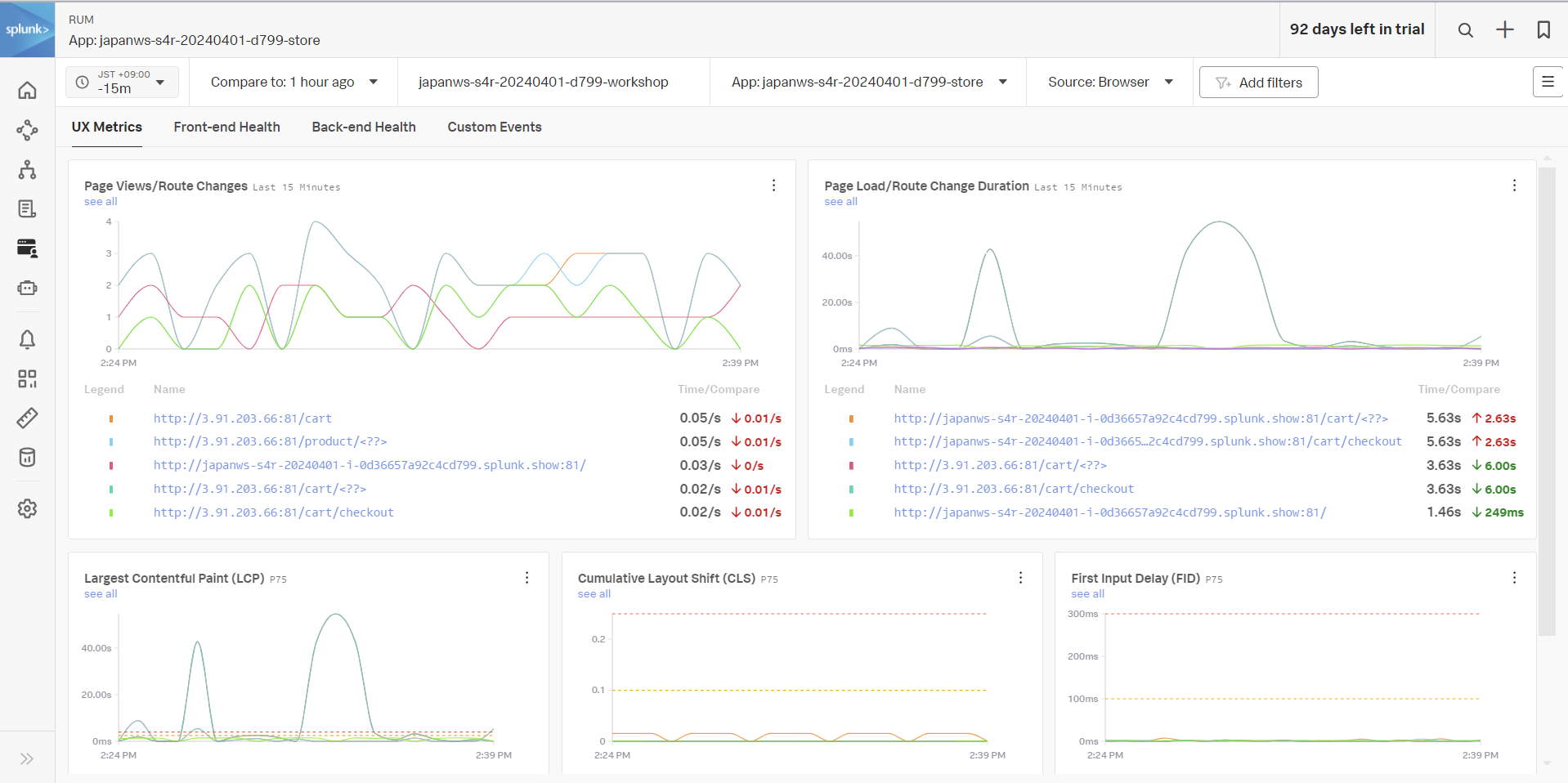
Custom Events として記録された処理で、1分あたりのリクエスト回数が最も多い処理は何ですか?
- Custom Event Requests のすぐ下の see all をクリックします
- Tag Spotlight というビューが表示されたはずです
- Tag Spotlight は取得したテレメトリーデータに含まれるタグ情報ごとの傾向を表示・分析する機能です

- Custom Event Name というタイルの中で AddToCart という項目を探します。みつけたらクリックして Add to filter をクリックしてください
- これにより、AddToCart 処理だけに注目をして、分析を行うことができます。

このアプリケーションに対してアクセス元として最も多い国はどこですか? またそれはどのタイルから分かりますか?
アメリカ (US) です。Countryタイルから分かります
- User Sessions をクリックします
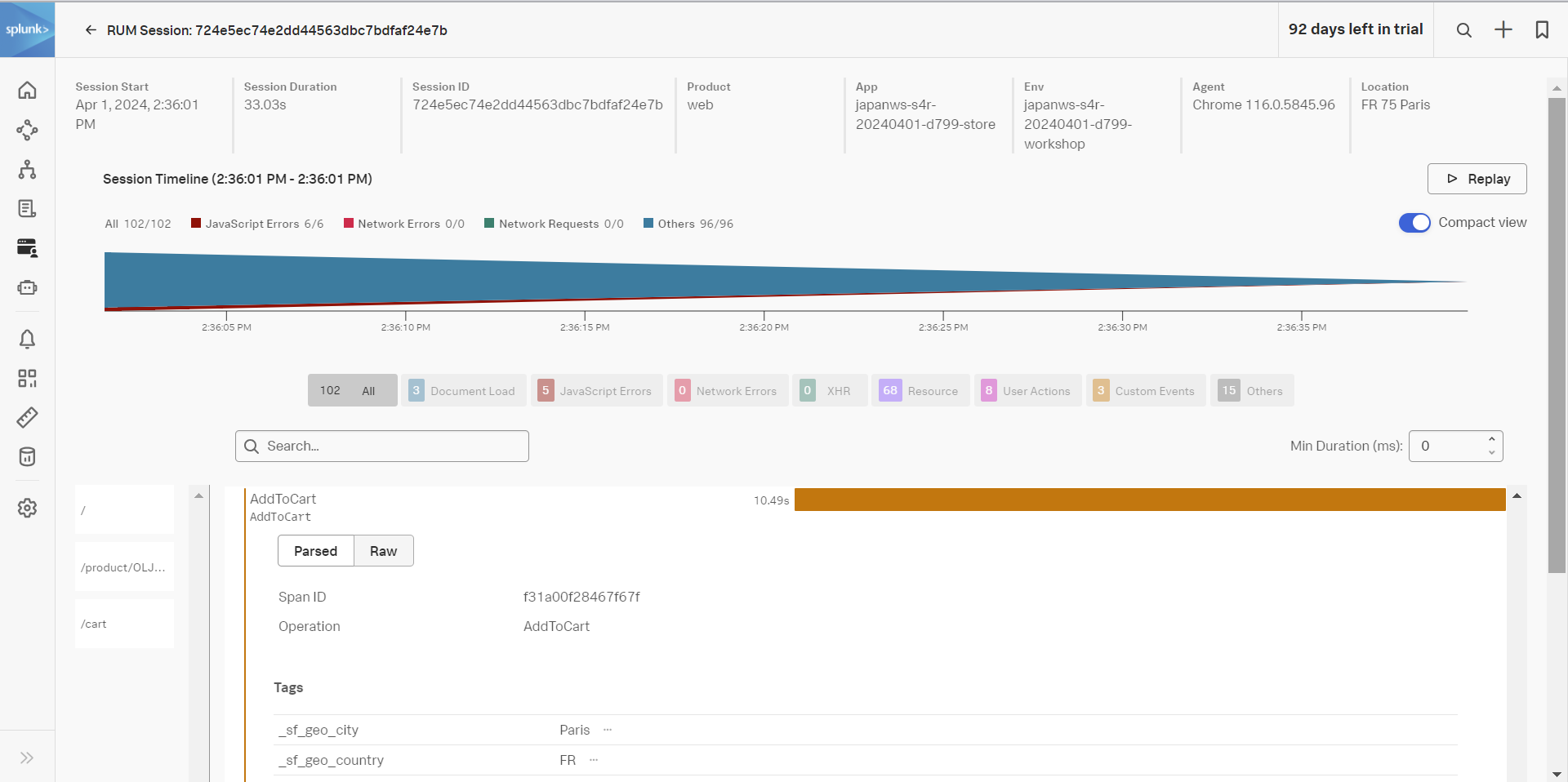
- Duration をクリックして、処理時間が長い順に並べ替えます
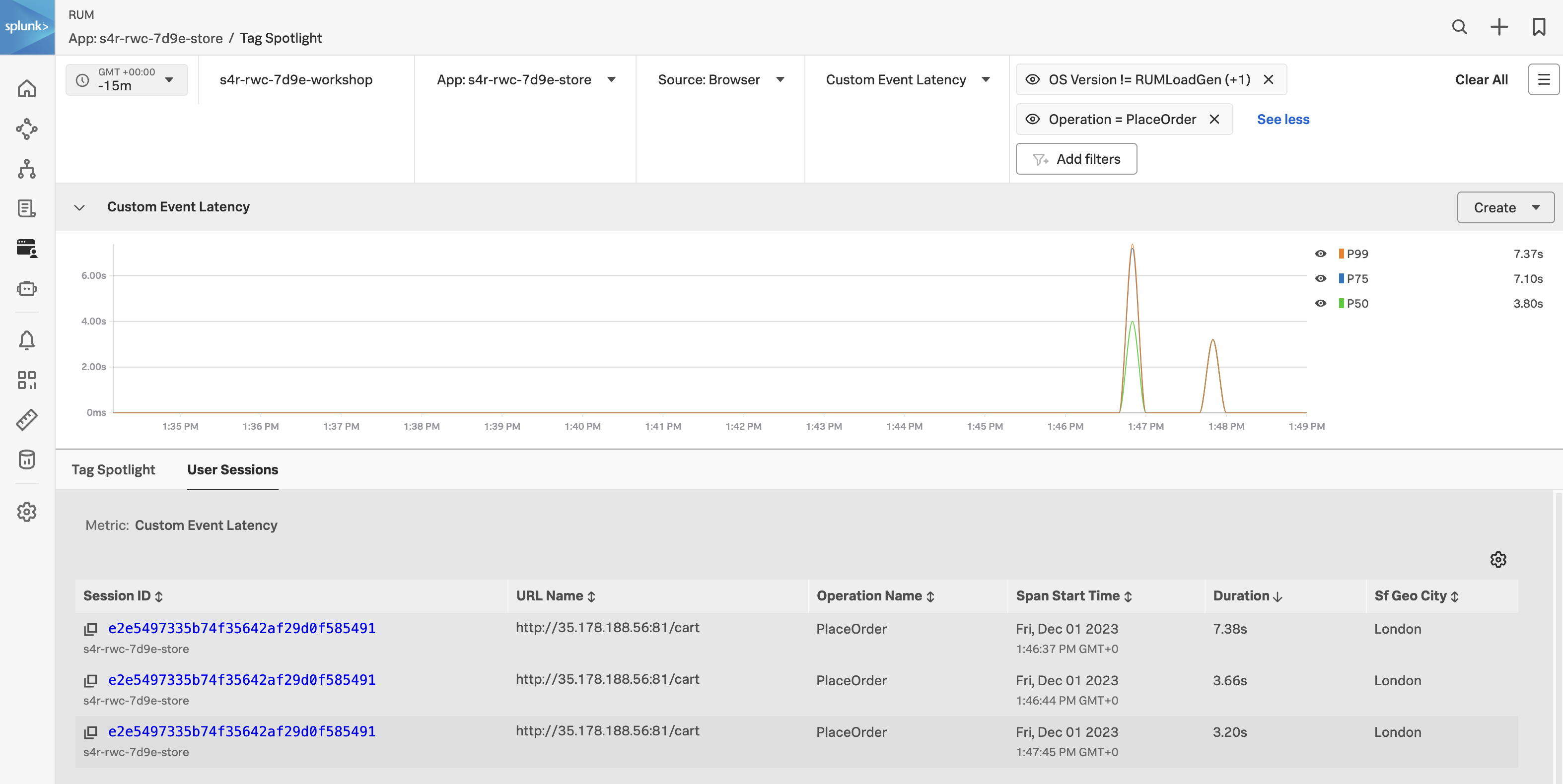
- AddToCart に該当する処理を実施したユーザーのセッションを確認することができます
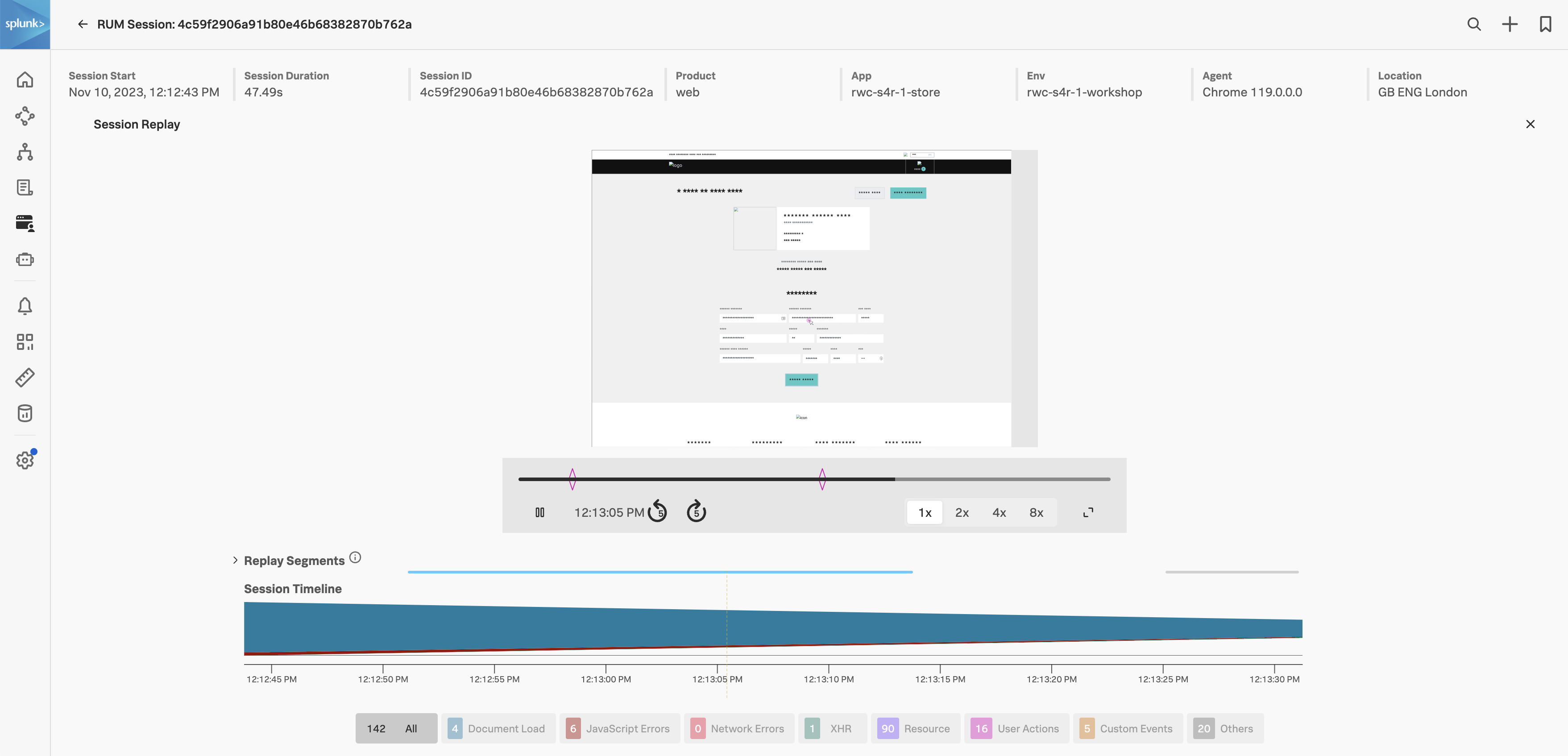
- 最も処理時間が長いユーザーセッションの Session ID をクリックします
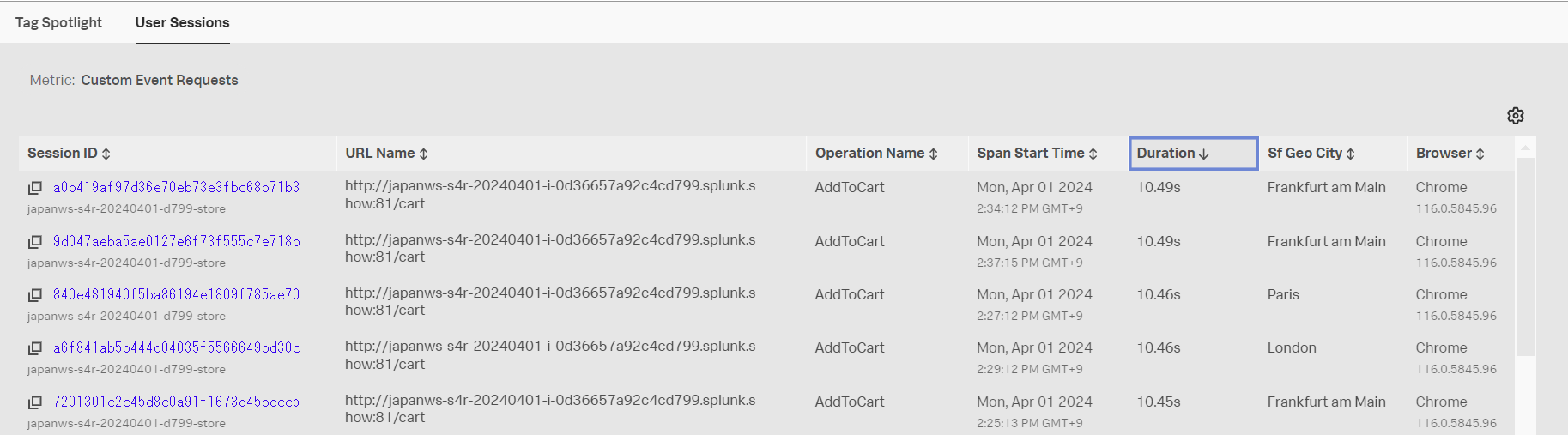
- 画面右上にある Replay ボタンを押してみたり、各処理の時間やタグ情報を確認したり、APM というリンクにカーソルを当ててみたりしましょう
次に、Splunk Application Performance Monitoring (APM) をチェックしましょう。
APMの概要
5分Splunk APM は、NoSample™ で End to End ですべてのアプリケーションやその依存性に関する可視性を提供し、モノリシックアプリ、マイクロサービスの両方で問題をより迅速に解決することに寄与します。チームは新しいアプリケーションをデプロイした際にもすぐに問題に気づくことができます。また、問題の発生源を絞り込み、切り分けることでトラブルシューティングに自信を持って取り組むことができます。バックエンドサービスがエンドユーザーとビジネスワークフローに与える影響を理解することを通じて、サービスのパフォーマンスを最適化することができます。
リアルタイムモニタリングとアラート: Splunk は、すぐに利用可能なサービスダッシュボードを提供します。急激な変化があると RED メトリクス(処理量、エラー、遅延)に基づいて自動的に問題を検出・アラートを発します。
動的なテレメトリーマップ: モダンなプロダクション環境でのサービスパフォーマンスをリアルタイムで簡単に視覚化します。インフラストラクチャ、アプリケーション、エンドユーザー、およびすべての依存関係からサービスパフォーマンスをエンドツーエンドで可視化することで、新しい問題を迅速に絞り込み、より効果的にトラブルシューティングを行うことができるようになります。
インテリジェントなタグ付けと分析: ビジネス、インフラストラクチャ、アプリケーションからのすべてのタグを一か所で表示し、特定のタグに対して遅延やエラーに関する新しい傾向を簡単に比較・理解することができます。
AI を活用したトラブルシューティングによる最も影響の大きい問題を特定: 個々のダッシュボードを手間をかけて掘り下げる必要はありません。問題をより効率的に切り分けることができます。サービスと顧客に最も影響を与える異常とエラーの原因を自動的に特定します。
すべてのトランザクションに対する完全な分散トレーシング分析: クラウドネイティブ環境の問題をより効果的に特定します。Splunk の分散トレーシングは、インフラストラクチャ、ビジネスワークフロー、アプリケーションの特徴を踏まえた上で、バックエンドとフロントエンドからのすべてのトランザクションを視覚化し、その関係性を明らかにします。
フルスタックでの相関性の可視化: Splunk Observability 内で、APM はトレース、メトリクス、ログ、プロファイリングをすべてリンクさせ、スタック全体における各コンポーネントの依存関係やパフォーマンスを簡単に理解できるようにします。
データベースクエリパフォーマンスの監視: SQL および NoSQL データベースからの遅いクエリや高頻度に実行されるクエリが、サービス、エンドポイント、およびビジネスワークフローにどのような影響を与えるかを簡単に特定できるようにします。計装は必要ありません。
APMの概要のサブセクション
APM ホームページ
メインメニューで APM をクリックすると、APM ホームページが表示されます。このページは3つのセクションで構成されています。
- オンボーディングパネル: Splunk APM を始める際に参考になるトレーニングビデオとドキュメンテーションへのリンク
- APM Overview: 最もエラー率やレイテンシーが高いサービスとビジネスワークフローのリアルタイムメトリクス
- 機能パネル: サービス、タグ、トレース、データベースクエリパフォーマンス、コードプロファイリングの詳細分析を行う際に使用するリンク
APM Overview パネルは、アプリケーションのヘルスステータスに関する概要を示します。これにはアプリケーションのサービス、レイテンシー、エラーのサマリーが含まれています。また、エラーレートが最も高いサービスとビジネスワークフローのリストも含まれています(ビジネスワークフローは、特定の活動やトランザクションに関連する一連のトレースの集合で、エンドツーエンドの KPI を監視し、根本原因とボトルネック特定することができるようになります)。
環境(Environment)について
複数のアプリケーションを簡単に区別するために、Splunk は Environment を使用します。ワークショップ環境の命名規則は [ワークショップの名前]-workshop です。インストラクターが正しい名前を案内します。
Exercise
- 表示されている画面上の時間枠が過去15分(-15m)に設定されていることを確認してください。
- ドロップダウンボックスからワークショップの Environment を選択してください。そのワークショップ環境名のみが選択されていることを確認してください。
エラーレートが最も高いサービスに関するチャートから、どんなことが分かりますか?
paymentservice が高いエラーレートを持っています
概要ページを下にスクロールすると、一部のサービスに Inferred Service が表示されることに気づくでしょう。
Splunk APM は、リモートサービスを呼び出すスパンに含まれる情報から、存在が推論されるサービス、つまり、Inferred Service を検出することができます。Inferred Service として検出されるサービスの例としては、データベース、HTTPエンドポイント、メッセージキューなどがあります。Inferred Service は計装されていませんが、サービスマップとサービスリストに表示されます。
Additional Exercise
もうすこし詳細に確認してみましょう。
バックエンドアプリケーションでの問題特定・原因調査を行う方法は、6. Splunk APM で取り組んでいただくことが可能です。
お時間がある方は、更にいくつかの機能を確認してみましょう。
- Service Map をクリックします。
- あわせて Show Legend を開いてみましょう。この Service Map に表示されている内容の凡例です。
- Service Map は、アプリケーションの相関性を表すマップです。APM エージェントを利用すると、アプリケーション間での連携やリクエストから自動的に生成されます。
- 点線の四角や丸のオブジェクトは、Inferred Service です。これらは計装されていませんが、計装済みのアプリケーションが連携先として利用していると推定されたため、サービスマップ上にも表示されています。
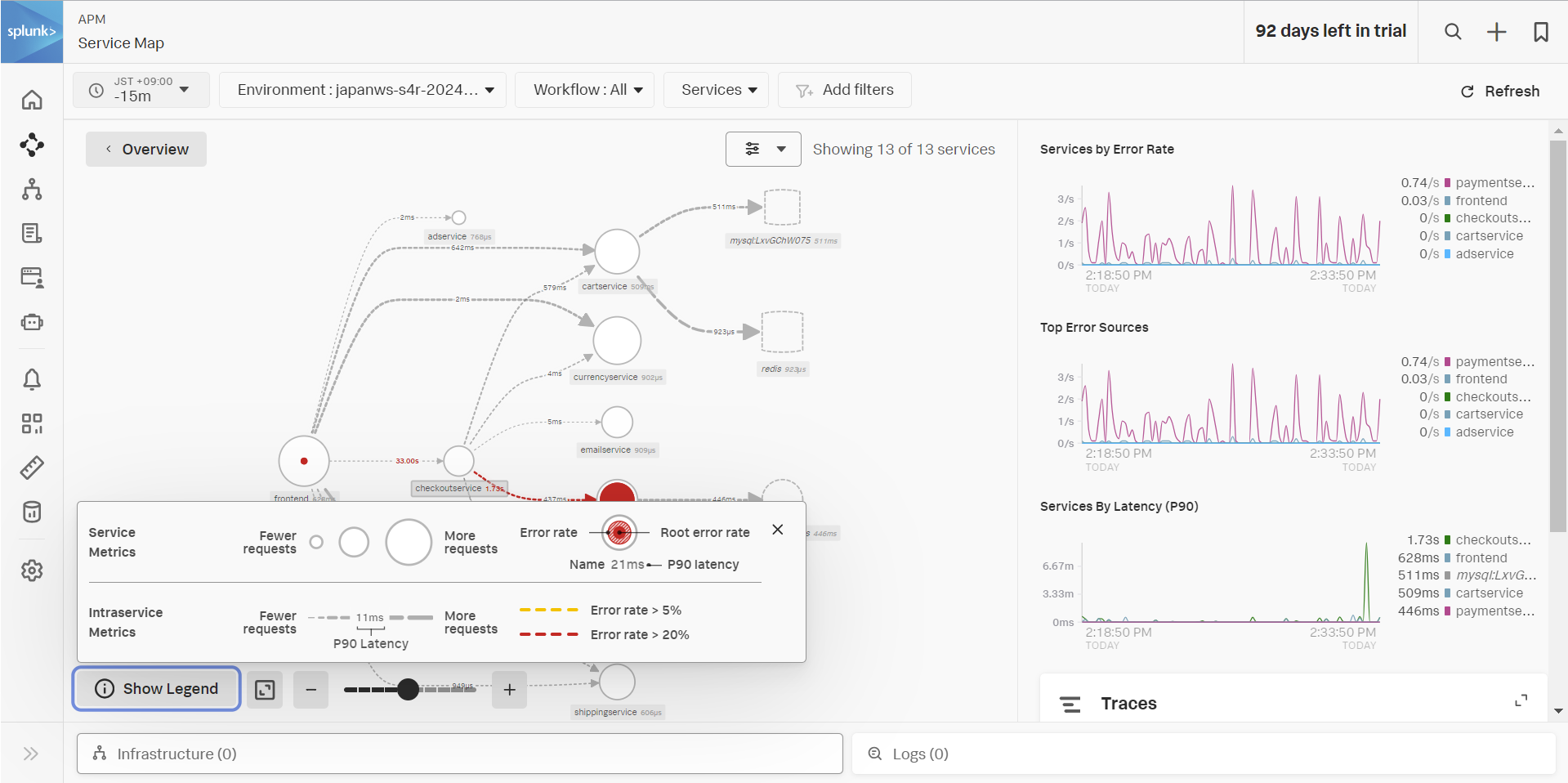
- エラー率が高いと、サービスマップ上ではどのように表示されますか?
- このシステムでは、どのようなDBを使用していますか?
- ヒント: DBは Inferred Service として、四角のオブジェクトで表示されます
- アプリケーションが赤くハイライトされます
- MySQLとRedisを使用しています
- Legend を開いている場合は閉じてください。
- エラーが頻発している paymentservice をクリックしてみましょう。
- 画面右側のメニューの表示が少し変わったはずです。paymentservice に関するメトリクスやメニューが表示されるようになりました。
- Breakdown をクリックし、version を探して、クリックしてみましょう。
- Service Map の表示が変わり、paymentservice がアプリケーションのバージョンごとに表示されるようになったはずです。
- Splunk APM では、タグ情報に基づいてサービスマップ自体を変化させて分析することができます。非常に視覚的なので、このシステムに詳しくない人でも探索できそうですね!
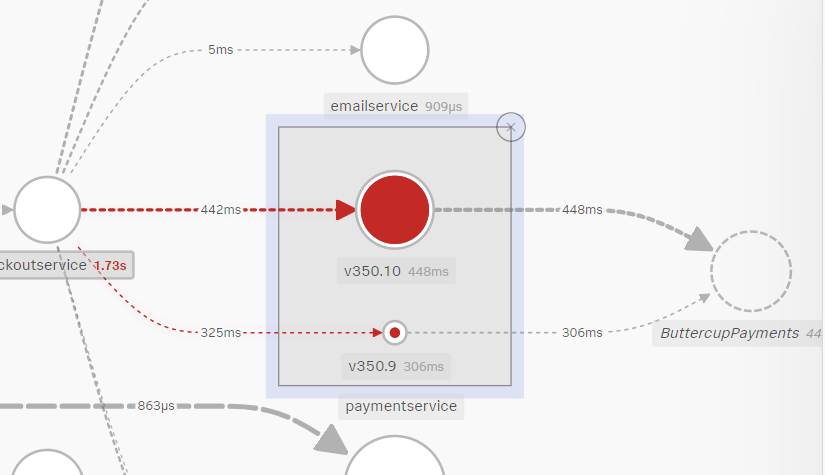
paymentservice を version ごとに分析すると、どういうことが分かりますか?
v350.10バージョンの方がエラー率が高いことが分かります
- v350.10 をクリックして、メニューのTraceを開いてみましょう。
- 画面右上に Switch to TraceAnalyzer というボタンがある場合は、これをクリックしてください。
- アプリケーションに対するリクエストが、どのように処理されたかをトレースし、エラーやボトルネックを特定したり、その処理の詳細を分析することができます
- この画面では、トレースの一覧が表示されます
- Errors Only のトグルを有効化してください。また、Duration をクリックして処理時間が長い順に並べ替えてください。
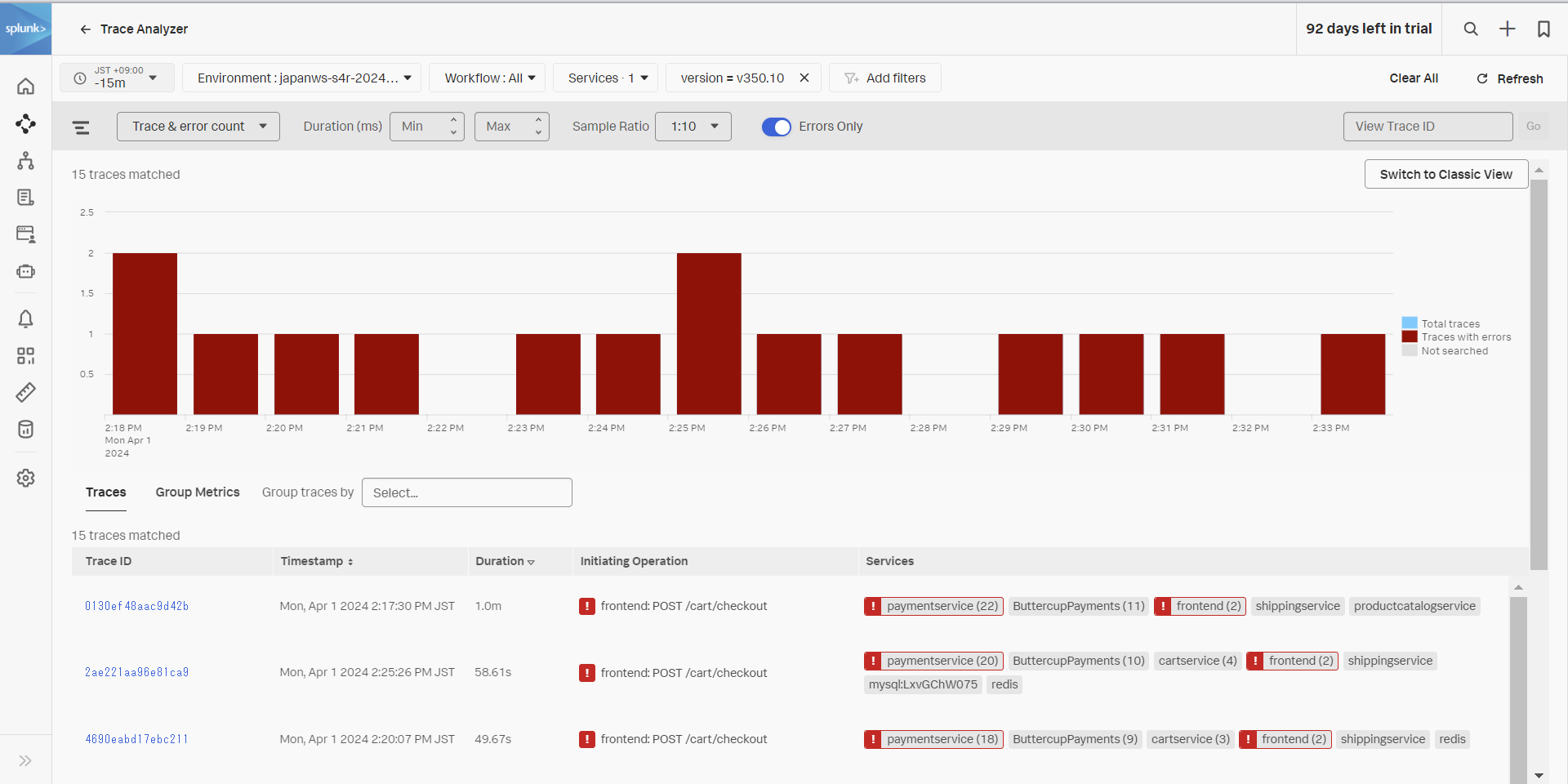
- 最も処理時間が長いトレースの Trace ID をクリックします。
- このトランザクションがどのように処理されたかを確認しましょう。
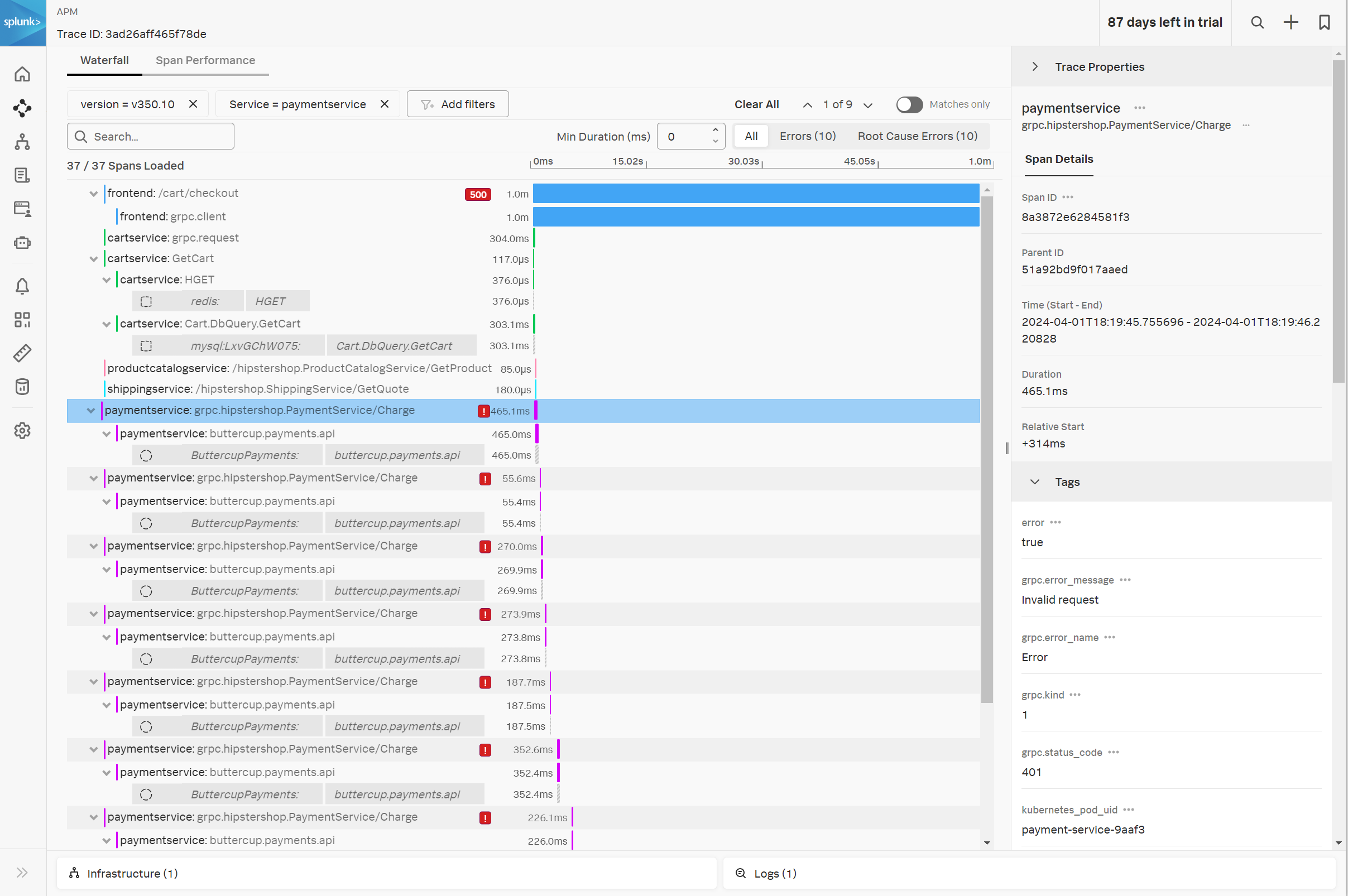
- 各行の処理を スパン(Span)、スパン全体を トレース(Trace) と呼びます。
- 赤とピンクの ! マークアイコンを見つけられますか? これはそれぞれ、一連のトランザクションの中でエラーを発生させたスパン(Root Cause Error)と、その影響で発生したエラーになったスパンとを区別して表示しています。
- 選択されたトレースによっては、ピンクの ! は表示されないかもしれません。
- いずれかのスパンをクリックすると、そのスパンに関連するタグ情報を確認することができます。
- 同じ処理が繰り返されている場合、スパンの左に x6 のように反復回数が表示されることがあります。
- 根本原因のエラーが発生しているサービスは何ですか?そのエラーメッセージは何ですか?
- このトレース処理に時間がかかっている原因として、どういったことが考えられますか?
- paymentserviceです。エラーメッセージは Invalid request を記録しています
- checkoutserviceとpaymentserviceでエラーが発生し、何度もリトライされていることで全体の処理時間が長くなっています
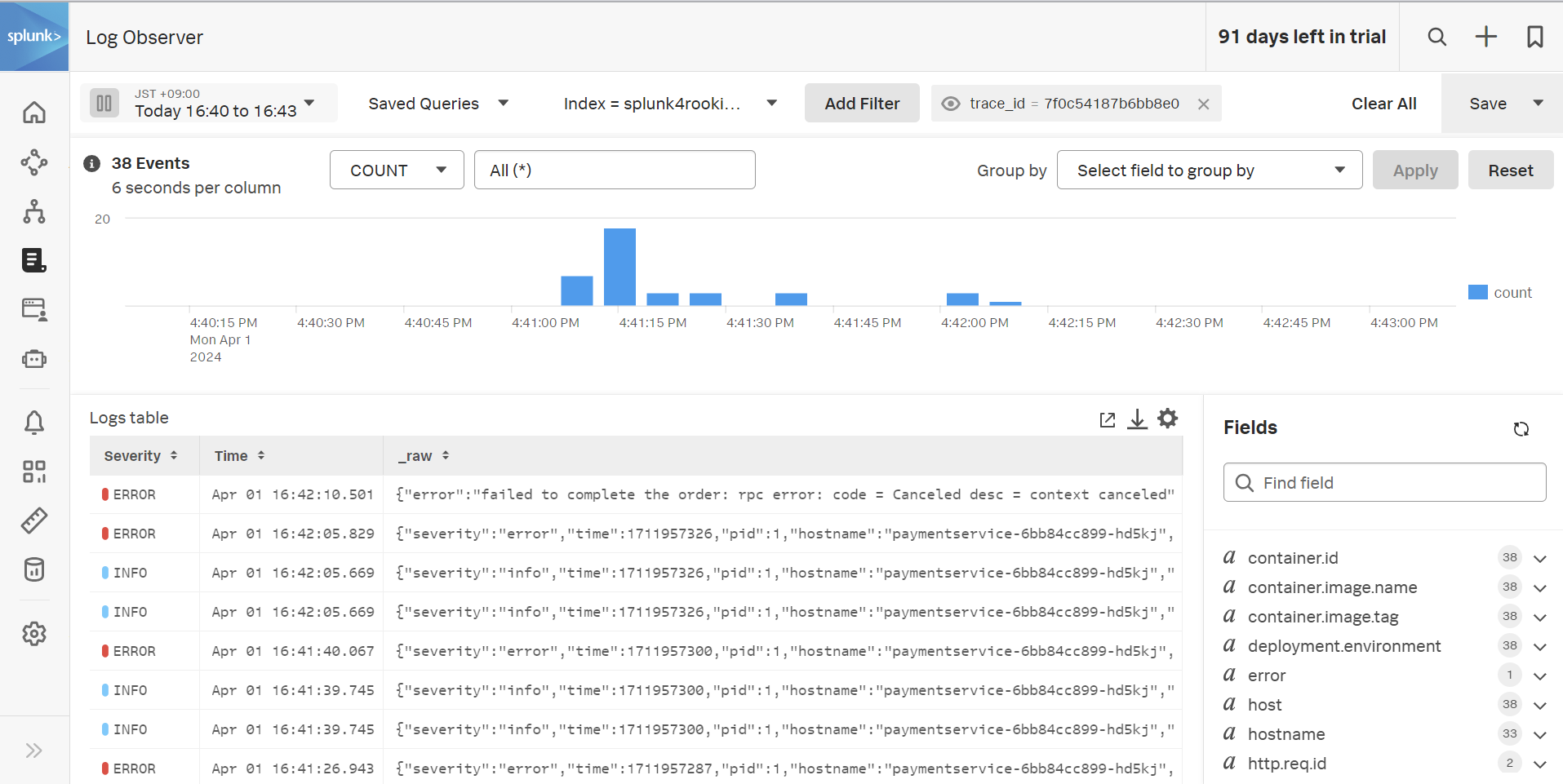
- 画面の最下部には Infrastructure や Logs というボタンが表示されているはずです。これらは、この処理と関連するシステムのコンポーネントやログの存在を教えてくれます。
- Logs をクリックし、Logs for trace … から始まる箇所をクリックしてみましょう。
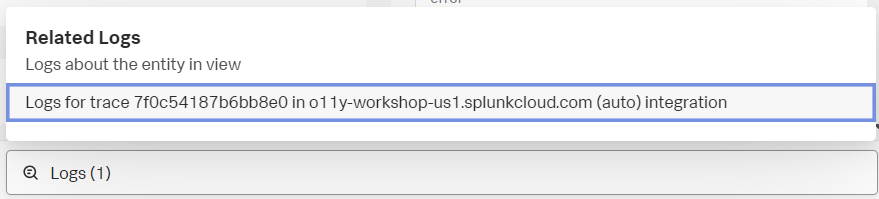
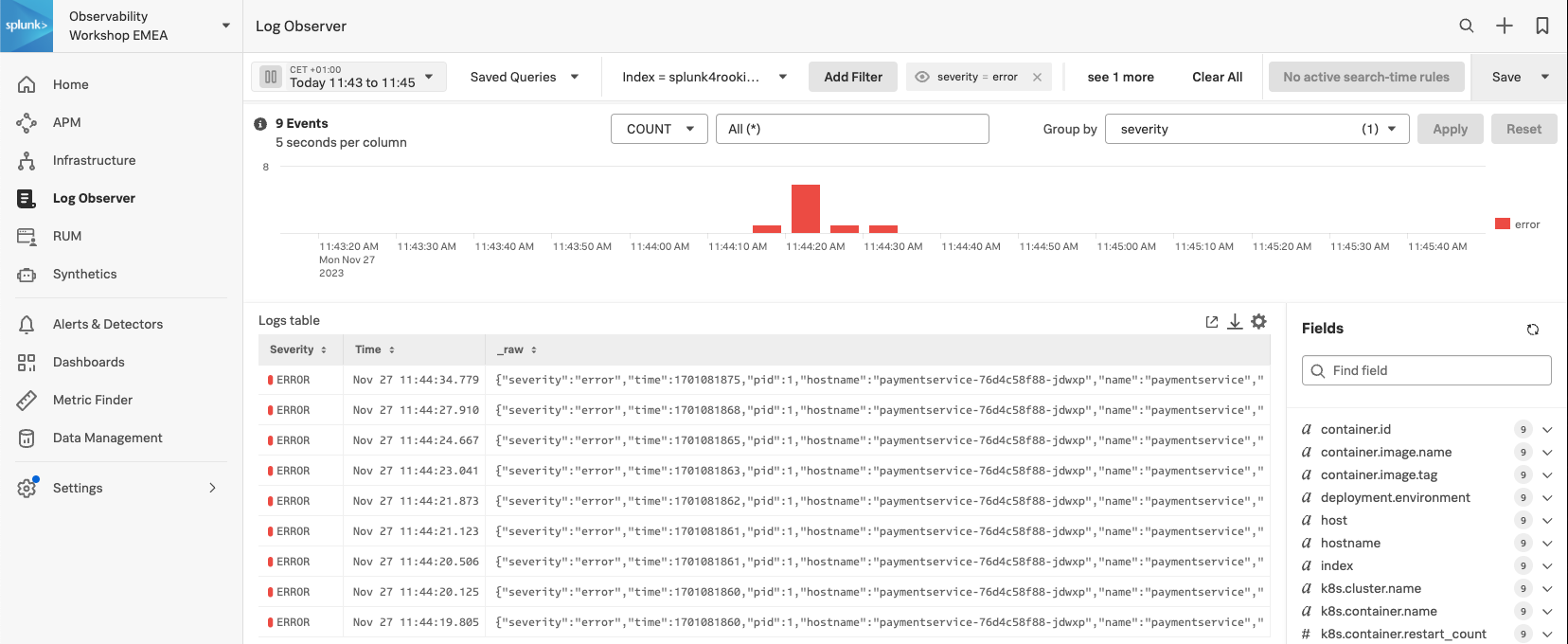
- Log Observer の画面が表示されます。この画面では、先ほどのトレースに関連するログのみを自動で抽出して提示してくれています。
- Log Observer の使い方は、次のワークショップコースの中で扱います。
次に、Splunk Log Observer (LO) をチェックしましょう。
Log Observerの概要
5 minutesLog Observer Connect は、Splunk Platform 上に取得されたログデータを直感的かつノーコードのインターフェースにシームレスに取り込むことが可能で、素早く問題を見つけて修正できるよう設計されています。ログベースの分析を簡単に実行でき、Splunk Infrastructure Monitoring のリアルタイムメトリクスや Splunk APM のトレースを1つの画面でシームレスに関連付けて確認することができます。
End to End の可視性: Splunk Platform の強力なログ機能を Splunk Observability Cloud のトレースとリアルタイムメトリクスと組み合わせることで、ハイブリッド環境のより深い洞察とコンテキストを提供します。
迅速かつ簡単なログベースの調査: Splunk Cloud Platform または Enterprise に既に取り込まれているログを Splunk Observability Cloud の簡素で直感的なインターフェースで再利用することができます。カスタマイズできて、すぐに使えるダッシュボードも活用できます(SPL の知識は不要です!)
大規模組織での利用が可能で、操作効率も向上: ログ管理をチームをまたいで一元化することで、データとチームの障壁を取り払い、システム全体に対するサポートを向上させます。
Log Observerの概要のサブセクション
Log Observer ホームページ
メインメニューで Log Observer をクリックしてみましょう。Log Observer ホームページは4つのセクションで構成されます。
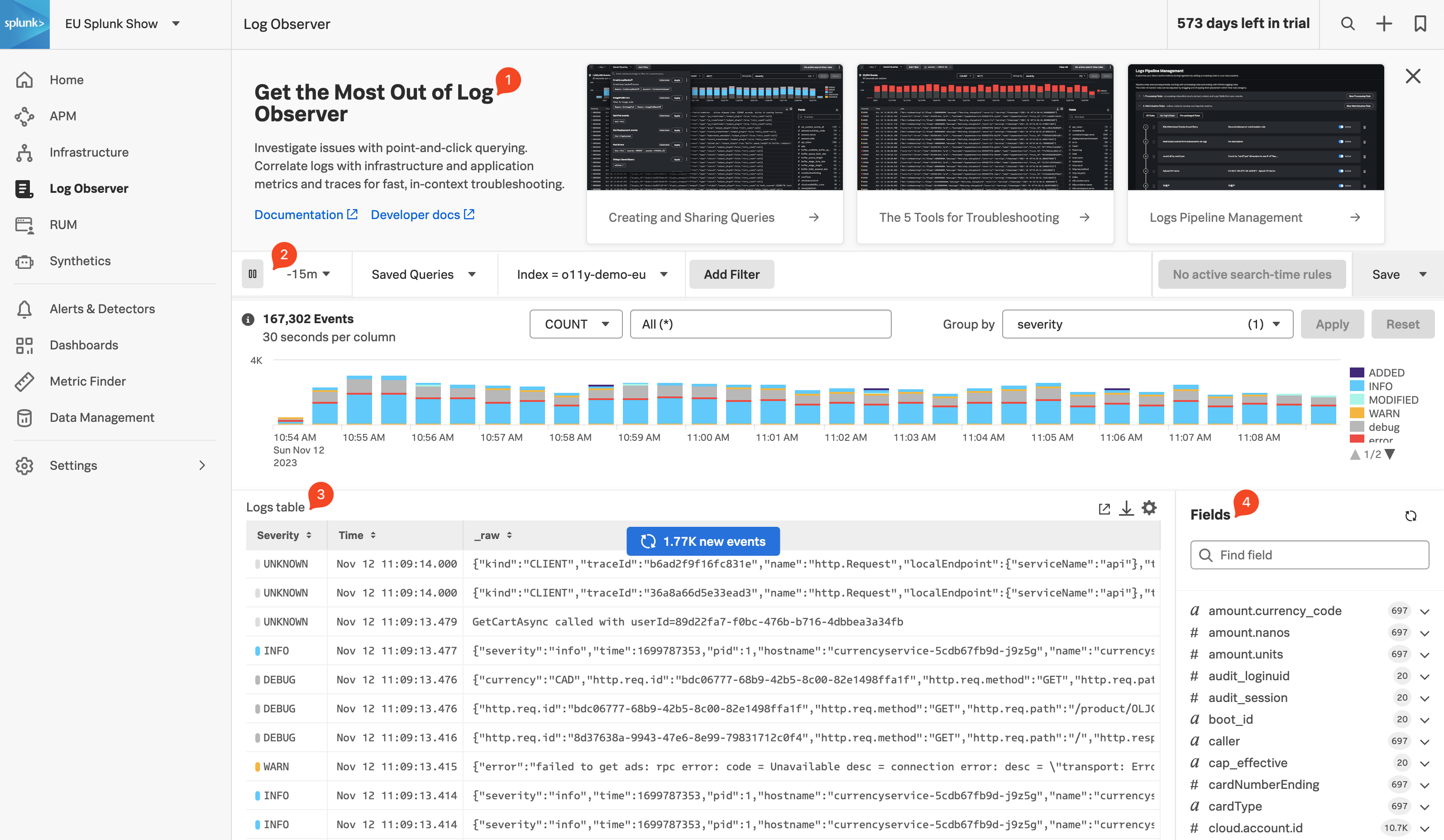
- オンボーディングパネル: Splunk Log Observer を始めるためのトレーニングビデオとドキュメンテーションへのリンク。
- フィルターパネル: 時間枠、index、および Field に基づいてログをフィルタリングすることができます。また、事前に保存しておいたクエリを利用することもできます。
- Log table: 現在のフィルタ条件に一致するログエントリーのリスト。
- Fields: 現在選択されている index で使用可能なフィールドのリスト。
Splunk index
一般的に、Splunk では「index」はデータが保存される指定された場所を指します。これはデータを格納するフォルダまたはコンテナのようなものです。 Splunk index 内のデータは検索と分析が容易になるように整理され構造化されています。異なるインデックスを作成して特定のタイプのデータを格納することができます。たとえば、Web サーバーログ用に1つの index、アプリケーションログ用に別の index を作成しておくようなことが可能です。
Tip
これまでに Splunk Enterprise または Splunk Cloud を使用したことがある場合、おそらくログから調査を開始することに慣れているでしょう。このあとの Exercise でも同じように取り組むことは可能ですが、このワークショップでは調査にあたってすべての OpenTelemetry シグナルを使用していきます。
さて、簡単なログ検索の演習を行いましょう。
Exercise
まず、visa を使用した注文を検索してみます。
時間枠を -15分 に設定してください
Filter で Add Filter をクリックし、次にダイアログで Fields をクリックしてください。
cardType と入力して選択してください
Top values の下にある visa をクリックし、その後 = をクリックしてフィルターに追加しましょう。

ログテーブル内のログエントリの1つをクリックして、そのエントリに cardType: "visa" が含まれていることを確認してください。
今度は出荷されたすべての注文を探してみましょう。
- Filter で Clear All をクリックして前のフィルターを削除してください。
- 再度 Filter で Add Filter をクリックし、次に Keyword を選択します。次に Enter Keyword… ボックスに
order: と入力してエンターキーを押してください。 - これで
order: という単語を含むログ行しか表示されなくなります。まだ多くのログ行がありますので、さらにフィルタリングしていきましょう。 - 別のフィルターを追加します。今度は Fields ボックスを選択し、Find a field… と表示されている検索ボックスに
severity と入力して選択してください。

- ダイアログボックスの下部にある Exclude all logs with this fields をクリックしてください。注文ログ行には
severity が割り当てられていないため、これにより不要なログ行を除外することができます。 - 画面上部にオンボーディングコンテンツが表示されている場合は、Exclude all logs with this fields ボタンを押すためにページをスクロールする必要があるかもしれません。
- これで過去15分間に販売された注文のリストが表示されたはずです。
次に、Splunk Synthetics を確認しましょう。
Syntheticsの概要
5 minutesSplunk Synthetic Monitoring は、URL、API、および重要な Web サービス全体に対する可視性を提供しており、問題の解決をより迅速に行うことができるようになります。IT 運用およびエンジニアリングチームは、簡単に問題を検出してアラートを発報したり、問題を優先順位づけすることができます。複数のステップから構成されるユーザージャーニーをシミュレーションしたり、新しいコードのデプロイがビジネスにどのような影響を与えるか測定したり、Web のパフォーマンスを最適化することも可能です。ステップバイステップのガイドにより、より良いデジタルエクスペリエンスを担保することにもつながります。
可用性の確認: ブラウザテストによって、ユーザーエクスペリエンスを構成する多段階のワークフローをシミュレートすることができます。これにより、重要なサービス、URL、および API のヘルスステータスや可用性を監視、アラートすることができます。
パフォーマンス指標の改善: Core Web Vitals およびモダンなパフォーマンスメトリクスを活用することで、すべてのパフォーマンスに関する問題点を1つの画面上で確認することができます。ページパフォーマンスを改善するために必要となるページの読み込み、対話性、視覚的な安定性に関するメトリクスを測定・改善したり、JavaScript エラーを見つけて修正したりすることができます。
フロントエンドからバックエンドまで: Splunk APM、Infrastructure Monitoring、On-Call、および ITSI との統合により、チームはバックエンドサービスやこれを支えるインフラストラクチャの状況、インシデント対応状況を踏まえたエンドポイントの稼働状態を確認することができ、環境全体を横断的に捉えてトラブルシュートを行うことができます。
問題の検知とアラート: エンドユーザーエクスペリエンスを監視およびシミュレートすることで、顧客に影響を与える前に API やサービスエンドポイント、重要なビジネストランザクションに対する問題を検知、アラートし、解決することができます。
ビジネスパフォーマンス: 主要なビジネストランザクションのために多段階のユーザーフローを簡単に定め、レコーディングすることで、数分でクリティカルなユーザージャーニーに関するテストを開始することができます。アップタイムやパフォーマンスに関わる SLA および SLO をトラックし、通知してくれます。
表示画面の記録とビデオ再生: 録画した画面や操作の再生、スクリーンショットの取得を行うことが可能で、現代でよく用いられるパフォーマンススコア、比較用のベンチマーク指標、エンドユーザーの体感を数値化したメトリクスとともに確認することができます。ビジュアルコンテンツの配信速度を最適化し、ページの安定性や対話性を向上させることで、より良いデジタルエクスペリエンスを展開することができます
Syntheticsの概要のサブセクション
Syntheticsホームページ
Synthetics をメインメニューでクリックしてみましょう。Synthetics ホームページに移動したはずです。このページには、役立つ情報を確認したり、Synthetic テストを選択または作成する3つのセクションがあります。
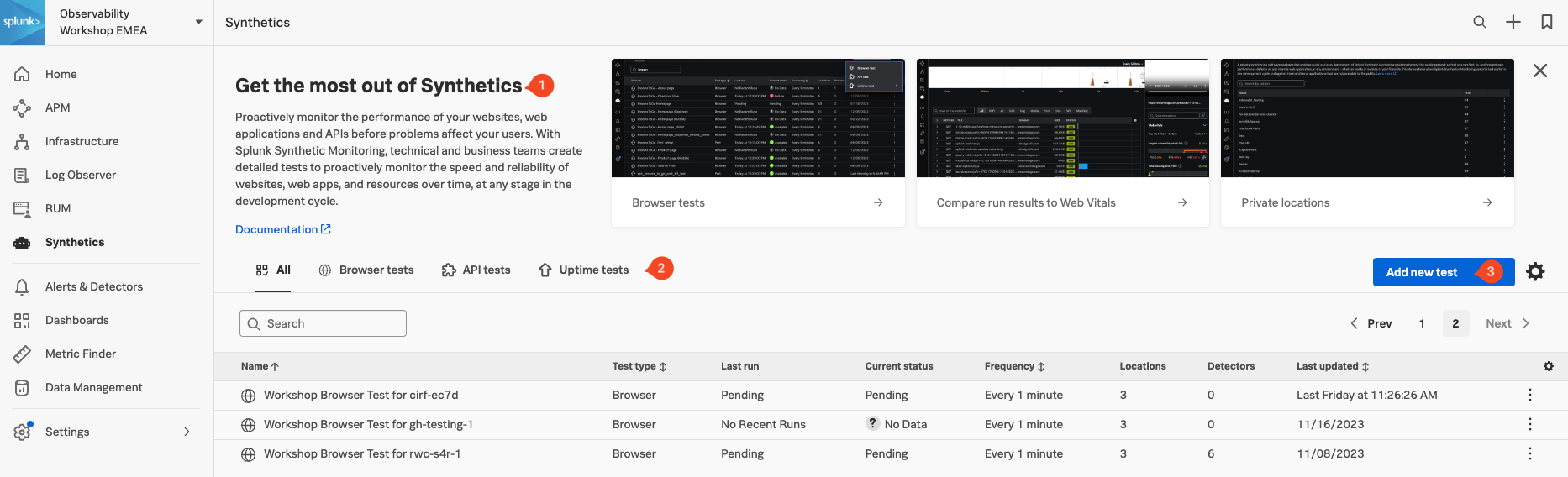
- オンボーディングパネル: Splunk Synthetics を始めるためのトレーニングビデオとドキュメンテーションへのリンク。
- テストパネル: 設定されているすべてのテストのリスト(Browser、API、および Uptime)
- Add new test: 新しい Synthetic テストを作成するためのドロップダウン。
Info
ワークショップの一環として、実行中のアプリケーションに対するブラウザーテストを用意しています。テストパネル(2)で見つけることができるはずです。テストの名前は Workshop Browser Test for のあとにワークショップの名前を続けたものとなります(講師が名前をご連絡いたします)。
ツアーを続けましょう。ワークショップ用の Browser Test の結果を見てみます。
Exercise
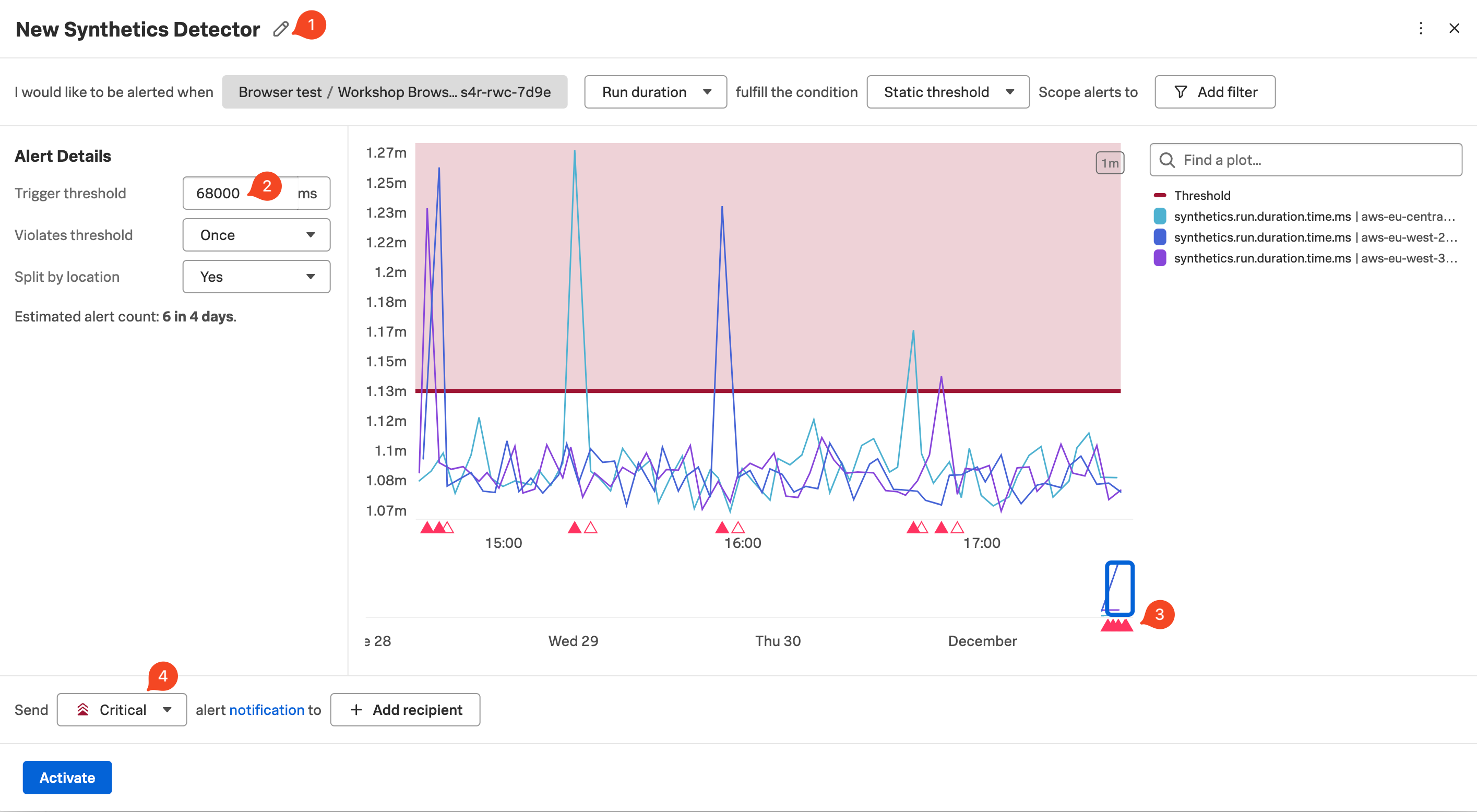
- テストパネルで、ワークショップの名前が含まれている行をクリックします。以下のように表示されるはずです。
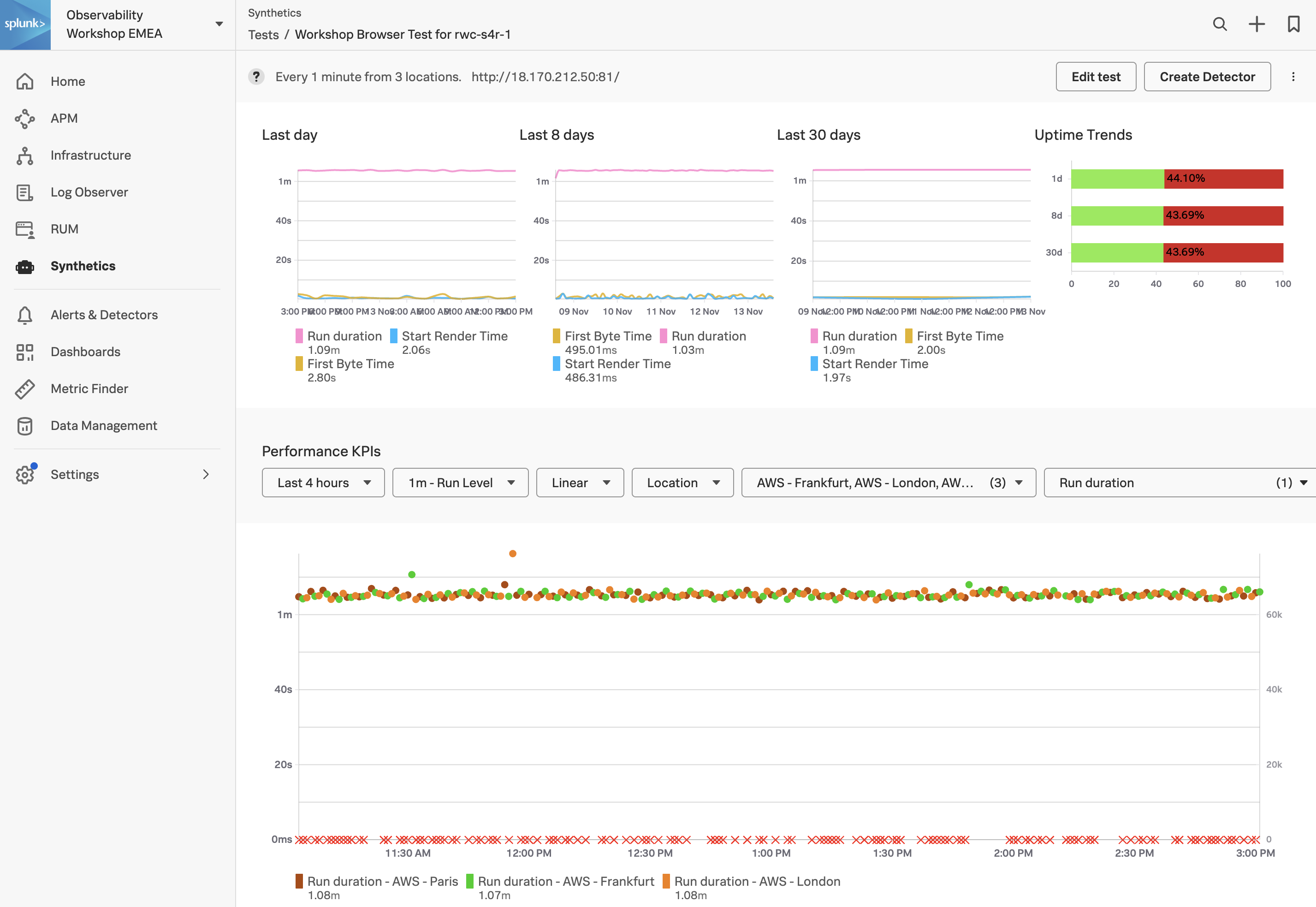
- Synthetic Tests ページでは、最後の1日、8日、および30日の間にサイトのパフォーマンスが表示されます。上のスクリーンショットに示されているように、テストがその期間より前に開始されていれば、対応するチャートにデータが表示されます。テストが作成された時点によっては、一部のデータが表示されない場合があります。
- Performance KPI のドロップダウンで、デフォルトの last 4 hours から last 1 hour に時間を変更してください。
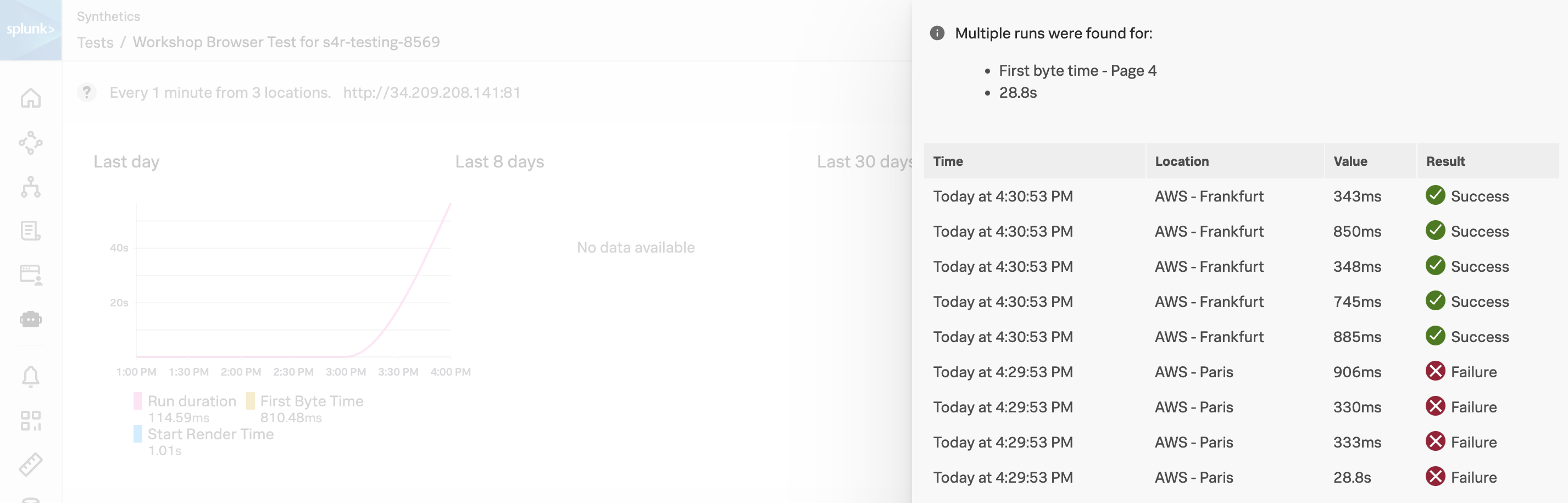
テストはどれくらいの頻度で実行され、どこから実行されていますか?
テストはフランクフルト、ロンドン、およびパリから、1分間隔のラウンドロビンで実行されます
Additional Exercise
テスト結果に基づいて問題調査を行ったり、監視設定を行う方法は、8. Splunk Synthetics で取り組んでいただくことが可能です。
実行したテストの詳細をもうすこし確認してみましょう。
- 画面下部に、Recent run results という欄があるはずです。Failed になっている最新のテストをクリックしましょう
- テスト結果の詳細画面が表示されます。
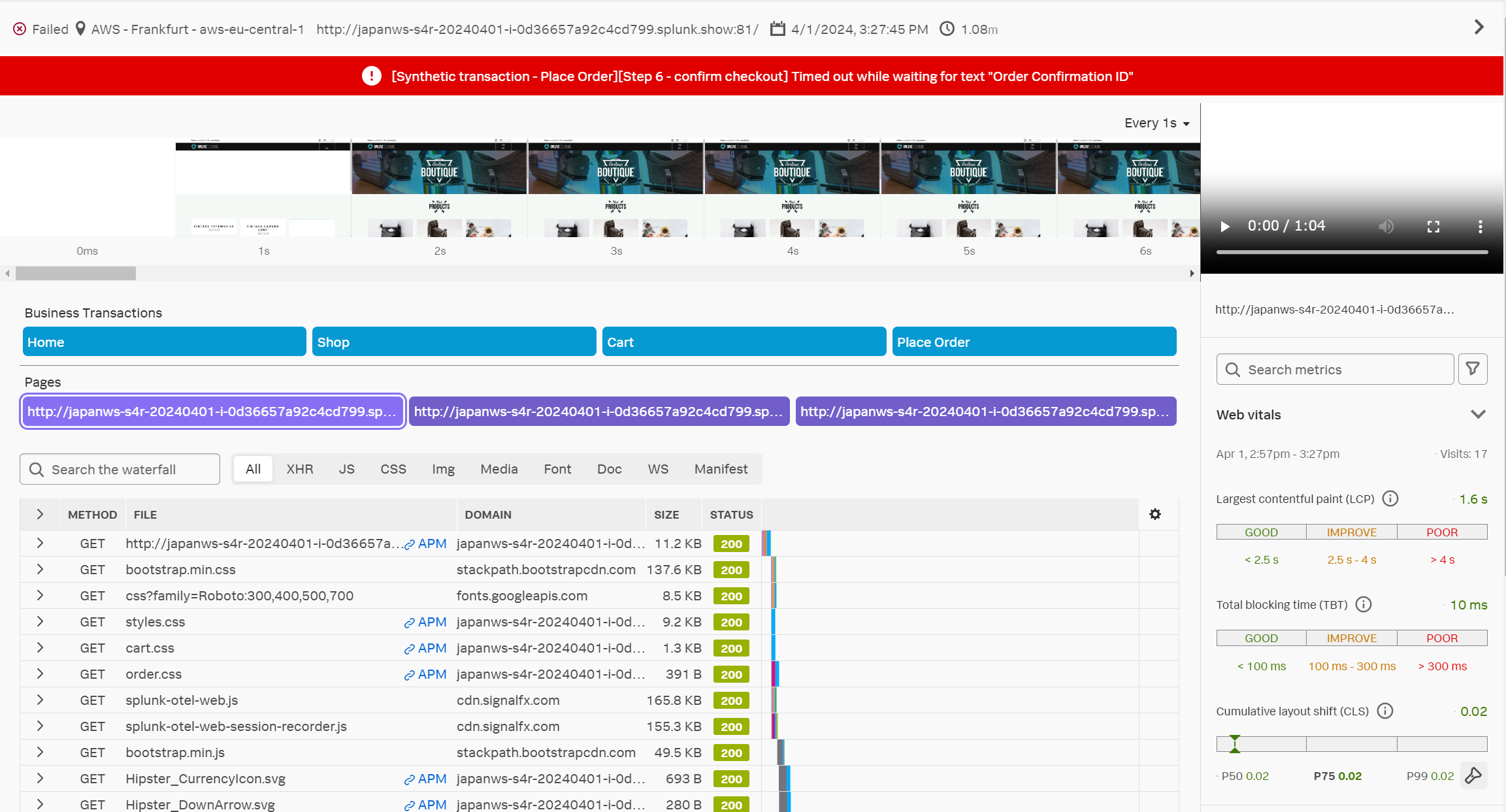
- 画面最上部に赤くエラーが表示されていることを確認しましょう

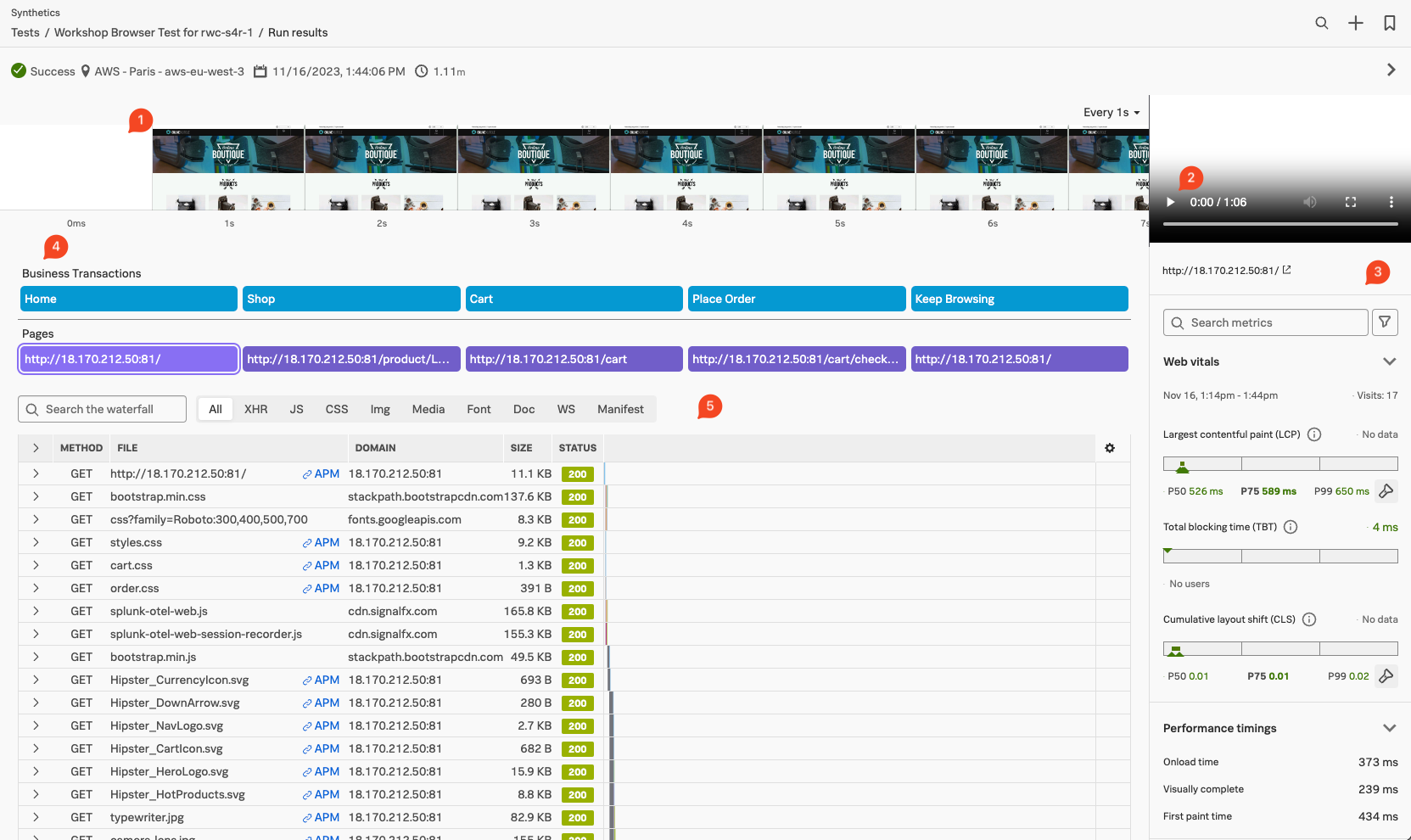
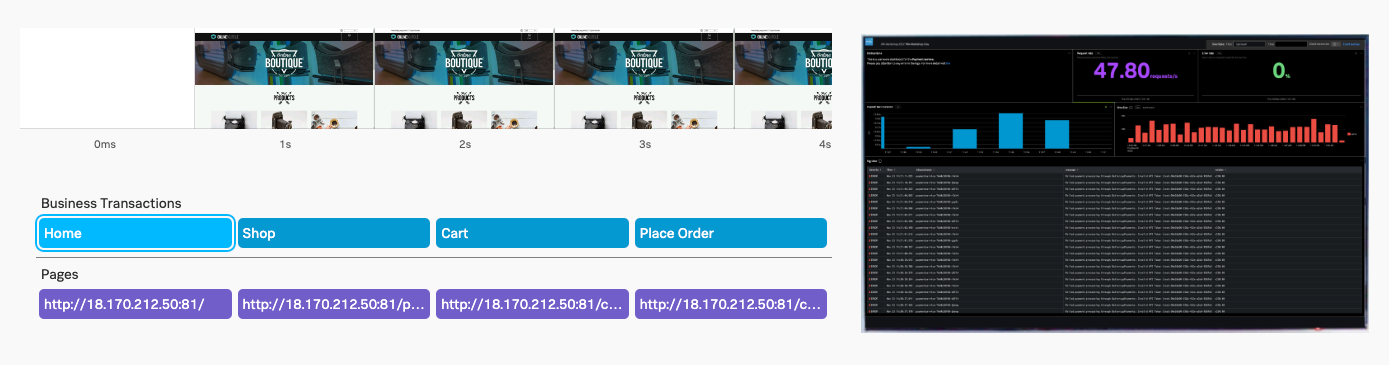
- 1秒間隔のスクリーンショットが横並びに表示されています。Every 1s というプルダウンを変えると、スクリーンショットの表示間隔を変更できます
- また、その右側には、録画再生ウィンドウがあるはずです。再生してみましょう
- 録画再生ウィンドウの下部には、この処理に関するパフォーマンス情報が表示されます。Web Vitalなどに基づいてパフォーマンスが可視化されています
- Business Transaction は、テストで確認したい処理をグループ化して定義したものです。また、Pages は、テストの中で開かれた Web ページの URL を示しています
- それぞれクリックしてみると、それに該当する処理が画面下部に表示されます。どのような処理が順番に実施されたか、処理状況が示されています。
- APM というリンクが表示されているはずです
- バックエンドアプリケーションを APM で計装している場合、Synthetic テストと APM のトレースを紐づけることができます
このテストはなぜ Failed と判断されましたか
Place Order 処理の後に “Order Confirmation ID” が表示されるまでに時間がかかり、タイムアウトしてしまった
次に、Splunk Infrastructure Monitoring (IM) を使用してアプリケーションが実行されているインフラストラクチャを調査しましょう。
Infrastructureの概要
5 minutesSplunk Infrastructure Monitoring (IM) は、ハイブリッドクラウド環境向けモニタリングおよびオブザビリティサービスとして市場でも高い評価を得ています。Splunk IM は特許取得済みのストリーミングアーキテクチャに基づいて構成されており、従来のソリューションよりも短時間かつ高精度で、インフラストラクチャ、サービス、およびアプリケーションのパフォーマンスを視覚化・分析できるリアルタイムソリューションを提供しています。
OpenTelemetry 標準化: あなたのデータを完全にコントロールすることができます。ベンダーロックインから解放され、独自エージェントの導入が不要になります。
Splunk の OTel Collector: シームレスなインストールとダイナミックな構成が可能で、ほんのわずかな時間ですべてのスタックに対して自動検出を行うことができます。これによりクラウド、サービス、およびシステム全体を横断的に可視化することができます。
300 以上の簡単に使用できる OOTB コンテンツ: Navigator と Dashboard が事前に用意されており、あなたの環境全体をすぐに可視化できます。すべてのデータをリアルタイムに扱うことが可能です。
Kubernetes ナビゲータ: すぐに利用できるプリセットのビューによって、ノード、Pod、およびコンテナの状態を包括的かつ構造的に理解できます。わかりやすく、インタラクティブなクラスターマップによって、初心者でも簡単に Kubernetes を理解できるでしょう。
アラートの自動検出と Detector: メトリクス取得を行いはじめるとすぐに、重要なメトリクスを自動的に判別し、detector(アラート)の条件が生成されます。テレメトリデータが取り込まれた直後から正確なアラートを行うことができ、ほんのわずかな時間で重要なアラート通知をリアルタイムに受け取ることができます。
ダッシュボード内のログ参照: ログメッセージとリアルタイムメトリクスを 1 ページで組み合わせて表示することができます。共通のフィルタ条件や時間制御により、共通のコンテキストに基づいて迅速にトラブルシューティングを行うことができます。
メトリクスパイプラインの管理: データ取り込み時点でメトリクスのボリュームを制御することができます。Instrumentation(計装)を変更することなく、必要なデータのみを保存・分析できるようにデータ集約や破棄を設定できます。メトリクスのボリュームを削減し、オブザービリティに対する支出を最適化することができるはずです。
Infrastructureの概要のサブセクション
Infrastructure Navigators
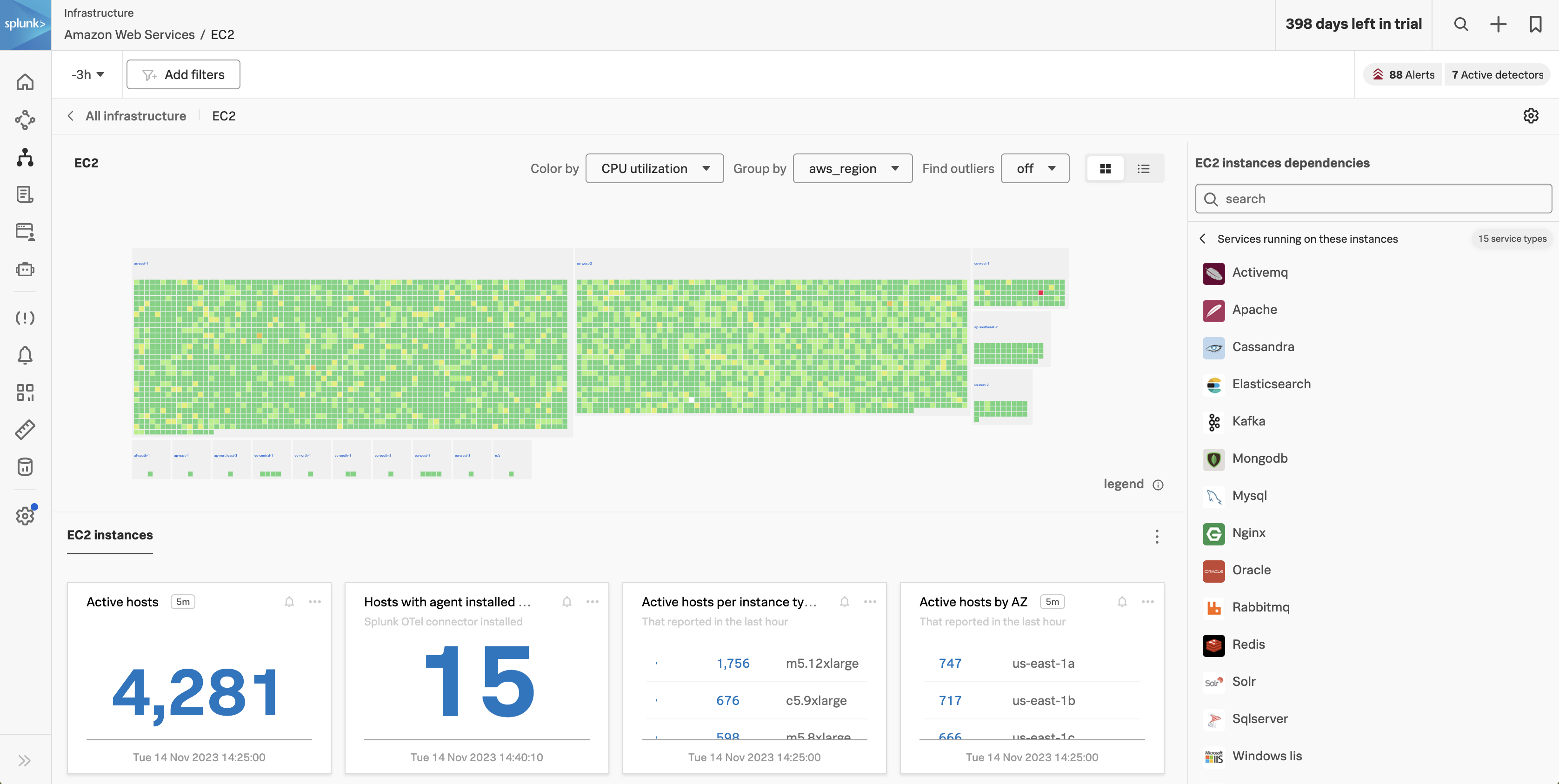
Infrastructure をメインメニューでクリックします。Infrastructure ホームページは4つの異なるセクションで構成されています。
- オンボーディングパネル: Splunk Infrastructure Monitoring を始める際に参照するトレーニングビデオとドキュメンテーションへのリンク。
- 時間とフィルタパネル: 時間ウィンドウ(一覧画面上では設定変更できません)
- Integration パネル: Splunk Observability Cloud にメトリクスを送信しているすべてのテクノロジのリスト。
- タイルパネル: Integration によって監視されているサービスの合計数(Integration 別に表示)
Infrastructure パネルを使用して、興味のあるインフラストラクチャ/テクノロジーを選択できます。やってみましょう。
Exercise
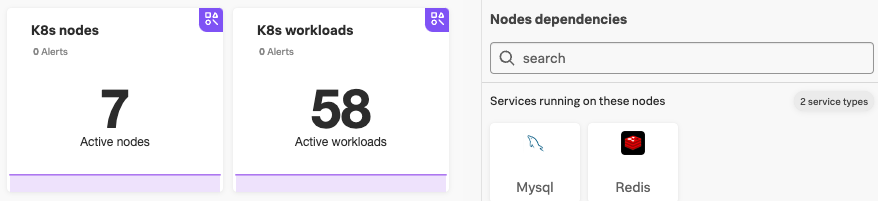
Integration パネルの Containers セクション(3)にある、Kubernetes を調査対象のテクノロジーとして選択します。
K8s Nodes と K8s Workloads の2つのタイルが表示されるはずです。
各タイルの下部には過去の推移を表すグラフがあり、上部には現在発生しているアラートの数が表示されます。これらの追加情報は全てのタイルに表示されており、インフラストラクチャの健全性を概要として確認するのに役立つはずです。
K8s Nodes タイルをクリックします。
Kubernetes クラスターが1つ以上の表示されます。
次に Add filters ボタンをクリックします。 k8s.cluster.name と入力し、検索結果をクリックします。
リストから [WORKSHOPの名前]-k3s-cluster を選択し、Apply Filter ボタンをクリックします。
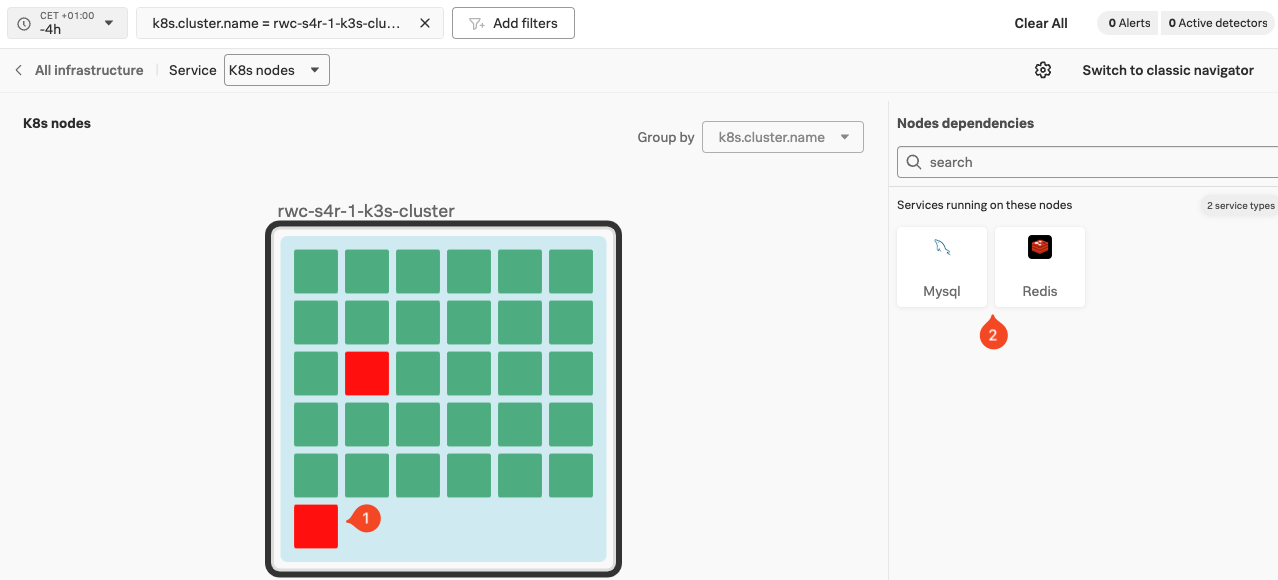
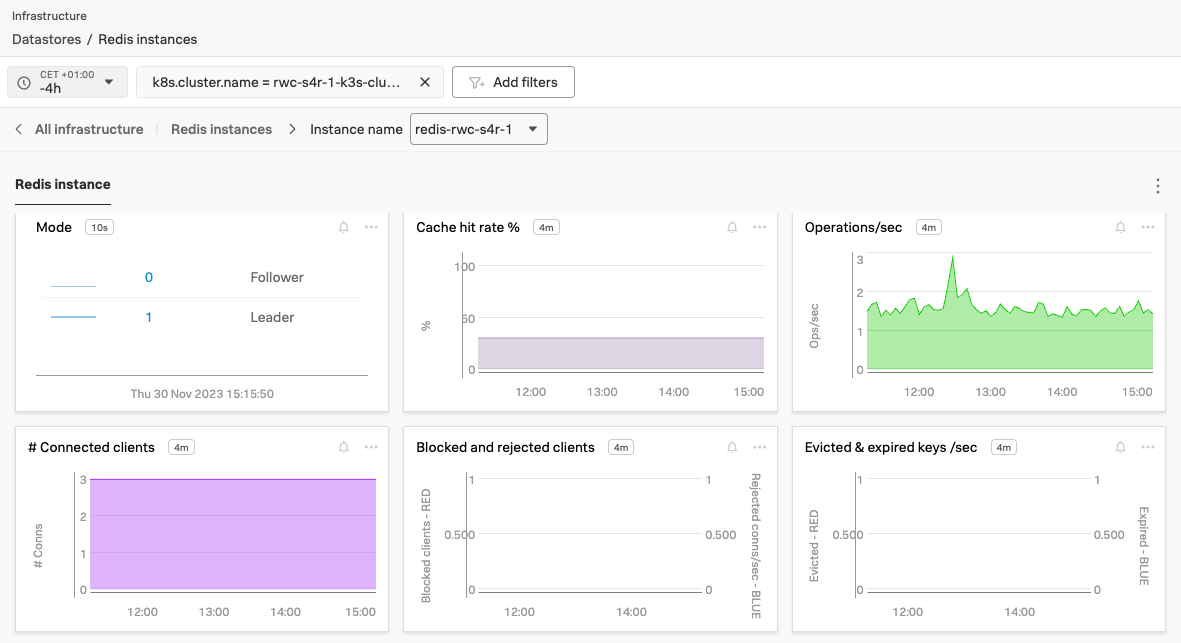
Kubernetes Navigator では、健全性を色で示します。ご覧の通り、2つの Pod またはサービスが健全ではなく、Failed 状態にあります(1)。残りは問題なく動いています。これは共用の Kubernetes 環境では一般的に発生することがあるもので、ワークショップではこれを再現しています。
サイドにあるタイルに注目してください。Nodes dependencies(2)の下に、MySQL と Redis のタイルが表示されています。これらは我々のeコマースアプリケーションで使用されている2つのデータベースです。
Node Dependencies
OpenTelemetry Collector によるモニタリングが構成されている場合、選択したノードで実行されているサービスが UI 上に表示されます。
これで Splunk Observability Cloud のツアーが完了しました。
さて、eコマースサイト「Online Boutique」にアクセスし、仮想のクレジット💶を使ってショッピングをしてみましょう。
5 分 ペルソナ
あなたは都会に暮らす、流行に敏感な人です。有名なオンラインブティックショップで次の新しいアイテムを買いたくてウズウズしています。オンラインブティックは、あらゆる流行の最先端を求める人のニーズを満たす場所であると聞いています。
この演習の目的は、オンラインブティックのウェブアプリケーションとやり取りすることです。これは Splunk Observability Cloud の機能をデモンストレーションするために使用されるサンプルアプリケーションで、アイテムを閲覧し、カートに追加してからチェックアウトすることができるシンプルなeコマースサイトです。
アプリケーションは既に展開されており、インストラクターからオンラインブティックのウェブサイトへのリンクが提供されます。
Exercise - ショッピングを始めましょう
- オンラインブティックへのリンクが手に入ったら、いくつかのアイテムを見て、カートに追加して、最後にチェックアウトしてみてください。
- この演習を数回繰り返し、可能であれば異なるブラウザ、モバイルデバイス、またはタブレットを使用してください。これにより、調査のために利用するより多くのデータを生成することができます。
Hint
ページの読み込みを待っている間に、マウスカーソルをページ上で動かしてください。これにより、後でこのワークショップで調査を行うためのさらに多くのデータが生成されます。
Exercise(続き)
- チェックアウト処理で何か気づきませんか? 完了までに時間がかかったように見えましたが、最終的には完了しましたか? こういったことが発生した場合は、注文確認 ID (Order Confirmation ID) をコピーして、後で使用できるようにローカルに保存してください。
- ショッピングに使用したブラウザセッションを閉じてください。
ユーザーエクスペリエンスが悪いと感じるかもしれません。これは顧客満足度に影響を与える潜在的な問題なので、これを解決するために手を打ってみましょう。
では、Splunk RUM でデータがどのように見えるか、確認してみましょう。
Splunk APMのサブセクション
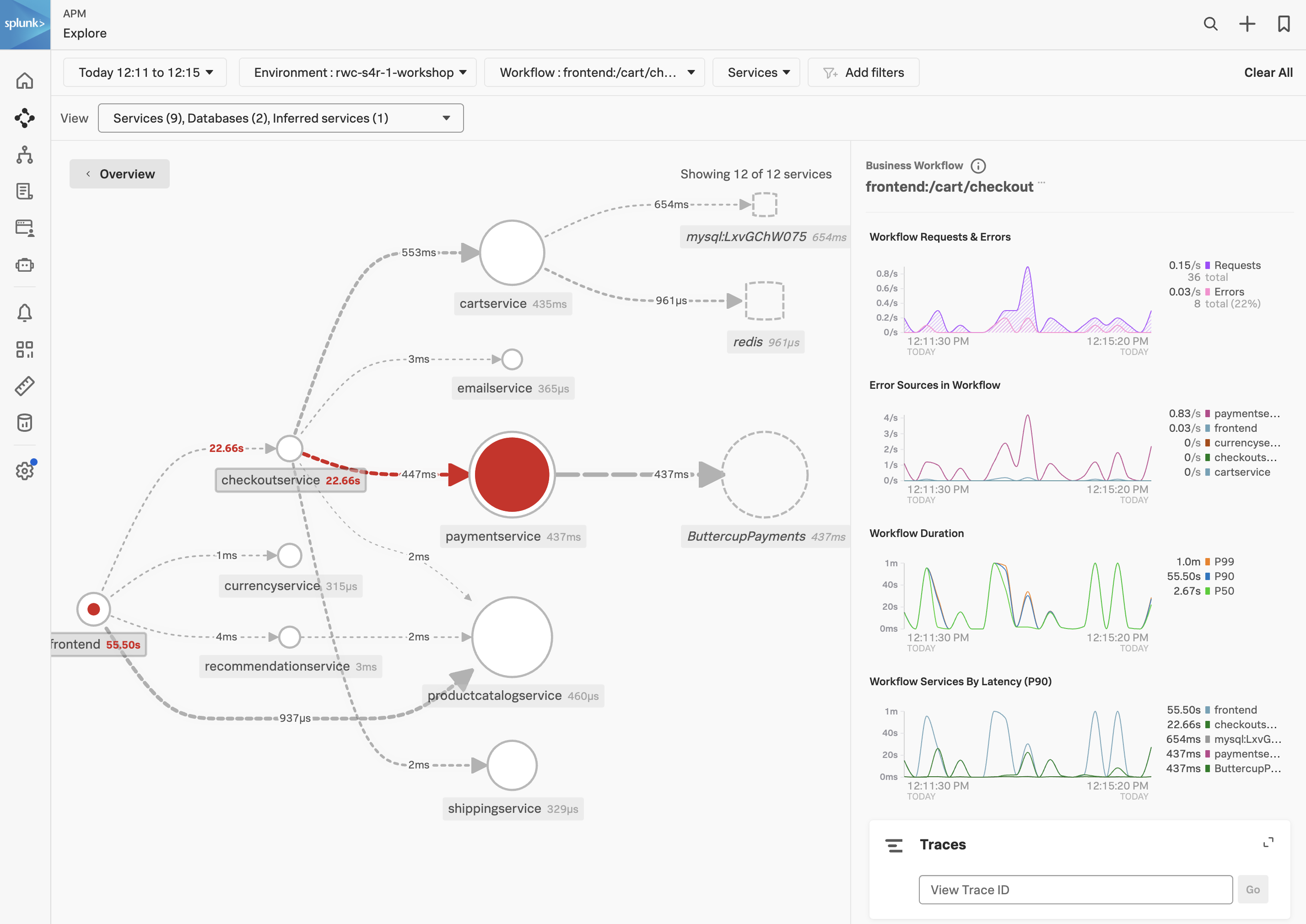
1. APM Explore
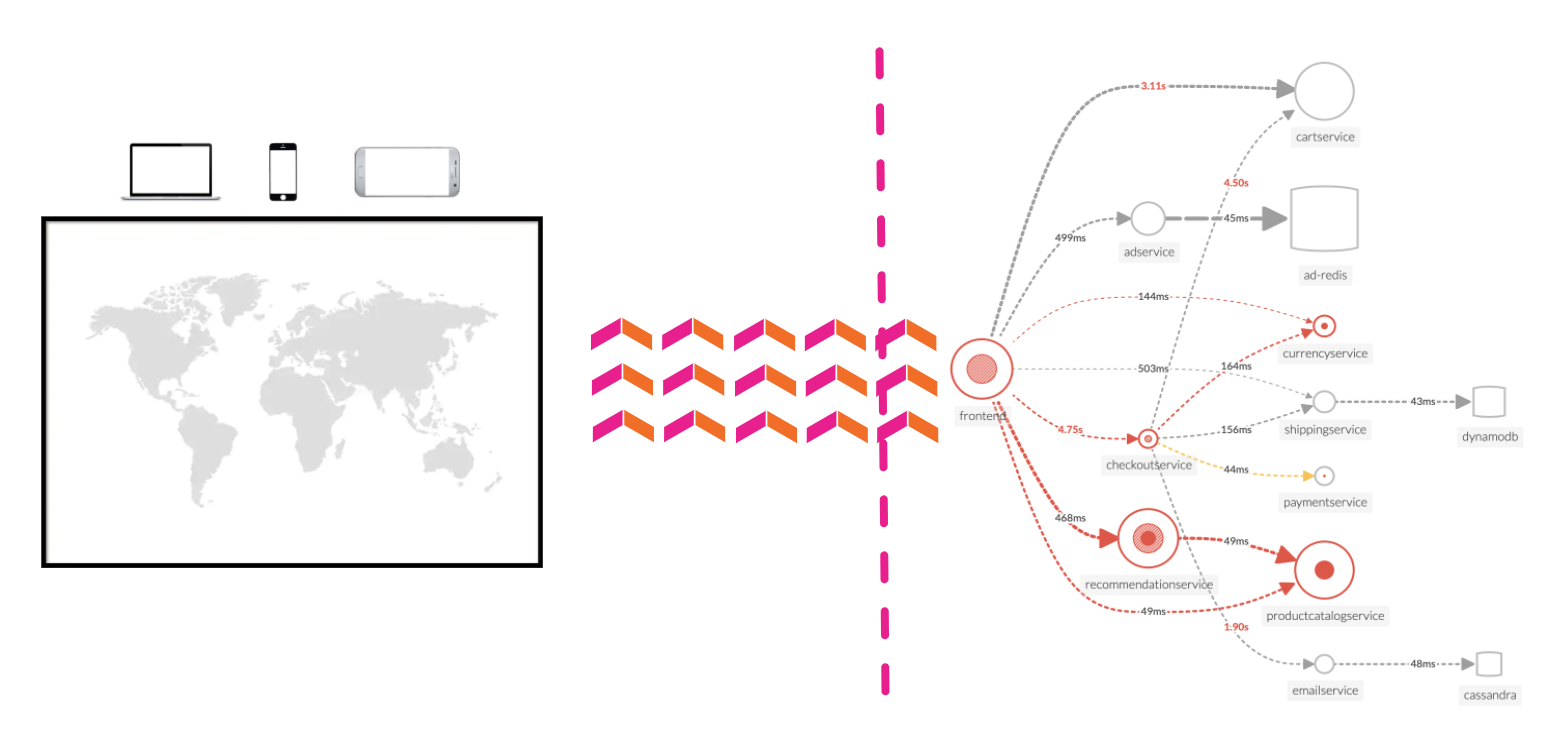
APM サービスマップは、APM で計装されたサービス、および、存在が推測されるサービス間の依存関係とつながりを表示します。このマップは、時間範囲、環境、ワークフロー、サービス、およびタグのフィルタで選択した内容に基づいて動的に生成されます。
RUM ウォーターフォールで APM リンクをクリックすると、サービスマップビューに自動的にフィルタが追加され、その Workflow Name(frontend:/cart/checkout)に関与したサービスが表示されます。
Service Map でワークフローに関係するサービスが表示されます。画面右側の Business Workflow の下には、選択したワークフローのチャートが表示されます。Service Map と Business Workflow のチャートは同期されています。Service Map 内であるサービスを選択すると、Business Workflow ペインのチャートが更新され、選択したサービスのメトリクスが表示されます。
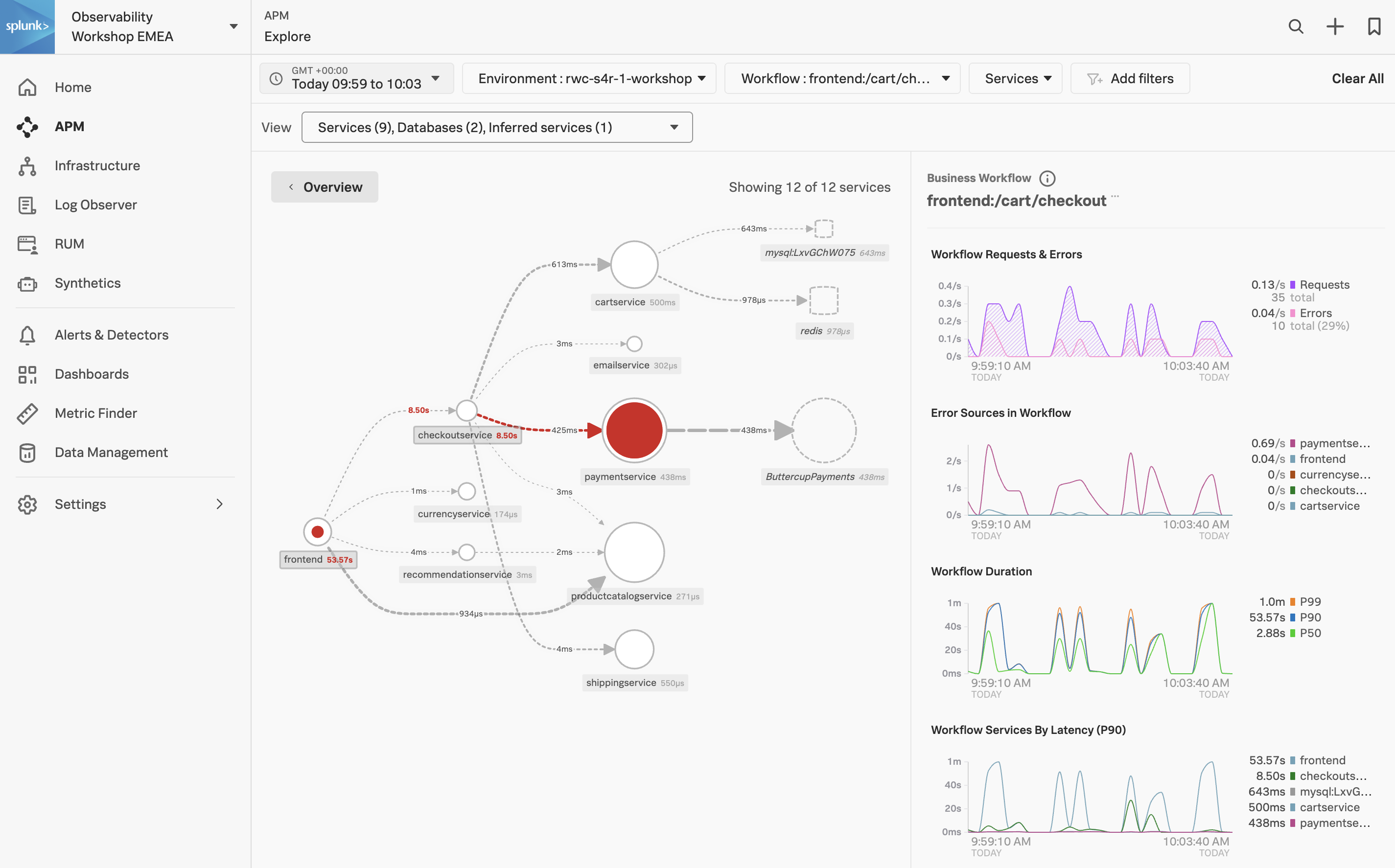
Exercise
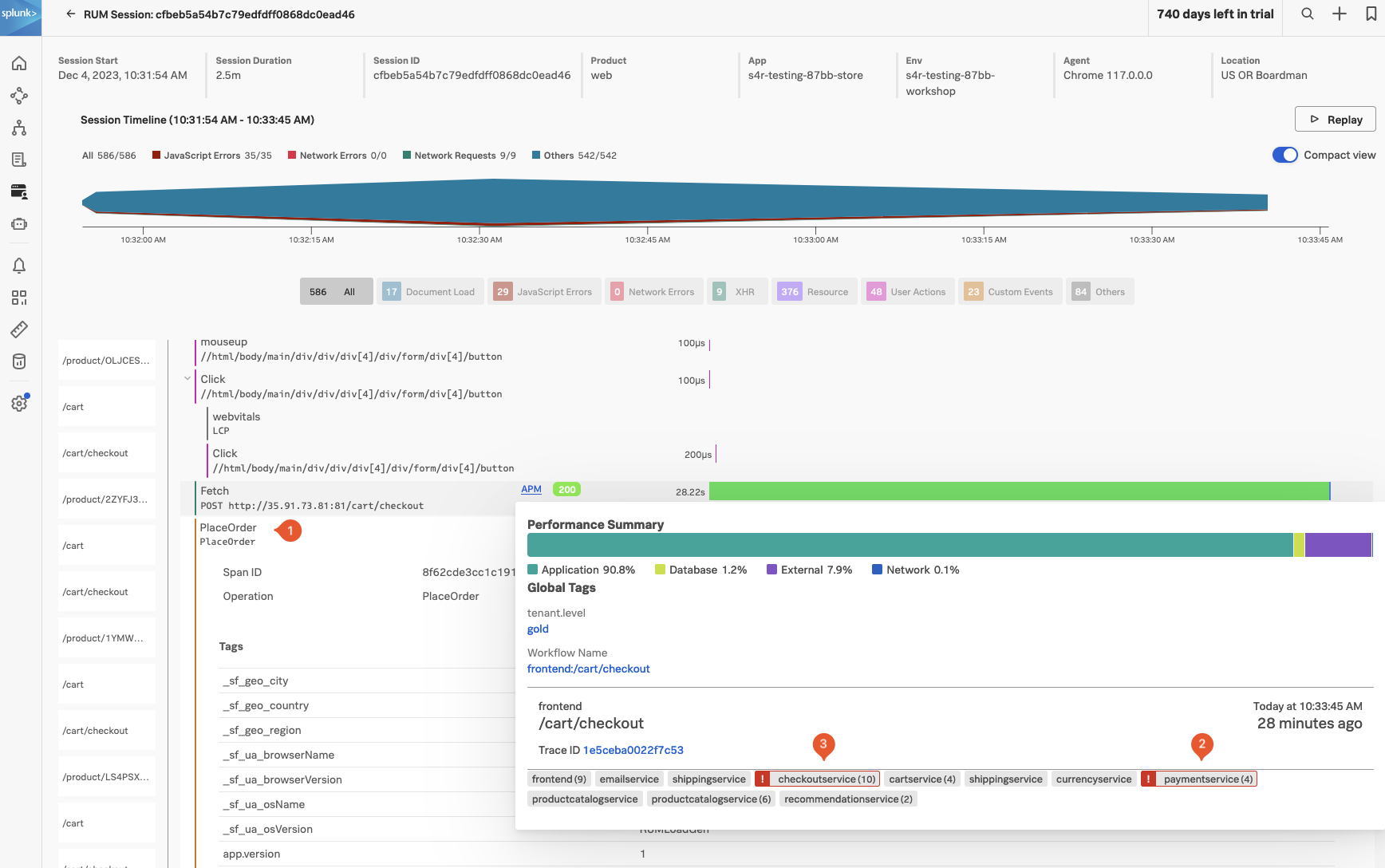
- paymentservice を Service Map でクリックしてください。
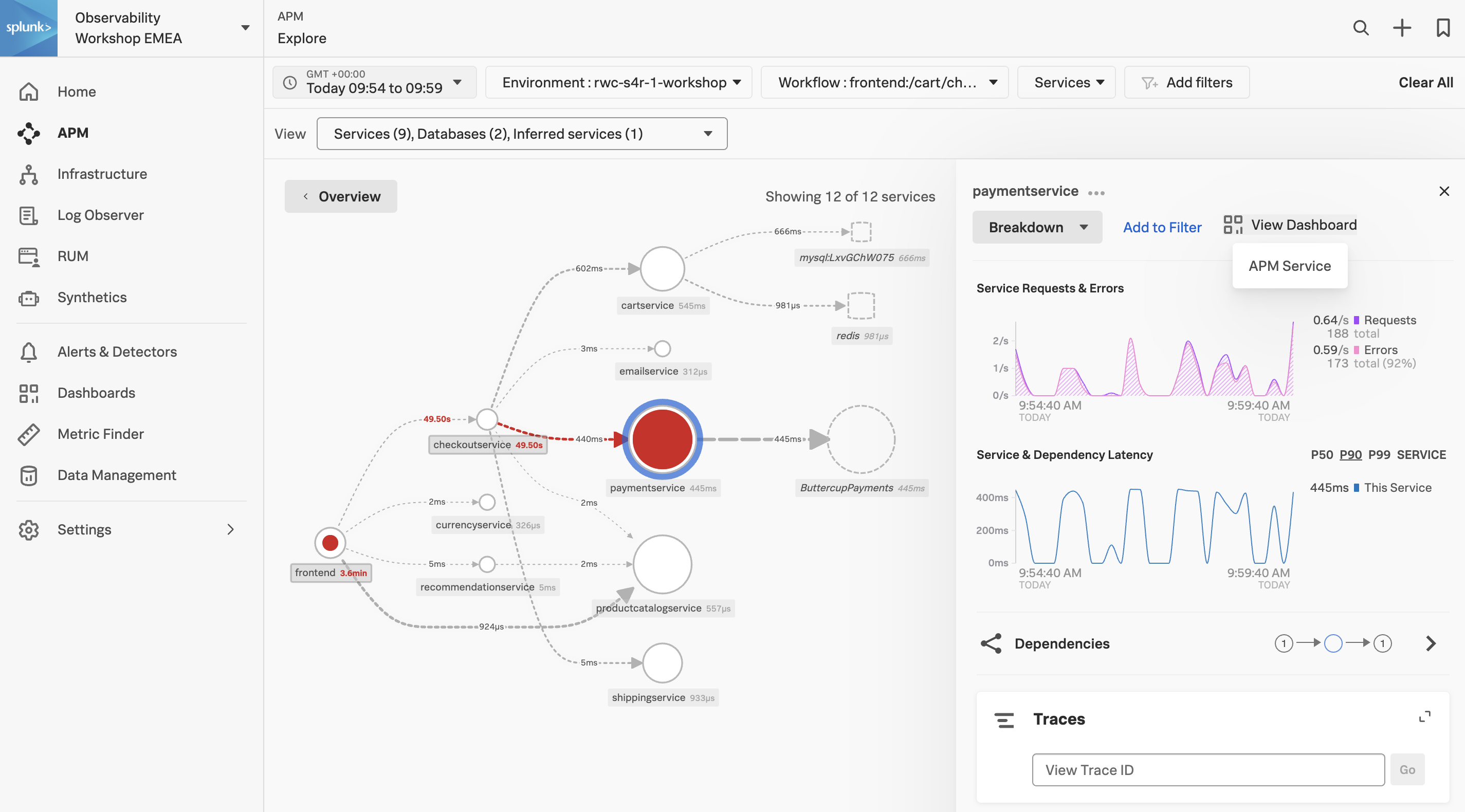
Splunk APM は、発生している問題をリアルタイムに確認し、特定のサービス、特定のエンドポイント、またはこれらを支えるインフラストラクチャに関連しているかどうかを迅速に判断するために利用できる、メトリクスをチャートとして可視化する一連の組み込みダッシュボードを提供しています。これを詳しく見てみましょう。
Exercise
- paymentservice パネルの右上にある View Dashboard をクリックしてください。
2. APM Service Dashboard
Service Dashboard
APM サービスダッシュボードは、サービス、エンドポイント、および Business Workflow のエンドポイントスパンから生成されたモニタリングメトリクセットに基づいて、リクエスト、エラー、および所要時間(RED)メトリクスを提供します。ダッシュボードを下にスクロールすると、基盤や Kubernetes に関連するメトリクスも表示され、インフラストラクチャに問題があるかどうかを判断するのに役立ちます。
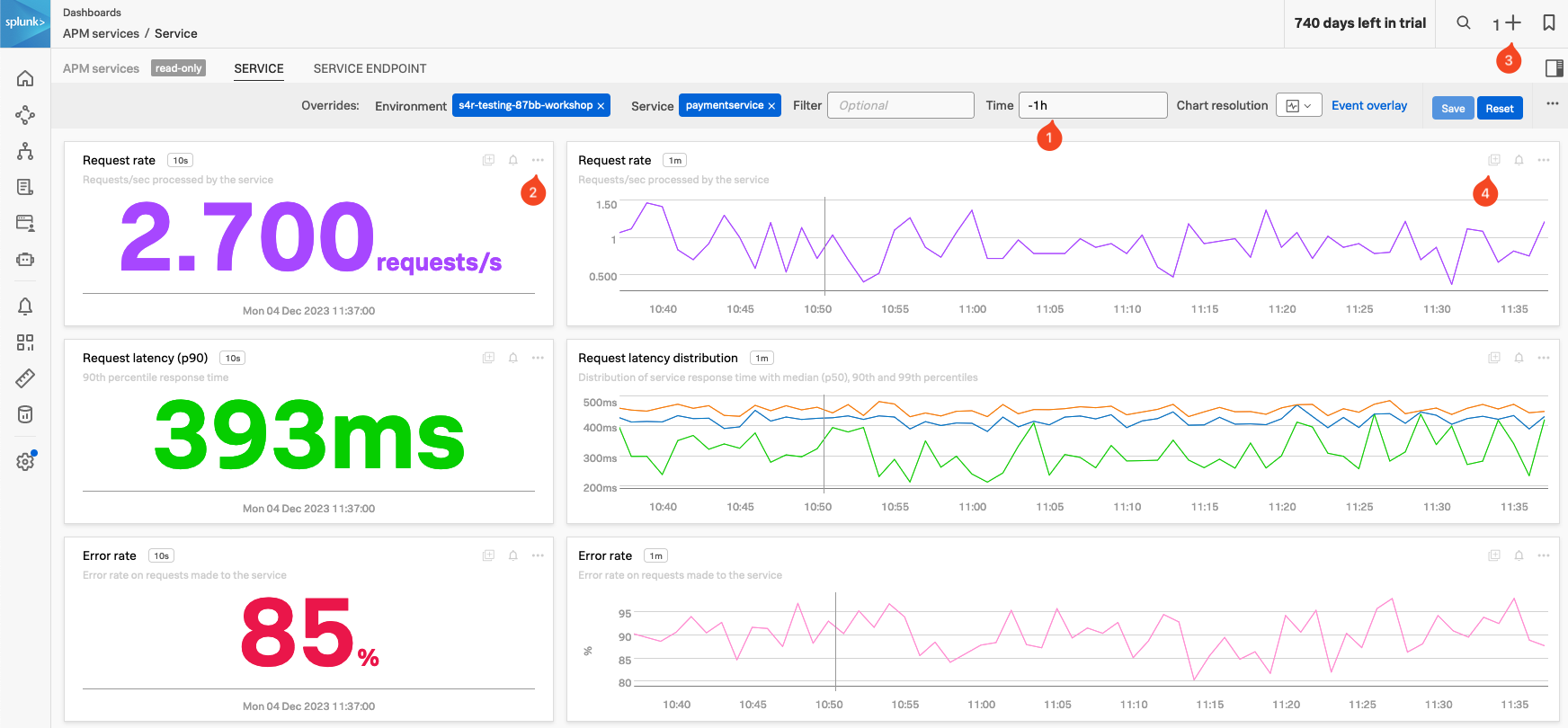
Exercise
- Time の枠 (1) を確認してください。ダッシュボードには、選択したアプリケーションの APM トレースによって取得された、処理にかかった時間に関するデータのみが表示されています(チャートは静的です)。
- Time の枠に -1h と入力し、Enter キーを押します。
- Request rate、Request latency (p90)、Error rate の Single Value チャートは 10 秒ごとに更新されており、引き続き多くのエラーが発生していることを示しています。
- これらのチャートはパフォーマンスの問題を迅速に特定するのに非常に役立ちます。このダッシュボードを使用してサービスのヘルスステータスを監視したり、ダッシュボードを作成・構成する際のベースとして利用することができます。
- これらのチャートをいくつか、後の演習で使用したいと思います。
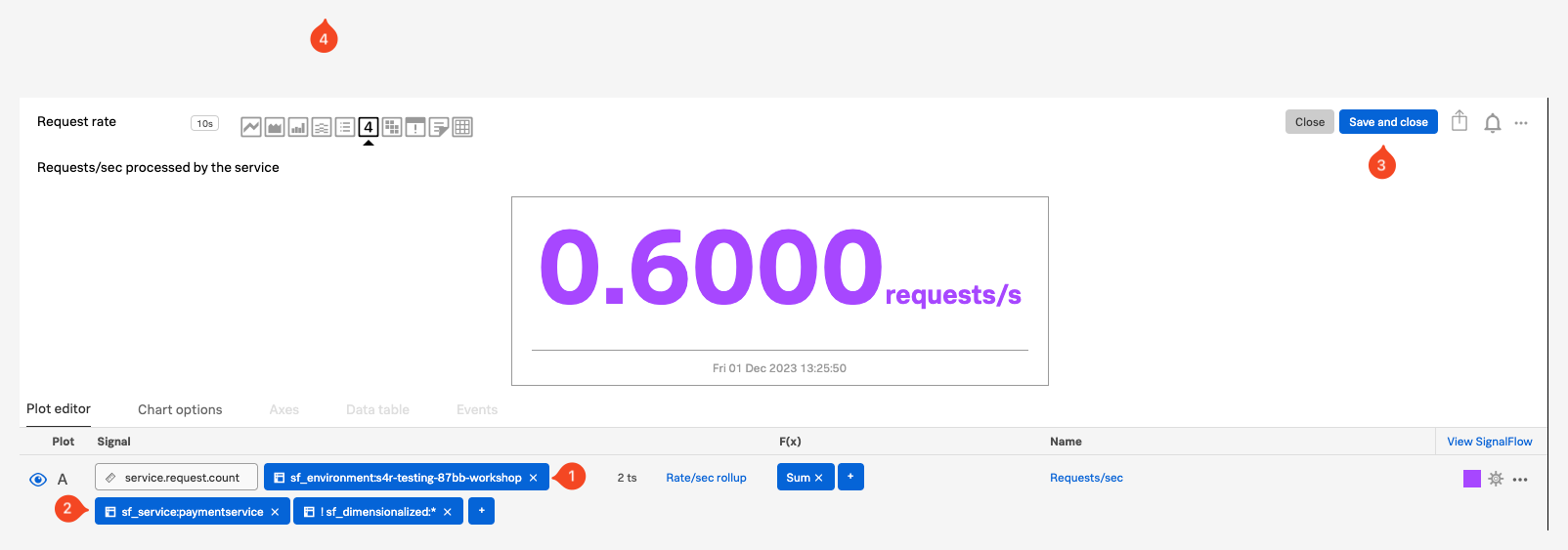
- Request rate Single Value チャート(2)で … をクリックし、Copy を選択します。これにより、ページの右上(3)の部分に 1 が表示され、クリップボードにコピーされたチャートがあることを示しています。
- Request rate の折れ線グラフ(4)では、Add to clipboard アイコンをクリックしてクリップボードに追加するか、… を使用して Add to clipboard を選択します。
- ページの右上(3)の部分に2が表示されていることを確認してください。
- それでは、エクスプロービューに戻りましょう。ブラウザの “戻る” ボタンをクリックしてください。

Exercise
サービスマップで paymentservice の上にカーソルを合わせてください。ポップアップして表示されたサービスに関するチャートからどんなことがわかりますか?
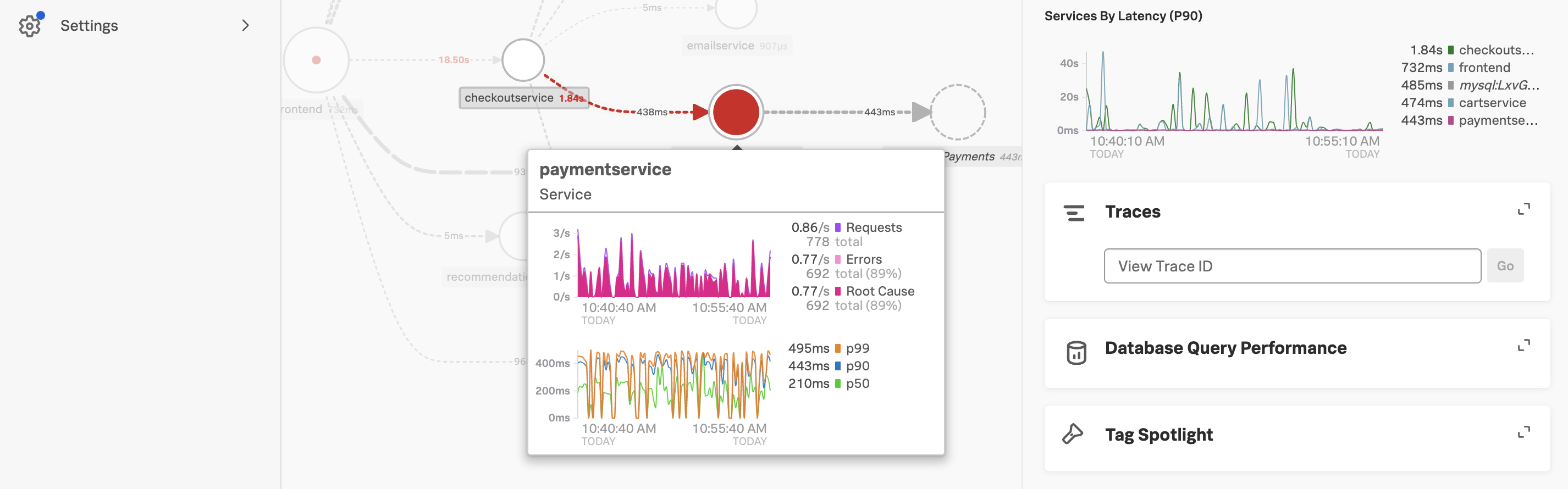
このエラー率にパターンがあるかどうかを理解する必要があります。そのためには、Tag Spotlight が便利です。
3. APM Tag Spotlight
Exercise
- paymentservice のタグを表示するには、paymentservice をクリックし、右側のメニューパネルで Tag Spotlight をクリックします(画面解像度によってはスクロールが必要な場合があります)。
- Tag Spotlight に移動したら、Show tags with no values のトグルスイッチがオフになっていることを確認してください。

Tag Spotlight には、2つの表示モードがあります。デフォルトは Request/Errors で、もう1つは Latency です。
Request/Error チャートでは、リクエストの合計数、エラーの合計数、および根本原因のエラーが表示されます。Latency チャートでは、p50、p90、および p99 のレイテンシが表示されます。これらの値は、Splunk APM がインデックス化された各スパンタグに対して生成する Troubleshooting MetricSets(TMS)に基づいています。これらは RED メトリクス(リクエスト、エラー、および所要時間)として知られています。
Exercise
version チャートです。v350.10 に対するリクエストの数はエラーの数と一致しています。
- これで、問題を引き起こしている paymentservice のバージョンを特定したので、エラーに関する詳細情報を見つけることができるかどうかを確認してみましょう。ページの上部にある ← Tag Spotlight をクリックして Service Map に戻ります。
4. APM Service Breakdown
Exercise
- 右側のペインで Breakdown をクリックします。
- リストから
tenant.level を選択します。これは顧客のステータスを表すタグであり、顧客のステータスに関連するトレンドを見るのに役立ちます。 - Service Map で gold をクリックして選択します。
- さらに Breakdown をクリックし、
version を選択します。これはサービスのバージョンを示すタグです。 - silver と bronze についても同様の手順を繰り返します。
確認できた内容から、どんな結論を得ることができますか?
すべてのテナントがバージョン v350.10 による影響を受けている
paymentservice が gold、silver、bronze の3つのサービスに分けて表示されていることが分かるでしょう。各テナントはバージョン (v350.10 と v350.9) ごとのサービスに分けられています。
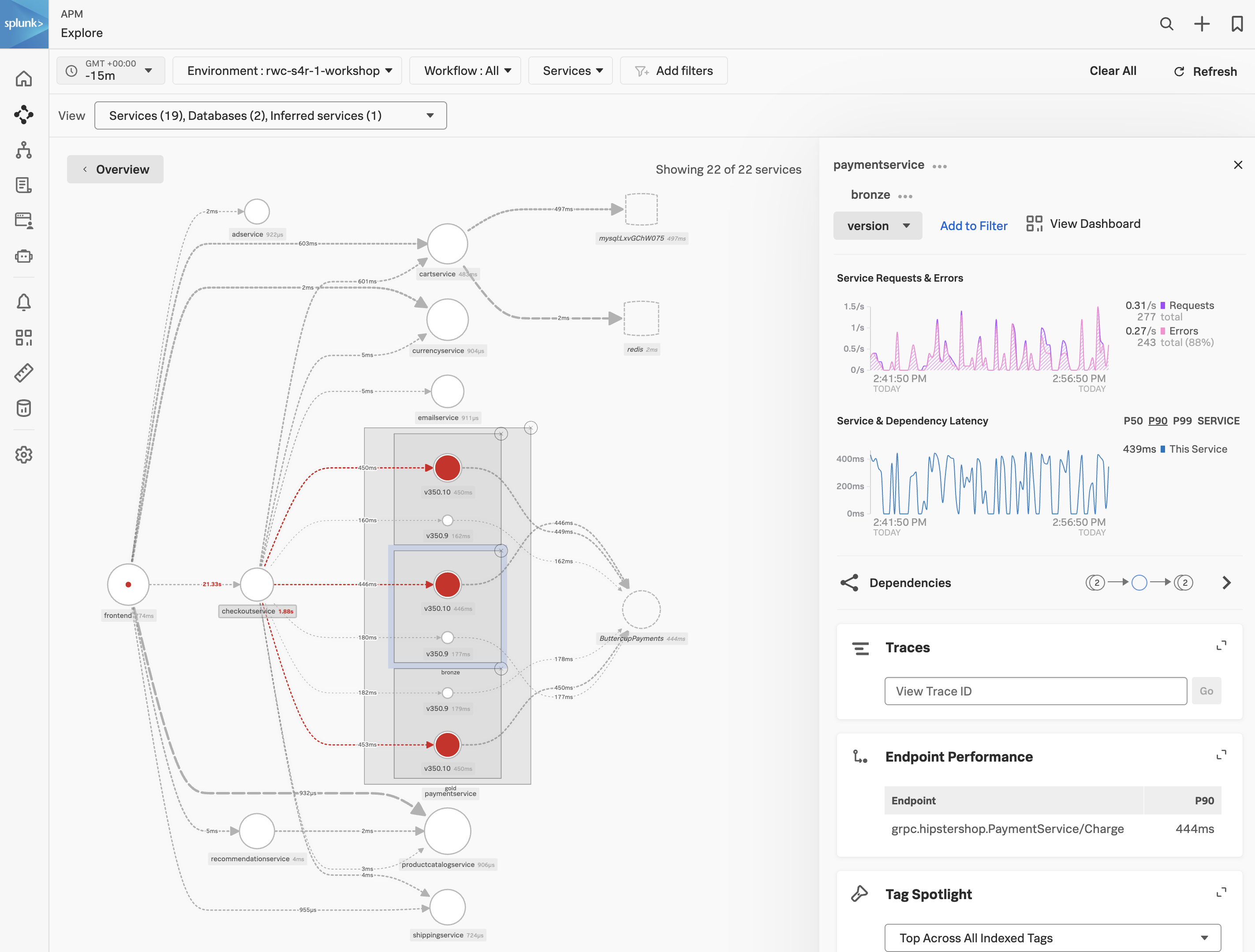
Exercise
- 3つの赤い円を囲む外側のメインボックスをクリックします。ボックスがハイライト表示されます。
スパンのタグ
スパンに付与されるタグに基づいてサービスの分析は非常に強力な機能です。これにより、異なる顧客、異なるバージョン、異なる地域などに対するサービスのパフォーマンスを確認できます。この演習では、paymentservice の v350.10 がすべての顧客に問題を引き起こしていることが判明しました。
次に、トレースを詳細に調査して問題の原因を見つける必要があります。
5. APM Trace Analyzer
Splunk APM では、NoSample™ の End to End の可視性が提供され、すべてのサービスのトレースがキャプチャされます。このワークショップでは、Order Confirmation ID がタグとして利用可能です。これにより、ワークショップの前半で遭遇したユーザーエクスペリエンスの問題のトレースを正確に検索できます。
Trace Analyzer
Splunk Observability Cloud は、アプリケーションモニタリングデータを探索するための複数のツールを提供しています。Trace Analyzer は、未知の問題や新しい問題を調査するために高カーディナリティで粒度の細かなデータを検索・探索するシナリオに適しています。
Exercise
- paymentservice の外側のボックスを選択した状態で、右側のペインで Traces をクリックします。
- Trace Analyzer を使用していることを確認するために、Switch to Classic View が表示されていることを確認します。表示されていない場合は、Switch to Trace Analyzer をクリックします。
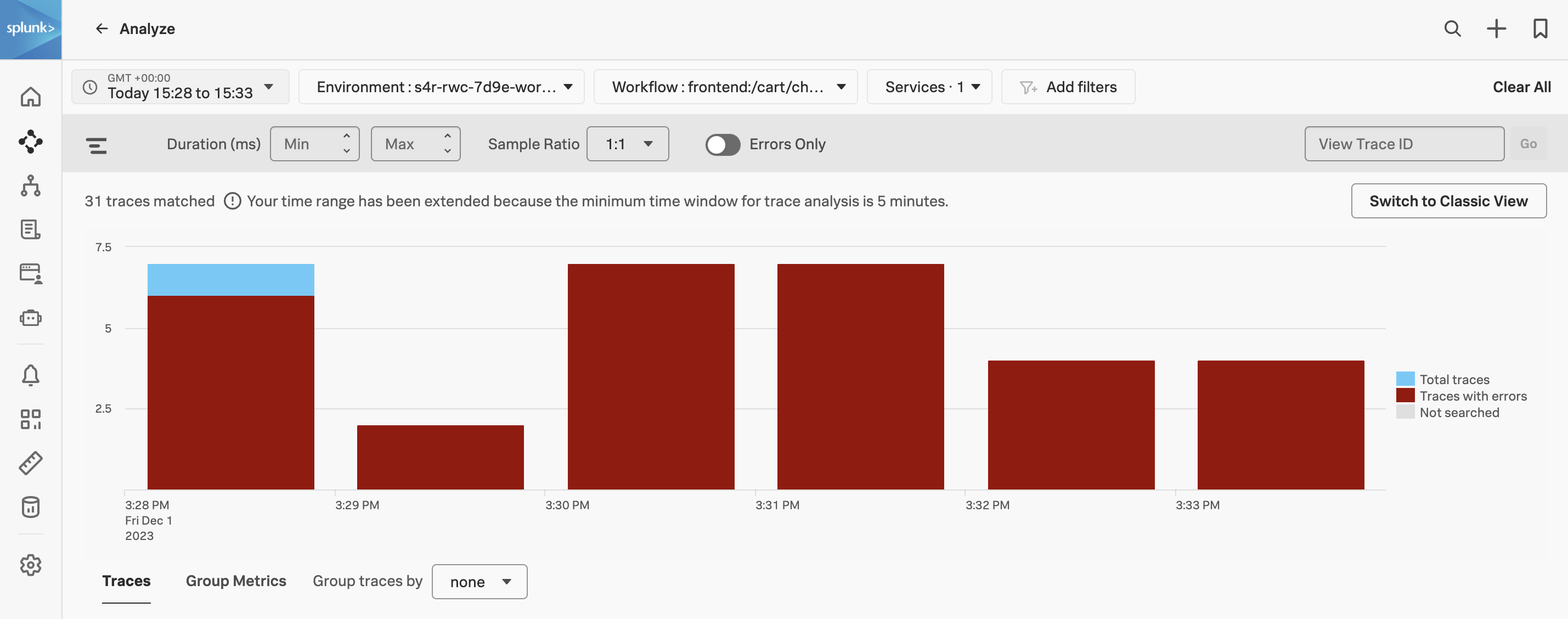
Exercise
- 表示する時間枠として Last 1 hour を選択します。
- ほとんどのトレースがエラー(赤)であり、エラーのない(青の)トレースは限られています。
- Sample Ratio が
1:10 ではなく 1:1 に設定されていることを確認します。 - Add filters をクリックし、
orderId を入力し、リストから orderId を選択します。 - ワークショップの前半でショッピングを行った際の Order Confirmation ID を貼り付けて Enter キーを押します。入力する ID が分からない場合は、インストラクターにお問い合わせください。
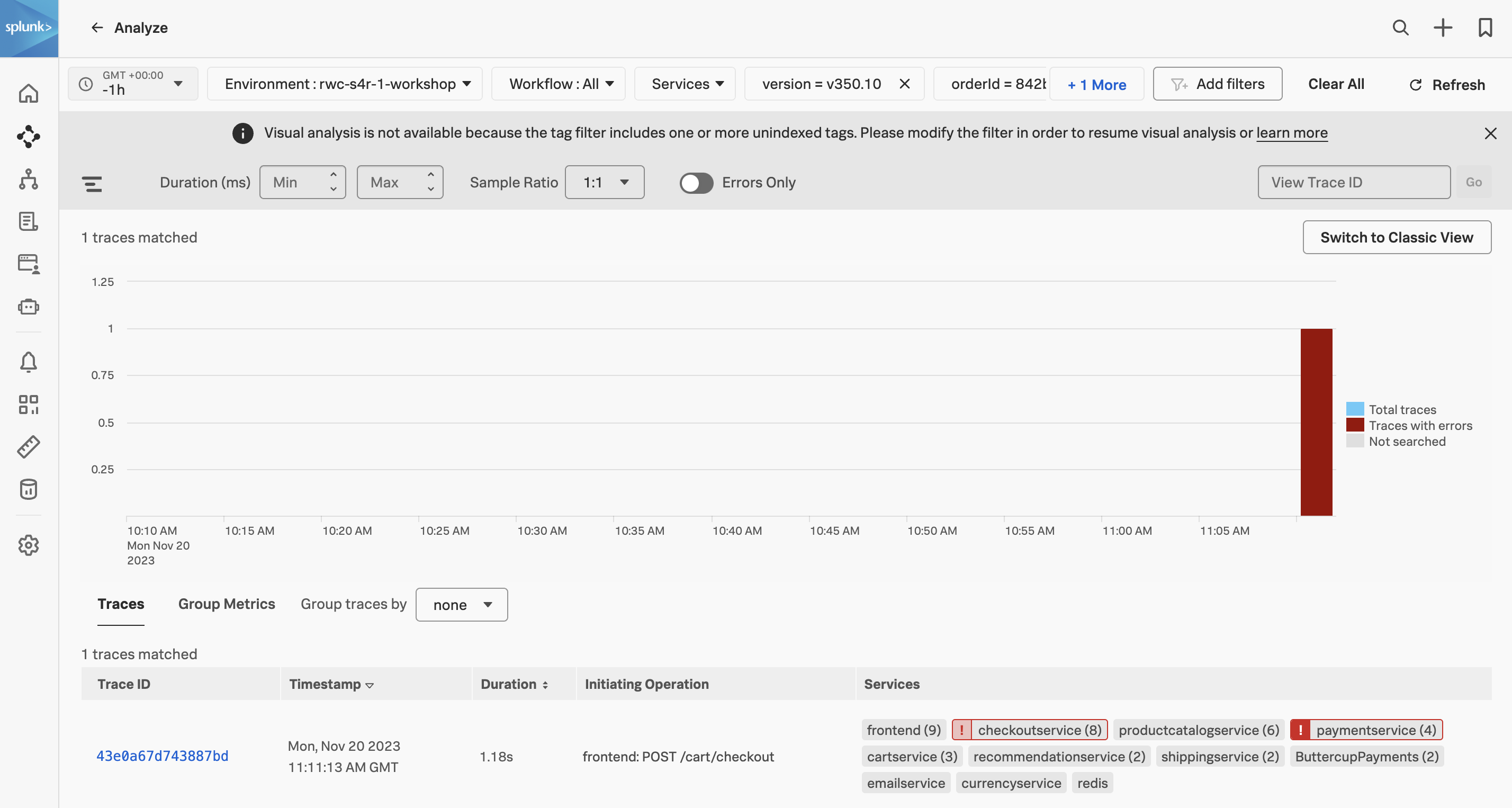
これで、あなたが体験した、チェックアウト処理で長時間待たされユーザーエクスペリエンスを損ねていた処理のトレースを絞り込むことができました。このトレースは最大13ヶ月間アクセスすることができます。そのため、例えば、開発者は後日この問題に再び取り組む際にも、このトレースを確認できるでしょう。
次に、トレースのウォーターフォールを見ていきましょう。
6. APM Waterfall
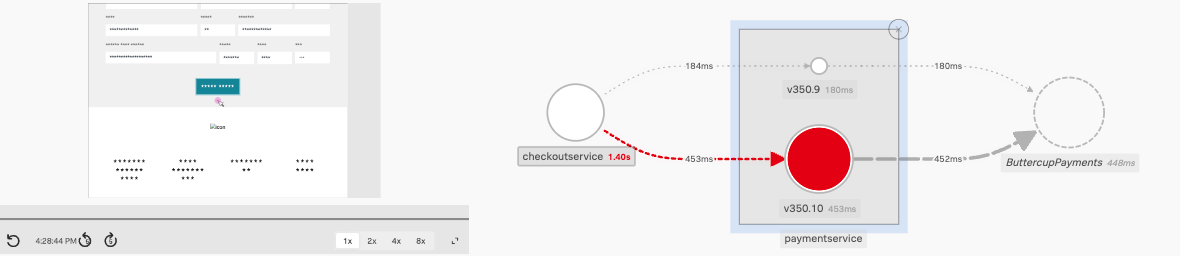
Trace Analyzer から Trace Waterfall に移動しました。トレースは、同じトレース ID を共有するスパンの集合であり、アプリケーションとその構成サービスによって処理される一意のトランザクションを表します。
Splunk APM の各スパンは、単一の操作をキャプチャします。Splunk APM は、スパンに記録された操作がエラーとなった場合、スパンをエラースパンと見なします。
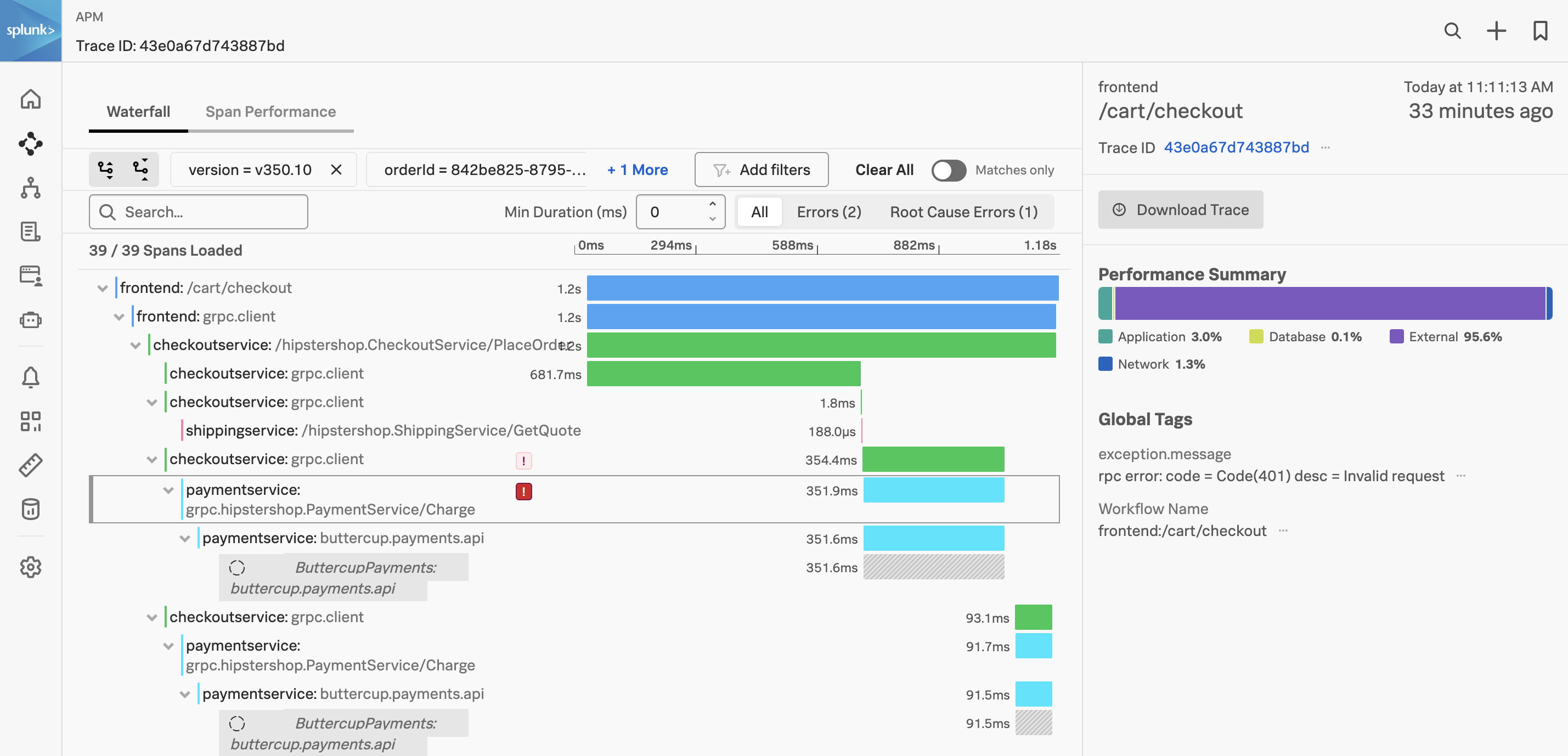
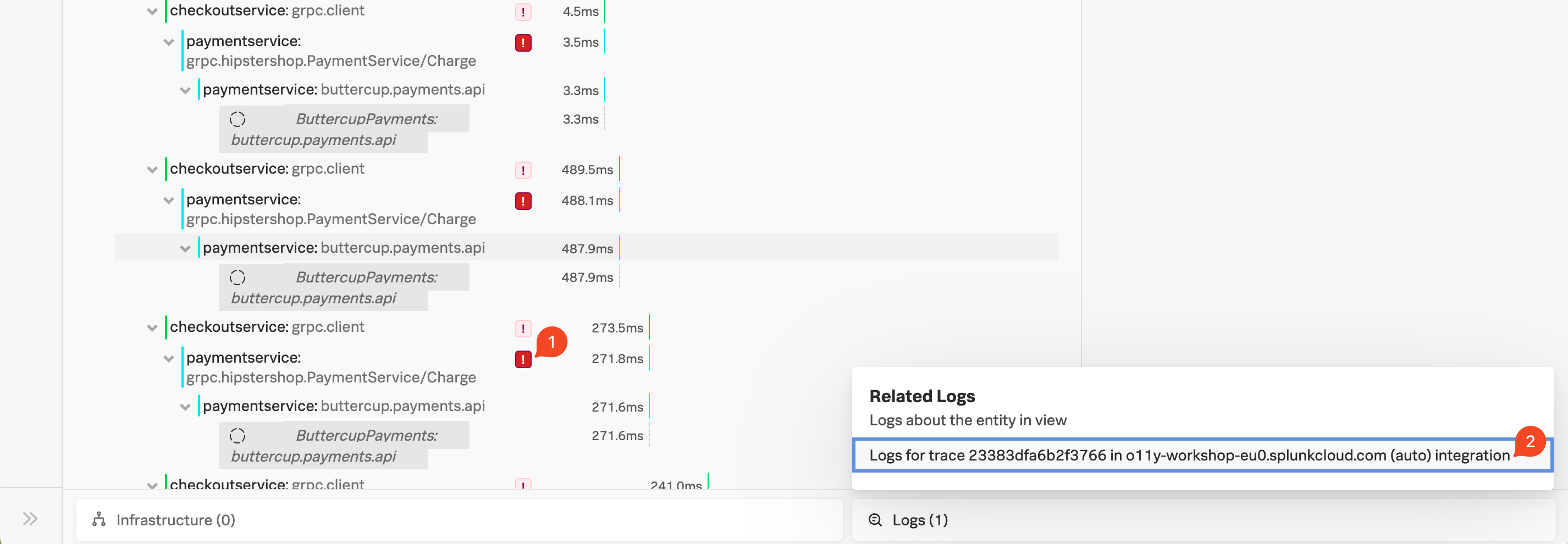
Exercise
- ウォーターフォール内の
paymentservice:grpc.hipstershop.PaymentService/Charge スパンの隣にある ! をクリックします。
スパンのメタデータに記録されているエラーメッセージとバージョンは何ですか?
Invalid Request と v350.10 です。
問題を引き起こしている paymentservice のバージョンを既に特定しているので、エラーに関してより詳細な情報を見つけられるか、やってみましょう。ここで Related logs が役立ちます。
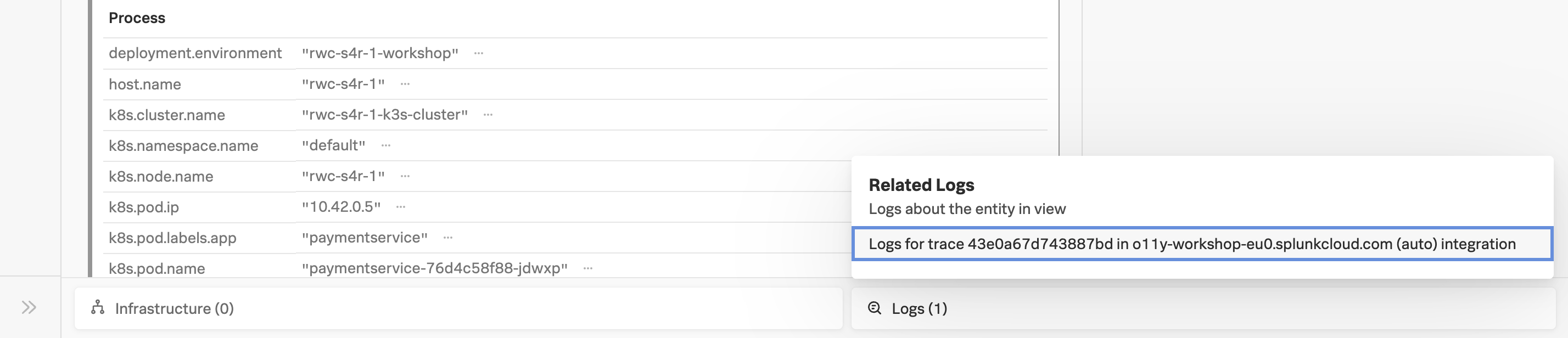
関連するコンテンツは、特定のメタデータによって実現されており、これにより、APM, Infrastructure Monitoring, Log Observer が Splunk Observability Cloud 内でフィルター条件を共有することで可能になっています。Related Logs が機能するには、ログに次のメタデータが必要です。
service.namedeployment.environmenthost.nametrace_idspan_id
Exercise
- Trace Waterfall の一番下で Logs (1) と書かれた部分をクリックします。これにより、このトレースに紐づく Related Logs があることが分かります。
- ポップアップ内の Logs for trace XXX エントリをクリックすると、トレース全体と関係のあるログが Log Observer で表示されます。
Splunk Log Observerのサブセクション
1. Log Filtering
Log Observer (LO) は複数の方法で使用できます。クイックツアーでは、LO ノーコードインターフェース を使用してログの特定のエントリを検索しました。ただし、このセクションでは、APM のトレースから LO に移動したと想定しています。
RUM と APM の間のリンクと同じように、前のアクションのコンテキストを引き継いでログを調査することができるのは一つの利点です。今回の場合、時間枠(1)を見てみると、これはトレースが取得された時間帯と一致しています。また、Filter(2)にも、trace_id の情報が既に設定されています。
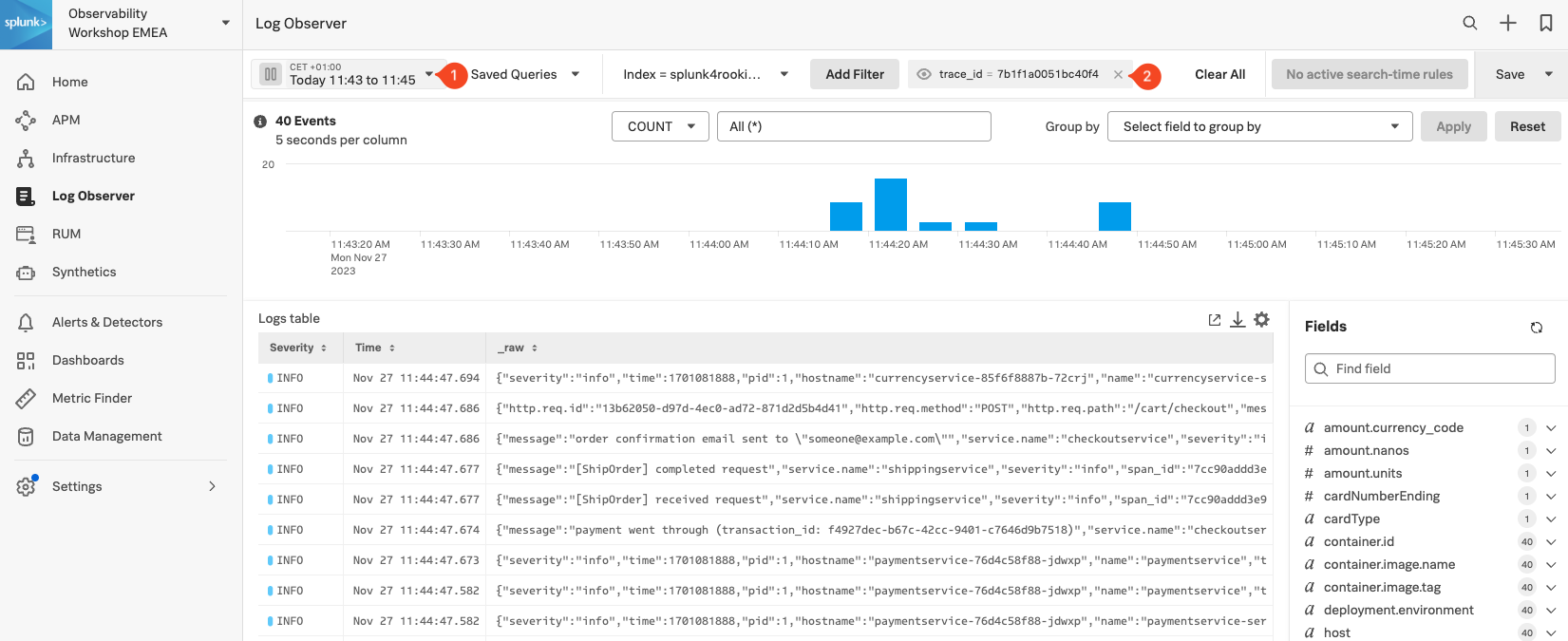
このビューには、オンラインブティックでエンドユーザーが実施した操作によって実行されたバックエンドのトランザクションに関わる すべての アプリケーションまたはサービスの すべての ログ行が含まれます。
オンラインブティックのような小さなアプリケーションでも、膨大な量のログが検出され、調査対象となる実際のインシデントに関わる特定のログを見つけ出すのが難しくなる場合があります。
次に、詳細なログエントリを見ていきましょう。
2. ログエントリの参照
特定のログ行を見る前に、これまでに何を行ってきたかと、オブザーバビリティの3本柱に基づいて、なぜここに辿り着いたのかを簡単に振り返りましょう。
| Metrics | Traces | Logs |
|---|
| 問題があるか? | 問題はどこにあるか? | 問題は何か? |
- メトリクスを使用して、アプリケーションに問題があることが判明しました。これは、サービスダッシュボードのエラーレートが本来の状態よりも高かったことから明らかです。
- トレースとスパンタグを使用して、問題がどこにあるかを見つけました。 paymentservice は
v350.9 と v350.10 の2つのバージョンで構成されており、 v350.10 に対するエラーレートは 100% でした。 - バージョン
v350.10 の paymentservice から生成されるエラーがオンラインブティックのチェックアウト処理の応答において、複数回の再試行と長時間の遅延を引き起こしていたことを確認しました。 - トレースから Related Content の強力な機能を使用して、失敗した paymentservice バージョンのログエントリに到達しました。これにより、問題が 何であるか を特定できるようになりました。
Exercise
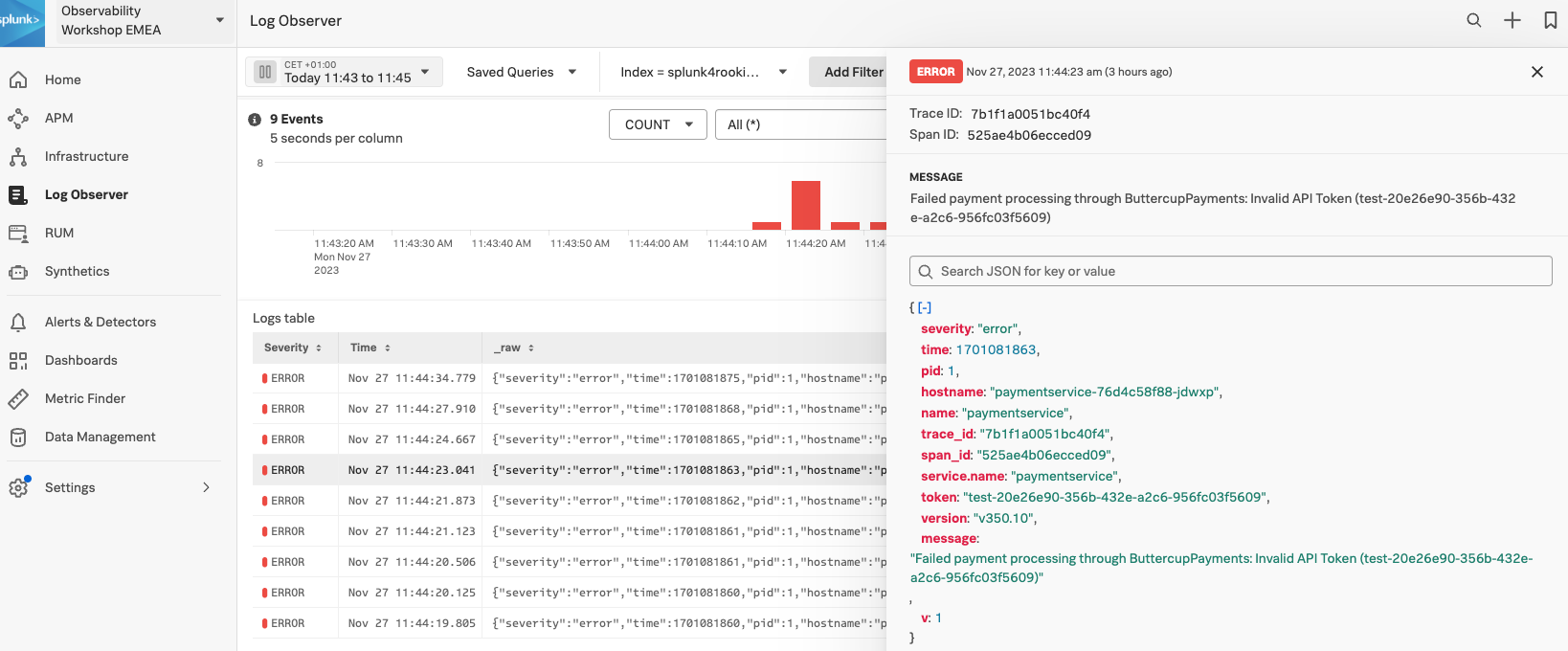
- Logs tables のエラーエントリをクリックします(異なるサービスからのまれなエラーがある場合は、エントリに
hostname: "paymentservice-xxxx" と表示されていることを確認してください)。
メッセージを踏まえ、問題を解決するためには開発チームに何を伝える必要がありますか?
開発チームは、有効なAPIトークンを使用してコンテナを再構築およびデプロイするか、 v350.9 にロールバックする必要があります。
- ログメッセージペインの X をクリックして閉じます。
おめでとうございます
Splunk Observability Cloud を使用することで、オンラインブティックでのショッピング中にユーザーエクスペリエンスが悪かった原因を理解することができました。オブザーバビリティの3本柱である メトリクス、トレース、ログ に基づいて、RUM、APM、およびログを利用することで、サービス全体で何が起こっており、その後、その根底にある原因を見つけることができました。
また、Splunkが提供する、アプリケーションの振る舞いのパターンを検出する Tag Spotlight によるインテリジェントなタグ付けと分析の機能や、問題のコンテキストを維持しながら異なるコンポーネント間を素早く移動する Related Contents によりスタック全体を相関させる機能についても、その使い方を理解したはずです。
ワークショップの次のパートでは、問題の特定から緩和、予防、およびプロセスの改善に進んでいきます。
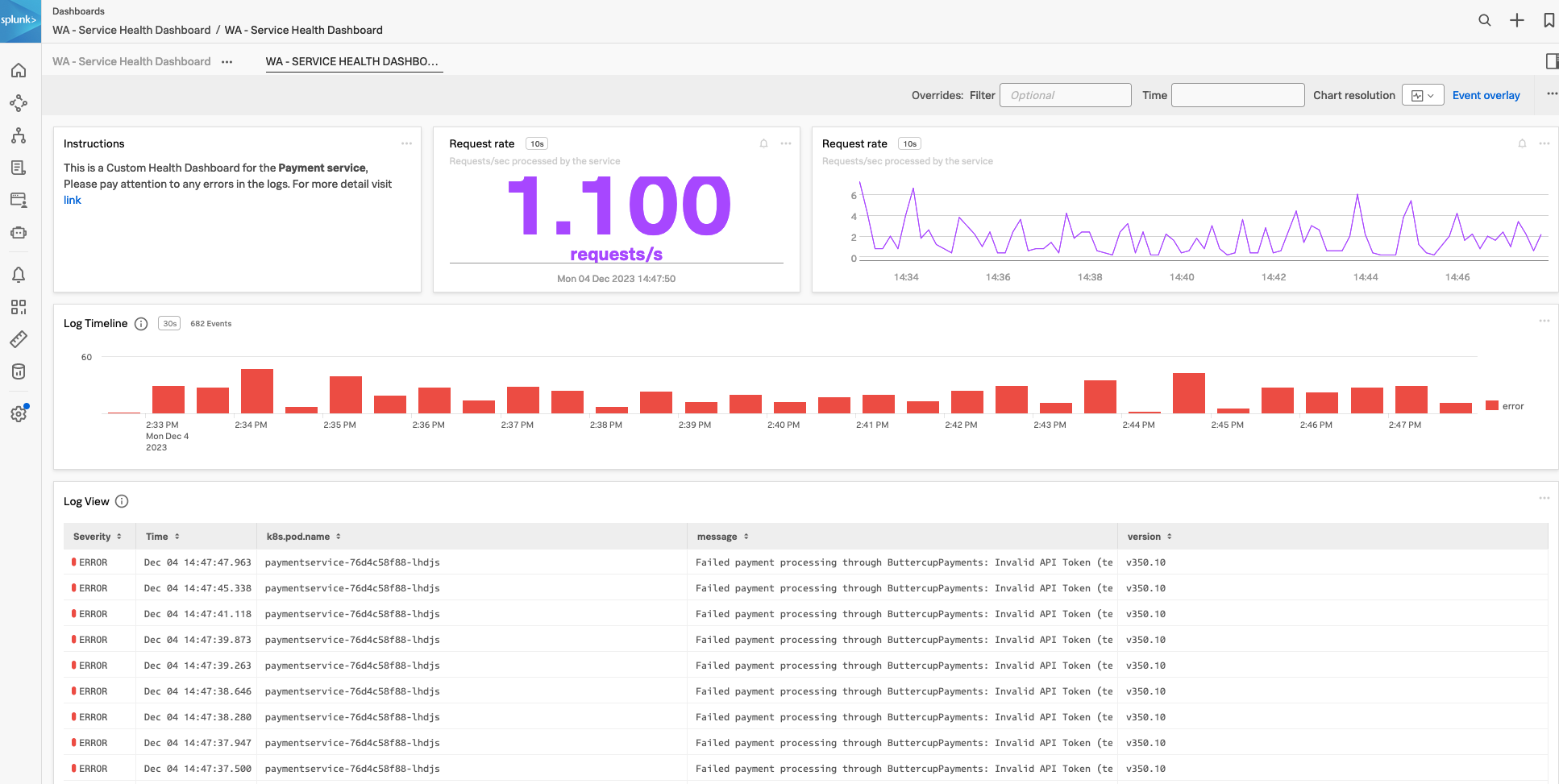
次に、カスタムダッシュボードでログチャートを作成します。
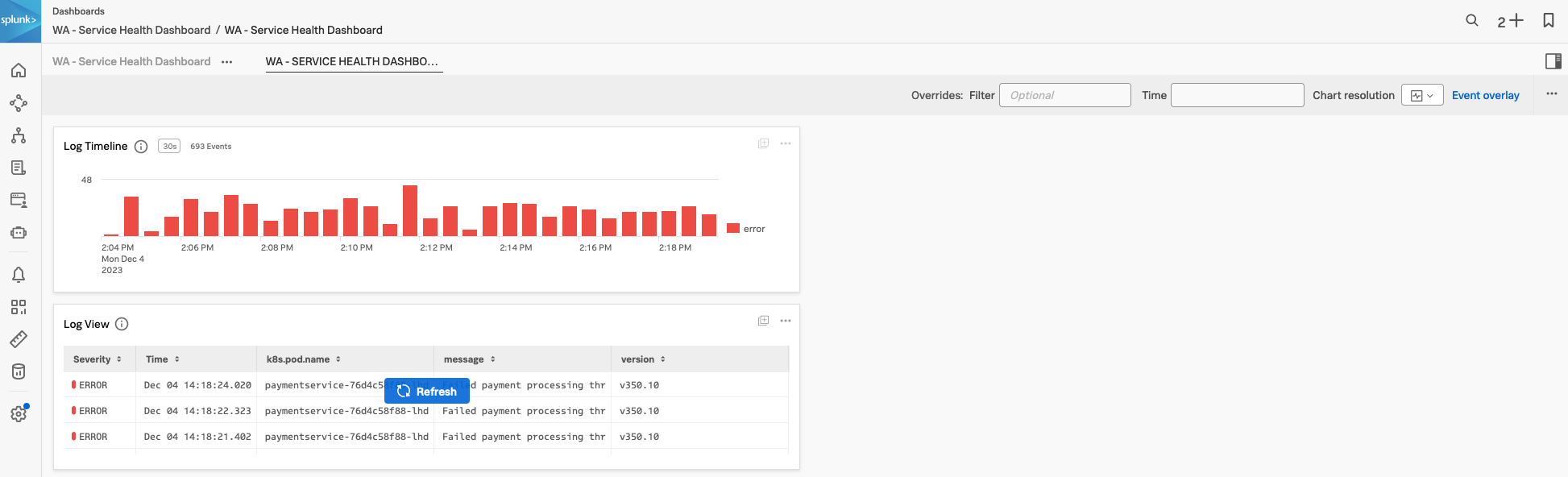
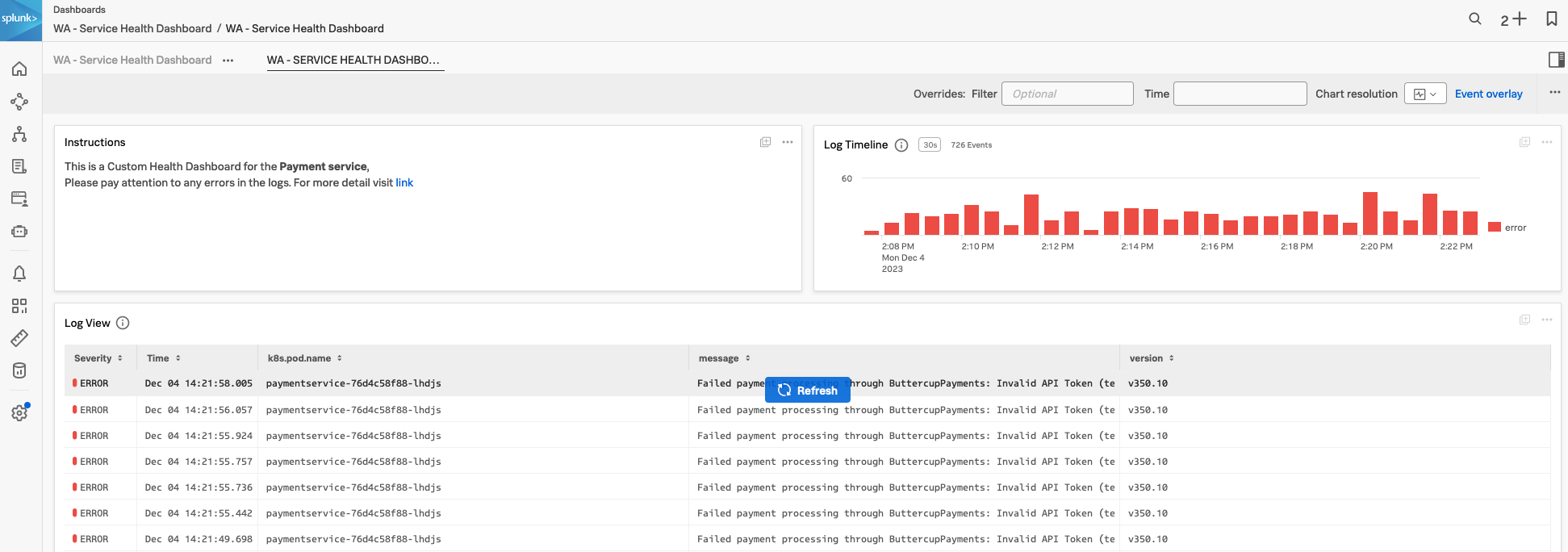
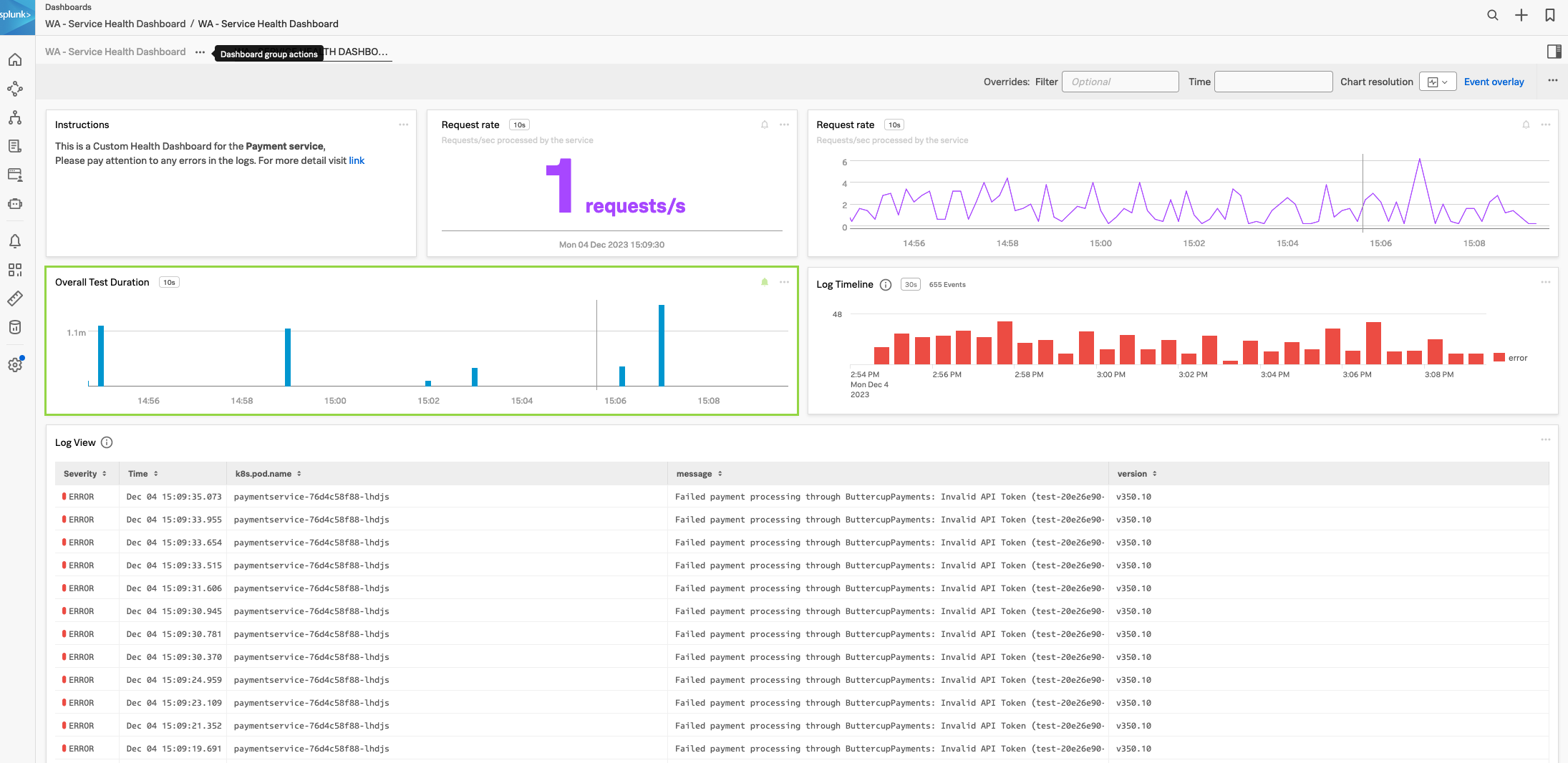
3. Log Timeline Chart
Log Observer である固定のビューを持っておくと、ダッシュボードの中でそのビューを活用し、将来的に問題の検出と解決にかかる時間を削減することができるでしょう。ワークショップの一環として、これらのチャートを使用するカスタムダッシュボードの例を作成します。
まず、Log Timeline チャートの作成を見てみましょう。Log Timeline チャートは、時間の経過とともにログメッセージを表示するために使用されます。これはログメッセージの頻度を確認し、パターンを識別するのに適した表現方法です。また、環境全体でのログメッセージの出力傾向を確認するのにも適しています。これらのチャートはカスタムダッシュボードに保存できます。
次に、Log View チャートを作成します。
4. Log View Chart
次に、ログに関するチャートタイプである Log View チャートタイプを見ていきます。このチャートを使用すると、事前に定義しておいたフィルタに基づいてログメッセージを表示できます。
前の Log Timeline チャートと同様に、Log View のチャートを Customer Health Service Dashboard に追加します。
次のセッションでは、Splunk Synthetics を見て、Web ベースのアプリケーションのテストを自動化する方法を見ていきます。