Make expensive service outages a thing of the past. Remediate issues faster, reduce on-call burnout and keep your services up and running.
Subsections of Unsupported Field Workshops
Splunk IM
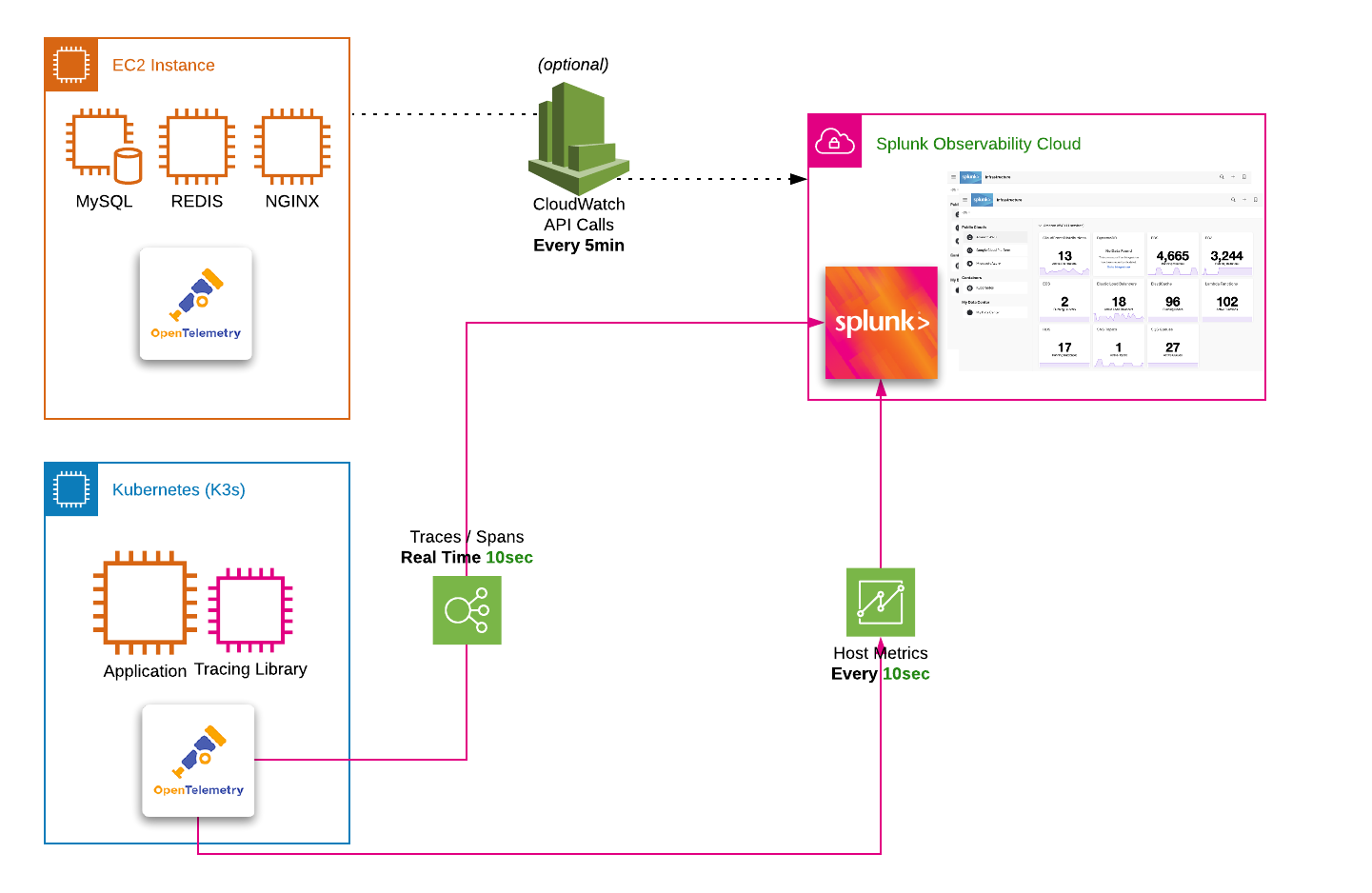
During this technical Splunk Observability Cloud Infrastructure Monitoring and APM Workshop, you will build out an environment based on a lightweight Kubernetes1 cluster.
To simplify the workshop modules, a pre-configured AWS/EC2 instance is provided.
The instance is pre-configured with all the software required to deploy the Splunk OpenTelemetry Connector2 in Kubernetes, deploy an NGINX^3 ReplicaSet^4 and finally deploy a microservices-based application which has been instrumented using OpenTelemetry to send metrics, traces, spans and logs3.
The workshops also introduce you to dashboards, editing and creating charts, creating detectors to fire alerts, Monitoring as Code and the Service Bureau4
By the end of these technical workshops, you will have a good understanding of some of the key features and capabilities of the Splunk Observability Cloud.
Here are the instructions on how to access your pre-configured AWS/EC2 instance
Kubernetes is a portable, extensible, open-source platform for managing containerized workloads and services, that facilitates both declarative configuration and automation. ↩︎
OpenTelemetry Collector offers a vendor-agnostic implementation on how to receive, process and export telemetry data. In addition, it removes the need to run, operate and maintain multiple agents/collectors to support open-source telemetry data formats (e.g. Jaeger, Prometheus, etc.) sending to multiple open-source or commercial back-ends. ↩︎
Jaeger, inspired by Dapper and OpenZipkin, is a distributed tracing system released as open source by Uber Technologies. It is used for monitoring and troubleshooting microservices-based distributed systems ↩︎
How to retrieve the IP address of the AWS/EC2 instance assigned to you.
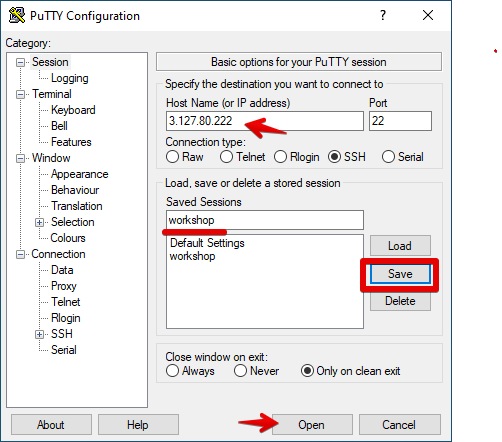
Connect to your instance using SSH, Putty1 or your web browser.
Verify your connection to your AWS/EC2 cloud instance.
Using Putty (Optional)
Using Multipass (Optional)
1. AWS/EC2 IP Address
In preparation for the workshop, Splunk has prepared an Ubuntu Linux instance in AWS/EC2.
To get access to the instance that you will be using in the workshop please visit the URL to access the Google Sheet provided by the workshop leader.
Search for your AWS/EC2 instance by looking for your first and last name, as provided during registration for this workshop.
Find your allocated IP address, SSH command (for Mac OS, Linux and the latest Windows versions) and password to enable you to connect to your workshop instance.
It also has the Browser Access URL that you can use in case you cannot connect via ssh or Putty - see EC2 access via Web browser
Important
Please use SSH or Putty to gain access to your EC2 instance if possible and
make a note of the IP address as you will need this during the workshop.
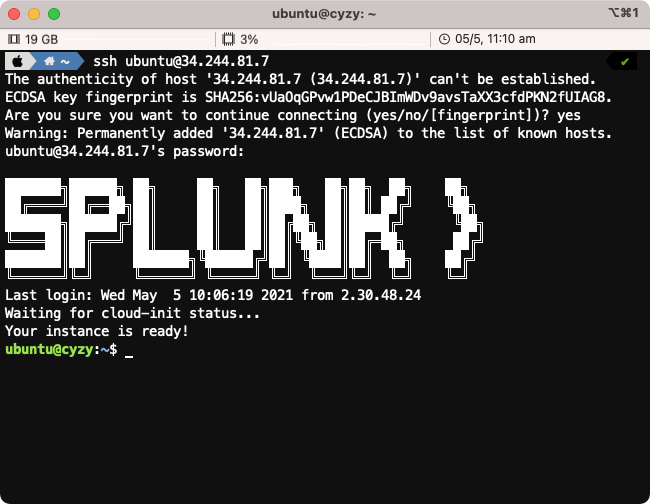
2. SSH (Mac OS/Linux)
Most attendees will be able to connect to the workshop by using SSH from their Mac or Linux device, or on Windows 10 and above.
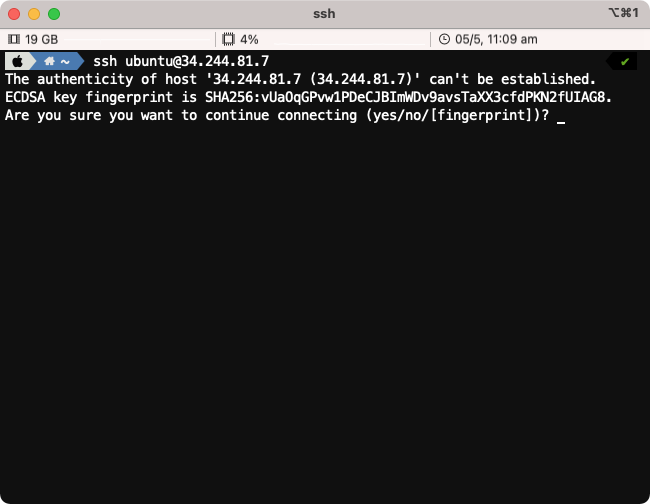
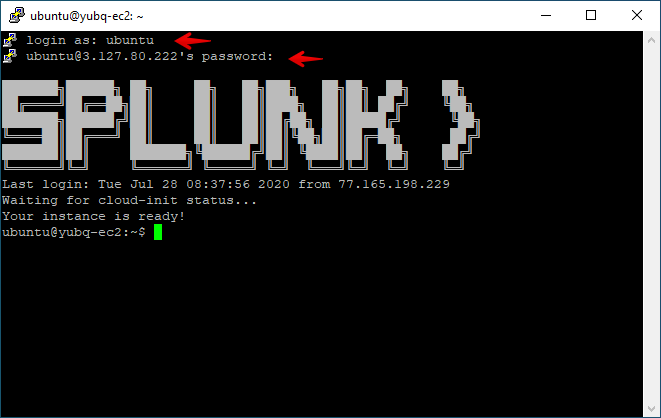
To use SSH, open a terminal on your system and type ssh splunk@x.x.x.x (replacing x.x.x.x with the IP address found in Step #1).
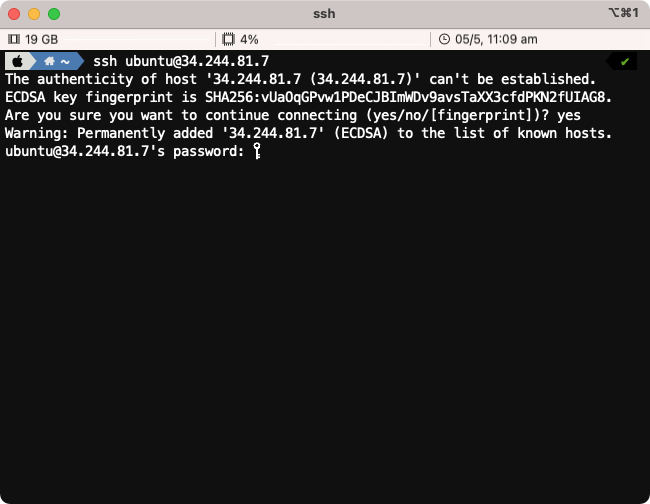
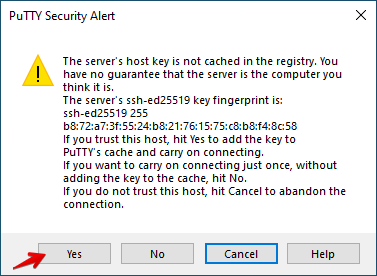
When prompted Are you sure you want to continue connecting (yes/no/[fingerprint])? please type yes.
Enter the password provided in the Google Sheet from Step #1.
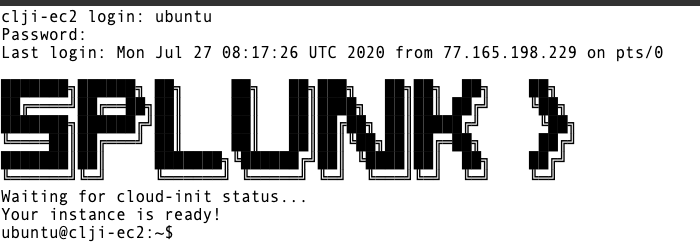
Upon successful login, you will be presented with the Splunk logo and the Linux prompt.
3. SSH (Windows 10 and above)
The procedure described above is the same on Windows 10, and the commands can be executed either in the Windows Command Prompt or PowerShell.
However, Windows regards its SSH Client as an “optional feature”, which might need to be enabled.
You can verify if SSH is enabled by simply executing ssh
If you are shown a help text on how to use the ssh-command (like shown on the screenshot below), you are all set.
If the result of executing the command looks something like the screenshot below, you want to enable the “OpenSSH Client” feature manually.
To do that, open the “Settings” menu, and click on “Apps”. While in the “Apps & features” section, click on “Optional features”.
Here, you are presented with a list of installed features. On the top, you see a button with a plus icon to “Add a feature”. Click it.
In the search input field, type “OpenSSH”, and find a feature called “OpenSSH Client”, or respectively, “OpenSSH Client (Beta)”, click on it, and click the “Install”-button.
Now you are set! In case you are not able to access the provided instance despite enabling the OpenSSH feature, please do not shy away from reaching
out to the course instructor, either via chat or directly.
If you are blocked from using SSH (Port 22) or unable to install Putty you may be able to connect to the workshop instance by using a web browser.
Note
This assumes that access to port 6501 is not restricted by your company’s firewall.
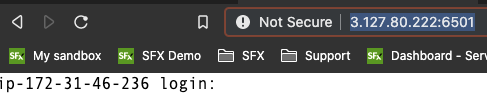
Open your web browser and type http://x.x.x.x:6501 (where X.X.X.X is the IP address from the Google Sheet).
Once connected, login in as splunk and the password is the one provided in the Google Sheet.
Once you are connected successfully you should see a screen similar to the one below:
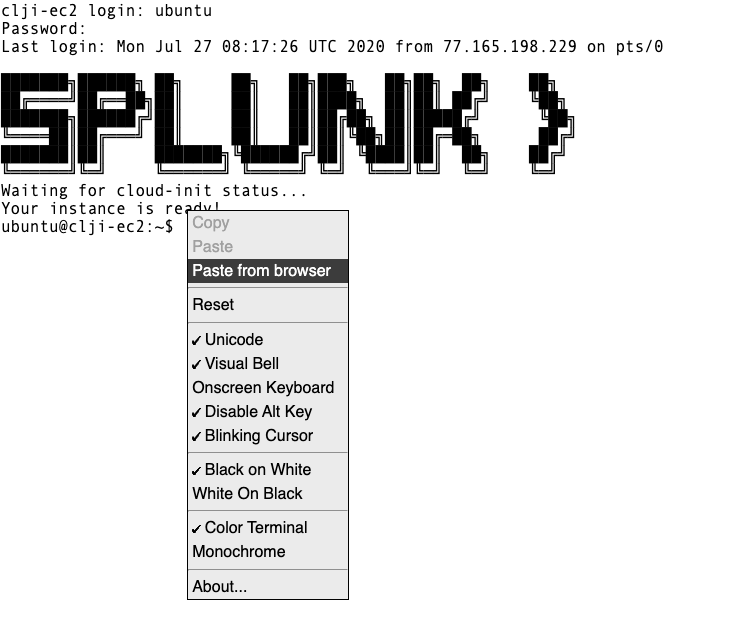
Unlike when you are using regular SSH, copy and paste does require a few extra steps to complete when using a browser session. This is due to cross browser restrictions.
When the workshop asks you to copy instructions into your terminal, please do the following:
Copy the instruction as normal, but when ready to paste it in the web terminal, choose Paste from browser as show below:
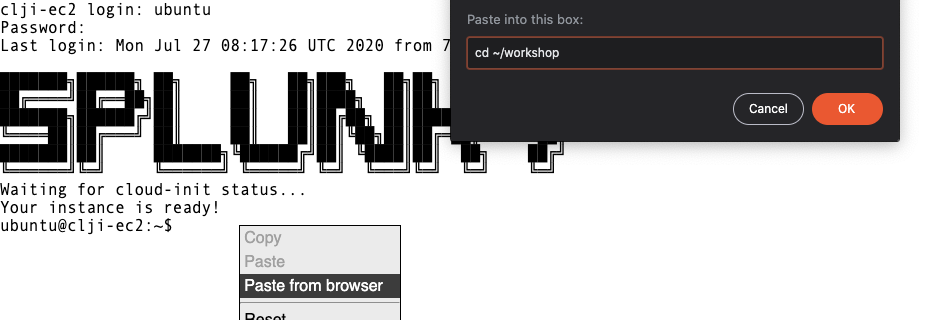
This will open a dialogue box asking for the text to be pasted into the web terminal:
Paste the text in the text box as shown, then press OK to complete the copy and paste process.
Note
Unlike regular SSH connection, the web browser has a 60-second time out, and you will be disconnected, and a Connect button will be shown in the center of the web terminal.
Simply click the Connect button and you will be reconnected and will be able to continue.
Using ACCESS_TOKEN={REDACTED}
Using REALM=eu0
“splunk-otel-collector-chart” has been added to your repositories
Using ACCESS_TOKEN={REDACTED}
Using REALM=eu0
Hang tight while we grab the latest from your chart repositories…
…Successfully got an update from the “splunk-otel-collector-chart” chart repository
Update Complete. ⎈Happy Helming!⎈
Install the OpenTelemetry Collector Helm chart with the following commands, do NOT edit this:
Using ACCESS_TOKEN={REDACTED}
Using REALM=eu0
NAME: splunk-otel-collector
LAST DEPLOYED: Fri May 7 11:19:01 2021
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
You can monitor the progress of the deployment by running kubectl get pods which should typically report a new pod is up and running after about 30 seconds.
Ensure the status is reported as Running before continuing.
kubectl get pods
NAME READY STATUS RESTARTS AGE
splunk-otel-collector-agent-2sk6k 0/1 Running 0 10s
splunk-otel-collector-k8s-cluster-receiver-6956d4446f-gwnd7 0/1 Running 0 10s
Ensure there are no errors by tailing the logs from the OpenTelemetry Collector pod. The output should look similar to the log output shown in the Output tab below.
Use the label set by the helm install to tail logs (You will need to press ctrl+c to exit). Or use the installed k9s terminal UI for bonus points!
2021-03-21T16:11:10.900Z INFO service/service.go:364 Starting receivers…
2021-03-21T16:11:10.900Z INFO builder/receivers_builder.go:70 Receiver is starting… {“component_kind”: “receiver”, “component_type”: “prometheus”, “component_name”: “prometheus”}
2021-03-21T16:11:11.009Z INFO builder/receivers_builder.go:75 Receiver started. {“component_kind”: “receiver”, “component_type”: “prometheus”, “component_name”: “prometheus”}
2021-03-21T16:11:11.009Z INFO builder/receivers_builder.go:70 Receiver is starting… {“component_kind”: “receiver”, “component_type”: “k8s_cluster”, “component_name”: “k8s_cluster”}
2021-03-21T16:11:11.009Z INFO k8sclusterreceiver@v0.21.0/watcher.go:195 Configured Kubernetes MetadataExporter {“component_kind”: “receiver”, “component_type”: “k8s_cluster”, “component_name”: “k8s_cluster”, “exporter_name”: “signalfx”}
2021-03-21T16:11:11.009Z INFO builder/receivers_builder.go:75 Receiver started. {“component_kind”: “receiver”, “component_type”: “k8s_cluster”, “component_name”: “k8s_cluster”}
2021-03-21T16:11:11.009Z INFO healthcheck/handler.go:128 Health Check state change {“component_kind”: “extension”, “component_type”: “health_check”, “component_name”: “health_check”, “status”: “ready”}
2021-03-21T16:11:11.009Z INFO service/service.go:267 Everything is ready. Begin running and processing data.
2021-03-21T16:11:11.009Z INFO k8sclusterreceiver@v0.21.0/receiver.go:59 Starting shared informers and wait for initial cache sync. {“component_kind”: “receiver”, “component_type”: “k8s_cluster”, “component_name”: “k8s_cluster”}
2021-03-21T16:11:11.281Z INFO k8sclusterreceiver@v0.21.0/receiver.go:75 Completed syncing shared informer caches. {“component_kind”: “receiver”, “component_type”: “k8s_cluster”, “component_name”: “k8s_cluster”}
Deleting a failed installation
If you make an error installing the OpenTelemetry Collector you can start over by deleting the installation using:
helm delete splunk-otel-collector
2. Validate metrics in the UI
In the Splunk UI, click the » bottom left and click on Infrastructure.
Under Containers click on Kubernetes to open the Kubernetes Navigator Cluster Map to ensure metrics are being sent in.
Validate that your cluster is discovered and reported by finding your cluster (in the workshop you will see many other clusters). To find your cluster name run the following command and copy the output to your clipboard:
echo$INSTANCE-k3s-cluster
Then in the UI, click on the “Cluster: - " menu just below the Splunk Logo, paste the Cluster name you just copied into the search box, click the box to select your cluster, and finally click off the menu into white space to apply the filter.
To examine the health of your node, hover over the pale blue background of your cluster, then click on the blue magnifying glass that appears in the top left-hand corner.
This will drill down to the node level. Next, open the Metrics sidebar by clicking on the sidebar button.
Once it is open, you can use the slider on the side to explore the various charts relevant to your cluster/node: CPU, Memory, Network, Events etc.
Subsections of 2. Get Data In
Deploying NGINX in K3s
Deploy a NGINX ReplicaSet into your K3s cluster and confirm the discovery of your NGINX deployment.
Run a load test to create metrics and confirm them streaming into Splunk Observability Cloud!
1. Start your NGINX
Verify the number of pods running in the Splunk UI by selecting the WORKLOADS tab. This should give you an overview of the workloads on your cluster.
Note the single agent container running per node among the default Kubernetes pods. This single container will monitor all the pods and services being deployed on this node!
Now switch back to the default cluster node view by selecting the MAP tab and selecting your cluster again.
In your AWS/EC2 or Multipass shell session change into the nginx directory:
cd ~/workshop/k3s/nginx
2. Create NGINX deployment
Create the NGINX ConfigMap1 using the nginx.conf file:
deployment.apps/nginx created
service/nginx created
Next, we will deploy Locust2 which is an open-source tool used for creating a load test against NGINX:
kubectl create -f locust-deployment.yaml
deployment.apps/nginx-loadgenerator created
service/nginx-loadgenerator created
Validate the deployment has been successful and that the Locust and NGINX pods are running.
If you have the Splunk UI open you should see new Pods being started and containers being deployed.
It should only take around 20 seconds for the pods to transition into a Running state. In the Splunk UI you will have a cluster that looks like the screenshot below:
If you select the WORKLOADS tab again you will now see that there is a new ReplicaSet and a deployment added for NGINX:
Locust, an open-source load generator, is available on port 8083 of the EC2 instance’s IP address. Open a new tab in your web browser and go to http://{==EC2-IP==}:8083/, you will then be able to see the Locust running.
Set the Spawn rate to 2 and click Start Swarming.
This will start a gentle continuous load on the application.
As you can see from the above screenshot, most of the calls will report a fail, this is expected, as we have not yet deployed the application behind it, however, NGINX is reporting on your attempts and you should be able to see those metrics.
Validate you are seeing those metrics in the UI by selecting Dashboards → Built-in Dashboard Groups → NGINX → NGINX Servers. Using the Overrides filter on k8s.cluster.name:, find the name of your cluster as returned by echo $INSTANCE-k3s-cluster in the terminal.
A ConfigMap is an API object used to store non-confidential data in key-value pairs. Pods can consume ConfigMaps as environment variables, command-line arguments, or configuration files in a volume. A ConfigMap allows you to decouple environment-specific configuration from your container images so that your applications are easily portable. ↩︎
Dashboards are groupings of charts and visualizations of metrics. Well-designed dashboards can provide useful and actionable insight into your system at a glance. Dashboards can be complex or contain just a few charts that drill down only into the data you want to see.
During this module, we are going to create the following charts and dashboard and connect them to your Team page.
2. Your Teams’ Page
Click on the from the navbar. As you have already been assigned to a team, you will land on the team dashboard. We use the Example Team as an example here. The one in your workshop will be different!
This page shows the total number of team members, how many active alerts for your team and all dashboards that are assigned to your team. Right now there are no dashboards assigned but as stated before, we will add the new dashboard that you will create to your Teams page later.
3. Sample Charts
To continue, click on All Dashboards in the top right corner of the screen. This brings you to the view that shows all the available dashboards, including the pre-built ones.
If you are already receiving metrics from a Cloud API integration or another service through the Splunk Agent you will see relevant dashboards for these services.
4. Inspecting the Sample Data
Among the dashboards, you will see a Dashboard group called Sample Data. Expand the Sample Data dashboard group by clicking on it, and then click on the Sample Charts dashboard.
In the Sample Charts dashboard, you can see a selection of charts that show a sample of the various styles, colors and formats you can apply to your charts in the dashboards.
Have a look through all the dashboards in this dashboard group (PART 1, PART 2, PART 3 and INTRO TO SPLUNK OBSERVABILITY CLOUD)
Subsections of 3. Dashboards
Editing charts
1. Editing a chart
Select the SAMPLE CHARTS dashboard and then click on the three dots ... on the Latency histogram chart, then on Open (or you can click on the name of the chart which here is Latency histogram).
You will see the plot options, current plot and signal (metric) for the Latency histogram chart in the chart editor UI.
In the Plot Editor tab under Signal you see the metric demo.trans.latency we are currently plotting.
You will see a number of Line plots. The number 18 ts indicates that we are plotting 18 metric time series in the chart.
Click on the different chart type icons to explore each of the visualizations. Notice their name while you swipe over them. For example, click on the Heat Map icon:
See how the chart changes to a heat map.
Note
You can use different charts to visualize your metrics - you choose which chart type fits best for the visualization you want to have.
Click on the Line chart type and you will see the line plot.
2. Changing the time window
You can also increase the time window of the chart by changing the time to Past 15 minutes by selecting from the Time dropdown.
3. Viewing the Data Table
Click on the Data Table tab.
You now see 18 rows, each representing a metric time series with a number of columns. These columns represent the dimensions of the metric. The dimensions for demo.trans.latency are:
demo_datacenter
demo_customer
demo_host
In the demo_datacenter column you see that there are two data centers, Paris and Tokyo, for which we are getting metrics.
If you move your cursor over the lines in the chart horizontally you will see the data table update accordingly. If you click on one of the lines in the chart you will see a pinned value appear in the data table.
Now click on Plot editor again to close the Data Table and let’s save this chart into a dashboard for later use!
Saving charts
1. Saving a chart
To start saving your chart, lets give it a name and description. Click the name of the chart Copy of Latency Histogram and rename it to “Active Latency”.
To change the description click on Spread of latency values across time. and change this to Overview of latency values in real-time.
Click the Save As button. Make sure your chart has a name, it will use the name Active Latency the you defined in the previous step, but you can edit it here if needed.
Press the Ok
button to continue.
2. Creating a dashboard
In the Choose dashboard dialog, we need to create a new dashboard, click on the New Dashboard
button.
You will now see the New Dashboard Dialog. In here you can give you dashboard a name and description, and set Read and Write Permissions.
Please use your own name in the following format to give your dashboard a name e.g. YOUR_NAME-Dashboard.
Please replace YOUR_NAME with your own name, change the dashboard permissions to Restricted Read and Write access, and verify your user can read/write.
You should see you own login information displayed, meaning you are now the only one who can edit this dashboard. Of course you have the option to add other users or teams from the drop box below that may edit your dashboard and charts, but for now make sure you change it back to Everyone can Read or Write to remove any restrictions and press the Save
Button to continue.
Your new dashboard is now available and selected so you can save your chart in your new dashboard.
Make sure you have your dashboard selected and press the Ok button.
You will now be taken to your dashboard like below. You can see at the top left that your YOUR_NAME-DASHBOARD is part of a Dashboard Group YOUR_NAME-Dashboard. You can add other dashboards to this dashboard group.
3. Add to Team page
It is common practice to link dashboards that are relevant to a Team to a teams page. So let’s add your dashboard to the team page for easy access later. Use the from the navbar again.
This will bring you to your teams dashboard, We use the team Example Team as an example here, the workshop one will be different.
Press the +Add Dashboard Group button to add you dashboard to the team page.
This will bring you to the Select a dashboard group to link to this team dialog.
Type your name (that you used above) in the search box to find your Dashboard. Select it so its highlighted and click the Ok button to add your dashboard.
Your dashboard group will appear as part of the team page. Please note during the course of the workshop many more will appear here.
Now click on the link for your Dashboard to add more charts!
3.3 Using Filters & Formulas
1 Creating a new chart
Let’s now create a new chart and save it in our dashboard!
Select the plus icon (top right of the UI) and from the drop down, choose the option Chart.
Or click on the + New Chart Button to create a new chart.
You will now see a chart template like the following.
Let’s enter a metric to plot. We are still going to use the metric demo.trans.latency.
In the Plot Editor tab under Signal enter demo.trans.latency.
You should now have a familiar line chart. Please switch the time to 15 mins.
2. Filtering and Analytics
Let’s now select the Paris datacenter to do some analytics - for that we will use a filter.
Let’s go back to the Plot Editor tab and click on Add Filter
, wait until it automatically populates, choose demo_datacenter, and then Paris.
In the F(x) column, add the analytic function Percentile:Aggregation, and leave the value to 95 (click outside to confirm).
For info on the Percentile function and the other functions see Chart Analytics.
3. Using Timeshift analytical function
Let’s now compare with older metrics. Click on ... and then on Clone in the dropdown to clone Signal A.
You will see a new row identical to A, called B, both visible and plotted.
For Signal B, in the F(x) column add the analytic function Timeshift and enter 1w (or 7d for 7 days), and click outside to confirm.
Click on the cog on the far right, and choose a Plot Color e.g. pink, to change color for the plot of B.
Click on Close.
We now see plots for Signal A (the past 15 minutes) as a blue plot, and the plots from a week ago in pink.
In order to make this clearer we can click on the Area chart icon to change the visualization.
We now can see when last weeks latency was higher!
Next, click into the field next to Time on the Override bar and choose Past Hour from the dropdown.
4. Using Formulas
Let’s now plot the difference of all metric values for a day with 7 days in between.
Click on Enter Formula
then enter A-B (A minus B) and hide (deselect) all Signals using the eye, except C.
We now see only the difference of all metric values of A and B being plotted. We see that we have some negative values on the plot because a metric value of B has some times larger value than the metric value of A at that time.
Lets look at the Signalflow that drives our Charts and Detectors!
3.4 SignalFlow
1. Introduction
Let’s take a look at SignalFlow - the analytics language of Observability Cloud that can be used to setup monitoring as code.
The heart of Splunk Infrastructure Monitoring is the SignalFlow analytics engine that runs computations written in a Python-like language. SignalFlow programs accept streaming input and produce output in real time. SignalFlow provides built-in analytical functions that take metric time series (MTS) as input, perform computations, and output a resulting MTS.
Comparisons with historical norms, e.g. on a week-over-week basis
Population overviews using a distributed percentile chart
Detecting if the rate of change (or other metric expressed as a ratio, such as a service level objective) has exceeded a critical threshold
Finding correlated dimensions, e.g. to determine which service is most correlated with alerts for low disk space
Infrastructure Monitoring creates these computations in the Chart Builder user interface, which lets you specify the input MTS to use and the analytical functions you want to apply to them. You can also run SignalFlow programs directly by using the SignalFlow API.
SignalFlow includes a large library of built-in analytical functions that take a metric time series as an input, performs computations on its datapoints, and outputs time series that are the result of the computation.
You will see the SignalFlow code that composes the chart we were working on. You can now edit the SignalFlow directly within the UI. Our documentation has the full list of SignalFlow functions and methods.
Also, you can copy the SignalFlow and use it when interacting with the API or with Terraform to enable Monitoring as Code.
Click on View Builder to go back to the Chart Builder UI.
Let’s save this new chart to our Dashboard!
Adding charts to dashboards
1. Save to existing dashboard
Check that you have YOUR_NAME-Dashboard: YOUR_NAME-Dashboard in the top left corner. This means you chart will be saved in this Dashboard.
Name the Chart Latency History and add a Chart Description if you wish.
Click on Save And Close. This returns you to your dashboard that now has two charts!
Now let’s quickly add another Chart based on the previous one.
2. Copy and Paste a chart
Click on the three dots ... on the Latency History chart in your dashboard and then on Copy.
You see the chart being copied, and you should now have a red circle with a white 1 next to the + on the top left of the page.
Click on the plus icon the top of the page, and then in the menu on Paste Charts (There should also be a red dot with a 1 visible at the end of the line).
This will place a copy of the previous chart in your dashboard.
3. Edit the pasted chart
Click on the three dots ... on one of the Latency History charts in your dashboard and then on Open (or you can click on the name of the chart which here is Latency History).
This will bring you to the editor environment again.
First set the time for the chart to -1 hour in the Time box at the top right of the chart. Then to make this a different chart, click on the eye icon in front of signal “A” to make it visible again, and then hide signal “C” via the eye icon and change the name for Latency history to Latency vs Load.
Click on the Add Metric Or Event button. This will bring up the box for a new signal. Type and select demo.trans.count for Signal D.
This will add a new Signal D to your chart, It shows the number of active requests. Add the filter for the demo_datacenter:Paris, then change the Rollup type by clicking on the Configure Plot button and changing the roll-up from Auto (Delta) to Rate/sec. Change the name from demo.trans.count to Latency vs Load.
Finally press the Save And Close button. This returns you to your dashboard that now has three different charts!
Let’s add an “instruction” note and arrange the charts!
Adding Notes and Dashboard Layout
1. Adding Notes
Often on dashboards it makes sense to place a short “instruction” pane that helps users of a dashboard. Lets add one now by clicking on the New Text Note
Button.
This will open the notes editor.
To allow you to add more then just text to you notes, Splunk is allowing you to use Markdown in these notes/panes.
Markdown is a lightweight markup language for creating formatted text using plain-text often used in Webpages.
This includes (but not limited to):
Headers. (in various sizes)
Emphasis styles.
Lists and Tables.
Links. These can be external webpages (for documentation for example) or directly to other Splunk IM Dashboards
Below is an example of above Markdown options you can use in your note.
# h1 Big headings
###### h6 To small headings
##### Emphasis
**This is bold text**, *This is italic text* , ~~Strikethrough~~##### Lists
Unordered
+ Create a list by starting a line with `+`, `-`, or `*`- Sub-lists are made by indenting 2 spaces:
- Marker character change forces new list start:
* Ac tristique libero volutpat at
+ Facilisis in pretium nisl aliquet
* Very easy!
Ordered
1. Lorem ipsum dolor sit amet
2. Consectetur adipiscing elit
3. Integer molestie lorem at massa
##### Tables
| Option | Description |
| ------ | ----------- |
| chart | path to data files to supply the data that will be passed into templates. |
| engine | engine to be used for processing templates. Handlebars is the default. |
| ext | extension to be used for dest files. |
#### Links
[link to webpage](https://www.splunk.com)
[link to dashboard with title](https://app.eu0.signalfx.com/#/dashboard/EaJHrbPAEAA?groupId=EaJHgrsAIAA&configId=EaJHsHzAEAA "Link to the Sample chart Dashboard!")
Copy the above by using the copy button and paste it in the Edit box.
the preview will show you how it will look.
2. Saving our chart
Give the Note chart a name, in our example we used Example text chart, then press the Save And Close Button.
This will bring you back to you Dashboard, that now includes the note.
3. Ordering & sizing of charts
If you do not like the default order and sizes of your charts you can simply use window dragging technique to move and size them to the desired location.
Grab the top border of a chart and you should see the mouse pointer change to a drag icon (see picture below).
Now drag the Latency vs Load chart to sit between the Latency History Chart and the Example text chart.
You can also resize windows by dragging from the left, right and bottom edges.
As a last exercise reduce the width of the note chart to about a third of the other charts. The chart will automatically snap to one of the sizes it supports. Widen the 3 other charts to about a third of the Dashboard. Drag the notes to the right of the others and resize it to match it to the 3 others. Set the Time to -1h and you should have the following dashboard!
On to Detectors!
Working with Detectors
10 minutes
Create a Detector from one of your charts
Setting Alert conditions
Running a pre-flight check
Working with muting rules
1. Introduction
Splunk Observability Cloud uses detectors, events, alerts, and notifications to keep you informed when certain criteria are met. For example, you might want a message sent to a Slack channel or an email address for the Ops team when CPU Utilization has reached 95%, or when the number of concurrent users is approaching a limit that might require you to spin up an additional AWS instance.
These conditions are expressed as one or more rules that trigger an alert when the conditions in the rules are met. Individual rules in a detector are labeled according to criticality: Info, Warning, Minor, Major, and Critical.
2. Creating a Detector
In Dashboards click on your Custom Dashboard Group (that you created in the previous module) and then click on the dashboard name.
We are now going to create a new detector from a chart on this dashboard. Click on the bell icon on the Latency vs Load chart, and then click New Detector From Chart.
In the text field next to Detector Name, ADD YOUR INITIALS before the proposed detector name.
Naming the detector
It’s important that you add your initials in front of the proposed detector name.
It should be something like this: XYZ’s Latency Chart Detector.
Click on Create Alert Rule
In the Detector window, inside Alert signal, the Signal we will alert on is marked with a (blue) bell in the Alert on column. The bell indicates which Signal is being used to generate the alert.
Click on Proceed to Alert Condition
3. Setting Alert condition
In Alert condition, click on Static Threshold and then on Proceed to Alert Settings
In Alert Settings, enter the value 290 in the Threshold field. In the same window change Time on top right to past day (-1d).
4. Alert pre-flight check
A pre-flight check will take place after 5 seconds. See the Estimated alert count. Based on the current alert settings, the amount of alerts we would have received in 1 day would have been 3.
About pre-flight checks
Once you set an alert condition, the UI estimates how many alerts you might get based on the current settings, and in the timeframe set on the upper right corner - in this case, the past day.
Immediately, the platform will start analyzing the signals with the current settings, and perform something we call a Pre-flight Check. This enables you to test the alert conditions using the historical data in the platform, to ensure the settings are logical and will not inadvertently generate an alert storm, removing the guesswork from configuring alerts in a simple but very powerful way, only available using the Splunk Observability Cloud.
Click on Add Recipient and then on your email address displayed as the first option.
Notification Services
That’s the same as entering that email address OR you can enter another email address by clicking on E-mail….
This is just one example of the many Notification Services the platform has available. You can check this out by going to the Integrations tab of the top menu, and see Notification Services.
6. Alert Activation
Click on Proceed to Alert Activation
In Activate… click on Activate Alert Rule
If you want to get alerts quicker you edit the rule and lower the value from 290 to say 280.
If you change the Time to -1h you can see how many alerts you might get with the threshold you have chosen based on the metrics from the last 1 hour.
Click on the in the navbar and then click on Detectors. You can optionally filter for your initials. You will see you detector listed here. If you don’t then please refresh your browser.
Congratulations! You have created your first detector and activated it!
Subsections of 4. Detectors
Working with Muting Rules
Learn how to configure Muting Rules
Learn how to resume notifications
1. Configuring Muting Rules
There will be times when you might want to mute certain notifications. For example, if you want to schedule downtime for maintenance on a server or set of servers, or if you are testing new code or settings etc. For that you can use muting rules in Splunk Observability Cloud. Let’s create one!
Click on Alerts & Detectors in the sidebar and then click Detectors to see the list of active detectors.
If you created a detector in Creating a Detector you can click on the three dots ... on the far right for that detector; if not, do that for another detector.
From the drop-down click on Create Muting Rule…
In the Muting Rule window check Mute Indefinitely and enter a reason.
Important
This will mute the notifications permanently until you come back here and un-check this box or resume notifications for this detector.
Click Next and in the new modal window confirm the muting rule setup.
Click on Mute Indefinitely to confirm.
You won’t be receiving any email notifications from your detector until you resume notifications again. Let’s now see how to do that!
2. Resuming notifications
To Resume notifications, click on Muting Rules, you will see the name of the detector you muted notifications for under Detector heading.
Click on the thee dots ... on the far right, and click on Resume Notifications.
Click on Resume to confirm and resume notifications for this detector.
Congratulations! You have now resumed your alert notifications!
Monitoring as Code
10 minutes
Use Terraform1 to manage Observability Cloud Dashboards and Detectors
Run Terraform to create detectors and dashboards from code using the Splunk Terraform Provider.
See how Terraform can also delete detectors and dashboards.
1. Initial setup
Monitoring as code adopts the same approach as infrastructure as code. You can manage monitoring the same way you do applications, servers, or other infrastructure components.
You can use monitoring as code to build out your visualizations, what to monitor, and when to alert, among other things. This means your monitoring setup, processes, and rules can be versioned, shared, and reused.
Full documentation for the Splunk Terraform Provider is available here.
Remaining in your AWS/EC2 instance, change into the o11y-cloud-jumpstart directory
cd ~/observability-content-contrib/integration-examples/terraform-jumpstart
Initialize Terraform and upgrade to the latest version of the Splunk Terraform Provider.
Note: Upgrading the SignalFx Terraform Provider
You will need to run the command below each time a new version of the Splunk Terraform Provider is released. You can track the releases on GitHub.
terraform init -upgrade
Upgrading modules...
- aws in modules/aws
- azure in modules/azure
- docker in modules/docker
- gcp in modules/gcp
- host in modules/host
- kafka in modules/kafka
- kubernetes in modules/kubernetes
- parent_child_dashboard in modules/dashboards/parent
- pivotal in modules/pivotal
- rum_and_synthetics_dashboard in modules/dashboards/rum_and_synthetics
- usage_dashboard in modules/dashboards/usage
Initializing the backend...
Initializing provider plugins...
- Finding latest version of splunk-terraform/signalfx...
- Installing splunk-terraform/signalfx v6.20.0...
- Installed splunk-terraform/signalfx v6.20.0 (self-signed, key ID CE97B6074989F138)
Partner and community providers are signed by their developers.
If you'd like to know more about provider signing, you can read about it here:
https://www.terraform.io/docs/cli/plugins/signing.html
Terraform has created a lock file .terraform.lock.hcl to record the provider
selections it made above. Include this file in your version control repository
so that Terraform can guarantee to make the same selections by default when
you run "terraform init" in the future.
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
2. Create execution plan
The terraform plan command creates an execution plan. By default, creating a plan consists of:
Reading the current state of any already-existing remote objects to make sure that the Terraform state is up-to-date.
Comparing the current configuration to the prior state and noting any differences.
Proposing a set of change actions that should, if applied, make the remote objects match the configuration.
The plan command alone will not actually carry out the proposed changes, and so you can use this command to check whether the proposed changes match what you expected before you apply the changes
terraform plan -var="api_token=$API_TOKEN" -var="realm=$REALM" -var="o11y_prefix=[$INSTANCE]"
Plan: 146 to add, 0 to change, 0 to destroy.
If the plan executes successfully, we can go ahead and apply:
3. Apply execution plan
The terraform apply command executes the actions proposed in the Terraform plan above.
The most straightforward way to use terraform apply is to run it without any arguments at all, in which case it will automatically create a new execution plan (as if you had run terraform plan) and then prompt you to provide the API Token, Realm (the prefix defaults to Splunk) and approve the plan, before taking the indicated actions.
Due to this being a workshop it is required that the prefix is to be unique so you need to run the terraform apply below.
Once the apply has been completed, validate that the detectors were created, under the Alerts & Detectors and click on the Detectors tab. They will be prefixed by the instance name. To check the prefix value run:
echo$INSTANCE
You will see a list of the new detectors and you can search for the prefix that was output from above.
3. Destroy all your hard work
The terraform destroy command is a convenient way to destroy all remote objects managed by your Terraform configuration.
While you will typically not want to destroy long-lived objects in a production environment, Terraform is sometimes used to manage ephemeral infrastructure for development purposes, in which case you can use terraform destroy to conveniently clean up all of those temporary objects once you are finished with your work.
Now go and destroy all the Detectors and Dashboards that were previously applied!
Validate all the detectors have been removed by navigating to Alerts → Detectors
Terraform is a tool for building, changing, and versioning infrastructure safely and efficiently. Terraform can manage existing and popular service providers as well as custom in-house solutions. ↩︎
A provider is responsible for understanding API interactions and exposing resources. Providers generally are an IaaS (e.g. Alibaba Cloud, AWS, GCP, Microsoft Azure, OpenStack), PaaS (e.g. Heroku), or SaaS services (e.g. Splunk, Terraform Cloud, DNSimple, Cloudflare). ↩︎
Service Bureau
10 minutes
How to keep track of the usage of Observability Cloud in your organization
Learn how to keep track of spend by exploring the Subscription Usage interface
Creating Teams
Adding notification rules to Teams
Controlling usage
1. Understanding engagement
To fully understand Observability Cloud engagement inside your organization, click on the » bottom left and select the Settings → Organization Overview, this will provide you with the following dashboards that show you how your Observability Cloud organization is being used:
You will see various dashboards such as Throttling, System Limits, Entitlements & Engagement. The workshop organization you’re using now may have less data to work with as this is cleared down after each workshop.
Take a minute to explore the various dashboards and charts in the Organization Overview of this workshop instance.
2. Subscription Usage
If you want to see what your usage is against your subscription you can select Subscription Usage.
This screen may take a few seconds to load whilst it calculates and pulls in the usage.
3. Understanding usage
You will see a screen similar to the one below that will give you an overview of the current usage, the average usage and your entitlement per category: Hosts, Containers, Custom Metrics and High Resolution Metrics.
The top chart shows you the current subscription levels per category (shown by the red arrows at the top in the screenshot below).
Also, your current usage of the four categories is displayed (shown in the red lines at the bottom of the chart).
In this example, you can see that there are 25 Hosts, 0 Containers, 100 Custom Metrics and 0 High Resolution Metrics.
In the bottom chart, you can see the usage per category for the current period (shown in the drop-down box on the top right of the chart).
The blue line marked Average Usage indicates what Observability Cloud will use to calculate your average usage for the current Subscription Usage Period.
Info
As you can see from the screenshot, Observability Cloud does not use High Watermark or P95% for cost calculation but the actual average hourly usage, allowing you to do performance testing or Blue/Green style deployments etc. without the risk of overage charges.
To get a feel for the options you can change the metric displayed by selecting the different options from the Usage Metric drop-down on the left, or change the Subscription Usage Period with the drop-down on the right.
Please take a minute to explore the different time periods & categories and their views.
Finally, the pane on the right shows you information about your Subscription.
Subsections of 6. Service Bureau
Teams
Introduction to Teams
Create a Team and add members to the Team
1. Introduction to Teams
To make sure that users see the dashboards and alerts that are relevant to them when using Observability Cloud, most organizations will use Observability Cloud’s Teams feature to assign a member to one or more Teams.
Ideally, this matches work-related roles, for example, members of a Dev-Ops or Product Management group would be assigned to the corresponding Teams in Observability Cloud.
When a user logs into Observability Cloud, they can choose which Team Dashboard will be their home page and they will typically select the page for their primary role.
In the example below, the user is a member of the Development, Operations and Product Management Teams, and is currently viewing the Dashboard for the Operations Team.
This Dashboard has specific Dashboard Groups for Usage, SaaS and APM Business Workflows assigned but any Dashboard Group can be linked to a Teams Dashboard.
They can use the menu along the top left to quickly navigate between their allocated teams, or they can use the ALL TEAMS dropdown on the right to select specific Team Dashboards, as well as quickly access ALL Dashboards** using the adjacent link.
Alerts can be linked to specific Teams so the Team can monitor only the Alerts they are interested in, and in the above example, they currently have 1 active Critical Alert.
The Description for the Team Dashboard can be customized and can include links to team-specific resources (using Markdown).
2. Creating a new Team
To work with Splunk’s Team UI click on the hamburger icon top left and select the Organizations Settings → Teams.
When the Team UI is selected you will be presented with the list of current Teams.
To add a new Team click on the Create New Team button. This will present you with the Create New Team dialog.
Create your own team by naming it [YOUR-INITIALS]-Team and add yourself by searching for your name and selecting the Add link next to your name. This should result in a dialog similar to the one below:
You can remove selected users by pressing Remove or the small x.
Make sure you have your group created with your initials and with yourself added as a member, then click Done
This will bring you back to the Teams list that will now show your Team and the ones created by others.
Note
The Teams(s) you are a member of have a grey Member icon in front of it.
If no members are assigned to your Team, you should see a blue Add Members link instead of the member count, clicking on that link will get you to the Edit Team dialog where you can add yourself.
This is the same dialog you get when pressing the 3 dots … at the end of the line with your Team and selecting Edit Team
The … menu gives you the option to Edit, Join, Leave or Delete a Team (leave and join will depend on if you are currently a member).
3. Adding Notification Rules
You can set up specific Notification rules per team, by clicking on the Notification Policy tab, this will open the notification edit menu.
By default, the system offers you the ability to set up a general notification rule for your team.
Note
The Email all team members option means all members of this Team will receive an email with the Alert information, regardless of the alert type.
3.1 Adding recipients
You can add other recipients, by clicking Add Recipient. These recipients do not need to be Observability Cloud users.
However, if you click on the link Configure separate notification tiers for different severity alerts you can configure every alert level independently.
Different alert rules for the different alert levels can be configured, as shown in the above image.
Critical and Major are using Splunk's On-Call Incident Management solution. For the Minor alerts, we send it to the Teams Slack channel and for Warning and Info we send an email.
3.2 Notification Integrations
In addition to sending alert notifications via email, you can configure Observability Cloud to send alert notifications to the services shown below.
Take a moment to create some notification rules for your Team.
Controlling Usage
Discover how you can restrict usage by creating separate Access Tokens and setting limits.
1. Access Tokens
If you wish to control the consumption of Hosts, Containers, Custom Metrics and High Resolution Metrics, you can create multiple Access Tokens and allocate them to different parts of your organization.
In the UI click on the » bottom left and select the Settings → Access Tokens under General Settings.
The Access Tokens Interface provides an overview of your allotments in the form of a list of Access Tokens that have been generated. Every Organization will have a Default token generated when they are first set up, but there will typically be multiple Tokens configured.
Each Token is unique and can be assigned limits for the number of Hosts, Containers, Custom Metrics and High Resolution Metrics it can consume.
The Usage Status Column quickly shows if a token is above or below its assigned limits.
2. Creating a new token
Let create a new token by clicking on the New Token button. This will provide you with the Name Your Access Token dialog.
Enter the new name of the new Token by using your Initials e.g. RWC-Token and make sure to tick both Ingest Token and API Token checkboxes!
After you press OK you will be taken back to the Access Token UI. Here your new token should be present, among the ones created by others.
If you have made an error in your naming, want to disable/enable a token or set a Token limit, click on the ellipsis (…) menu button behind a token limit to open the manage token menu.
If you made a typo you can use the Rename Token option to correct the name of your token.
3. Disabling a token
If you need to make sure a token cannot be used to send Metrics in you can disable a token.
Click on Disable to disable the token, this means the token cannot be used for sending in data to Splunk Observability Cloud.
The line with your token should have become greyed out to indicate that it has been disabled as you can see in the screenshot below.
Go ahead and click on the ellipsis (…) menu button to Disable and Enable your token.
4. Manage token usage limits
Now, let’s start limiting usage by clicking on Manage Token Limit in the 3 … menu.
This will show the Manage Token Limit Dialog:
In this dialog, you can set the limits per category.
Please go ahead and specify the limits as follows for each usage metric:
Limit
Value
Host Limit
5
Container Limit
15
Custom Metric Limit
20
High Resolution Metric Limit
0
For our lab use your email address, and double check that you have the correct numbers in your dialog box as shown in the table above.
Token limits are used to trigger an alert that notifies one or more recipients when the usage has been above 90% of the limit for 5 minutes.
To specify the recipients, click Add Recipient, then select the recipient or notification method you want to use (specifying recipients is optional but highly recommended).
The severity of token alerts is always Critical.
Click on Update to save your Access Tokens limits and The Alert Settings.
Note: Going above token limit
When a token is at or above its limit in a usage category, new metrics for that usage category will not be stored and processed by Observability Cloud. This will make sure there will be no unexpected cost due to a team sending in data without restriction.
Note: Advanced alerting
If you wish to get alerts before you hit 90%, you can create additional detectors using whatever values you want. These detectors could target the Teams consuming the specific Access Tokens so they can take action before the admins need to get involved.
In your company you would distribute these new Access Tokens to various teams, controlling how much information/data they can send to Observability Cloud.
This will allow you to fine-tune the way you consume your Observability Cloud allotment and prevent overages from happening.
Congratulations! You have now completed the Service Bureau module.
NodeJS Zero-Config Workshop
30 minutesAuthor
Robert Castley
The goal is to walk through the basic steps to configure the following components of the Splunk Observability Cloud platform:
Splunk Infrastructure Monitoring (IM)
Splunk Zero Configuration Auto Instrumentation for NodeJS (APM)
AlwaysOn Profiling
Splunk Log Observer (LO)
We will deploy the OpenTelemetry Astronomy Shop application in Kubernetes, which contains two NodeJS services (Frontend & Payment Service). Once the application and the OpenTelemetry Connector are up and running, we will start seeing metrics, traces and logs via the Zero Configuration Auto Instrumentation for NodeJS that will be used by the Splunk Observability Cloud platform to provide insights into the application.
Prerequisites
Outbound SSH access to port 2222.
Outbound HTTP access to port 8083.
Familiarity with the bash shell and vi/vim editor.
To not conflict with other workshops, we will deploy the OpenTelemetry Demo in a separate namespace called otel-demo. To create the namespace, run the following command:
kubectl create namespace otel-demo
2. Deploy the OpenTelemetry Demo
Next, change to the directory containing the OpenTelemetry Demo application:
cd ~/workshop/apm
Deploy the OpenTelemetry Demo application:
kubectl apply -n otel-demo -f otel-demo.yaml
serviceaccount/opentelemetry-demo created
service/opentelemetry-demo-adservice created
service/opentelemetry-demo-cartservice created
service/opentelemetry-demo-checkoutservice created
service/opentelemetry-demo-currencyservice created
service/opentelemetry-demo-emailservice created
service/opentelemetry-demo-featureflagservice created
service/opentelemetry-demo-ffspostgres created
service/opentelemetry-demo-frontend created
service/opentelemetry-demo-kafka created
service/opentelemetry-demo-loadgenerator created
service/opentelemetry-demo-paymentservice created
service/opentelemetry-demo-productcatalogservice created
service/opentelemetry-demo-quoteservice created
service/opentelemetry-demo-recommendationservice created
service/opentelemetry-demo-redis created
service/opentelemetry-demo-shippingservice created
deployment.apps/opentelemetry-demo-accountingservice created
deployment.apps/opentelemetry-demo-adservice created
deployment.apps/opentelemetry-demo-cartservice created
deployment.apps/opentelemetry-demo-checkoutservice created
deployment.apps/opentelemetry-demo-currencyservice created
deployment.apps/opentelemetry-demo-emailservice created
deployment.apps/opentelemetry-demo-featureflagservice created
deployment.apps/opentelemetry-demo-ffspostgres created
deployment.apps/opentelemetry-demo-frauddetectionservice created
deployment.apps/opentelemetry-demo-frontend created
deployment.apps/opentelemetry-demo-kafka created
deployment.apps/opentelemetry-demo-loadgenerator created
deployment.apps/opentelemetry-demo-paymentservice created
deployment.apps/opentelemetry-demo-productcatalogservice created
deployment.apps/opentelemetry-demo-quoteservice created
deployment.apps/opentelemetry-demo-recommendationservice created
deployment.apps/opentelemetry-demo-redis created
deployment.apps/opentelemetry-demo-shippingservice created
Once the application is deployed, we need to wait for the pods to be in a Running state. To check the status of the pods, run the following command:
Obtain the public IP address of the instance you are running on. You can do this by running the following command:
curl ifconfig.me
Once the port-forward is running, you can access the application by opening a browser and navigating to http://<public IP address>:8083. You should see the following:
Once you have confirmed the application is running, you can close the port-forward by pressing ctrl + c.
Next, we will deploy the OpenTelemetry Collector.
Installing the OpenTelemetry Collector
1. Introduction
Delete any existing OpenTelemetry Collectors
If you have completed any other Observability workshops, please ensure you delete the collector running in Kubernetes before continuing. This can be done by running the following command:
helm delete splunk-otel-collector
2. Confirm environment variables
To ensure your instance is configured correctly, we need to confirm that the required environment variables for this workshop are set correctly. In your terminal run the following command:
env
In the output check the following environment variables are present and have values set:
ACCESS_TOKEN
REALM
RUM_TOKEN
HEC_TOKEN
HEC_URL
For this workshop, all of the above are required. If any are missing, please contact your instructor.
3. Install the OpenTelemetry Collector
We can then go ahead and install the Collector. Some additional parameters are passed to the helm install command, they are:
--set="operator.enabled=true" - Enabled the Splunk OpenTelemetry Collector Operator for Kubernetes.
--set="certmanager.enabled=true" - The cert-manager adds certificates and certificate issuers as resource types in Kubernetes clusters and simplifies the process of obtaining, renewing and using those certificates.
--set="splunkObservability.profilingEnabled=true" - Enables CPU/Memory profiling for supported languages.
Once the installation is completed, you can navigate to the Kubernetes Navigator to see the data from your host.
Click on Add filters select k8s.cluster.name and select the cluster of your workshop instance.
You can determine your instance name from the command prompt in your terminal session:
echo$INSTANCE
Once you see data flowing for your host, we are then ready to get started with the APM component.
Zero Configuration - Frontend Service
1. Patching the Frontend service
First, confirm that you can see your environment in APM. There should be a service called loadgenerator displayed in the Service map.
Next, we will patch the frontend deployment with an annotation to inject the NodeJS auto instrumentation. This will allow us to see the frontend service in APM. Note, that at this point we have not edited any code.
This will cause the opentelemetry-demo-frontend pod to restart.
The annotation value default/splunk-otel-collector refers to the instrumentation configuration named splunk-otel-collector in the default namespace.
If the chart is not installed in the default namespace, modify the annotation value to be {chart_namespace}/splunk-otel-collector.
After a few minutes, you should see the frontend service in APM.
With the frontend service highlighted, click on the Traces tab to see the traces for the service. Select one of the traces and confirm that the trace contains metadata confirming that the Splunk Zero-Configuration Auto-Instrumentation for NodeJS is being used.
Zero Configuration - Payment Service
1. Patching the Payment Service
Finally, we will patch the paymentservice deployment with an annotation to inject the NodeJS auto instrumentation. This will allow us to see the paymentservice service in APM.
This will cause the opentelemetry-demo-paymentservice pod to restart and after a few minutes, you should see the paymentservice service in APM.
Code Profiling - Payment Service
1. AlwaysOn Profiling for the Payment Service
AlwaysOn Profiling is a feature of the Splunk Distribution of OpenTelemetry Collector that allows you to collect CPU and Memory profiling data for your services without having to modify your code. This is useful for troubleshooting performance issues in your services. Here are some of the benefits of AlwaysOn Profiling:
Perform continuous profiling of your applications. The profiler is always on once you activate it.
Collect code performance context and link it to trace data.
Explore memory usage and garbage collection of your application.
Analyze code bottlenecks that impact service performance.
Identify inefficiencies that increase the need for scaling up cloud resources.
With the opentelemetry-demo-paymentservice selected, click on AlwaysOn Profiling to view the code profiling data for the service.
Here you can see the CPU and Memory profiling data for the paymentservice service. You can also see the CPU and Memory profiling data for the frontend service by selecting the opentelemetry-demofrontend service from the Service dropdown.
Logs - Payment Service
1. Viewing the logs for the Payment Service
Navigate back to APM from the main menu and under Services click on opentelemetry-demo-paymentservice. This will open up the Service map for the paymentservice service only.
At the bottom of the page, click on the Logs(1) tab to view the logs for the paymentservice service.
Once in Log Observer select one of the log entries to view the metadata for the log entry.
Getting Data In (GDI) with OTel and UF
45 minutes
During this technical workshop, you will learn how to:
Efficiently deploy complex environments
Capture metrics from these environments to Splunk Observability Cloud
Auto-instrument a Python application
Enable OS logging to Splunk Enterprise via Universal Forwarder
To simplify the workshop modules, a pre-configured AWS EC2 instance is provided.
By the end of this technical workshop, you will have an approach to demonstrating metrics collection for complex environments and services.
Subsections of GDI (OTel & UF)
Getting Started with O11y GDI - Real Time Enrichment Workshop
Please note to begin the following lab, you must have completed the prework:
Obtain a Splunk Observability Cloud access key
Understand cli commands
Follow these steps if using O11y Workshop EC2 instances
cd /home/splunk
git clone https://github.com/leungsteve/realtime_enrichment.git
cd realtime_enrichment/workshop
python3 -m venv rtapp-workshop
source rtapp-workshop/bin/activate
Deploy Complex Environments and Capture Metrics
Objective: Learn how to efficiently deploy complex infrastructure components such as Kafka and MongoDB to demonstrate metrics collection with Splunk O11y IM integrations
Duration: 15 Minutes
Scenario
A prospect uses Kafka and MongoDB in their environment. Since there are integrations for these services, you’d like to demonstrate this to the prospect. What is a quick and efficient way to set up a live environment with these services and have metrics collected?
1. Where can I find helm charts?
Google “myservice helm chart”
https://artifacthub.io/ (Note: Look for charts from trusted organizations, with high star count and frequent updates)
Use information for each Helm chart and Splunk O11y Data Setup to generate values.yaml for capturing metrics from Kafka and MongoDB.
Note
values.yaml for the different services will be passed to the Splunk Helm Chart at installation time. These will configure the OTEL collector to capture metrics from these services.
Verify that out of the box dashboards for Kafka, MongoDB and Zookeeper are populated in the Infrastructure Monitor landing page. Drill down into each component to view granular details for each service.
Tip: You can use the filter k8s.cluster.name with your cluster name to find your instance.
Infrastructure Monitoring Landing page:
K8 Navigator:
MongoDB Dashboard:
Kafka Dashboard:
Code to Kubernetes - Python
Code to Kubernetes - Python
Objective: Understand activities to instrument a python application and run it on Kubernetes.
Verify the code
Containerize the app
Deploy the container in Kubernetes
Note: these steps do not involve Splunk
Duration: 15 Minutes
1. Verify the code - Review service
Navigate to the review directory
cd /home/splunk/realtime_enrichment/flask_apps/review/
fromflaskimportFlask,jsonifyimportrandomimportsubprocessreview=Flask(__name__)num_reviews=8635403num_reviews=100000reviews_file='/var/appdata/yelp_academic_dataset_review.json'@review.route('/')defhello_world():returnjsonify(message='Hello, you want to hit /get_review. We have '+str(num_reviews)+' reviews!')@review.route('/get_review')defget_review():random_review_int=str(random.randint(1,num_reviews))line_num=random_review_int+'q;d'command=["sed",line_num,reviews_file]# sed "7997242q;d" <file>random_review=subprocess.run(command,stdout=subprocess.PIPE,text=True)returnrandom_review.stdoutif__name__=="__main__":review.run(host='0.0.0.0',port=5000,debug=True)
Inspect requirements.txt
Flask==2.0.2
Create a virtual environment and Install the necessary python packages
Start the REVIEW service. Note: You can stop the app with control+C
python3 review.py
* Serving Flask app 'review'(lazy loading) * Environment: production
...snip...
* Running on http://10.160.145.246:5000/ (Press CTRL+C to quit) * Restarting with stat
127.0.0.1 - - [17/May/2022 22:46:38]"GET / HTTP/1.1"200 -
127.0.0.1 - - [17/May/2022 22:47:02]"GET /get_review HTTP/1.1"200 -
127.0.0.1 - - [17/May/2022 22:47:58]"GET /get_review HTTP/1.1"200 -
Verify that the service is working
Open a new terminal and ssh into your ec2 instance. Then use the curl command in your terminal.
curl http://localhost:5000
Or hit the URL http://{Your_EC2_IP_address}:5000 and http://{Your_EC2_IP_address}:5000/get_review with a browser
curl localhost:5000
{"message": "Hello, you want to hit /get_review. We have 100000 reviews!"}curl localhost:5000/get_review
{"review_id":"NjbiESXotcEdsyTc4EM3fg","user_id":"PR9LAM19rCM_HQiEm5OP5w","business_id":"UAtX7xmIfdd1W2Pebf6NWg","stars":3.0,"useful":0,"funny":0,"cool":0,"text":"-If you're into cheap beer (pitcher of bud-light for $7) decent wings and a good time, this is the place for you. Its generally very packed after work hours and weekends. Don't expect cocktails. \n\n-You run into a lot of sketchy characters here sometimes but for the most part if you're chilling with friends its not that bad. \n\n-Friendly bouncer and bartenders.","date":"2016-04-12 20:23:24"}
Workshop Question
What does this application do?
Do you see the yelp dataset being used?
Why did the output of pip freeze differ each time you ran it?
Which port is the REVIEW app listening on? Can other python apps use this same port?
2. Create a REVIEW container
To create a container image, you need to create a Dockerfile, run docker build to build the image referencing the Docker file and push it up to a remote repository so it can be pulled by other sources.
Verify that the deployment and services are running:
kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
review 1/1 1 1 19h
kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
review NodePort 10.43.175.21 <none> 5000:30000/TCP 154d
curl localhost:30000
{
"message": "Hello, you want to hit /get_review. We have 100000 reviews!"
}
curl localhost:30000/get_review
{"review_id":"Vv9rHtfBrFc-1M1DHRKN9Q","user_id":"EaNqIwKkM7p1bkraKotqrg","business_id":"TA1KUSCu8GkWP9w0rmElxw","stars":3.0,"useful":1,"funny":0,"cool":0,"text":"This is the first time I've actually written a review for Flip, but I've probably been here about 10 times. \n\nThis used to be where I would take out of town guests who wanted a good, casual, and relatively inexpensive meal. \n\nI hadn't been for a while, so after a long day in midtown, we decided to head to Flip. \n\nWe had the fried pickles, onion rings, the gyro burger, their special burger, and split a nutella milkshake. I have tasted all of the items we ordered previously (with the exception of the special) and have been blown away with how good they were. My guy had the special which was definitely good, so no complaints there. The onion rings and the fried pickles were greasier than expected. Though I've thought they were delicious in the past, I probably wouldn't order either again. The gyro burger was good, but I could have used a little more sauce. It almost tasted like all of the ingredients didn't entirely fit together. Something was definitely off. It was a friday night and they weren't insanely busy, so I'm not sure I would attribute it to the staff not being on their A game...\n\nDon't get me wrong. Flip is still good. The wait staff is still amazingly good looking. They still make delicious milk shakes. It's just not as amazing as it once was, which really is a little sad.","date":"2010-10-11 18:18:35"}
Workshop Question
What changes are required if you need to make an update to your Dockerfile now?
Instrument REVIEWS for Tracing
1. Use Data Setup to instrument a Python application
Monitor System Logs with Splunk Universal Forwarder
Objective: Learn how to monitor Linux system logs with the Universal Forwarder sending logs to Splunk Enterprise
Duration: 10 Minutes
Scenario
You’ve been tasked with monitoring the OS logs of the host running your Kubernetes cluster. We are going to utilize a script that will autodeploy the Splunk Universal Forwarder. You will then configure the Universal Forwarder to send logs to the Splunk Enterprise instance assigned to you.
1. Ensure You’re in the Correct Directory
we will need to be in /home/splunk/session-2
cd /home/splunk/session-2
2. Review the Universal Forwarder Install Script
Let’s take a look at the script that will install the Universal Forwarder and Linux TA automatically for you.
This script is primarily used for remote instances.
Note we are not using a deployment server in this lab, however it is recommended in production we do that.
What user are we installing Splunk as?
#!/bin/sh
# This EXAMPLE script shows how to deploy the Splunk universal forwarder# to many remote hosts via ssh and common Unix commands.# For "real" use, this script needs ERROR DETECTION AND LOGGING!!# --Variables that you must set -----# Set username using by splunkd to run.SPLUNK_RUN_USER="ubuntu"# Populate this file with a list of hosts that this script should install to,# with one host per line. This must be specified in the form that should# be used for the ssh login, ie. username@host## Example file contents:# splunkuser@10.20.13.4# splunkker@10.20.13.5HOSTS_FILE="myhost.txt"# This should be a WGET command that was *carefully* copied from splunk.com!!# Sign into splunk.com and go to the download page, then look for the wget# link near the top of the page (once you have selected your platform)# copy and paste your wget command between the ""WGET_CMD="wget -O splunkforwarder-9.0.3-dd0128b1f8cd-Linux-x86_64.tgz 'https://download.splunk.com/products/universalforwarder/releases/9.0.3/linux/splunkforwarder-9.0.3-dd0128b1f8cd-Linux-x86_64.tgz'"# Set the install file name to the name of the file that wget downloads# (the second argument to wget)INSTALL_FILE="splunkforwarder-9.0.3-dd0128b1f8cd-Linux-x86_64.tgz"# After installation, the forwarder will become a deployment client of this# host. Specify the host and management (not web) port of the deployment server# that will be managing these forwarder instances.# Example 1.2.3.4:8089# DEPLOY_SERVER="x.x.x.x:8089"# After installation, the forwarder can have additional TA's added to the # /app directory please provide the local where TA's will be. TA_INSTALL_DIRECTORY="/home/splunk/session-2"# Set the seed app folder name for deploymentclien.conf# DEPLOY_APP_FOLDER_NAME="seed_all_deploymentclient"# Set the new Splunk admin passwordPASSWORD="buttercup"REMOTE_SCRIPT_DEPLOY="
cd /opt
sudo $WGET_CMD sudo tar xvzf $INSTALL_FILE sudo rm $INSTALL_FILE #sudo useradd $SPLUNK_RUN_USER sudo find $TA_INSTALL_DIRECTORY -name '*.tgz' -exec tar xzvf {} --directory /opt/splunkforwarder/etc/apps \;
sudo chown -R $SPLUNK_RUN_USER:$SPLUNK_RUN_USER /opt/splunkforwarder
echo \"[user_info]
USERNAME = admin
PASSWORD = $PASSWORD\" > /opt/splunkforwarder/etc/system/local/user-seed.conf
#sudo cp $TA_INSTALL_DIRECTORY/*.tgz /opt/splunkforwader/etc/apps/
#sudo find /opt/splunkforwarder/etc/apps/ -name '*.tgz' -exec tar xzvf {} \;
#sudo -u splunk /opt/splunkforwarder/bin/splunk start --accept-license --answer-yes --auto-ports --no-prompt
/opt/splunkforwarder/bin/splunk start --accept-license --answer-yes --auto-ports --no-prompt
#sudo /opt/splunkforwarder/bin/splunk enable boot-start -user $SPLUNK_RUN_USER /opt/splunkforwarder/bin/splunk enable boot-start -user $SPLUNK_RUN_USER #sudo cp $TA_INSTALL_DIRECTORY/*.tgz /opt/splunkforwarder/etc/apps/
exit
"DIR="$(cd"$( dirname "${BASH_SOURCE[0]}")" >/dev/null &&pwd)"#===============================================================================================echo"In 5 seconds, will run the following script on each remote host:"echoecho"===================="echo"$REMOTE_SCRIPT_DEPLOY"echo"===================="echo sleep 5echo"Reading host logins from $HOSTS_FILE"echoecho"Starting."for DST in `cat "$DIR/$HOSTS_FILE"`;doif[ -z "$DST"];thencontinue;fiecho"---------------------------"echo"Installing to $DST"echo"Initial UF deployment" sudo ssh -t "$DST""$REMOTE_SCRIPT_DEPLOY"doneecho"---------------------------"echo"Done"echo"Please use the following app folder name to override deploymentclient.conf options: $DEPLOY_APP_FOLDER_NAME"
3. Run the install script
We will run the install script now. You will see some Warnings at the end. This is totally normal. The script is built for use on remote machines, however for todays lab you will be using localhost.
./install.sh
You will be asked Are you sure you want to continue connecting (yes/no/[fingerprint])?
Answer Yes.
Enter your ssh password when prompted.
4. Verify installation of the Universal Forwarader
We need to verify that the Splunk Universal Forwarder is installed and running.
You should see a couple PID’s return and a “Splunk is currently running.” message.
/opt/splunkforwarder/bin/splunk status
5. Configure the Universal Forwarder to Send Data to Splunk Enterprise
We will be able to send the data to our Splunk Enterprise environment easily by entering one line into the cli.
6. Verify the Data in Your Splunk Enterprise Environment
We are now going to take a look at the Splunk Enterprise environment to verify logs are coming in.
Logs will be coming into index=main
Open your web browser and navigate to: http://<your_splunk_enterprise_ip:8000
You will use the credentials admin:<your_ssh_password>
In the search bar, type in the following:
index=main host=<your_host_name>
You should see data from your host. Take note of the interesting fields and the different data sources flowing in.
Splunk OnCall
1 hour 30 minutesAuthor
Geoff Higginbottom
Aim
This module is simply to ensure you have access to the Splunk On-Call UI (formerly known as VictorOps), Splunk Infrastructure Monitoring UI (formerly known as SignalFx) and the EC2 Instance which has been allocated to you.
Once you have access to each platform, keep them open for the duration of the workshop as you will be switching between them and the workshop instructions.
1. Activate your Splunk On-Call Login
You should have received an invitation to Activate your Splunk On-Call account via e-mail, if you have not already done so, click the Activate Account link and follow the prompts.
If you did not receive an invitation it is probably because you already have a Splunk On-Call login, linked to a different organization.
If so log in to that Org, then use the organization dropdown next to your username in the top left to switch to the Observability Workshop Org.
Note
If you do not see the Organisation dropdown menu item next to your name with Observability Workshop EMEA that is OK, it simply means you only have access to a single Org so that menu is not visible to you.
2. Activate your Splunk Infrastructure Monitoring Login
You should have received an invitation to join the Splunk Infrastructure Monitoring - Observability Workshop. If you have not already done so click the JOIN NOW button and follow the prompts to set a password and activate your login.
3. Access your EC2 Instance
Splunk has provided you with a dedicated EC2 Instance which you can use during this workshop for triggering Incidents the same way the instructor did during the introductory demo. This VM has Splunk Infrastructure Monitoring deployed and has an associated Detector configured. The Detector will pass Alerts to Splunk On-Call which will then create Incidents and page the on-call user.
The welcome e-mail you received providing you all the details for this Workshop contain the instructions for accessing your allocated EC2 Instance.
SSH (Mac OS/Linux)
Most attendees will be able to connect to the workshop by using SSH from their Mac or Linux device.
To use SSH, open a terminal on your system and type ssh splunk@x.x.x.x (replacing x.x.x.x with the IP address found in your welcome e-mail).
When prompted Are you sure you want to continue connecting (yes/no/[fingerprint])? please type yes.
Enter the password provided in the welcome e-mail.
Upon successful login you will be presented with the Splunk logo and the Linux prompt.
If you are blocked from using SSH (Port 22) or unable to install Putty you may be able to connect to the workshop instance by using a web browser.
!!! note
This assumes that access to port 6501 is not restricted by your company’s firewall.
Open your web browser and type http://x.x.x.x:650 (where x.x.x.x is the IP address from the welcome e-mail).
Once connected, login in as splunk and the password is the one provided in the welcome e-mail.
Once you are connected successfully you should see a screen similar to the one below:
Copy & Paste in browser
Unlike when you are using regular SSH, copy and paste does require a few extra steps to complete when using a browser session. This is due to cross browser restrictions.
When the workshop asks you to copy instructions into your terminal, please do the following:
Copy the instruction as normal, but when ready to paste it in the web terminal, choose Paste from browser as show below:
This will open a dialogue box asking for the text to be pasted into the web terminal:
Paste the text in the text box as show, then press OK to complete the copy and paste process.
Unlike regular SSH connection, the web browser has a 60 second time out, and you will be disconnected, and a Connect button will be shown in the center of the web terminal.
Simply click the Connect button and you will be reconnected and will be able to continue.
The aim of this module is for you to configure your personal profile which controls how you will be notified by Splunk On-Call whenever you get paged.
1. Contact Methods
Switch to the Splunk On-Call UI and click on your login name in the top right hand corner and chose Profile from the drop down. Confirm your contact methods are listed correctly and add any additional phone numbers and e-mail address you wish to use.
2. Mobile Devices
To install the Splunk On-Call app for your smartphone search your phones App Store for Splunk On-Call to find the appropriate version of the app. The publisher should be listed as VictorOps Inc.
Install the App and login, then refresh the Profile page and your device should now be listed under the devices section. Click the Test push notification button and confirm you receive the test message.
3. Personal Calendar
This link will enable you to sync your on-call schedule with your calendar, however as you do not have any allocated shifts yet this will currently be empty. You can add it to your calendar by copying the link into your preferred application and setting it up as a new subscription.
4. Paging Policies
Paging Polices specify how you will be contacted when on-call. The Primary Paging Policy will have defaulted to sending you an SMS assuming you added your phone number when activating your account. We will now configure this policy into a three tier multi-stage policy similar to the image below.
4.1 Send a push notification
Click the edit policy button in the top right corner for the Primary Paging Policy.
Send a push notification to all my devices
Execute the next step if I have not responded within 5 minutes
Click Add a Step
4.2 Send an e-mail
Send an e-mail to [your email address]
Execute the next step if I have not responded within 5 minutes
Click Add a Step
4.3 Call your number
Every 5 minutes until we have reached you
Make a phone call to [your phone number]
Click Save to save the policy.
When you are on-call or in the escalation path of an incident, you will receive notifications in this order following these time delays.
To cease the paging you must acknowledge the incident. Acknowledgements can occur in one of the following ways:
Expanding the Push Notification on your device and selecting Acknowledge
Responding to the SMS with the 5 digit code included
Pressing 4 during the Phone Call
Slack Button
For more information on Notification Types, see here.
5. Custom Paging Policies
Custom paging polices enable you to override the primary policy based on the time and day of the week. A good example would be to get the system to immediately phone you whenever you get a page during the evening or weekends as this is more likely to get your attention than a push notification.
Create a new Custom Policy by clicking Add a Policy and configure with the following settings:
5.1 Custom evening policy
Policy Name: Evening
Every 5 minutes until we have reached you
Make a phone call to [your phone number]
Time Period: All 7 Days
Time zone
Between 7pm and 9am
Click Save to save the policy then add one more.
5.2 Custom weekend policy
Policy Name: Weekend
Every 5 minutes until we have reached you
Make a phone call to [your phone number]
Time Period: Sat & Sun
Time zone
Between 9am and 7pm
Click Save to save the policy.
These custom paging policies will be used during the specified times in place of the Primary Policy. However, admins do have the ability to ignore these custom policies, and we will highlight how this is achieved in a later module.
The final option here is the setting for Recovery Notifications. These are typically low priority, will default to Push, but can also be email, sms or phone call. Your profile is now fully configured using these example configurations.
Organizations will have different views on how profiles should be configured and will typically issue guidelines for paging policies and times between escalations etc.
Please wait for the instructor before proceeding to the Teams module.
Subsections of 1. Getting Started
Teams
Aim
The aim of this module is for you to complete the first step of Team configuration by adding users to your Team.
1. Find your Team
Navigate to the Teams tab on the main toolbar, you should find you that a Team has been created for you as part of the workshop pre-setup and you would have been informed of your Team Name via e-mail.
If you have found your pre-configured Team, skip Step 2. and proceed to Step 3. Configure Your Team. However, if you cannot find your allocated Team, you will need to create a new one, so proceed with Step 2. Create Team
2. Create Team
Only complete this step if you cannot find your pre-allocated Team as detailed in your workshop e-mail. Select Add Team, then enter your allocated team name, this will typically be in the format of “AttendeeID Workshop” and then save by clicking the Add Team button.
3. Configure Your Team
You now need to add other users to your team. If you are running this workshop using the Splunk provided environment, the following accounts are available for testing. If you are running this lab in your own environment, you will have been provided a list of usernames you can use in place of the table below.
These users are dummy accounts who will not receive notifications when they are on call.
Name
Username
Shift
Duane Chow
duanechow
Europe
Steven Gomez
gomez
Europe
Walter White
heisenberg
Europe
Jim Halpert
jimhalpert
Asia
Lydia Rodarte-Quayle
lydia
Asia
Marie Schrader
marie
Asia
Maximo Arciniega
maximo
West Coast
Michael Scott
michaelscott
West Coast
Tuco Salamanca
tuco
West Coast
Jack Welker
jackwelker
24/7
Hank Schrader
hank
24/7
Pam Beesly
pambeesly
24/7
Add the users to your team, using either the above list or the alternate one provided to you. The value in the Shift column can be ignored for now, but will be required for a later step.
Click Invite User button on the right hand side, then either start typing the usernames (this will filter the list), or copy and paste them into the dialogue box. Once all users are added to the list click the Add User button.
To make a team member a Team Admin, simply click the :fontawesome-regular-edit: icon in the right hand column, pick any user and make them an Admin.
Tip
For large team management you can use the APIs to streamline this process.
A rotation is a recurring schedule, that consists of one or more shifts, with members who rotate through a shift.
The aim of this module is for you to configure two example Rotations, and assign Team Members to the Rotations.
Navigate to the Rotations tab on the Teams sub menu, you should have no existing Rotations so we need to create some.
The 1st Rotation you will create is for a follow the sun support pattern where the members of each shift provide cover during their normal working hours within their time zone.
The 2nd will be a Rotation used to provide escalation support by more experienced senior members of the team, based on a 24/7, 1 week shift pattern.
1. Follow the Sun Support - Business Hours
Click Add Rotation
Enter a name of “Follow the Sun Support - Business Hours” and Select Partial day from the three available shift templates.
Enter a Shift name of “Asia”
Time Zone set to “Asia/Tokyo”
Each user is on duty from “Monday through Friday from 9.00am to 5.00pm”
Handoff happens every “5 days”
The next handoff happens - Select the next Monday using the calendar
Click Save Rotation
You will now be prompted to add Members to this shift; add the Asia members who are Jim Halpert, Lydie Rodarte-Quayle and Marie Schrader, but only if you’re using the Splunk provided environment for this workshop.
If you’re using your own Organisation refer to the specific list provided separately.
Now add an 2nd shift for Europe by again clicking +Add a shift → Partial Day
Enter a Shift name of “Europe”
Time Zone set to “Europe/London”
Each user is on duty from “Monday through Friday from 9.00am to 5.00pm”
Handoff happens every “5 days”
The next handoff happens - Select the next Monday using the calendar
Click Save Shift
You will again be prompted to add Members to this shift; add the Europe members who are Duane Chow, Steven Gomez and Walter White, but only if you’re using the Observability Workshop Org for this workshop.
If you’re using your own Organisation refer to the specific list provided separately.
Now add a 3rd shift for West Coast USA by again clicking +Add a shift - Partial Day
Enter a Shift name of “West Coast”
Time Zone set to “US/Pacific”
Each user is on duty from “Monday through Friday from 9.00am to 5.00pm”
Handoff happens every “5 days”
The next handoff happens - Select the next Monday using the calendar
Click Save Shift
You will again be prompted to add Members to this shift; add the West Coast members who are Maximo Arciniega, Michael Scott and Tuco Salamanca, but only if you’re using the Observability Workshop Org for this workshop.
If you’re using your own Organisation refer to the specific list provided separately.
The first user added will be the ‘current’ user for that shift.
You can re-order the shifts by simply dragging the users up and down, and you can change the current user by clicking Set Current on an alternate user
You will now have three different Shift patterns, that provide cover 24hr hours, Mon - Fri, but with no cover at weekends.
We will now add another Rotation for our Senior SRE Escalation cover.
2. Senior SRE Escalation
Click Add Rotation
Enter a name of “Senior SRE Escalation”
Select 24/7 from the three available shift templates
Enter a Shift name of “Senior SRE Escalation”
Time Zone set to “Asia/Tokyo”
Handoff happens every “7 days at 9.00am”
The next handoff happens [select the next Monday from the date picker]
Click Save Rotation
You will again be prompted to add Members to this shift; add the 24/7 members who are Jack Welker, Hank Schrader and Pam Beesly, but only if you’re using the Observability Workshop Org for this workshop.
If you’re using your own Organisation refer to the specific list provided separately.
Please wait for the instructor before proceeding to the Configuring Escalation Policies module.
Configure Escalation Policies
Aim
Escalation policies determine who is actually on-call for a given team and are the link to utilizing any rotations that have been created.
The aim of this module is for you to create three different Escalation Policies to demonstrate a number of different features and operating models.
The instructor will start by explaining the concepts before you proceed with the configuration.
Navigate to the Escalation Polices tab on the Teams sub menu, you should have no existing Polices so we need to create some.
We are going to create the following Polices to cover off three typical use cases.
1. 24/7 Policy
Click Add Escalation Policy
Policy Name: 24/7
Step 1
Immediately
Notify the on-duty user(s) in rotation → Senior SRE Escalation
Click Save
2. Primary Policy
Click Add Escalation Policy
Policy Name: Primary
Step 1
Immediately
Notify the on-duty user(s) in rotation → Follow the Sun Support - Business Hours
Click Add Step
Step 2
If still un-acknowledged after 15 minutes
Notify the next user(s) in the current on-duty shift → Follow the Sun Support - Business Hours
Click Add Step
Step 3
If still un-acknowledged after 15 more minutes
Execute Policy → [Your Team Name] : 24/7
Click Save
3. Waiting Room Policy
Click Add Escalation Policy
Policy Name: Waiting Room
Step 1
If still un-acknowledged after 10 more minutes
Execute Policy → [Your Team Name] : Primary
Click Save
You should now have the following three escalation polices:
You may have noticed that when we created each policy there was the following warning message:
Warning
There are no routing keys for this policy - it will only receive incidents via manual reroute or when on another escalation policy
This is because there are no Routing Keys linked to these Escalation Polices, so now that we have these polices configured we can create the Routing Keys and link them to our Polices..
Routing Keys map the incoming alert messages from your monitoring system to an Escalation Policy which in turn sends the notifications to the appropriate team.
Note that routing keys are case insensitive and should only be composed of letters, numbers, hyphens, and underscores.
The aim of this module is for you to create some routing keys and then link them to your Escalation Policies you have created in the previous exercise.
1. Instance ID
Each participant requires a unique Routing Key so we use the Hostname of the EC2 Instance you were allocated. We are only doing this to ensure your Routing Key is unique and we know all Hostnames are unique. In a production deployment the Routing Key would typically reflect the name of a System or Service being monitored, or a Team such as 1st Line Support etc.
Your welcome e-mail informed you of the details of your EC2 Instance that has been provided for you to use during this workshop and you should have logged into this as part of the 1st exercise.
The e-mail also contained the Hostname of the Instance, but you can also obtain it from the Instance directly. To get your Hostname from within the shell session connected to your Instance run the following command:
echo${HOSTNAME}
zevn
It is very important that when creating the Routing Keys you use the 4 letter hostname allocated to you as a Detector has been configured within Splunk Infrastructure Monitoring using this hostname, so any deviation will cause future exercises to fail.
2 Create Routing Keys
Navigate to Settings on the main menu bar, you should now be at the Routing Keys page.
You are going to create the following two Routing Keys using the naming conventions listed in the following table, but replacing {==HOSTNAME==} with the value from above and replace TEAM_NAME with the team you were allocated or created earlier.
Routing Key
Escalation Policies
HOSTNAME_PRI
TEAM_NAME : Primary
HOSTNAME_WR
TEAM_NAME : Waiting Room
There will probably already be a number of Routing Keys configured, but to add a new one simply scroll to the bottom of the page and then click Add Key
In the left hand box, enter the name for the key as per the table above. In the Routing Key column, select your Teams Primary policy from the drop down in the Escalation Polices column. You can start typing your Team Name to filter the results.
Note
If there are a large number of participants on the workshop, resulting in an unusually large number of Escalation Policies sometimes the search filter does not list all the Policies under your Team Name. If this happens instead of using the search feature, simply scroll down to your team name, all the policies will then be listed.
Repeat the above steps for both Keys, xxxx_PRI and xxxx_WR, mapping them to your Teams Primary and Waiting Room policies.
You should now have two Routing Keys configured, similar to the following:
Tip
You can assign a Routing Key to multiple Escalation Policies if required by simply selecting more from the list
If you now navigate back to Teams → [Your Team Name] → Escalation Policies and look at the settings for your Primary and Waiting Room polices you will see that these now have Routes assigned to them.
The 24/7 policy does not have a Route assigned as this will only be triggered via an Execute Policy escalation from the Primary policy.
Please wait for the instructor before proceeding to the Incident Lifecycle/Overview module.
Incident Lifecycle
Aim
The aim of this module is for you to get more familiar with the Timeline Tab and the filtering features.
1. Timeline
The aim of Splunk On-Call is to make being on call more bearable, and it does this by getting the critical data, to the right people, at the right time.
The key to making it work for you is to centralize all your alerting sources, sending them all to the Splunk On-Call platform, then you have a single pane of glass in which to manage all of your alerting.
Login to the Splunk On-Call UI and select the Timeline tab on the main menu bar, you should have a screen similar to the following image:
2. People
On the left we have the People section with the Teams and Users sub tabs. On the Teams tab, click on All Teams then expand [Your Team name].
Users with the Splunk On-Call Logo against their name are currently on call. Here you can see who is on call within a particular Team, or across all Teams via Users → On-Call.
If you click into one of the currently on call users, you can see their status. It shows which Rotation they are on call for, when their current Shift ends and their next Shift starts (times are displayed in your time zone), what contact methods they have and which Teams they belong to (dummy users such as Hank do not have Contact Methods configured).
3. Timeline
In the centre Timeline section you get a realtime view of what is happening within your environment with the newest messages at the top. Here you can quickly post update messages to make your colleagues aware of important developments etc.
You can filter the view using the buttons on the top toolbar showing only update messages, GitHub integrations, or apply more advanced filters.
Lets change the Filters settings to streamline your view. Click the Filters button then within the Routing Keys tab change the Show setting from all routing keys to selected routing keys. Change the My Keys value to all and the Other Keys value to selected and deselect all keys under the Other Keys section.
Click anywhere outside of the dialogue box to close it.
You will probably now have a much simpler view as you will not currently have Incidents created using your Routing Keys, so you are left with the other types of messages that the Timeline can display.
Click on Filters again, but this time switch to the Message Types tab. Here you control the types of messages that are displayed.
For example, deselect On-call Changes and Escalations, this will reduce the amount of messages displayed.
4. Incidents
On the right we have the Incidents section. Here we get a list of all the incidents within the platform, or we can view a more specific list such as incidents you are specifically assigned to, or for any of the Teams you are a member of.
Select the Team Incidents tab you should find that the Triggered, Acknowledged & Resolved tabs are currently all empty as you have had no incidents logged.
Let’s change that by generating your first incident!
The aim of this module is for you to place yourself ‘On-Call’ then generate an Incident using the supplied EC2 Instance so you can then work through the lifecycle of an Incident.
1. On-Call
Before generating any incidents you should assign yourself to the current Shift within your Follow the Sun Support - Business Hours Rotation and also place yourself On-Call.
Click on the Schedule link within your Team in the People section on the left, or navigate to Teams → [Your Team] → Rotations
Expand the Follow the Sun Support - Business Hours Rotation
Click on the Manage members icon (the figures) for the current active shift depending on your time zone
Use the Select a user to add… dropdown to add yourself to the shift
Then click on Set Current next to your name to make yourself the current on-call user within the shift
You should now get a Push Notification to your phone informing you that You Are Now On-Call
2. Trigger Alert
Switch back to your shell session connected to your EC2 Instance; all of the following commands will be executed from your Instance.
Force the CPU to spike to 100% by running the following command:
This will result in an Alert being generated by Splunk Infrastructure Monitoring which in turn will generate an Incident within Splunk On-Call within a maximum of 10 seconds. This is the default polling time for the OpenTelemetry Collector installed on your instance (note it can be reduced to 1 second).
Use your Splunk On-Call App on your phone to acknowledge the Incident by clicking on the push notification …
…to open the alert in the Splunk On-Call mobile app, then clicking on either the single tick in the top right hand corner, or the Acknowledge link to acknowledge the incident and stop the escalation process.
The :fontawesome-solid-check: will then transform into a :fontawesome-solid-check::fontawesome-solid-check:, and the status will change from TRIGGERED to ACKNOWLEDGED.
Triggered Incident
Acknowledge Incident
2. Details and Annotations
Still on your phone, select the Alert Details tab. Then on the Web UI, navigate back to Timeline, select Team Incidents on the right, then select Acknowledged and click into the new Incident, this will open up the War Room Dashboard view of the Incident.
You should now have the Details tab displayed on both your Phone and the Web UI. Notice how they both show the exact same information.
Now select the Annotations tab on both the Phone and the Web UI, you should have a Graph displayed in the UI which is generated by Splunk Infrastructure Monitoring.
On your phone you should get the same image displayed (sometimes it’s a simple hyperlink depending on the image size)
Splunk On-Call is a ‘Mobile First’ platform meaning the phone app is full functionality and you can manage an incident directly from your phone.
For the remainder of this module we will focus on the Web UI however please spend some time later exploring the phone app features.
3. Link to Alerting System
Sticking with the Web UI, click the 2. Alert Details in SignalFx link.
This will open a new browser tab and take you directly to the Alert within Splunk Infrastructure Monitoring where you could then progress your troubleshooting using the powerful tools built into its UI.
However, we are focussing on Splunk On-Call so close this tab and return to the Splunk On-Call UI.
4. Similar Incidents
What if Splunk On-Call could identify previous incidents within the system which may give you a clue to the best way to tackle this incident.
The Similar Incidents tab does exactly that, surfacing previous incidents allowing you to look at them and see what actions were taken to resolve them, actions which could be easily repeated for this incident.
5 Timeline
On right we have a Time Line view where you can add messages and see the history of previous alerts and interactions.
6 Add Responders
On the far left you have the option of allocating additional resources to this incident by clicking on the Add Responders link.
This allows you build a virtual team specific to this incident by adding other Teams or individual Users, and also share details of a Conference Bridge where you can all get together and collaborate.
Once the system has built up some incident data history, it will use Machine Learning to suggest Teams and Users who have historically worked on similar incidents, as they may be best placed to help resolve this incident quickly.
You can select different Teams and/or Users and also choose from a pre-configured conference bridge, or populate the details of a new bridge from your preferred provider.
We do not need to add any Responders in this exercise so close the Add Responders dialogue by clicking Cancel.
7 Reroute
If it’s decided that maybe the incident could be better dealt with by a different Team, the call can be Rerouted by clicking the Reroute Button at the top of the left hand panel.
In a similar method to that used in the Add Responders dialogue, you can select Teams or Users to Reroute the Incident to.
We do not need to actually Reroute in this exercise so close the Reroute Incident dialogue by clicking Cancel.
8 Snooze
You can also snooze this incident by clicking on the alarm clock Button at the top of the left hand panel.
You can enter an amount of time upto 24 hours to snooze the incident. This action will be tracked in the Timeline, and when the time expires the paging will restart.
This is useful for low priority incidents, enabling you to put them on a back burner for a few hours, but it ensures they do not get forgotten thanks to the paging process starting again.
We do not need to actually Snooze in this exercise so close the Snooze Incident dialogue by clicking Cancel.
9 Action Tracking
Now lets fix this issue and update the Incident with what we did. Add a new message at the top of the right hand panel such as Discovered rogue process, terminated it.
All the actions related to the Incident will be recorded here, and can then be summarized is a Post Incident Review Report available from the Reports tab
10 Resolution
Now kill off the process we started in the VM to max out the CPU by switching back the Shell session for the VM and pressing ctrl+c
Within no more than 10 seconds SignalFx should detect the new CPU value, clear the alert state in SignalFx, then automatically update the Incident in VictorOps marking it as Resolved.
As we have two way integration between Splunk Infrastructure Monitoring and Splunk On-Call we could have also marked the incident as Resolved in Splunk On-Call, and this would have resulted in the alert in Splunk Infrastructure Monitoring being resolved as well.
That completes this introduction to Splunk On-Call!