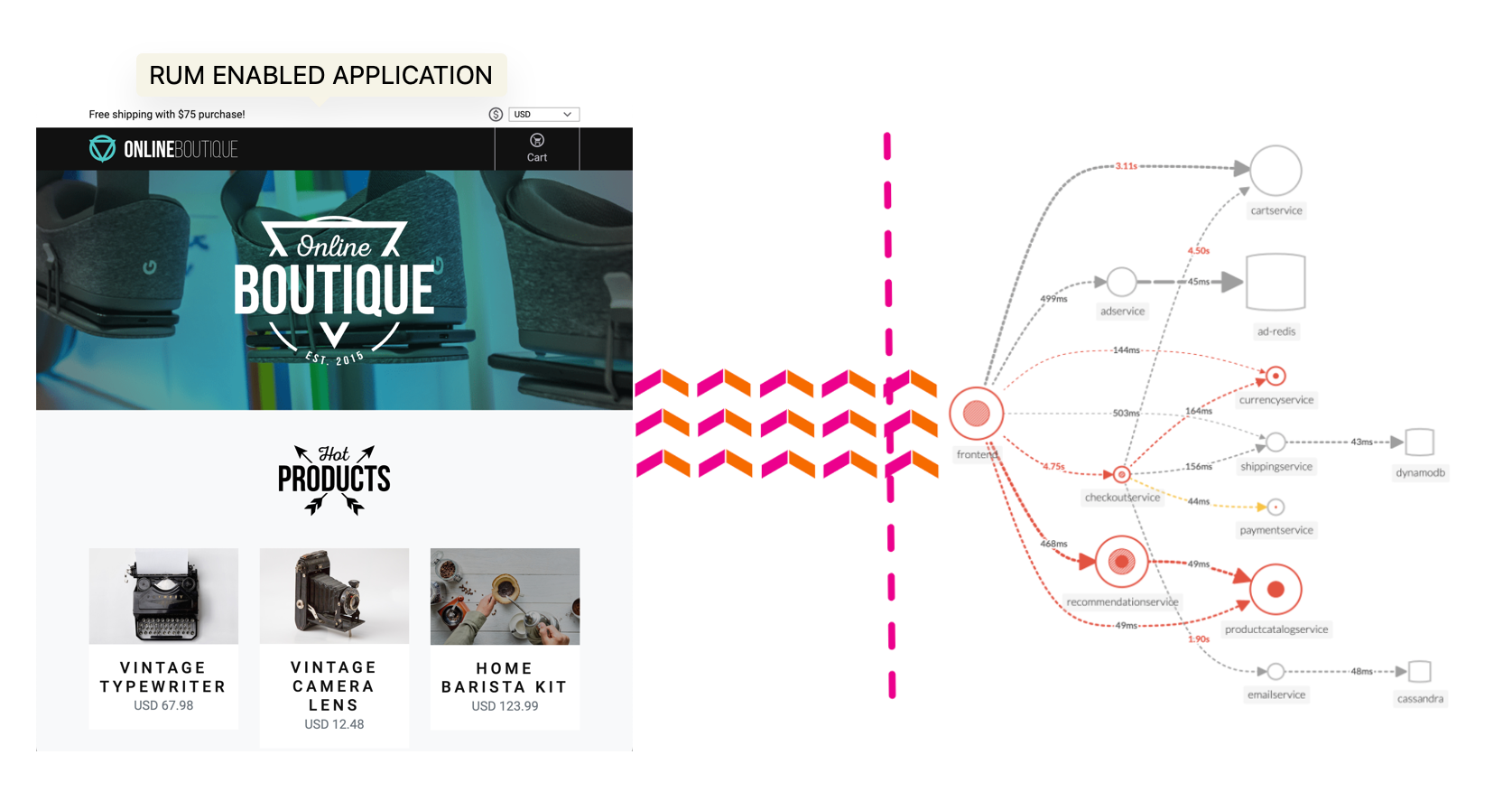
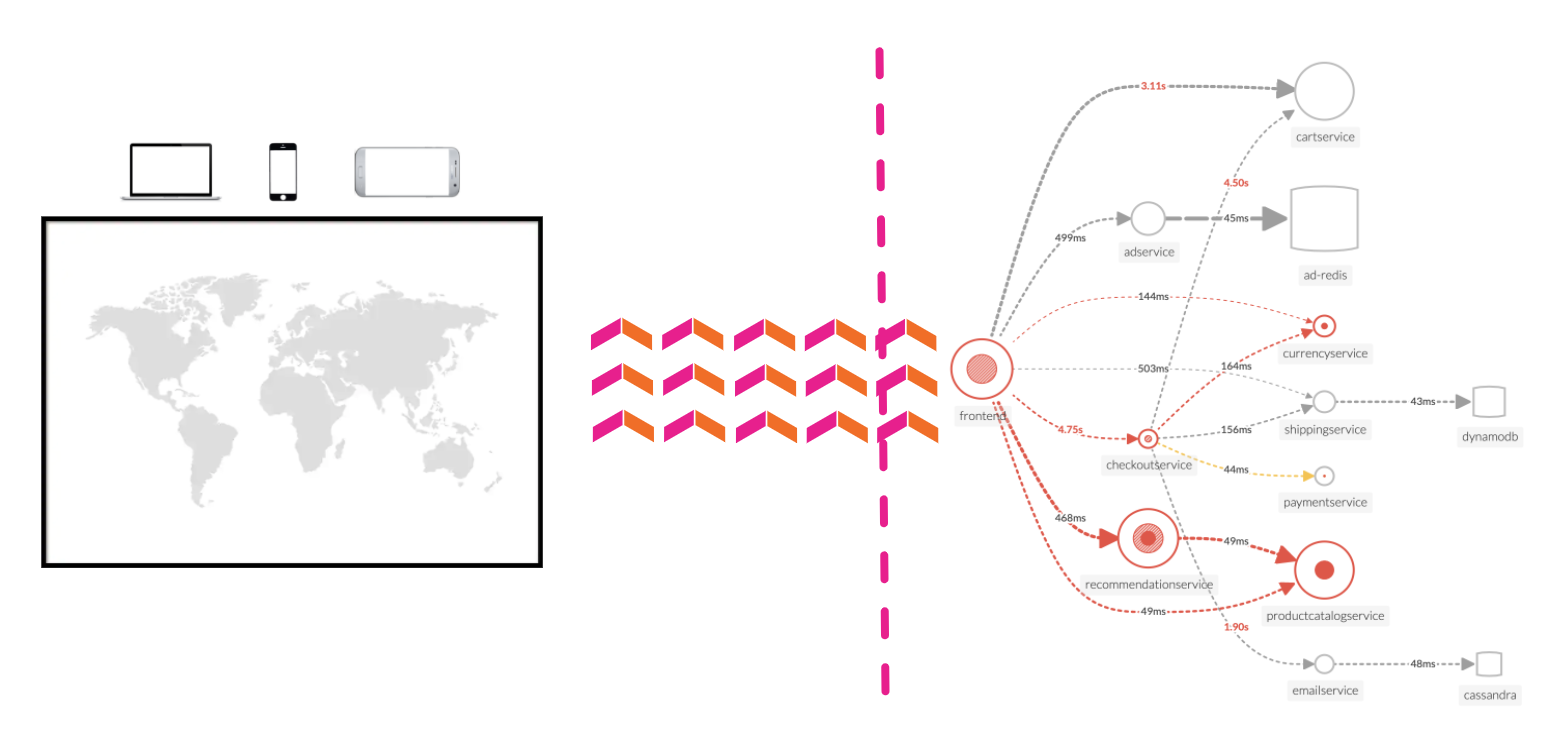
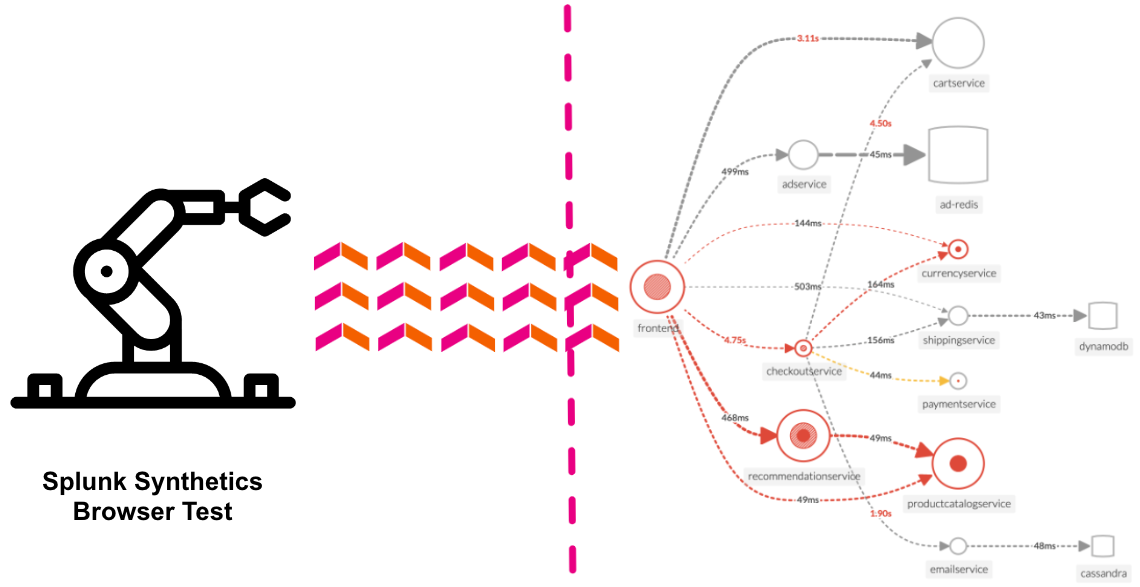
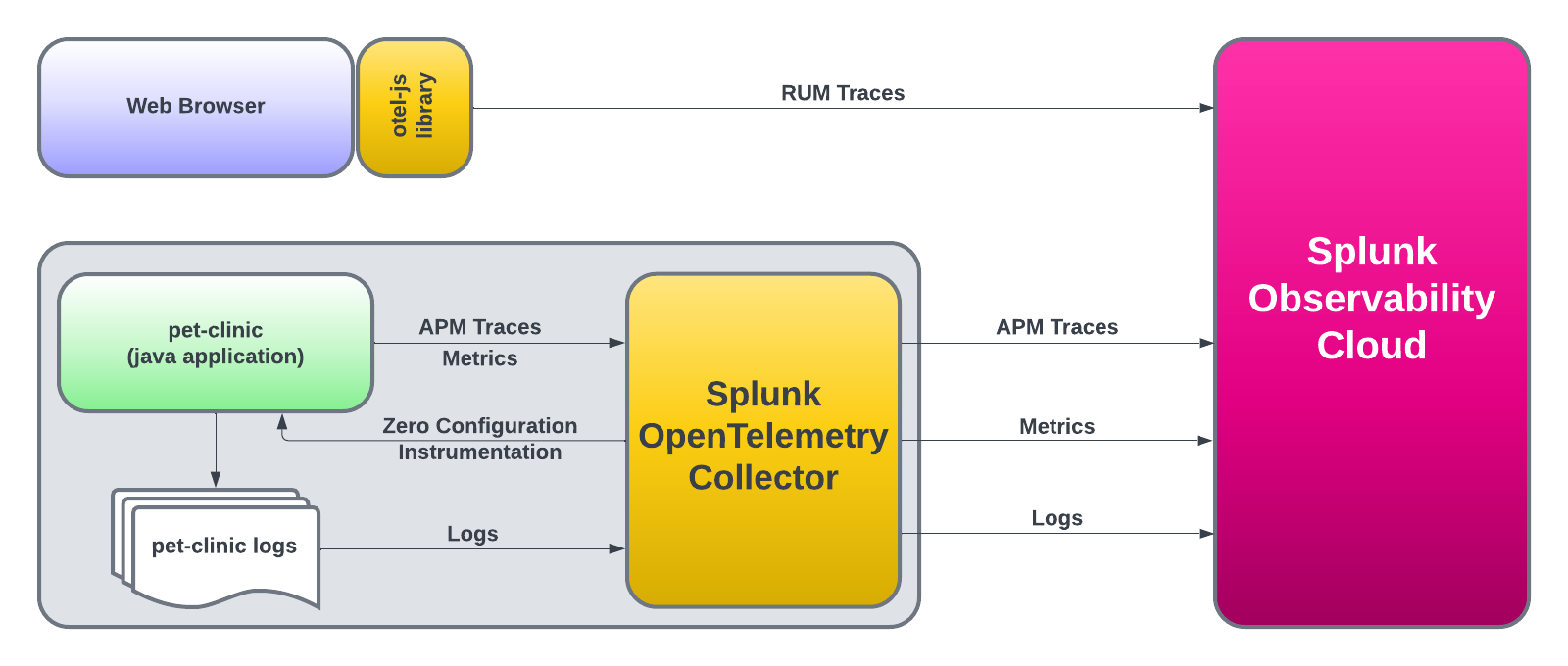
RUM トレース(フロントエンド)から APM トレース(バックエンド)へとジャンプすることで、End to End 全体を可視化する能力を理解しましょう。すべてのサービスはテレメトリー(トレースとスパン)を送信しており、Splunk Observability Cloud はそれを可視化・分析し、異常やエラーを検出するために使用することができます。
Splunk Log Observer (LO)
Related Content の強力な機能を使うと、あるコンポーネントから別のコンポーネントにジャンプすることが可能になります。ここでは、私たちは APM トレースから、そのトレースに関連するログにジャンプします。
メニューの下部で、好みの外観を選択します。Light、Dark、または Auto モードが選択できます。
Sign Out ボタンが表示されていることに気付きましたか? でも、押さないでくださいね!😊
メインメニューに戻るために < をクリックします。
次に、Splunk Real User Monitoring (RUM) をチェックしましょう。
RUMの概要
5分
Splunk RUM は業界唯一の End to End の, NoSample™ RUM ソリューションです。すべての Web およびモバイルセッションに関するユーザーエクスペリエンス全体を可視化し、フロントエンドの全てのトレースをバックエンドのメトリクス、トレース、ログと一意に組み合わせることができます。IT 運用チームとエンジニアリングチームは、迅速にエラー範囲の特定、対処の優先度付け、他の問題との切り分け、実際のユーザーに対する影響の測定を行うことができます。また、すべてのユーザー操作をビデオでリプレイしながらパフォーマンス指標と相関させることでエンドユーザー体験を最適化することができます。
メインメニューで RUM をクリックすると、RUM のメインとなるホーム画面、ランディングページに移動します。このページでは、選択したすべての RUM アプリケーション全体のステータスを一目で確認できることに主眼が置かれています。フルサイズ、あるいは、コンパクトビューのいずれかの形式で表示することができます。
Splunk APM は、NoSample™ で End to End ですべてのアプリケーションやその依存性に関する可視性を提供し、モノリシックアプリ、マイクロサービスの両方で問題をより迅速に解決することに寄与します。チームは新しいアプリケーションをデプロイした際にもすぐに問題に気づくことができます。また、問題の発生源を絞り込み、切り分けることでトラブルシューティングに自信を持って取り組むことができます。バックエンドサービスがエンドユーザーとビジネスワークフローに与える影響を理解することを通じて、サービスのパフォーマンスを最適化することができます。
リアルタイムモニタリングとアラート: Splunk は、すぐに利用可能なサービスダッシュボードを提供します。急激な変化があると RED メトリクス(処理量、エラー、遅延)に基づいて自動的に問題を検出・アラートを発します。
概要ページを下にスクロールすると、一部のサービスに Inferred Service が表示されることに気づくでしょう。
Splunk APM は、リモートサービスを呼び出すスパンに含まれる情報から、存在が推論されるサービス、つまり、Inferred Service を検出することができます。Inferred Service として検出されるサービスの例としては、データベース、HTTPエンドポイント、メッセージキューなどがあります。Inferred Service は計装されていませんが、サービスマップとサービスリストに表示されます。
フィルターパネル: 時間枠、index、および Field に基づいてログをフィルタリングすることができます。また、事前に保存しておいたクエリを利用することもできます。
Log table: 現在のフィルタ条件に一致するログエントリーのリスト。
Fields: 現在選択されている index で使用可能なフィールドのリスト。
Splunk index
一般的に、Splunk では「index」はデータが保存される指定された場所を指します。これはデータを格納するフォルダまたはコンテナのようなものです。 Splunk index 内のデータは検索と分析が容易になるように整理され構造化されています。異なるインデックスを作成して特定のタイプのデータを格納することができます。たとえば、Web サーバーログ用に1つの index、アプリケーションログ用に別の index を作成しておくようなことが可能です。
RUM トレース(フロントエンド)から APM トレース(バックエンド)にジャンプすることで、完全な End to End の可視性の力を理解できるでしょう。すべてのサービスが Splunk Observability Cloud によって視覚化、分析、異常およびエラーの検出が可能となるテレメトリ(トレースやスパン)を送信しています。
RUM と APM は同じコインの両側面です。RUM はアプリケーションのクライアント側のビューであり、APM はサーバー側のビューです。このセクションでは、APM を使用してどこに問題が潜んでいるかドリルダウンし、特定します。
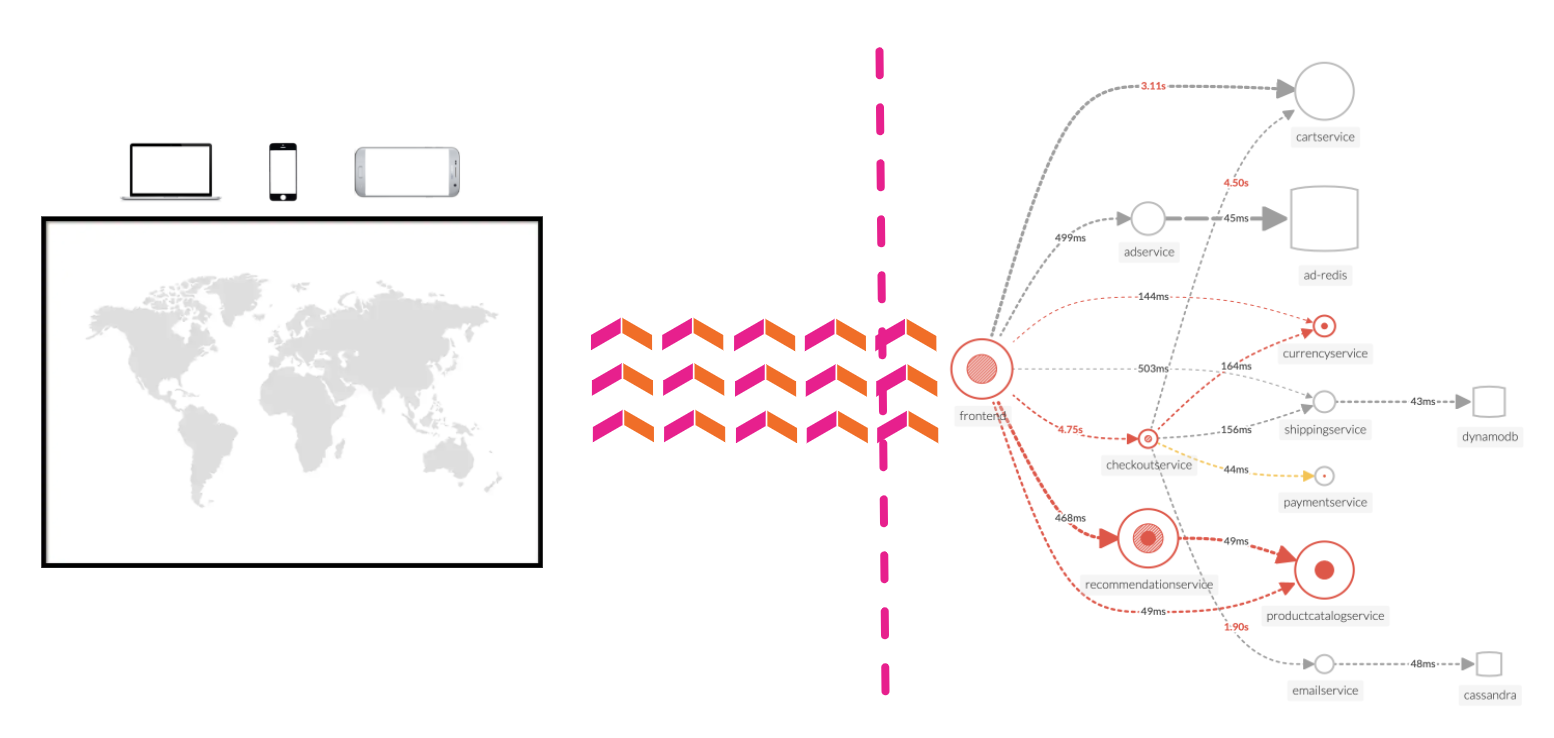
RUM ウォーターフォールで APM リンクをクリックすると、サービスマップビューに自動的にフィルタが追加され、その Workflow Name(frontend:/cart/checkout)に関与したサービスが表示されます。
Service Map でワークフローに関係するサービスが表示されます。画面右側の Business Workflow の下には、選択したワークフローのチャートが表示されます。Service Map と Business Workflow のチャートは同期されています。Service Map 内であるサービスを選択すると、Business Workflow ペインのチャートが更新され、選択したサービスのメトリクスが表示されます。
Splunk APM では、NoSample™ の End to End の可視性が提供され、すべてのサービスのトレースがキャプチャされます。このワークショップでは、Order Confirmation ID がタグとして利用可能です。これにより、ワークショップの前半で遭遇したユーザーエクスペリエンスの問題のトレースを正確に検索できます。
また、Splunkが提供する、アプリケーションの振る舞いのパターンを検出する Tag Spotlight によるインテリジェントなタグ付けと分析の機能や、問題のコンテキストを維持しながら異なるコンポーネント間を素早く移動する Related Contents によりスタック全体を相関させる機能についても、その使い方を理解したはずです。
Using ACCESS_TOKEN={REDACTED}
Using REALM=eu0
“splunk-otel-collector-chart” has been added to your repositories
Using ACCESS_TOKEN={REDACTED}
Using REALM=eu0
Hang tight while we grab the latest from your chart repositories…
…Successfully got an update from the “splunk-otel-collector-chart” chart repository
Update Complete. ⎈Happy Helming!⎈
Using ACCESS_TOKEN={REDACTED}
Using REALM=eu0
NAME: splunk-otel-collector
LAST DEPLOYED: Fri May 7 11:19:01 2021
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
約30秒程度待ってから kubectl get pods を実行すると、新しいポッドが稼働していることが報告され、デプロイメントの進捗を監視することができます。
続行する前に、ステータスがRunningと報告されていることを確認してください。
kubectl get pods
NAME READY STATUS RESTARTS AGE
splunk-otel-collector-agent-2sk6k 0/1 Running 0 10s
splunk-otel-collector-k8s-cluster-receiver-6956d4446f-gwnd7 0/1 Running 0 10s
YOUR_NAME を自分の名前に置き換えてから、編集権限をEveryone can Read or Write からRestricted Read and Write access に変更してみてください。
ここには、自分のログイン情報が表示されます。つまり、このダッシュボードを編集できるのは自分だけということになります。もちろん、ダッシュボードやチャートを編集できる他のユーザーやチームを下のドロップボックスから追加することもできますが、今回は、Everyone can Read or Write に 再設定 して制限を解除し、Save ボタンを押して続行してください。
これでチームダッシュボードに遷移します。ここでは、チーム Example Team を例にしていますが、ワークショップのものは異なります。
を押し、 Add Dashboard Group ボタンを押して、チームページにダッシュボードを追加します。
すると、 Select a dashboard group to link to this team ダイアログが表示されます。
検索ボックスにご自身のお名前(上記で使用したお名前)を入力して、ダッシュボードを探します。ダッシュボードがハイライトされるように選択し、Ok ボタンをクリックしてダッシュボードを追加します。
リンク: 外部の Web ページ (ドキュメントなど) や他の Splunk IM ダッシュボードへの直接リンクできます
以下は、ノートで使用できる上記のMarkdownオプションの例です。
# h1 Big headings
###### h6 To small headings
##### Emphasis
**This is bold text**, *This is italic text* , ~~Strikethrough~~##### Lists
Unordered
+ Create a list by starting a line with `+`, `-`, or `*`- Sub-lists are made by indenting 2 spaces:
- Marker character change forces new list start:
* Ac tristique libero volutpat at
+ Facilisis in pretium nisl aliquet
* Very easy!
Ordered
1. Lorem ipsum dolor sit amet
2. Consectetur adipiscing elit
3. Integer molestie lorem at massa
##### Tables
| Option | Description |
| ------ | ----------- |
| chart | path to data files to supply the data that will be passed into templates. |
| engine | engine to be used for processing templates. Handlebars is the default. |
| ext | extension to be used for dest files. |
#### Links
[link to webpage](https://www.splunk.com)
[link to dashboard with title](https://app.eu0.signalfx.com/#/dashboard/EaJHrbPAEAA?groupId=EaJHgrsAIAA&configId=EaJHsHzAEAA "Link to the Sample chart Dashboard!")
Upgrading modules...
- aws in modules/aws
- azure in modules/azure
- docker in modules/docker
- gcp in modules/gcp
- host in modules/host
- kafka in modules/kafka
- kubernetes in modules/kubernetes
- parent_child_dashboard in modules/dashboards/parent
- pivotal in modules/pivotal
- rum_and_synthetics_dashboard in modules/dashboards/rum_and_synthetics
- usage_dashboard in modules/dashboards/usage
Initializing the backend...
Initializing provider plugins...
- Finding latest version of splunk-terraform/signalfx...
- Installing splunk-terraform/signalfx v6.20.0...
- Installed splunk-terraform/signalfx v6.20.0 (self-signed, key ID CE97B6074989F138)
Partner and community providers are signed by their developers.
If you'd like to know more about provider signing, you can read about it here:
https://www.terraform.io/docs/cli/plugins/signing.html
Terraform has created a lock file .terraform.lock.hcl to record the provider
selections it made above. Include this file in your version control repository
so that Terraform can guarantee to make the same selections by default when
you run "terraform init" in the future.
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
2. プランの作成
terraform plan コマンドで、実行計画を作成します。デフォルトでは、プランの作成は以下のように構成されています。
cd ~/workshop/apm
kubectl apply -f deployment.yaml
APM Only Deployment
deployment.apps/recommendationservice created
service/recommendationservice created
deployment.apps/productcatalogservice created
service/productcatalogservice created
deployment.apps/cartservice created
service/cartservice created
deployment.apps/adservice created
service/adservice created
deployment.apps/paymentservice created
service/paymentservice created
deployment.apps/loadgenerator created
service/loadgenerator created
deployment.apps/shippingservice created
service/shippingservice created
deployment.apps/currencyservice created
service/currencyservice created
deployment.apps/redis-cart created
service/redis-cart created
deployment.apps/checkoutservice created
service/checkoutservice created
deployment.apps/frontend created
service/frontend created
service/frontend-external created
deployment.apps/emailservice created
service/emailservice created
deployment.apps/rum-loadgen-deployment created
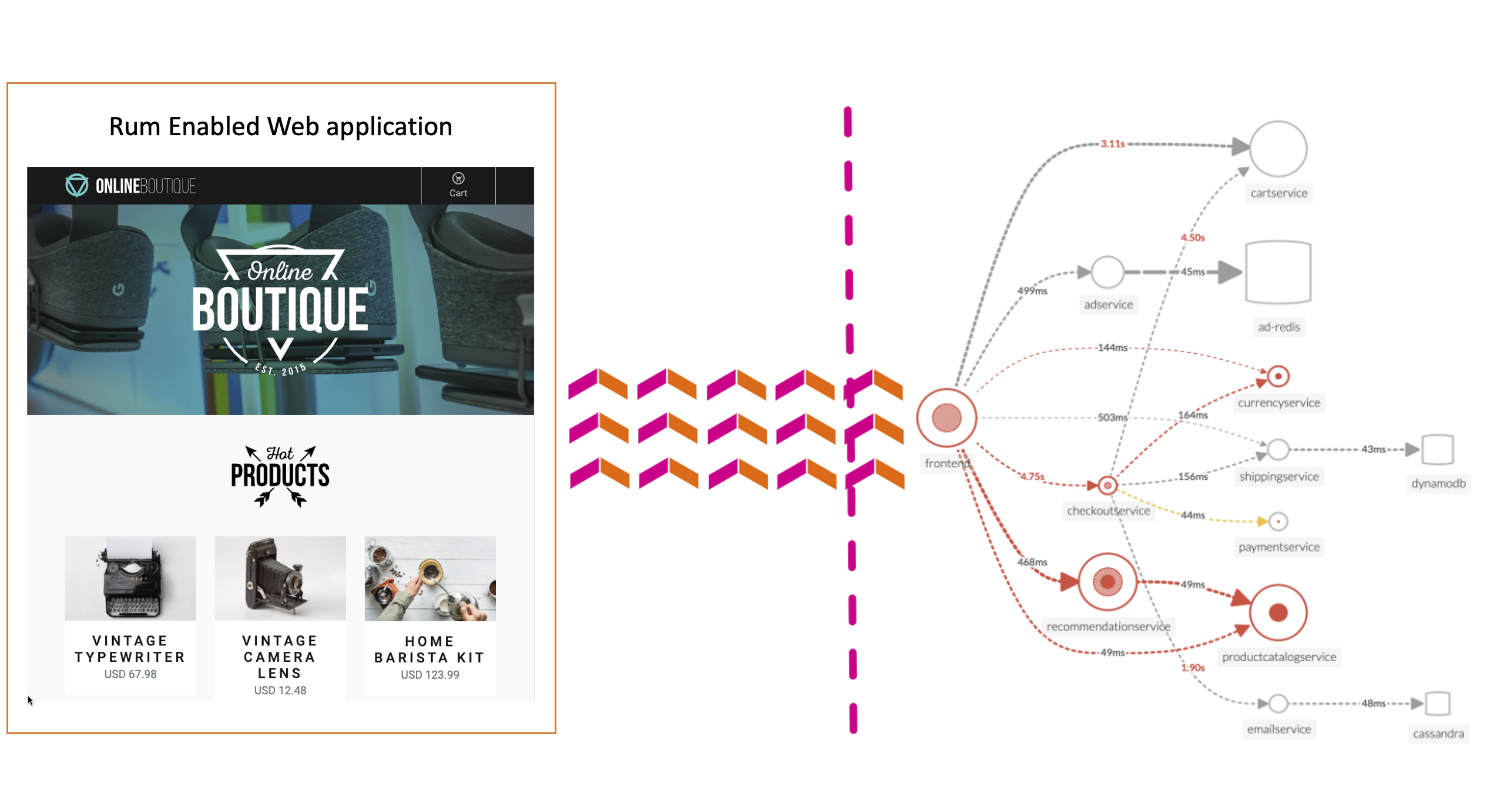
右上にある「Services by Error Rate」グラフのピンク色の線上をクリックします。選択すると、サンプルトレースのリストが表示されます。Initiating Operation ofが frontend: POST /cart/checkout であるサンプルトレースの1つをクリックしてください。
Splunk RUM は、業界唯一のエンド・ツー・エンドで完全忠実なリアルユーザーモニタリングソリューションです。パフォーマンスを最適化し、トラブルシューティングを迅速に行い、エンドユーザーエクスペリエンスを完全に可視化するために構築されています。
Splunk RUM は、ユーザーエクスペリエンスに影響を与える Web およびモバイルアプリケーションのパフォーマンス問題を特定することができます。Core Web Vitalによるページパフォーマンスのベンチマークと計測をサポートします。W3C タイミング、長時間実行されるタスクの特定、ページロードに影響を与える可能性のあるあらゆるものが含まれますが、これらに限定されるものではありません。
フロントエンドとバックエンドのアプリケーションのパフォーマンスは相互に依存していることがよくあります。バックエンドサービスとユーザーエクスペリエンスとの関連性を十分に理解し、可視化できることがますます重要になっています。
全体像を把握するために、Splunk RUM は当社のフロントエンドとバックエンドのマイクロサービス間のシームレスな相関関係を提供します。マイクロサービスやインフラストラクチャに関連する問題によって、ユーザーが Web ベースのアプリケーションで最適とは言えない状態を経験している場合、Splunk はこの問題を検出して警告することができます。
RUM ユーザーセッションは、アプリケーション上でのユーザーインタラクションの「記録」であり、基本的にはエンドユーザーのブラウザまたはモバイルアプリケーションから直接測定されたウェブサイトまたはアプリケーションのパフォーマンスを収集します。これを行うために、各ページに数行のJavaScriptが埋め込まれています。このスクリプトは、各ユーザーがページを探索する際にデータを収集し、解析のためにそのデータを転送します。 ↩︎↩︎
cd ~/workshop/apm
kubectl delete -f deployment.yaml
kubectl apply -f deployment.yaml
......
Adding RUM_TOKEN to deployment
deployment.apps/recommendationservice created
service/recommendationservice created
deployment.apps/productcatalogservice created
service/productcatalogservice created
deployment.apps/cartservice created
service/cartservice created
deployment.apps/adservice created
service/adservice created
deployment.apps/paymentservice created
service/paymentservice created
deployment.apps/loadgenerator created
service/loadgenerator created
deployment.apps/shippingservice created
service/shippingservice created
deployment.apps/currencyservice created
service/currencyservice created
deployment.apps/redis-cart created
service/redis-cart created
deployment.apps/checkoutservice created
service/checkoutservice created
deployment.apps/frontend created
service/frontend created
service/frontend-external created
deployment.apps/emailservice created
service/emailservice created
deployment.apps/rum-loadgen-deployment created
cd ~/workshop/apm
kubectl apply -f deployment.yaml
deployment.apps/checkoutservice created
service/checkoutservice created
deployment.apps/redis-cart created
service/redis-cart created
deployment.apps/productcatalogservice created
service/productcatalogservice created
deployment.apps/loadgenerator created
service/loadgenerator created
deployment.apps/frontend created
service/frontend created
service/frontend-external created
deployment.apps/paymentservice created
service/paymentservice created
deployment.apps/emailservice created
service/emailservice created
deployment.apps/adservice created
service/adservice created
deployment.apps/cartservice created
service/cartservice created
deployment.apps/recommendationservice created
service/recommendationservice created
deployment.apps/shippingservice created
service/shippingservice created
deployment.apps/currencyservice created
service/currencyservice created
Internet Explorer 11 をお使いの場合、この演習では Web/RUM 用のSplunk Open Telemetry JavaScriptの特定のバージョンが必要になるため、問題が発生する可能性があります。
ただし、Online Boutiqueサイトを右クリックすると、「ソースを表示」 のオプションが表示され、必要な変更を確認することができます。
ご覧の通り、当サイトは3つのメトリクスすべてで Good スコアを獲得し、良好な動作をしています。これらのメトリクスは、アプリケーションの変更がもたらす影響を特定し、サイトのパフォーマンスを向上させるために使用することができます。
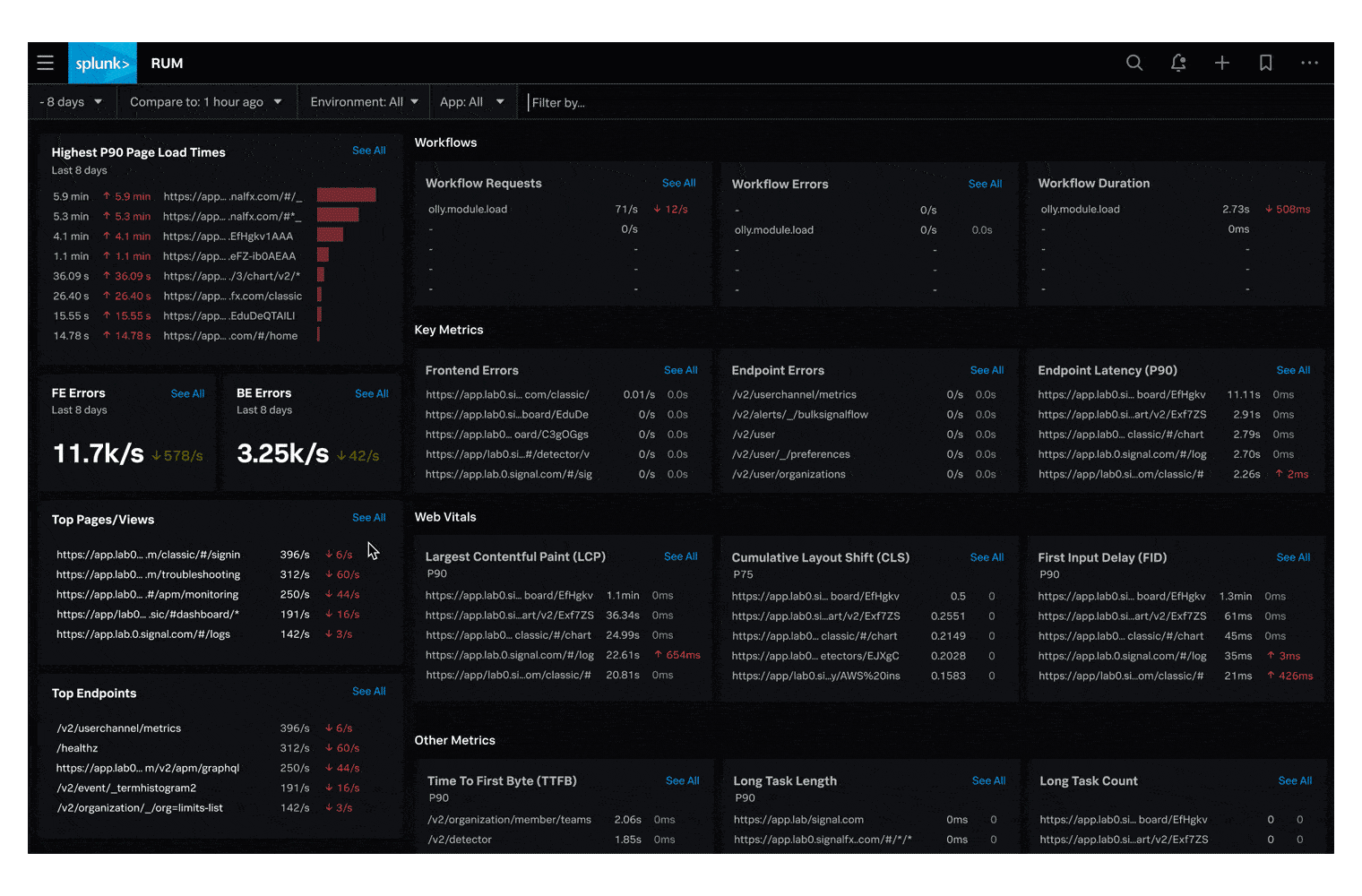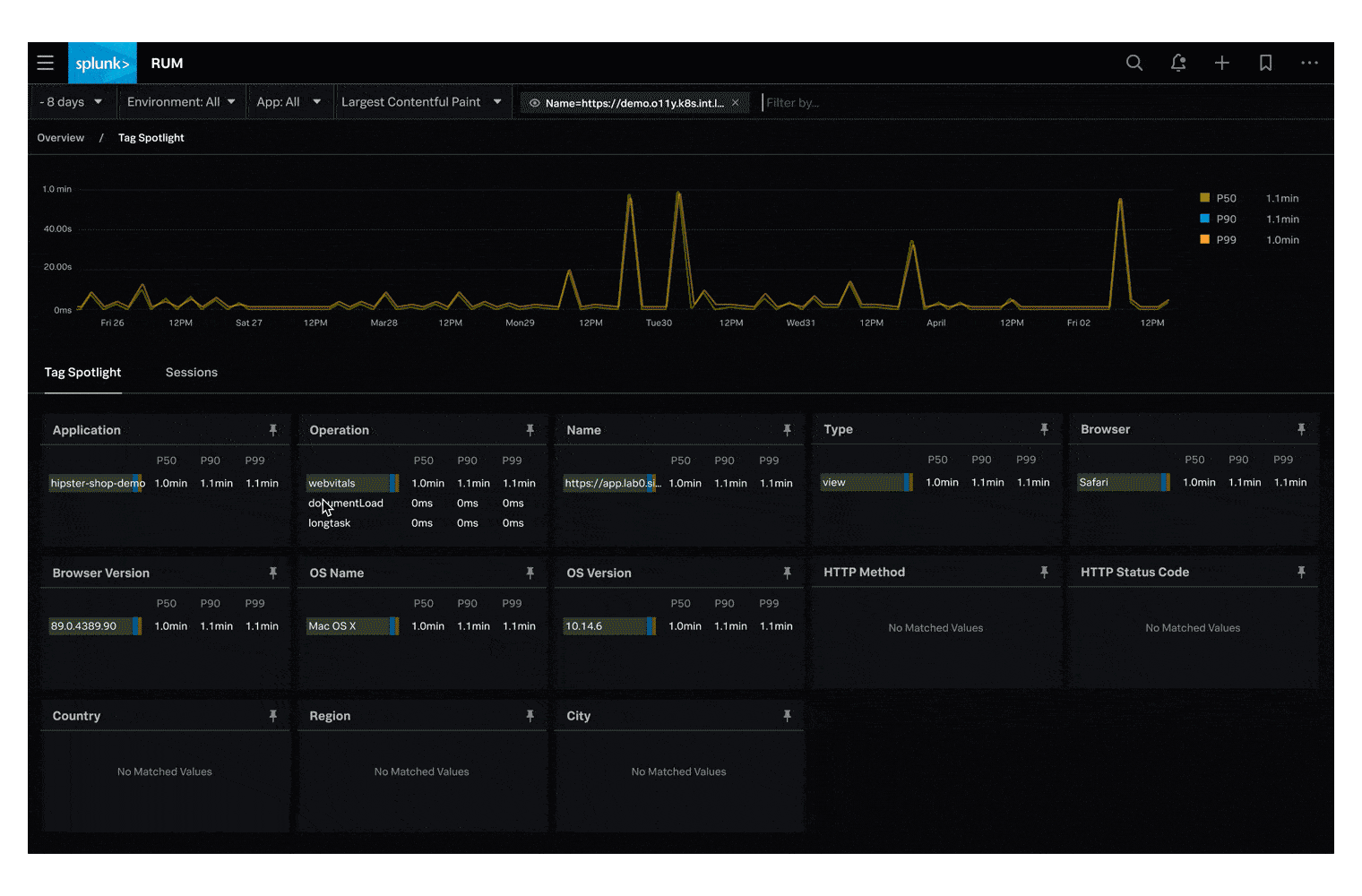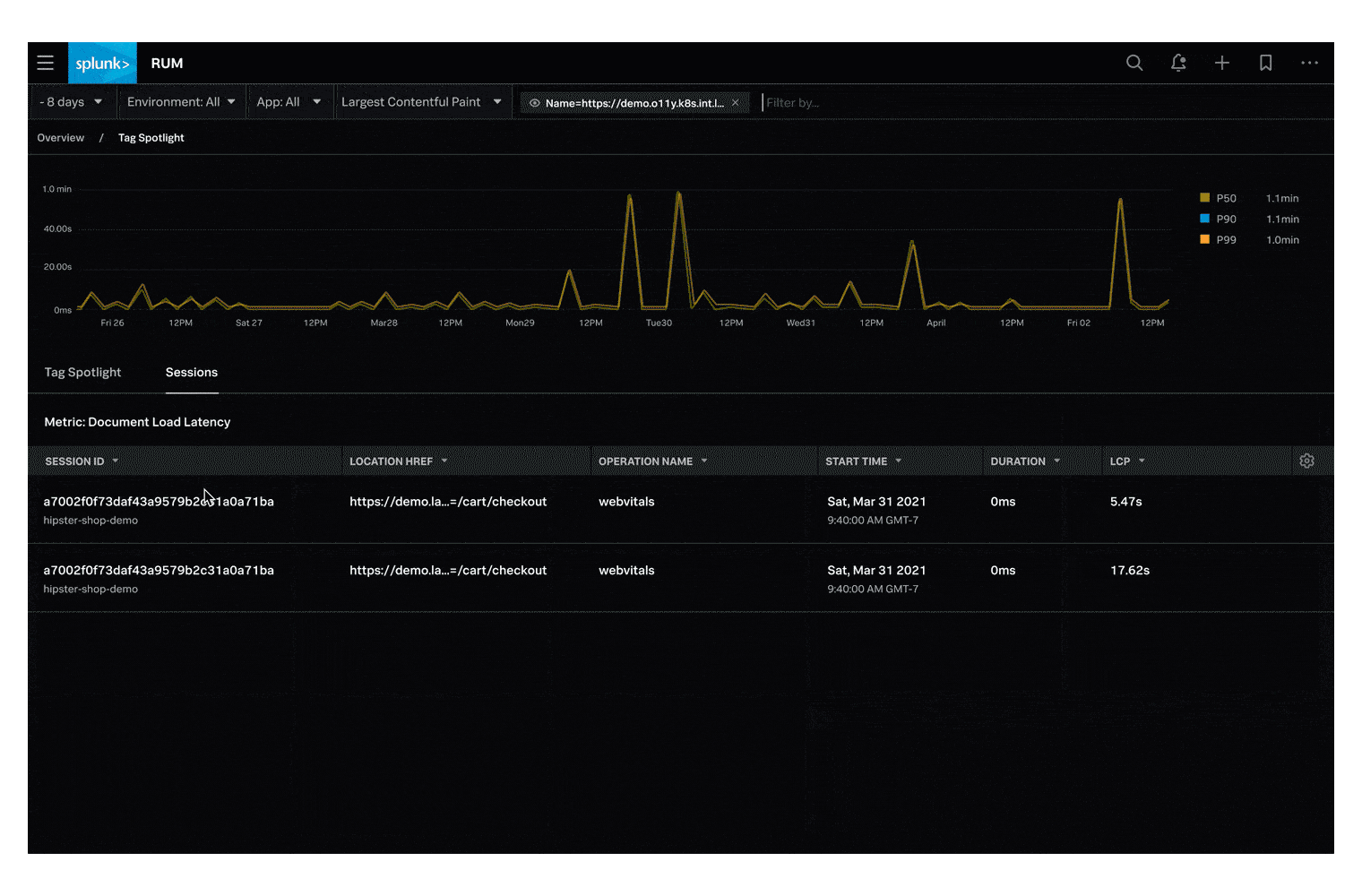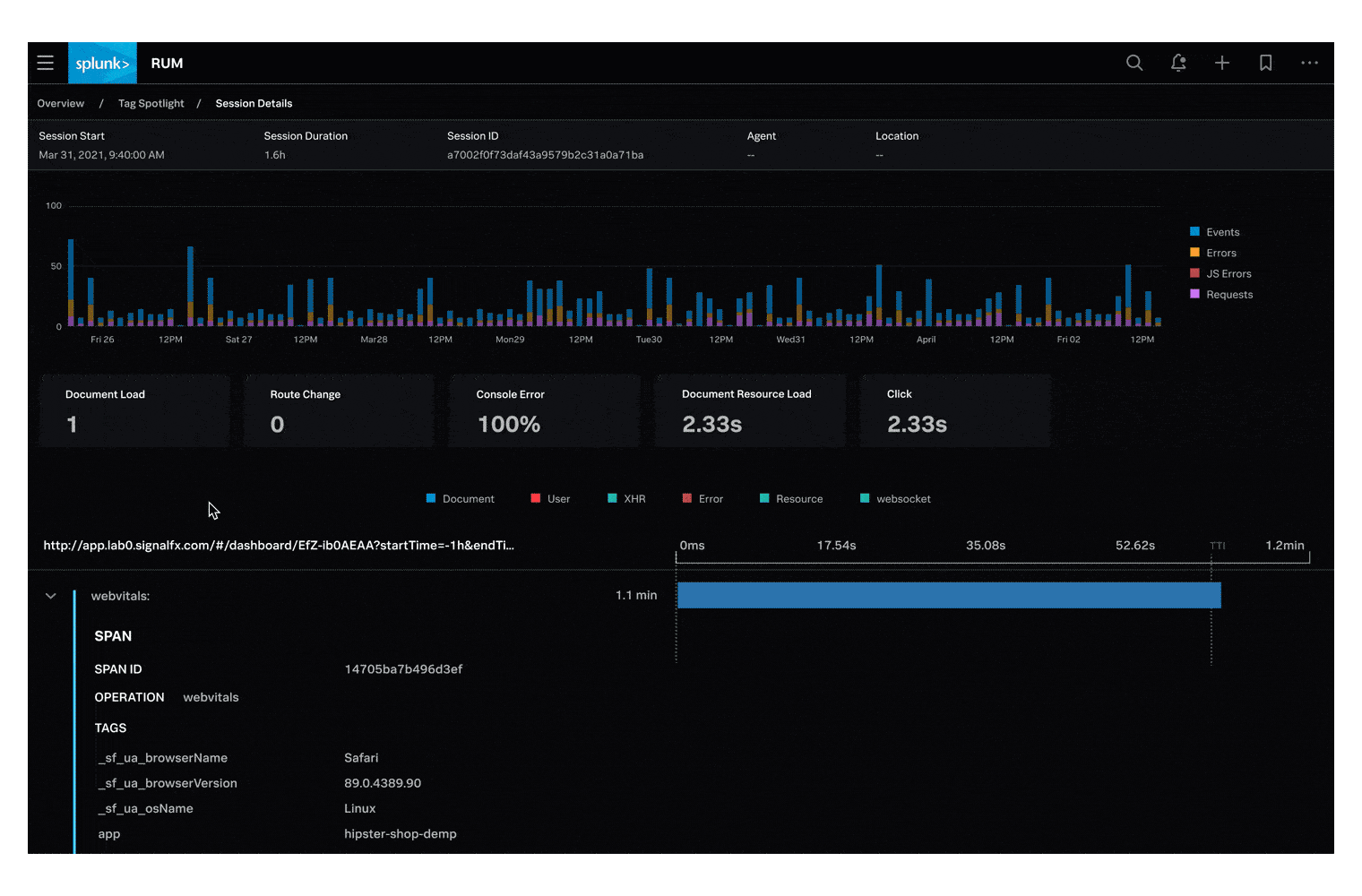
Web Vitalsペインに表示されているメトリクスをクリックすると、対応する Tag Spotlight ダッシュボードに移動します。例えば Largest Contentful Paint (LCP) をクリックすると、以下のスクリーンショットのようなダッシュボードが表示され、このメトリクスのパフォーマンスに関するタイムラインとテーブルビューを見ることができます。これにより、OS やブラウザーのバージョンなど、より一般的な問題の傾向を把握することができます。
Web Vitalsペインは、Web Vitalのメトリクスに基づいてエンドユーザーに提供しているエクスペリエンスに関する洞察を得たい場合に使用する場所です。
Web Vitalは、ウェブ上で優れたユーザーエクスペリエンスを提供するために不可欠な品質シグナルの統一ガイダンスを提供するGoogleのイニシアチブであり、3つの主要なパラメーターに焦点を当てています。
Largest Contentful Paint (LCP) (最大コンテンツの描画):読み込みのパフォーマンスを測定するものです。良いユーザーエクスペリエンスを提供するために、LCPはページが読み込まれてから2.5秒以内に発生する必要があります。
First Input Delay (FID) (初回入力までの遅延時間):インタラクティブ性を評価するものです。良いユーザーエクスペリエンスを提供するために、ページのFIDは100ミリ秒以下であるべきです。
Tag Spotlightは、チャートビューで異常値を確認したり、タグで問題を特定するのに役立つように設計されています。
Document Load Latency ビューで、Browser 、 Browser Version 、 OS Name タグビューを見ると、様々なブラウザーの種類とバージョン、そして基盤となるOSを確認することができます。
これにより、特定のブラウザやOSのバージョンに関連する問題が強調表示されるため、特定が容易になります。
Real User Monitoring (RUM)計装のために、Open Telemetry Javascript https://github.com/signalfx/splunk-otel-js-web スニペットをページ内に追加します。再度ウィザードを使用します Data Management → Add Integrationボタン → Monitor user experience(画面上部タブ) → Browser Instrumentationを開きます。
ドロップダウンから設定済みの RUM ACCESS TOKEN を選択し、Next をクリックします。以下の構文で App name とEnvironment を入力します:
次に、ワークショップのRUMトークンを選択し、 App nameとEnvironmentを定義します。ウィザードでは、ページ上部の <head> セクションに配置する必要のある HTML コードの断片が表示されます。この例では、次のように記述していますが、ウィザードでは先程入力した値が反映されてるはずです。
Alt-U で、アンドゥができます。Macの場合は Esc キーを押したあとに U を押してください!
ctrl-_ のあとに数字を入力すると、指定した行数にジャンプします。
ctrl-O のあとに Enter で、ファイルを保存します。
ctrl-X で、nanoを終了します。
receivers:hostmetrics:collection_interval:10sscrapers:# CPU utilization metricscpu:# Disk I/O metricsdisk:# File System utilization metricsfilesystem:# Memory utilization metricsmemory:# Network interface I/O metrics & TCP connection metricsnetwork:# CPU load metricsload:# Paging/Swap space utilization and I/O metricspaging:# Process count metricsprocesses:# Per process CPU, Memory and Disk I/O metrics. Disabled by default.# process:
extensions:health_check:endpoint:0.0.0.0:13133pprof:endpoint:0.0.0.0:1777zpages:endpoint:0.0.0.0:55679receivers:hostmetrics:collection_interval:10sscrapers:# CPU utilization metricscpu:# Disk I/O metricsdisk:# File System utilization metricsfilesystem:# Memory utilization metricsmemory:# Network interface I/O metrics & TCP connection metricsnetwork:# CPU load metricsload:# Paging/Swap space utilization and I/O metricspaging:# Process count metricsprocesses:# Per process CPU, Memory and Disk I/O metrics. Disabled by default.# process:otlp:protocols:grpc:http:opencensus:# Collect own metricsprometheus/internal:config:scrape_configs:- job_name:'otel-collector'scrape_interval:10sstatic_configs:- targets:['0.0.0.0:8888']jaeger:protocols:grpc:thrift_binary:thrift_compact:thrift_http:zipkin:processors:batch:exporters:logging:verbosity:detailedservice:pipelines:traces:receivers:[otlp, opencensus, jaeger, zipkin]processors:[batch]exporters:[logging]metrics:receivers:[otlp, opencensus, prometheus/internal]processors:[batch]exporters:[logging]extensions:[health_check, pprof, zpages]
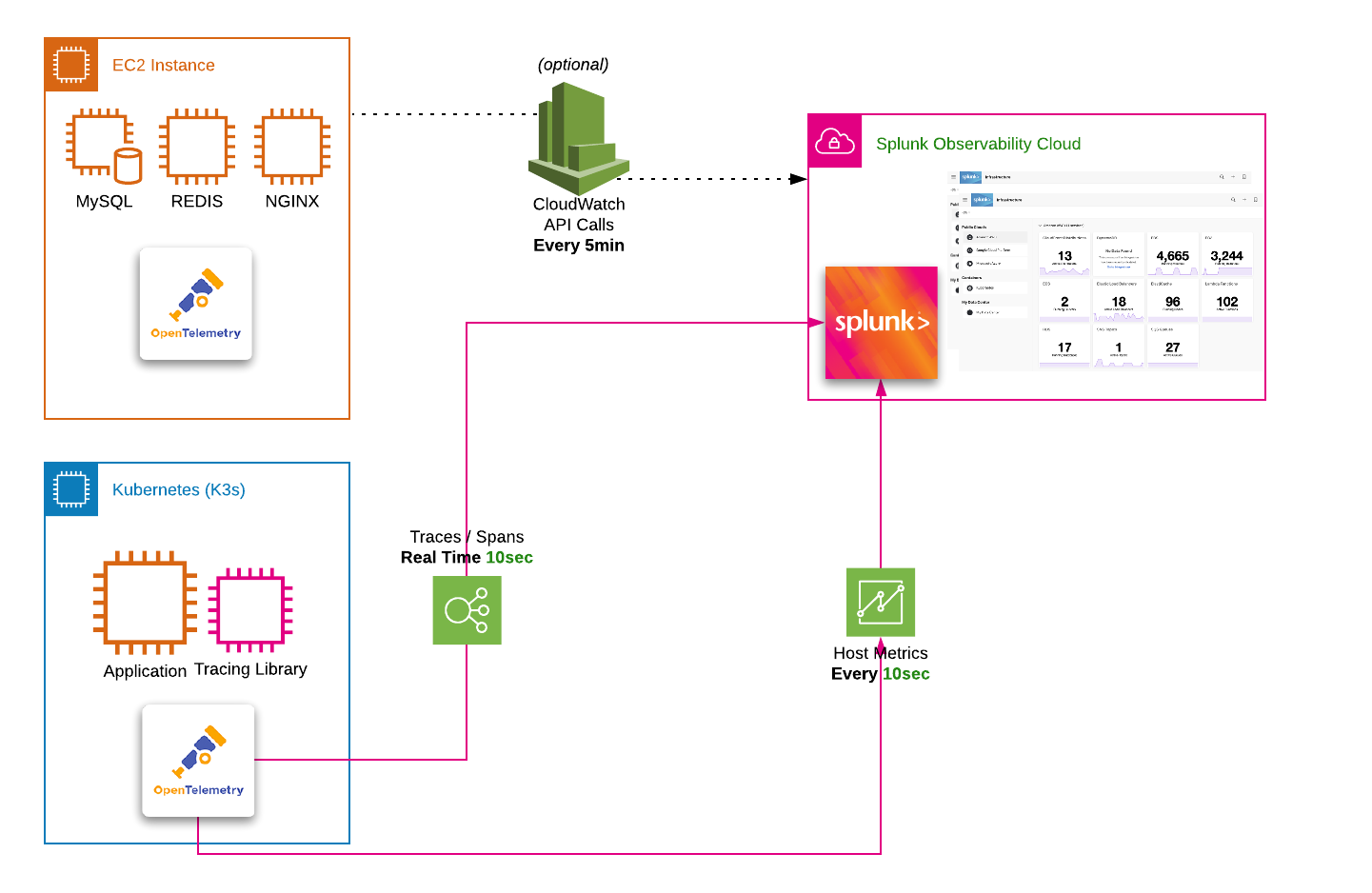
If the workshop instance is running on an AWS/EC2 instance we can gather the following tags from the EC2 metadata API (this is not available on other platforms).
ワークショップのインスタンスが AWS/EC2 インスタンスで実行されている場合、EC2 のメタデータ API から以下のタグを収集します(これは他のプラットフォームでは利用できないものもあります)。
extensions:health_check:endpoint:0.0.0.0:13133pprof:endpoint:0.0.0.0:1777zpages:endpoint:0.0.0.0:55679receivers:hostmetrics:collection_interval:10sscrapers:# CPU utilization metricscpu:# Disk I/O metricsdisk:# File System utilization metricsfilesystem:# Memory utilization metricsmemory:# Network interface I/O metrics & TCP connection metricsnetwork:# CPU load metricsload:# Paging/Swap space utilization and I/O metricspaging:# Process count metricsprocesses:# Per process CPU, Memory and Disk I/O metrics. Disabled by default.# process:otlp:protocols:grpc:http:opencensus:# Collect own metricsprometheus/internal:config:scrape_configs:- job_name:'otel-collector'scrape_interval:10sstatic_configs:- targets:['0.0.0.0:8888']jaeger:protocols:grpc:thrift_binary:thrift_compact:thrift_http:zipkin:processors:batch:resourcedetection/system:detectors:[system]system:hostname_sources:[os]resourcedetection/ec2:detectors:[ec2]attributes/conf:actions:- key:participant.nameaction:insertvalue:"INSERT_YOUR_NAME_HERE"exporters:logging:verbosity:detailedservice:pipelines:traces:receivers:[otlp, opencensus, jaeger, zipkin]processors:[batch]exporters:[logging]metrics:receivers:[otlp, opencensus, prometheus]processors:[batch]exporters:[logging]extensions:[health_check, pprof, zpages]
extensions:health_check:endpoint:0.0.0.0:13133pprof:endpoint:0.0.0.0:1777zpages:endpoint:0.0.0.0:55679receivers:hostmetrics:collection_interval:10sscrapers:# CPU utilization metricscpu:# Disk I/O metricsdisk:# File System utilization metricsfilesystem:# Memory utilization metricsmemory:# Network interface I/O metrics & TCP connection metricsnetwork:# CPU load metricsload:# Paging/Swap space utilization and I/O metricspaging:# Process count metricsprocesses:# Per process CPU, Memory and Disk I/O metrics. Disabled by default.# process:otlp:protocols:grpc:http:opencensus:# Collect own metricsprometheus/internal:config:scrape_configs:- job_name:'otel-collector'scrape_interval:10sstatic_configs:- targets:['0.0.0.0:8888']jaeger:protocols:grpc:thrift_binary:thrift_compact:thrift_http:zipkin:processors:batch:resourcedetection/system:detectors:[system]system:hostname_sources:[os]resourcedetection/ec2:detectors:[ec2]attributes/conf:actions:- key:participant.nameaction:insertvalue:"INSERT_YOUR_NAME_HERE"exporters:logging:verbosity:normalotlphttp/splunk:metrics_endpoint:https://ingest.${env:REALM}.signalfx.com/v2/datapoint/otlpheaders:X-SF-TOKEN:${env:ACCESS_TOKEN}service:pipelines:traces:receivers:[otlp, opencensus, jaeger, zipkin]processors:[batch]exporters:[logging]metrics:receivers:[otlp, opencensus, prometheus]processors:[batch]exporters:[logging]extensions:[health_check, pprof, zpages]
service:telemetry:logs:level:<info|warn|error>development:<true|false>encoding:<console|json>disable_caller:<true|false>disable_stacktrace:<true|false>output_paths:[<stdout|stderr>, paths...]error_output_paths:[<stdout|stderr>, paths...]initial_fields:key:valuemetrics:level:<none|basic|normal|detailed># Address binds the promethues endpoint to scrapeaddress:<hostname:port>
extensions:health_check:endpoint:0.0.0.0:13133pprof:endpoint:0.0.0.0:1777zpages:endpoint:0.0.0.0:55679receivers:hostmetrics:collection_interval:10sscrapers:# CPU utilization metricscpu:# Disk I/O metricsdisk:# File System utilization metricsfilesystem:# Memory utilization metricsmemory:# Network interface I/O metrics & TCP connection metricsnetwork:# CPU load metricsload:# Paging/Swap space utilization and I/O metricspaging:# Process count metricsprocesses:# Per process CPU, Memory and Disk I/O metrics. Disabled by default.# process:otlp:protocols:grpc:http:opencensus:# Collect own metricsprometheus/internal:config:scrape_configs:- job_name:'otel-collector'scrape_interval:10sstatic_configs:- targets:['0.0.0.0:8888']jaeger:protocols:grpc:thrift_binary:thrift_compact:thrift_http:zipkin:processors:batch:resourcedetection/system:detectors:[system]system:hostname_sources:[os]resourcedetection/ec2:detectors:[ec2]attributes/conf:actions:- key:participant.nameaction:insertvalue:"INSERT_YOUR_NAME_HERE"exporters:logging:verbosity:normalotlphttp/splunk:metrics_endpoint:https://ingest.${env:REALM}.signalfx.com/v2/datapoint/otlpheaders:X-SF-TOKEN:${env:ACCESS_TOKEN}service:pipelines:traces:receivers:[otlp, opencensus, jaeger, zipkin]processors:[batch]exporters:[logging]metrics:receivers:[hostmetrics, otlp, opencensus, prometheus/internal]processors:[batch, resourcedetection/system, resourcedetection/ec2, attributes/conf] exporters:[logging, otlphttp/splunk]extensions:[health_check, pprof, zpages]
これらの指標は Google の DevOps Research and Assessment (DORA) チームによって特定されたもので、ソフトウェア開発チームのパフォーマンスを示すのに役立ちます。Jenkins CI を選択した理由は、私たちが同じオープンソースソフトウェアエコシステムに留まり、将来的にベンダー管理のCIツールが採用する例となることができるためです。
packagejenkinscireceiverimport("go.opentelemetry.io/collector/config/confighttp""go.opentelemetry.io/collector/receiver/scraperhelper""splunk.conf/workshop/example/jenkinscireceiver/internal/metadata")typeConfigstruct{// HTTPClientSettings contains all the values
// that are commonly shared across all HTTP interactions
// performed by the collector.
confighttp.HTTPClientSettings`mapstructure:",squash"`// ScraperControllerSettings will allow us to schedule
// how often to check for updates to builds.
scraperhelper.ScraperControllerSettings`mapstructure:",squash"`// MetricsBuilderConfig contains all the metrics
// that can be configured.
metadata.MetricsBuilderConfig`mapstructure:",squash"`}
---# Type defines the name to reference the component# in the configuration filetype:jenkins# Status defines the component type and the stability levelstatus:class:receiverstability:development:[metrics]# Attributes are the expected fields reported# with the exported values.attributes:job.name:description:The name of the associated Jenkins jobtype:stringjob.status:description:Shows if the job had passed, or failedtype:stringenum:- failed- success- unknown# Metrics defines all the pontentially exported values from this receiver. metrics:jenkins.jobs.count:enabled:truedescription:Provides a count of the total number of configured jobsunit:"{Count}"gauge:value_type:intjenkins.job.duration:enabled:truedescription:Show the duration of the jobunit:"s"gauge:value_type:intattributes:- job.name- job.statusjenkins.job.commit_delta:enabled:truedescription:The calculation difference of the time job was finished minus commit timestampunit:"s"gauge:value_type:intattributes:- job.name- job.status
// To generate the additional code needed to capture metrics,
// the following command to be run from the shell:
// go generate -x ./...
//go:generate go run github.com/open-telemetry/opentelemetry-collector-contrib/cmd/mdatagen@v0.80.0 metadata.yaml
packagejenkinscireceiver// There is no code defined within this file.
コマンド go generate -x ./... を実行すると、定義されたメトリクスをエクスポートするために必要なすべてのコードを含む新しいフォルダ jenkinscireceiver/internal/metadata が作成されます。生成されるコードは以下の通りです:
packagejenkinscireceiverimport("errors""go.opentelemetry.io/collector/component""go.opentelemetry.io/collector/config/confighttp""go.opentelemetry.io/collector/receiver""go.opentelemetry.io/collector/receiver/scraperhelper""splunk.conf/workshop/example/jenkinscireceiver/internal/metadata")funcNewFactory()receiver.Factory{returnreceiver.NewFactory(metadata.Type,newDefaultConfig,receiver.WithMetrics(newMetricsReceiver,metadata.MetricsStability),)}funcnewMetricsReceiver(_context.Context,setreceiver.CreateSettings,cfgcomponent.Config,consumerconsumer.Metrics)(receiver.Metrics,error){// Convert the configuration into the expected type
conf,ok:=cfg.(*Config)if!ok{returnnil,errors.New("can not convert config")}sc,err:=newScraper(conf,set)iferr!=nil{returnnil,err}returnscraperhelper.NewScraperControllerReceiver(&conf.ScraperControllerSettings,set,consumer,scraperhelper.AddScraper(sc),)}
packagejenkinscireceiverimport("go.opentelemetry.io/collector/config/confighttp""go.opentelemetry.io/collector/receiver/scraperhelper""splunk.conf/workshop/example/jenkinscireceiver/internal/metadata")typeConfigstruct{// HTTPClientSettings contains all the values
// that are commonly shared across all HTTP interactions
// performed by the collector.
confighttp.HTTPClientSettings`mapstructure:",squash"`// ScraperControllerSettings will allow us to schedule
// how often to check for updates to builds.
scraperhelper.ScraperControllerSettings`mapstructure:",squash"`// MetricsBuilderConfig contains all the metrics
// that can be configured.
metadata.MetricsBuilderConfig`mapstructure:",squash"`}funcnewDefaultConfig()component.Config{return&Config{ScraperControllerSettings:scraperhelper.NewDefaultScraperControllerSettings(metadata.Type),HTTPClientSettings:confighttp.NewDefaultHTTPClientSettings(),MetricsBuilderConfig:metadata.DefaultMetricsBuilderConfig(),}}
packagejenkinscireceivertypescraperstruct{}funcnewScraper(cfg*Config,setreceiver.CreateSettings)(scraperhelper.Scraper,error){// Create a our scraper with our values
s:=scraper{// To be filled in later
}returnscraperhelper.NewScraper(metadata.Type,s.scrape)}func(scraper)scrape(ctxcontext.Context)(pmetric.Metrics,error){// To be filled in
returnpmetrics.NewMetrics(),nil}
---dist:name:otelcoldescription:"Conf workshop collector"output_path:./distversion:v0.0.0-experimentalextensions:- gomod:github.com/open-telemetry/opentelemetry-collector-contrib/extension/basicauthextension v0.80.0- gomod:github.com/open-telemetry/opentelemetry-collector-contrib/extension/healthcheckextension v0.80.0receivers:- gomod:go.opentelemetry.io/collector/receiver/otlpreceiver v0.80.0- gomod:github.com/open-telemetry/opentelemetry-collector-contrib/receiver/jaegerreceiver v0.80.0- gomod:github.com/open-telemetry/opentelemetry-collector-contrib/receiver/prometheusreceiver v0.80.0- gomod:splunk.conf/workshop/example/jenkinscireceiver v0.0.0path:./jenkinscireceiverprocessors:- gomod:go.opentelemetry.io/collector/processor/batchprocessor v0.80.0exporters:- gomod:go.opentelemetry.io/collector/exporter/loggingexporter v0.80.0- gomod:go.opentelemetry.io/collector/exporter/otlpexporter v0.80.0- gomod:go.opentelemetry.io/collector/exporter/otlphttpexporter v0.80.0# This replace is a go directive that allows for redefine# where to fetch the code to use since the default would be from a remote project.replaces:- splunk.conf/workshop/example/jenkinscireceiver => ./jenkinscireceiver
packagejenkinscireceiverimport("context"jenkins"github.com/yosida95/golang-jenkins""go.opentelemetry.io/collector/component""go.opentelemetry.io/collector/pdata/pmetric""go.opentelemetry.io/collector/receiver""go.opentelemetry.io/collector/receiver/scraperhelper""splunk.conf/workshop/example/jenkinscireceiver/internal/metadata")typescraperstruct{mb*metadata.MetricsBuilderclient*jenkins.Jenkins}funcnewScraper(cfg*Config,setreceiver.CreateSettings)(scraperhelper.Scraper,error){s:=&scraper{mb:metadata.NewMetricsBuilder(cfg.MetricsBuilderConfig,set),}returnscraperhelper.NewScraper(metadata.Type,s.scrape,scraperhelper.WithStart(func(ctxcontext.Context,hcomponent.Host)error{client,err:=cfg.ToClient(h,set.TelemetrySettings)iferr!=nil{returnerr}// The collector provides a means of injecting authentication
// on our behalf, so this will ignore the libraries approach
// and use the configured http client with authentication.
s.client=jenkins.NewJenkins(nil,cfg.Endpoint)s.client.SetHTTPClient(client)returnnil}),)}func(sscraper)scrape(ctxcontext.Context)(pmetric.Metrics,error){// To be filled in
returnpmetric.NewMetrics(),nil}
func(sscraper)scrape(ctxcontext.Context)(pmetric.Metrics,error){jobs,err:=s.client.GetJobs()iferr!=nil{returnpmetric.Metrics{},err}// Recording the timestamp to ensure
// all captured data points within this scrape have the same value.
now:=pcommon.NewTimestampFromTime(time.Now())// Casting to an int64 to match the expected type
s.mb.RecordJenkinsJobsCountDataPoint(now,int64(len(jobs)))// To be filled in
returns.mb.Emit(),nil}
func(sscraper)scrape(ctxcontext.Context)(pmetric.Metrics,error){jobs,err:=s.client.GetJobs()iferr!=nil{returnpmetric.Metrics{},err}// Recording the timestamp to ensure
// all captured data points within this scrape have the same value.
now:=pcommon.NewTimestampFromTime(time.Now())// Casting to an int64 to match the expected type
s.mb.RecordJenkinsJobsCountDataPoint(now,int64(len(jobs)))for_,job:=rangejobs{// Ensure we have valid results to start off with
var(build=job.LastCompletedBuildstatus=metadata.AttributeJobStatusUnknown)// This will check the result of the job, however,
// since the only defined attributes are
// `success`, `failure`, and `unknown`.
// it is assume that anything did not finish
// with a success or failure to be an unknown status.
switchbuild.Result{case"aborted","not_built","unstable":status=metadata.AttributeJobStatusUnknowncase"success":status=metadata.AttributeJobStatusSuccesscase"failure":status=metadata.AttributeJobStatusFailed}s.mb.RecordJenkinsJobDurationDataPoint(now,int64(job.LastCompletedBuild.Duration),job.Name,status,)}returns.mb.Emit(),nil}
func(sscraper)scrape(ctxcontext.Context)(pmetric.Metrics,error){jobs,err:=s.client.GetJobs()iferr!=nil{returnpmetric.Metrics{},err}// Recording the timestamp to ensure
// all captured data points within this scrape have the same value.
now:=pcommon.NewTimestampFromTime(time.Now())// Casting to an int64 to match the expected type
s.mb.RecordJenkinsJobsCountDataPoint(now,int64(len(jobs)))for_,job:=rangejobs{// Ensure we have valid results to start off with
var(build=job.LastCompletedBuildstatus=metadata.AttributeJobStatusUnknown)// Previous step here
// Ensure that the `ChangeSet` has values
// set so there is a valid value for us to reference
iflen(build.ChangeSet.Items)==0{continue}// Making the assumption that the first changeset
// item is the most recent change.
change:=build.ChangeSet.Items[0]// Record the difference from the build time
// compared against the change timestamp.
s.mb.RecordJenkinsJobCommitDeltaDataPoint(now,int64(build.Timestamp-change.Timestamp),job.Name,status,)}returns.mb.Emit(),nil}
プロパティを使う良い例としては、ホスト情報の追加などがあります。 machine_type, processor, os などの情報を確認することが重要ですが、これらをディメンションとして設定し、各ホストからのすべてのメトリクスと共に送信するのではなく、プロパティとして設定し、ホストディメンションに添付することができます。