Ninja Workshops
Pet Clinic Java ワークショップ
JavaアプリケーションをつかったSplunk Oservabilityのワークショップです
OpenTelemetry Collector
OpenTelemetry Collectorのコンセプトを学び、Splunk Observability Cloudにデータを送信する方法を理解しましょう。
JavaアプリケーションをつかったSplunk Oservabilityのワークショップです
OpenTelemetry Collectorのコンセプトを学び、Splunk Observability Cloudにデータを送信する方法を理解しましょう。
このワークショップでは、Splunk Observabilityプラットフォームの以下のコンポーネントを構成するための、基本的なステップを体験できます:
ワークショップの中では、Javaのサンプルアプリケーション(Spring Pet Clinic)をクローン(ダウンロード)し、アプリケーションのコンパイル、パッケージ、実行していきます。
アプリケーションを起動すると、OpenTelemetry Javaエージェントを通じて、Splunk APMでメトリクスとトレースが即座に表示されるようになります。
その後、Splunk OpenTelemetry Javascript Libraries (RUM)を使用して、Pet Clinicのエンドユーザーインターフェース(アプリケーションによってレンダリングされるHTMLページ)を計装し、エンドユーザーが実行する個々のクリックとページロードのすべてについて、RUMトレースを生成していきます。
このワークショップは、ホスト/インスタンスが提供されるSplunk実行ワークショップ または 自前のホスト/Multipassインスタンス で行う、自己主導型のワークショップです。
ご自身のシステムには、以下のものがインストールされ、有効になっている必要があります:
8083 が開いていること(インバウンド/アウトバウンド)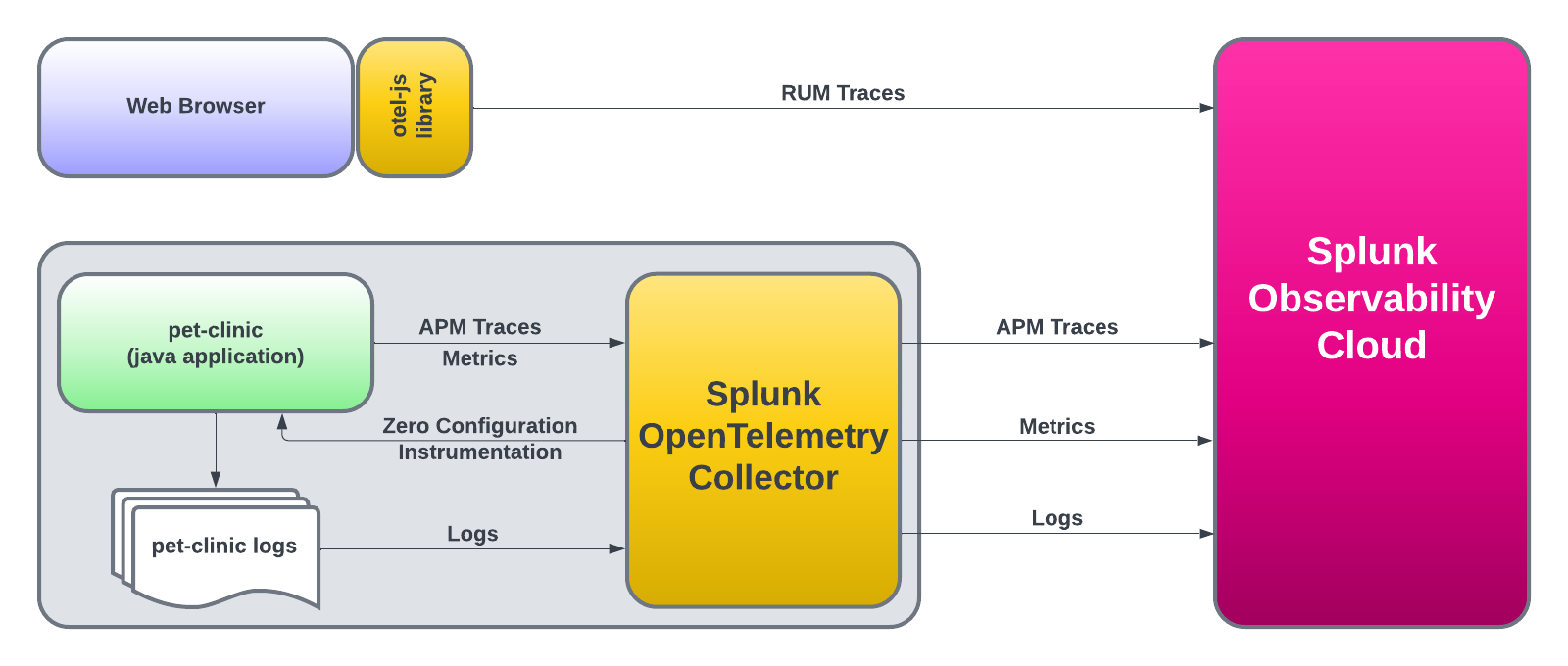
OpenTelemetry Collectorは、インフラストラクチャーとアプリケーションを計装するためのコアコンポーネントです。 その役割は収集と送信です:
Splunk Observability Cloudでは、インフラストラクチャーとアプリケーションの両方で Collector のセットアップを案内するウィザードを提供しています。デフォルトでは、ウィザードはコレクターのインストールのみを行うコマンドのみを提供します。
すでに Splunk IM ワークショップを終了している場合は、既存の環境変数を利用することができます。そうでない場合は、ACCESS_TOKENとREALMの環境変数を設定して、OpenTelemetry Collectorのインストールコマンドを実行していきます。
例えば、Realmが us1 の場合、export REALM=us1 と入力し、eu0 の場合は export REALM=eu0 と入力します。
export ACCESS_TOKEN="<replace_with_O11y-Workshop-ACCESS_TOKEN>"export REALM="<replace_with_REALM>"同じVMインスタンスにSplunk IM ワークショップのセットアップをしている場合、Otel Collectorをインストールする前に Kubernetes で実行中の Collector を削除していることを確認してください。これは、以下のコマンドを実行することで行うことができます:
helm delete splunk-otel-collector次に、Collectorをインストールします。インストールスクリプトに渡される追加のパラメータは --deployment-environment です。
curl -sSL https://dl.signalfx.com/splunk-otel-collector.sh > /tmp/splunk-otel-collector.sh && \
sudo sh /tmp/splunk-otel-collector.sh --deployment-environment $(hostname)-petclinic --realm $REALM -- $ACCESS_TOKEN。 AWS/EC2インスタンス上でこのワークショップを行う場合、インスタンスのホスト名を公開するためにコレクターにパッチを適用する必要があります:
sudo sed -i 's/gcp, ecs, ec2, azure, system/system, gcp, ecs, ec2, azure/g' /etc/otel/collector/agent_config.yamlagent_config.yaml にパッチを適用したあと、Collector を再起動してください:
sudo systemctl restart splunk-otel-collectorインストールが完了したら、Splunk Observabilityの Hosts with agent installed ダッシュボードに移動して、Dashboards → Hosts with agent installed からホストのデータを確認してみましょう。
ダッシュボードのフィルタを使用して host.nameを選択し、仮想マシンのホスト名を入力または選択します。ホストのデータが表示されたら、APMコンポーネントを使用する準備が整いました。
APMをセットアップするためにまず必要なのは…そう、アプリケーションです!この演習では、Spring PetClinicアプリケーションを使用します。これはSpringフレームワーク(Spring Boot)で作られた、非常に人気のあるサンプルJavaアプリケーションです。
まずはPetClinicリポジトリをクローンし、そして、アプリケーションをコンパイル、ビルド、パッケージ、テストしていきます。
git clone https://github.com/spring-projects/spring-petclinicspring-petclinic ディレクトリに移動します:
cd spring-petclinicPetClinic が使用する MySQL データベースを起動します:
docker run -d -e MYSQL_USER=petclinic -e MYSQL_PASSWORD=petclinic -e MYSQL_ROOT_PASSWORD=root -e MYSQL_DATABASE=petclinic -p 3306:3306 docker.io/biarms/mysql:5.7そして、Splunk版のOpenTelemetry Java APMエージェントをダウンロードしておきましょう。
curl -L https://github.com/signalfx/splunk-otel-java/releases/latest/download/splunk-otel-javaagent.jar \
-o splunk-otel-javaagent.jar次に、mavenコマンドを実行してPetClinicをコンパイル/ビルド/パッケージ化します:
./mvnw package -Dmaven.test.skip=true実際にアプリをコンパイルする前に、mavenが多くの依存ライブラリをダウンロードするため、初回実行時には数分かかるでしょう。2回目以降の実行はもっと短くなります。
そして、以下のコマンドでアプリケーションを実行することができます:
java -javaagent:./splunk-otel-javaagent.jar \
-Dserver.port=8083 \
-Dotel.service.name=$(hostname).service \
-Dotel.resource.attributes=deployment.environment=$(hostname),version=0.314 \
-Dsplunk.profiler.enabled=true \
-Dsplunk.profiler.memory.enabled=true \
-Dsplunk.metrics.enabled=true \
-jar target/spring-petclinic-*.jar --spring.profiles.active=mysqlアプリケーションが動作しているかどうかは、http://<VM_IP_ADDRESS>:8083 にアクセスして確認することができます。
次に、トラフィックを生成し、クリックしまくり、エラーを生成し、ペットを追加するなどしてください。
-Dotel.service.name=$(hostname).service では、アプリケーションの名前を定義しています。サービスマップ上のアプリケーションの名前等に反映されます。-Dotel.resource.attributes=deployment.environment=$(hostname),version=0.314 では、Environmentと、versionを定義しています。deployment.environment=$(hostname) は、Splunk APM UIの上部「Environment」に反映されます。version=0.314 はここでは、アプリケーションのバージョンを示しています。トレースをドリルダウンしたり、サービスマップの Breakdown の機能で分析したり、Tag Spotlightを開くと version 毎のパフォーマンス分析が使えます。-Dsplunk.profiler.enabled=true および splunk.profiler.memory.enabled=true では、CPUとメモリのプロファイリングを有効にしています。Splunk APM UIから、AlwaysOn Profilingを開いてみてください。-Dsplunk.metrics.enabled=true では、メモリやスレッドなどJVMメトリクスの送信を有効にしています。Dashboardsから、APM java servicesを開いてみてください。その後、Splunk APM UIにアクセスして、それぞれのテレメトリーデータを確認してみましょう!
サービスマップやTab Spotlightで、 version などのカスタム属性で分析できるようにするためには、Troubleshooting MetricSetsの設定をあらかじめ追加する必要があります。
左メニューの Settings → APM MetricSets で、設定を管理することができます。 もしお使いのアカウントで分析できなければ、設定を追加してみましょう。
次のセクションではカスタム計装を追加して、OpenTelemetryでは何ができるのか、さらに見ていきます。
前のセクション足したような、プロセス全体に渡る属性は便利なのですが、ときにはさらに、リクエストの内容に応じた状況を知りたくなるかもしれません。 心配ありません、OpenTelemetryのAPIを通じてそれらを計装し、データを送り、Splunk Observabilityで分析できるようになります。
最初に、JavaアプリケーションがOpenTelemetryのAPIを使えるように、ライブラリの依存を追加していきます。 もちろん、vimなどのお好みのエディタをお使い頂いても大丈夫です!
アプリケーションが起動中であれば、一旦停止しましょう。ターミナルで Ctrl-c を押すと、停止することができます。
nano pom.xmlそして、<dependencies> セクションの中(33行目)に↓を追加してください。
ファイル修正後、 ctrl-O のあとに Enter で、ファイルを保存します。次に ctrl-X で、nanoを終了します。
<dependency>
<groupId>io.opentelemetry</groupId>
<artifactId>opentelemetry-api</artifactId>
</dependency>念のため、コンパイルできるか確かめてみましょう:
./mvnw package -Dmaven.test.skip=truenanoはLinux環境でよく使われる、シンプルなエディタの一つです。
Alt-U で、アンドゥができます。Macの場合は Esc キーを押したあとに U を押してください!ctrl-_ のあとに数字を入力すると、指定した行数にジャンプします。ctrl-O のあとに Enter で、ファイルを保存します。ctrl-X で、nanoを終了します。もしファイルをどうしようもなく壊してしまって元に戻したい場合は、gitを使って次のようにするとよいでしょう。
git checkout pom.xmlこれで、JavaのアプリケーションでOpenTelemetryのAPIが使う準備ができました。
では、アプリケーションコードをちょっと変更して、リクエストのコンテキストのデータをスパン属性に追加してみましょう。
ここでは Pet Clinic アプリケーションの中で Find Owners が使われたときに、どのような検索文字列が指定されたのかを調査できるようにしていきます。
検索条件によってパフォーマンスが劣化してしまうケース、よくありませんか?そんなときは OwnerController に計装を追加していきましょう!
nano src/main/java/org/springframework/samples/petclinic/owner/OwnerController.javaこのコードを 変更するのは2箇所 です。
まず、import jakarta.validation.Valid; の下、37行目付近に↓を足します:
import io.opentelemetry.api.trace.Span;次に、 // find owners by last name のコメントがある箇所(おそらく95行目付近にあります)の下に、次のコードを足していきましょう:
Span span = Span.current();
span.setAttribute("lastName", owner.getLastName());このコードで、Last Nameとして指定された検索条件が、スパン属性 lastName としてSplunk Observabilityに伝えるようになりました。
アプリケーションをコンパイルし直ししますが、Javaコードを多少汚してしまったかもしれません。 spring-javaformat:apply を指定しながらコンパイルしてみましょう。
./mvnw spring-javaformat:apply package -Dmaven.test.skip=trueアプリケーションを起動します。せっかくなので、バージョンを一つあげて version=0.315 としましょう。
java -javaagent:./splunk-otel-javaagent.jar \
-Dserver.port=8083 \
-Dotel.service.name=$(hostname).service \
-Dotel.resource.attributes=deployment.environment=$(hostname),version=0.315 \
-Dsplunk.profiler.enabled=true \
-Dsplunk.profiler.memory.enabled=true \
-Dsplunk.metrics.enabled=true \
-jar target/spring-petclinic-*.jar --spring.profiles.active=mysqlhttp://<VM_IP_ADDRESS>:8083 にアクセスして、オーナー検索をいくつか試してましょう。そしてSplunk APM UIからExploreを開き、アプリケーションのトレースを見ていきます。
マニュアル計装で何ができるか、他の言語でのやり方などは、OpenTelemetryの公式ウェブサイトにある Instrumentation ページをご覧ください。
検証が完了したら、ターミナルで Ctrl-c を押すと、アプリケーションを停止することができます。
次のセクションでは、RUMを使ってブラウザ上のパフォーマンスデータを収集してみましょう。
Real User Monitoring (RUM)計装のために、Open Telemetry Javascript https://github.com/signalfx/splunk-otel-js-web スニペットをページ内に追加します。再度ウィザードを使用します Data Management → Add Integrationボタン → Monitor user experience(画面上部タブ) → Browser Instrumentationを開きます。
ドロップダウンから設定済みの RUM ACCESS TOKEN を選択し、Next をクリックします。以下の構文で App name とEnvironment を入力します:
次に、ワークショップのRUMトークンを選択し、 App nameとEnvironmentを定義します。ウィザードでは、ページ上部の <head> セクションに配置する必要のある HTML コードの断片が表示されます。この例では、次のように記述していますが、ウィザードでは先程入力した値が反映されてるはずです。
<hostname>-petclinic-service<hostname>-petclinic-envウィザードで編集済みコードスニペットをコピーするか、以下のスニペットをコピーして適宜編集してください。ただし:
[hostname]-petclinic-service - [hostname] をお使いのホスト名に書き換えてください[hostname]-petclinic-env - [hostname] をお使いのホスト名に書き換えてください <script src="https://cdn.signalfx.com/o11y-gdi-rum/latest/splunk-otel-web.js" crossorigin="anonymous"></script>
<script>
SplunkRum.init({
beaconUrl: "https://rum-ingest.<REALM>.signalfx.com/v1/rum",
rumAuth: "<RUM_ACCESS_TOKEN>",
app: "<hostname>.service",
environment: "<hostname>"
});
</script>Spring PetClinicアプリケーションでは、1つのHTMLページを「レイアウト」ページとして使用し、アプリケーションのすべてのページで再利用しています。これは、Splunk RUM計装ライブラリを挿入するのに最適な場所であり、すべてのページで自動的に読み込まれます。
では、レイアウトページを編集してみましょう:
nano src/main/resources/templates/fragments/layout.htmlそして、上で生成したスニップをページの <head> セクションに挿入してみましょう。さて、アプリケーションを再構築して、再び実行する必要があります。
mavenコマンドを実行して、PetClinicをコンパイル/ビルド/パッケージ化します:
./mvnw package -Dmaven.test.skip=trueそして、アプリケーションを動かしてみましょう。バージョンを version=0.316 とするのをお忘れなく。
java -javaagent:./splunk-otel-javaagent.jar \
-Dserver.port=8083 \
-Dotel.service.name=$(hostname).service \
-Dotel.resource.attributes=deployment.environment=$(hostname),version=0.316 \
-Dsplunk.profiler.enabled=true \
-Dsplunk.profiler.memory.enabled=true \
-Dsplunk.metrics.enabled=true \
-jar target/spring-petclinic-*.jar --spring.profiles.active=mysqlここまできて version を毎回変えるためにコマンドラインを修正するのは大変だと思うことでしょう。実際、修正が漏れた人もいるかもしれません。
本番環境では、環境変数でアプリケーションバージョンを与えたり、コンテナイメージの作成時にビルドIDを与えたりすることになるはずです。
次に、より多くのトラフィックを生成するために、アプリケーションに再度アクセスしてみましょう。 http://<VM_IP_ADDRESS>:8083 にアクセスすると、今度はRUMトレースが報告されるはずです。
RUMにアクセスして、トレースとメトリクスのいくつかを見てみましょう。左のメニューから RUM を選ぶと、Spring Pet Clinicでのユーザー(あなたです!)が体験したパフォーマンスが表示されます。
このセクションでは、Spring PetClinicアプリケーションをファイルシステムのファイルにログを書き込むように設定し、 Splunk OpenTelemetry Collectorがそのログファイルを読み取り(tail)、Splunk Observability Platformに情報を報告するように設定していきます。
Splunk OpenTelemetry Collectorを、Spring PetClinicのログファイルをtailし Splunk Observability Cloudエンドポイントにデータを報告するように設定する必要があります。
Splunk OpenTelemetry Collectorは、FluentDを使用してログの取得/報告を行い、
Spring PetClinicのログを報告するための適切な設定を行うには、
デフォルトディレクトリ(/etc/otel/collector/fluentd/conf.d/)にFluentDの設定ファイルを追加するだけです。
以下は、サンプルのFluentD設定ファイル petclinic.conf を新たに作成し、
sudo nano /etc/otel/collector/fluentd/conf.d/petclinic.confファイル /tmp/spring-petclinic.logを読み取るよう設定を記述します。
<source>
@type tail
@label @SPLUNK
tag petclinic.app
path /tmp/spring-petclinic.log
pos_file /tmp/spring-petclinic.pos_file
read_from_head false
<parse>
@type none
</parse>
</source>このとき、ファイル petclinic.conf のアクセス権と所有権を変更する必要があります。
sudo chown td-agent:td-agent /etc/otel/collector/fluentd/conf.d/petclinic.conf
sudo chmod 755 /etc/otel/collector/fluentd/conf.d/petclinic.confファイルが作成されたら、FluentDプロセスを再起動しましょう。
sudo systemctl restart td-agentSpring Pet Clinicアプリケーションは、いくつかのJavaログライブラリを使用することができます。 このシナリオでは、logbackを使ってみましょう。
リソースフォルダに logback.xml という名前のファイルを作成して…
nano src/main/resources/logback.xml以下の設定を保存しましょう:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE xml>
<configuration scan="true" scanPeriod="30 seconds">
<contextListener class="ch.qos.logback.classic.jul.LevelChangePropagator">
<resetJUL>true</resetJUL>
</contextListener>
<logger name="org.springframework.samples.petclinic" level="debug"/>
<appender name="file" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>/tmp/spring-petclinic.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>springLogFile.%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>5</maxHistory>
<totalSizeCap>1GB</totalSizeCap>
</rollingPolicy>
<encoder>
<pattern>
%d{yyyy-MM-dd HH:mm:ss} - %logger{36} - %msg trace_id=%X{trace_id} span_id=%X{span_id} trace_flags=%X{trace_flags} service.name=%property{otel.resource.service.name}, deployment.environment=%property{otel.resource.deployment.environment} %n
</pattern>
</encoder>
</appender>
<root level="debug">
<appender-ref ref="file" />
</root>
</configuration>その後、アプリケーションを再構築して再度実行していきます。
./mvnw package -Dmaven.test.skip=truejava -javaagent:./splunk-otel-javaagent.jar \
-Dserver.port=8083 \
-Dotel.service.name=$(hostname).service \
-Dotel.resource.attributes=deployment.environment=$(hostname),version=0.317 \
-Dsplunk.profiler.enabled=true \
-Dsplunk.profiler.memory.enabled=true \
-Dsplunk.metrics.enabled=true \
-jar target/spring-petclinic-*.jar --spring.profiles.active=mysqlこれまで通り、アプリケーション http://<VM_IP_ADDRESS>:8083 にアクセスしてトラフィックを生成すると、ログメッセージが報告されるようになります。
左側のLog Observerアイコンをクリックして、ホストとSpring PetClinicアプリケーションからのログメッセージのみを選択するためのフィルタを追加できます。
これでワークショップは終了です。 これまでに、Splunk Observability Cloudにメトリクス、トレース、ログ、データベースクエリのパフォーマンス、コードプロファイリングが報告されるようになりました。 おめでとうございます!
OpenTelemetry を使い始める場合は、バックエンドに直接データを送ることから始めるかもしれません。最初のステップとしてはよいですが、OpenTelemetry Collector をオブザーバビリティのアーキテクチャとして使用するのは多くの利点があり、本番環境では Collector を使ったデプロイを推奨しています。
このワークショップでは、OpenTelemetry Collector を使用することに焦点を当て、Splunk Observability Cloud で使用するためのレシーバー、プロセッサー、エクスポーターを定義し、実際にテレメトリデータを送信するためのパイプラインを設定することで、環境に合わせて Collector を活用を学びます。また、分散プラットフォームのビジネスニーズに対応するための、カスタムコンポーネントを追加できるようになるまでの道のりを進むことになります。
ワークショップの途中には、展開できる Ninja セクション があります。これらはより実践的で、ワークショップ中、もしくは自分の時間を使って、さらに技術的な詳細に取り組むことができます。
OpenTelemetry プロジェクトは頻繁に開発されているため、Ninjaセクションの内容が古くなる可能性があることに注意してください。コンテンツが古い場合には更新のリクエストを出すこともできますので、必要なものを見つけた場合はお知らせください。
このワークショップは、OpenTelemetry Collector のアーキテクチャとデプロイメントについてさらに学びたいと考えている開発者やシステム管理者を対象としています。
このセッションの終わりまでに、参加者は以下を行うことができるようになります:
%%{
init:{
"theme":"base",
"themeVariables": {
"primaryColor": "#ffffff",
"clusterBkg": "#eff2fb",
"defaultLinkColor": "#333333"
}
}
}%%
flowchart LR;
subgraph Receivers
A[OTLP] --> M(Receivers)
B[JAEGER] --> M(Receivers)
C[Prometheus] --> M(Receivers)
end
subgraph Processors
M(Receivers) --> H(Filters, Attributes, etc)
E(Extensions)
end
subgraph Exporters
H(Filters, Attributes, etc) --> S(OTLP)
H(Filters, Attributes, etc) --> T(JAEGER)
H(Filters, Attributes, etc) --> U(Prometheus)
end
OpenTelemetry Collector のインストールのために、まずはダウンロードするのが最初のステップです。このラボでは、 wget コマンドを使って OpenTelemetry の GitHub リポジトリから .deb パッケージをダウンロードしていきます。
OpenTelemetry Collector Contrib releases page
から、ご利用のプラットフォーム用の .deb パッケージを入手してください。
wget https://github.com/open-telemetry/opentelemetry-collector-releases/releases/download/v0.80.0/otelcol-contrib_0.80.0_linux_amd64.debdpkg を使って、 .deb パッケージをインストールします。下記の dpkg Output のようになれば、インストールは成功です!
sudo dpkg -i otelcol-contrib_0.80.0_linux_amd64.debSelecting previously unselected package otelcol-contrib.
(Reading database ... 64218 files and directories currently installed.)
Preparing to unpack otelcol-contrib_0.75.0_linux_amd64.deb ...
Unpacking otelcol-contrib (0.75.0) ...
Setting up otelcol-contrib (0.75.0) ...
Created symlink /etc/systemd/system/multi-user.target.wants/otelcol-contrib.service → /lib/systemd/system/otelcol-contrib.service.これで、Collector が動いているはずです。root権限で systemctl コマンドを使って、それを確かめてみましょう。
sudo systemctl status otelcol-contrib● otelcol-contrib.service - OpenTelemetry Collector Contrib
Loaded: loaded (/lib/systemd/system/otelcol-contrib.service; enabled; vendor preset: enabled)
Active: active (running) since Tue 2023-05-16 08:23:23 UTC; 25s ago
Main PID: 1415 (otelcol-contrib)
Tasks: 5 (limit: 1141)
Memory: 22.2M
CPU: 125ms
CGroup: /system.slice/otelcol-contrib.service
└─1415 /usr/bin/otelcol-contrib --config=/etc/otelcol-contrib/config.yaml
May 16 08:23:39 ip-10-0-9-125 otelcol-contrib[1415]: NumberDataPoints #0
May 16 08:23:39 ip-10-0-9-125 otelcol-contrib[1415]: Data point attributes:
May 16 08:23:39 ip-10-0-9-125 otelcol-contrib[1415]: -> exporter: Str(logging)
May 16 08:23:39 ip-10-0-9-125 otelcol-contrib[1415]: -> service_instance_id: Str(df8a57f4-abdc-46b9-a847-acd62db1001f)
May 16 08:23:39 ip-10-0-9-125 otelcol-contrib[1415]: -> service_name: Str(otelcol-contrib)
May 16 08:23:39 ip-10-0-9-125 otelcol-contrib[1415]: -> service_version: Str(0.75.0)
May 16 08:23:39 ip-10-0-9-125 otelcol-contrib[1415]: StartTimestamp: 2023-05-16 08:23:39.006 +0000 UTC
May 16 08:23:39 ip-10-0-9-125 otelcol-contrib[1415]: Timestamp: 2023-05-16 08:23:39.006 +0000 UTC
May 16 08:23:39 ip-10-0-9-125 otelcol-contrib[1415]: Value: 0.000000
May 16 08:23:39 ip-10-0-9-125 otelcol-contrib[1415]: {"kind": "exporter", "data_type": "metrics", "name": "logging"}systemctl status コマンドの表示を中止するときは q キーを押してください。
サービスを停止するときは、 stop コマンドを使います。
sudo systemctl stop otelcol-contrib更新した設定ファイルを読み込ませるときは、 restart コマンドでサービスの再起動をしましょう。
sudo systemctl restart otelcol-contribOpenTelemetry Collector は YAML ファイルを使って設定をしていきます。これらのファイルには、必要に応じて変更できるデフォルト設定が含まれています。提供されているデフォルト設定を見てみましょう:
cat /etc/otelcol-contrib/config.yaml | |
おめでとうございます!OpenTelemetry Collector のダウンロードとインストールに成功しました。あなたは OTel Ninja になる準備ができました。しかしまずは、設定ファイルと OpenTelemetry Collector の異なるディストリビューションについて見ていきましょう。
Splunk は、自社で完全にサポートされた OpenTelemetry Collector のディストリビューションを提供しています。このディストリビューションは、Splunk GitHub Repository からインストールするか、Splunk Observability Cloud のウィザードを使用して、簡単なインストールスクリプトを作成し、コピー&ペーストすることで利用できます。このディストリビューションには、OpenTelemetry Collector Contrib ディストリビューションにはない追加機能や強化が含まれています。
このセクションでは、ホストメトリクスを Splunk Observability Cloud に送信するために、設定ファイルの各セクションを詳しく見ていき、変更する方法について説明します。
さて、OpenTelemetry Collector はインストールできました。次は OpenTelemetry Collector のエクステンション(拡張機能)を見てみましょう。エクステンションはオプションで、主にテレメトリーデータの処理を伴わないタスクで使用できます。例としては、ヘルスモニタリング、サービスディスカバリ、データ転送などがあります。
%%{
init:{
"theme": "base",
"themeVariables": {
"primaryColor": "#ffffff",
"clusterBkg": "#eff2fb",
"defaultLinkColor": "#333333"
}
}
}%%
flowchart LR;
style E fill:#e20082,stroke:#333,stroke-width:4px,color:#fff
subgraph Receivers
A[OTLP] --> M(Receivers)
B[JAEGER] --> M(Receivers)
C[Prometheus] --> M(Receivers)
end
subgraph Processors
M(Receivers) --> H(Filters, Attributes, etc)
E(Extensions)
end
subgraph Exporters
H(Filters, Attributes, etc) --> S(OTLP)
H(Filters, Attributes, etc) --> T(JAEGER)
H(Filters, Attributes, etc) --> U(Prometheus)
end
他のコンポーネントと同様に、エクステンションは config.yaml ファイルで設定できます。ここでは実際に config.yaml ファイルを編集して、エクステンションを設定していきましょう。デフォルトの config.yaml では、すでに pprof エクステンションと zpages エクステンションが設定されていることを確認してみてください。このワークショップでは、設定ファイルをアップデートして health_check エクステンションを追加し、ポートを解放し、外部ネットワークからコレクターのヘルスチェックにアクセスできるようにしていきます。
sudo vi /etc/otelcol-contrib/config.yamlextensions:
health_check:
endpoint: 0.0.0.0:13133コレクターを起動します:
sudo systemctl restart otelcol-contribこのエクステンションはHTTPのURLを公開し、OpenTelemetory Collectorの稼働状況をチェックするプローブを提供します。このエクステンションはKubernetes環境でのLiveness/Readinessプローブとしても使われています。 curl コマンドの使い方は、curl man page を参照してください。
次のコマンドを実行します:
curl http://localhost:13133{"status":"Server available","upSince":"2023-04-27T10:11:22.153295874+01:00","uptime":"16m24.684476004s"}Performance Profiler エクステンションは、Go の net/http/pprof エンドポイントを有効化します。これは通常、開発者がパフォーマンスプロファイルを収集し、サービスの問題を調査するために使用します。このワークショップでは詳しく紹介はしません。
zPages は、外部エクスポータに代わるプロセス内部の機能です。有効化すると、バックグラウンドでトレースとメトリクス情報を収集し、集計し、どのようなデータを扱ったかの Web ページを公開します。zpages は、コレクターが期待どおりに動作していることを確認するための非常に便利な診断機能です。
ServiceZ は、コレクターサービスの概要と、pipelinez、extensionz、featurez zPages へのクイックアクセスを提供します。このページでは、ビルドとランタイムの情報も提供します。
URL: http://localhost:55679/debug/servicez (localhost は、適切なホスト名に切り替えてください)

PipelineZ は、コレクターで実行中のパイプラインに関する情報を提供します。タイプ、データが変更されているか、各パイプラインで使用されているレシーバー、プロセッサー、エクスポーターの情報を見ることができます。
URL: http://localhost:55679/debug/pipelinez (localhost は、適切なホスト名に切り替えてください)

ExtensionZ は、コレクターで有効化されたエクステンションを確認できます。
Example URL: http://localhost:55679/debug/extensionz (localhost は、適切なホスト名に切り替えてください)

さて、エクステンションについて説明したので、設定の変更箇所を確認していきましょう。
さて、エクステンションについて復習したところで、ワークショップのデータパイプラインの部分に飛び込んでみましょう。パイプラインとは、コレクター内でデータがたどる経路を定義するもので、レシーバーから始まり、追加の処理や変更をし、最終的にエクスポーターを経由してコレクターを出ます。
OpenTelemetry Collector のデータパイプラインは、レシーバー、プロセッサー、エクスポーターで構成されています。まずは、レシーバーから見ていきましょう。
レシーバーワークショップへようこそ!OpenTelemetry Collectorのデータパイプラインのスタート地点です。さあ、始めましょう。
レシーバーはデータをCollectorに取り込む方法で、プッシュベースとプルベースのものがあります。レシーバーは1つ以上のデータソースをサポートします。一般的に、レシーバーは指定されたフォーマットでデータを受け入れ、内部フォーマットに変換し、該当するパイプラインで定義されたプロセッサやエクスポータにデータを渡します。
プッシュまたはプルベースのレシーバは、データをCollectorに取り込む方法です。レシーバは 1 つまたは複数のデータソースをサポートします。通常、レシーバは指定されたフォーマットでデータを受け入れ、内部フォーマットに変換し、該当するパイプラインで定義されたプロセッサーや エクスポーターにデータを渡します。
%%{
init:{
"theme":"base",
"themeVariables": {
"primaryColor": "#ffffff",
"clusterBkg": "#eff2fb",
"defaultLinkColor": "#333333"
}
}
}%%
flowchart LR;
style M fill:#e20082,stroke:#333,stroke-width:4px,color:#fff
subgraph Receivers
A[OTLP] --> M(Receivers)
B[JAEGER] --> M(Receivers)
C[Prometheus] --> M(Receivers)
end
subgraph Processors
M(Receivers) --> H(Filters, Attributes, etc)
E(Extensions)
end
subgraph Exporters
H(Filters, Attributes, etc) --> S(OTLP)
H(Filters, Attributes, etc) --> T(JAEGER)
H(Filters, Attributes, etc) --> U(Prometheus)
end
Host Metrics レシーバー は、さまざまなソースからスクレイピングされたホストシステムに関するメトリクスを生成します。これは、コレクターがエージェントとしてデプロイされるときに使用さます。
etc/otel-contrib/config.yaml ファイルを更新して、hostmetrics レシーバーを設定してみましょう。以下の YAML を receivers セクションの下に挿入します。
sudo vi /etc/otelcol-contrib/config.yamlvi/vimの操作に慣れていない場合は、nano もお試しいただくと良いかもしれません。nanoはLinux環境でよく使われる、シンプルなエディタの一つです。
sudo nano /etc/otelcol-contrib/config.yamlAlt-U で、アンドゥができます。Macの場合は Esc キーを押したあとに U を押してください!ctrl-_ のあとに数字を入力すると、指定した行数にジャンプします。ctrl-O のあとに Enter で、ファイルを保存します。ctrl-X で、nanoを終了します。receivers:
hostmetrics:
collection_interval: 10s
scrapers:
# CPU utilization metrics
cpu:
# Disk I/O metrics
disk:
# File System utilization metrics
filesystem:
# Memory utilization metrics
memory:
# Network interface I/O metrics & TCP connection metrics
network:
# CPU load metrics
load:
# Paging/Swap space utilization and I/O metrics
paging:
# Process count metrics
processes:
# Per process CPU, Memory and Disk I/O metrics. Disabled by default.
# process:Prometheus のレシーバーも、もちろんあります。Prometheus は OpenTelemetry Collector で使われているオープンソースのツールキットです。このレシーバーは、OpenTelemetry Collector 自身からメトリクスをスクレイピングするためにも使われます。これらのメトリクスは、コレクタの健全性をモニタリングするために使用できる。
ここでは、prometheus レシーバーを変更して、コレクター自身からメトリクスを収集できるようにしてみます。レシーバーの名前を prometheus から prometheus/internal に変更して、レシーバーが何をしているのかをより明確しましょう。設定ファイルを以下のように更新します:
prometheus/internal:
config:
scrape_configs:
- job_name: 'otel-collector'
scrape_interval: 10s
static_configs:
- targets: ['0.0.0.0:8888']上記の設定では、OpenTelemetry Collector 自身が公開している Prometheus エンドポイントをスクレイピングしています。どのような情報が得られるか、curl コマンドで試すことができます:
curl http://localhost:8888/metricsレシーバー、プロセッサー、エクスポーター、パイプラインなどのコンポーネントは、 otlp や otlp/2 のように、 type[/name] 形式に従った識別子によって定義されます。識別子が一意である限り、与えられたタイプのコンポーネントを複数回定義することができるようになります。
ここでは prometheus/internal という識別子でこのコンポーネントを特定できるようにしたので、別の prometheus レシーバーを追加して、監視対象インスタンスの Prometheus エンドポイントをスクレイピングさせることもできます。
このスクリーンショットは、 prometheus/internal レシーバーが OpenTelemetry Collector から収集したメトリクスの、spmeのダッシュボードの例です。ここではスパン・メトリクス・ログの、それぞれの受信および送信の様子を見ることができます。
このダッシュボードはSplunk Observability Cloud にある組み込みダッシュボードで、Splunk OpenTelemetry Collector のインストールの状況を簡単にモニタリングできます。

デフォルトの設定には、他のレシーバーがあることに気づくはずです。 otlp、opencensus、jaeger、zipkin が定義されています。これらは他のソースからテレメトリーデータを受信するために使われます。このワークショップでは、これらのレシーバーについては取り上げませんので、そのままにしておきましょう。
これで、レシーバーをカバーできました。ここで、設定のの変更内容をチェックしてみましょう。
これで、レシーバーを通して OpenTelemetry Collector にデータがどのように取り込まれるかを確認しました。次に、コレクターが受信したデータをどのように処理するかを見てみましょう。
ここではコレクターを再起動しないでください! /etc/otelcol-contrib/config.yaml の変更はまだ完了していません。
プロセッサーは、レシーバーとエクスポーターとの間で、データに対して実行される処理です。プロセッサーはオプションですが、いくつかは推奨されています。OpenTelemetry Collector Contrib には多数のプロセッサーが含まれています。
%%{
init:{
"theme":"base",
"themeVariables": {
"primaryColor": "#ffffff",
"clusterBkg": "#eff2fb",
"defaultLinkColor": "#333333"
}
}
}%%
flowchart LR;
style Processors fill:#e20082,stroke:#333,stroke-width:4px,color:#fff
subgraph Receivers
A[OTLP] --> M(Receivers)
B[JAEGER] --> M(Receivers)
C[Prometheus] --> M(Receivers)
end
subgraph Processors
M(Receivers) --> H(Filters, Attributes, etc)
E(Extensions)
end
subgraph Exporters
H(Filters, Attributes, etc) --> S(OTLP)
H(Filters, Attributes, etc) --> T(JAEGER)
H(Filters, Attributes, etc) --> U(Prometheus)
end
デフォルトでは、batch プロセッサーだけが有効になっています。このプロセッサーは、データをエクスポートする前にバッチ処理して、エクスポーターへのネットワーク・コールの回数を減らすために使われます。このワークショップではデフォルトの設定を使用します:
send_batch_size (デフォルト = 8192): タイムアウトに関係なく、バッチを送信するスパン、メトリクスデータポイント、またはログレコードの数。パイプラインの次のコンポーネントに送信されるバッチサイズを制限する場合には、 send_batch_max_size を使います。timeout (デフォルト = 200ms): サイズに関係なく、バッチが送信されるまでの時間。ゼロに設定すると、send_batch_size の設定を無視して send_batch_max_size だけが適用され、データは直ちに送信されます。send_batch_max_size (デフォルト = 0): バッチサイズの上限。0 を設定すると、バッチサイズの上限がないことして扱われます。この設定は、大きなバッチが小さなユニットに分割されることを保証します。send_batch_size 以上でなければななりません。resourcedetection プロセッサーは、ホストからリソース情報を検出して、テレメトリーデータ内のリソース値をこの情報で追加または上書きすることができます。
デフォルトでは、可能であればホスト名を FQDN に設定し、そうでなければ OS が提供するホスト名になります。このロジックは hostname_sources オプションを使って変更できます。FQDN を取得せず、OSが提供するホスト名を使用するには、hostname_sourcesをosに設定します。
processors:
batch:
resourcedetection/system:
detectors: [system]
system:
hostname_sources: [os]If the workshop instance is running on an AWS/EC2 instance we can gather the following tags from the EC2 metadata API (this is not available on other platforms). ワークショップのインスタンスが AWS/EC2 インスタンスで実行されている場合、EC2 のメタデータ API から以下のタグを収集します(これは他のプラットフォームでは利用できないものもあります)。
cloud.provider ("aws")cloud.platform ("aws_ec2")cloud.account.idcloud.regioncloud.availability_zonehost.idhost.image.idhost.namehost.typeこれらのタグをメトリクスに追加するために、別のプロセッサーとして定義してみましょう。
processors:
batch:
resourcedetection/system:
detectors: [system]
system:
hostname_sources: [os]
resourcedetection/ec2:
detectors: [ec2]attribute プロセッサーを使うと、スパン、ログ、またはメトリクスの属性を変更できます。また、このプロセッサーは、入力データをフィルタリングし、マッチさせ、指定されたアクションに含めるべきか、除外すべきかを決定する機能もサポートしています。
アクションを設定するには、指定された順序で実行されるアクションのリストを記述します。サポートされるアクションは以下の通りです:
insert: その属性がない場合に、新しい属性値を挿入します。update: その属性がある場合に、その属性値を更新します。upsert: insert または update を実行します。属性がない場合には新しい属性値を挿入し、属性がある場合にはその値を更新します。delete: 入力データから属性値を削除します。hash: 属性値をハッシュ化 (SHA1) します。extract: 入力キーの値を正規表現ルールを使って抽出し、対象キーの値を更新します。対象キーがすでに存在する場合は、その値は上書きされます。次の例のように、attribute プロセッサーを使って、キーは participant.name、あたいはあなたの名前(例: marge_simpson)という新しい属性を追加してみましょう。
INSERT_YOUR_NAME_HERE の箇所は、自分の名前に置き換えてください。また、自分の名前に スペースを使わない ようにしてください。
このワークショップの後半では、この属性を使用して Splunk Observability Cloud でメトリクスをフィルタリングします。
processors:
batch:
resourcedetection/system:
detectors: [system]
system:
hostname_sources: [os]
resourcedetection/ec2:
detectors: [ec2]
attributes/conf:
actions:
- key: participant.name
action: insert
value: "INSERT_YOUR_NAME_HERE"これで、プロセッサーがカバーできました。ここで、設定のの変更内容をチェックしてみましょう。
エクスポーターは、プッシュまたはプルベースであり、一つ以上のバックエンド/デスティネーションにデータを送信する方法です。エクスポーターは、一つまたは複数のデータソースをサポートすることがあります。
このワークショップでは、otlphttp エクスポーターを使用します。OpenTelemetry Protocol (OTLP) は、テレメトリーデータを伝送するためのベンダーニュートラルで標準化されたプロトコルです。OTLP エクスポーターは、OTLP プロトコルを実装するサーバーにデータを送信します。OTLP エクスポーターは、gRPC および HTTP/JSON プロトコルの両方をサポートします。
%%{
init:{
"theme":"base",
"themeVariables": {
"primaryColor": "#ffffff",
"clusterBkg": "#eff2fb",
"defaultLinkColor": "#333333"
}
}
}%%
flowchart LR;
style Exporters fill:#e20082,stroke:#333,stroke-width:4px,color:#fff
subgraph Receivers
A[OTLP] --> M(Receivers)
B[JAEGER] --> M(Receivers)
C[Prometheus] --> M(Receivers)
end
subgraph Processors
M(Receivers) --> H(Filters, Attributes, etc)
E(Extensions)
end
subgraph Exporters
H(Filters, Attributes, etc) --> S(OTLP)
H(Filters, Attributes, etc) --> T(JAEGER)
H(Filters, Attributes, etc) --> U(Prometheus)
end
Splunk Observability Cloud へ HTTP 経由でメトリックスを送信するためには、otlphttp エクスポーターを設定する必要があります。
/etc/otelcol-contrib/config.yaml ファイルを編集し、otlphttp エクスポーターを設定しましょう。以下の YAML を exporters セクションの下に挿入し、例えば2スペースでインデントしてください。
また、ディスクの容量不足を防ぐために、ロギングエクスポーターの詳細度を変更します。デフォルトの detailed は非常に詳細です。
exporters:
logging:
verbosity: normal
otlphttp/splunk:次に、metrics_endpoint を定義して、ターゲットURLを設定していきます。
Splunk 主催のワークショップの参加者である場合、使用しているインスタンスにはすでに Realm 環境変数が設定されています。その環境変数を設定ファイルで参照します。それ以外の場合は、新しい環境変数を作成して Realm を設定する必要があります。例えば:
export REALM="us1"使用するURLは https://ingest.${env:REALM}.signalfx.com/v2/datapoint/otlp です。(Splunkは、データの居住地に応じて世界中の主要地域に Realm を持っています)。
otlphttp エクスポーターは、traces_endpoint と logs_endpoint それぞれのターゲットURLを定義することにより、トレースとログを送信するようにも設定できますが、そのような設定はこのワークショップの範囲外とします。
exporters:
logging:
verbosity: normal
otlphttp/splunk:
metrics_endpoint: https://ingest.${env:REALM}.signalfx.com/v2/datapoint/otlpデフォルトでは、すべてのエンドポイントで gzip 圧縮が有効になっています。エクスポーターの設定で compression: none を設定することにより、圧縮を無効にすることができます。このワークショップでは圧縮を有効にしたままにし、データを送信する最も効率的な方法としてデフォルト設定を使っていきます。
Splunk Observability Cloud にメトリクスを送信するためには、アクセストークンを使用する必要があります。これは、Splunk Observability Cloud UI で新しいトークンを作成することにより行うことができます。トークンの作成方法についての詳細は、Create a token を参照してください。トークンは INGEST タイプである必要があります。
Splunk 主催のワークショップの参加者である場合、使用しているインスタンスにはすでにアクセストークンが設定されています(環境変数として設定されています)ので、その環境変数を設定ファイルで参照します。それ以外の場合は、新しいトークンを作成し、それを環境変数として設定する必要があります。例えば:
export ACCESS_TOKEN=<replace-with-your-token>トークンは、設定ファイル内で headers: セクションの下に X-SF-TOKEN: ${env:ACCESS_TOKEN} を挿入することにで定義します:
exporters:
logging:
verbosity: normal
otlphttp/splunk:
metrics_endpoint: https://ingest.${env:REALM}.signalfx.com/v2/datapoint/otlp
headers:
X-SF-TOKEN: ${env:ACCESS_TOKEN}これで、エクスポーターもカバーできました。設定を確認していきましょう:
もちろん、OTLP プロトコルをサポートする他のソリューションを指すように metrics_endpoint を簡単に設定することができます。
次に、config.yaml のサービスセクションで、今設定したレシーバー、プロセッサー、エクスポーターを有効にしていきます。
Service セクションでは、レシーバー、プロセッサー、エクスポーター、およびエクステンションにある設定に基づいて、コレクターで有効にするコンポーネントを設定していきます。
コンポーネントが設定されていても、Service セクション内で定義されていない場合、そのコンポーネントは有効化されません。
サービスのセクションは、以下の3つのサブセクションで構成されています:
デフォルトの設定では、拡張機能セクションが health_check、pprof、zpages を有効にするように設定されており、これらは以前のエクステンションのモジュールで設定しました。
service:
extensions: [health_check, pprof, zpages]それでは、メトリックパイプラインを設定していきましょう!
ワークショップのレシーバー部分で振り返ると、ホストシステムに関するメトリクスを生成するために、様々なソースからスクレイピングする Host Metrics レシーバーを定義しました。このレシーバーを有効にするためには、メトリクスパイプラインに hostmetrics レシーバーを含める必要があります。
metrics パイプラインで、メトリクスの receivers セクションに hostmetrics を追加します。
service:
pipelines:
traces:
receivers: [otlp, opencensus, jaeger, zipkin]
processors: [batch]
exporters: [logging]
metrics:
receivers: [hostmetrics, otlp, opencensus, prometheus]
processors: [batch]
exporters: [logging]ワークショップの前半で、prometheus レシーバーの名前を変更し、コレクター内部のメトリクスを収集していることを反映して、prometheus/internal という名前にしました。
現在、メトリクスパイプラインの下で prometheus/internal レシーバーを有効にする必要があります。metrics パイプラインの下の receivers セクションを更新して、prometheus/internal を含めます:
service:
pipelines:
traces:
receivers: [otlp, opencensus, jaeger, zipkin]
processors: [batch]
exporters: [logging]
metrics:
receivers: [hostmetrics, otlp, opencensus, prometheus/internal]
processors: [batch]
exporters: [logging]また、コレクターがインスタンスのホスト名やAWS/EC2のメタデータを取得できるように、resourcedetection/system および resourcedetection/ec2 プロセッサーを追加しました。これらのプロセッサーをメトリクスパイプライン下で有効にする必要があります。
metrics パイプラインの下の processors セクションを更新して、resourcedetection/system および resourcedetection/ec2 を追加します:
service:
pipelines:
traces:
receivers: [otlp, opencensus, jaeger, zipkin]
processors: [batch]
exporters: [logging]
metrics:
receivers: [hostmetrics, otlp, opencensus, prometheus/internal]
processors: [batch, resourcedetection/system, resourcedetection/ec2]
exporters: [logging]また、このワークショップのプロセッサーセクションでは、attributes/conf プロセッサーを追加し、コレクターがすべてのメトリクスに participant.name という新しい属性を挿入するようにしました。これをメトリクスパイプライン下で有効にする必要があります。
metrics パイプラインの下の processors セクションを更新して、attributes/conf を追加します:
service:
pipelines:
traces:
receivers: [otlp, opencensus, jaeger, zipkin]
processors: [batch]
exporters: [logging]
metrics:
receivers: [hostmetrics, otlp, opencensus, prometheus/internal]
processors: [batch, resourcedetection/system, resourcedetection/ec2, attributes/conf]
exporters: [logging]ワークショップのエクスポーターセクションでは、otlphttp エクスポーターを設定して、メトリクスを Splunk Observability Cloud に送信するようにしました。これをメトリクスパイプライン下で有効にする必要があります。
metrics パイプラインの下の exporters セクションを更新して、otlphttp/splunk を追加します:
service:
pipelines:
traces:
receivers: [otlp, opencensus, jaeger, zipkin]
processors: [batch]
exporters: [logging]
metrics:
receivers: [hostmetrics, otlp, opencensus, prometheus/internal]
processors: [batch, resourcedetection/system, resourcedetection/ec2, attributes/conf]
exporters: [logging, otlphttp/splunk]コレクターを再起動する前に、設定ファイルを検証することをお勧めします。これは、組み込みの validate コマンドを使用して行うことができます:
otelcol-contrib validate --config=file:/etc/otelcol-contrib/config.yamlError: failed to get config: cannot unmarshal the configuration: 1 error(s) decoding:
* error decoding 'processors': error reading configuration for "attributes/conf": 1 error(s) decoding:
* 'actions[0]' has invalid keys: actions
2023/06/29 09:41:28 collector server run finished with error: failed to get config: cannot unmarshal the configuration: 1 error(s) decoding:
* error decoding 'processors': error reading configuration for "attributes/conf": 1 error(s) decoding:
* 'actions[0]' has invalid keys: actions動作する設定ができたので、コレクターを起動し、その後 zPages が報告している内容を確認しましょう。
sudo systemctl restart otelcol-contrib
OpenTelemetry Collector を設定して Splunk Observability Cloud にメトリクスを送信するようにしたので、Splunk Observability Cloud でデータを見てみましょう。Splunk Observability Cloud への招待を受け取っていない場合は、講師がログイン資格情報を提供します。
その前に、もう少し興味深くするために、インスタンスでストレステストを実行しましょう。これにより、ダッシュボードが活性化されます。
sudo apt install stress
while true; do stress -c 2 -t 40; stress -d 5 -t 40; stress -m 20 -t 40; doneSplunk Observability Cloudにログインしたら、左側のナビゲーションを使用して Dashboards に移動します:

検索ボックスで OTel Contrib を検索します:

ダッシュボードが存在しない場合は、講師が迅速に追加します。このワークショップの Splunk 主催版に参加していない場合、インポートするダッシュボードグループはこのページの下部にあります。
OTel Contrib Dashboard ダッシュボードをクリックして開きます:

ダッシュボードの上部にある Filter 欄に「participant」の途中まで入力し、候補に出る participant.name を選択します:

participant.name で、config.yaml 内で設定したあなたの名前を入力するか、リストから選択することができます:

これで、OpenTelemetry Collector を設定したホストの、ホストメトリクスを確認することができます。
Open Telemetry Collectorのためのコンポーネントを構築するには、以下の3つの主要な部分が必要です:
これについて、プロジェクトの重要なDevOpsメトリクスを追跡するためにJenkinsと連携するコンポーネントを構築する例を考えていきます。
測定しようとしているメトリクスは次のとおりです:
これらの指標は Google の DevOps Research and Assessment (DORA) チームによって特定されたもので、ソフトウェア開発チームのパフォーマンスを示すのに役立ちます。Jenkins CI を選択した理由は、私たちが同じオープンソースソフトウェアエコシステムに留まり、将来的にベンダー管理のCIツールが採用する例となることができるためです。
組織内でオブザーバビリティを向上させる際には、トレードオフが発生するため、考慮する点があります。
| 長所 | 短所 | |
|---|---|---|
| (自動)計装1 | システムを観測するために外部APIが不要 | 計装を変更するにはプロジェクトの変更が必要 |
| システム所有者/開発者は可観測性の変更が可能 | ランタイムへの追加の依存が必要 | |
| システムの文脈を理解し、Exemplar とキャプチャされたデータを関連付けることが可能 | システムのパフォーマンスに影響を与える可能性がある | |
| コンポーネント | データ名や意味の変更をシステムのリリースサイクルから独立した展開が可能 | APIの破壊的な変更の可能性があり、システムとコレクター間でリリースの調整が必要 |
| その後の利用に合わせて収集されるデータの更新/拡張が容易 | キャプチャされたデータの意味がシステムリリースと一致せず、予期せず壊れる可能性がある |
計装(instrument, インストゥルメント)とは、アプリケーションなどのシステムコンポーネントに対して、トレースやメトリクス、ログなどのテレメトリーデータを出力させる実装。計装ライブラリを最低限セットアップするだけで一通りのトレースやメトリクスなどを出力できるような対応を「自動計装」と呼びます。 ↩︎
このワークショップのセクションを完了する時間は経験によって異なる場合があります。
完成したものはこちらにあります。詰まった場合や講師と一緒に進めたい場合に利用してください。
新しい Jenkins CI レシーバーの開発を始めるため、まずは Go プロジェクトのセットアップから始めていきます。 新しい Go プロジェクトを作成する手順は以下の通りです:
${HOME}/go/src/jenkinscireceiver という名前の新しいディレクトリを作成し、そのディレクトリに移動します。go mod init splunk.conf/workshop/example/jenkinscireceiver を実行して、Go のモジュールを初期化します。go.mod というファイルが作成されます。go.sum として保存されます。コンポーネントの Configuration 部分は、ユーザーがコンポーネントに対する入力を行う方法であり、設定に使用される値は以下のようである必要があります:
---
# Required Values
endpoint: http://my-jenkins-server:8089
auth:
authenticator: basicauth/jenkins
# Optional Values
collection_interval: 10m
metrics:
example.metric.1:
enabled: true
example.metric.2:
enabled: true
example.metric.3:
enabled: true
example.metric.4:
enabled: true---
jenkins_server_addr: hostname
jenkins_server_api_port: 8089
interval: 10m
filter_builds_by:
- name: my-awesome-build
status: amber
track:
values:
example.metric.1: yes
example.metric.2: yes
example.metric.3: no
example.metric.4: no悪い例では、Configuration のベストプラクティスに反するとコンポーネントが使いにくくなってしまうことが理解できるはずです。 フィールドの値が何であるべきかを明確ではなく、既存のプロセッサーに移譲できる機能を含み、コレクター内の他のコンポーネントと比較してフィールドの命名に一貫性がありません。
良い例では、必要な値をシンプルに保ち、他のコンポーネントからのフィールド名を再利用し、コンポーネントが Jenkins とコレクター間の相互作用にのみ焦点を当てています。
設定値の中には、このコンポーネントで独自に追加するものと、コレクター内部の共有ライブラリによって提供されているものがあります。これらはビジネスロジックに取り組む際にさらに詳しく説明します。Configuration は小さく始めるべきで、ビジネスロジックに追加の機能が必要になったら、設定も追加していきましょう。
Configuration に必要なコードを実装するために、config.go という名前の新しいファイルを以下の内容で作成します:
package jenkinscireceiver
import (
"go.opentelemetry.io/collector/config/confighttp"
"go.opentelemetry.io/collector/receiver/scraperhelper"
"splunk.conf/workshop/example/jenkinscireceiver/internal/metadata"
)
type Config struct {
// HTTPClientSettings contains all the values
// that are commonly shared across all HTTP interactions
// performed by the collector.
confighttp.HTTPClientSettings `mapstructure:",squash"`
// ScraperControllerSettings will allow us to schedule
// how often to check for updates to builds.
scraperhelper.ScraperControllerSettings `mapstructure:",squash"`
// MetricsBuilderConfig contains all the metrics
// that can be configured.
metadata.MetricsBuilderConfig `mapstructure:",squash"`
}Jenkinsからメトリクスを取得するために必要なコンポーネントの種類をおさらいしましょう:
レシーバーが解決するビジネスユースケースは以下の通りです:
これらは一般的に pull 対 push ベースのデータ収集と呼ばれ、詳細についてはレシーバーの概要で読むことができます。
プロセッサーが解決するビジネスユースケースは以下の通りです:
プロセッサーを通過するデータタイプは、下流のコンポーネントに同じデータタイプを転送する必要があることを覚えておいてください。 詳細については、プロセッサーの概要をご覧ください。
エクスポーターが解決するビジネスユースケースは以下の通りです:
OpenTelemetryコレクターは「バックエンド」、すべてを一元化した観測可能性スイートを目指すのではなく、OpenTelemetryの創設原則に忠実であり続けることを目指しています。つまり、ベンダーに依存しない全ての人のための観測可能性です。詳細については、エクスポーターの概要をお読みください。
コネクターは比較的新しいコンポーネントで、このワークショップではあまり触れていません。 コネクターは、異なるテレメトリタイプやパイプラインをまたいで使用できるプロセッサーのようなものだといえます。たとえば、コネクターはログとしてデータを受け取り、メトリクスとして出力したり、あるパイプラインからメトリクスを受け取り、テレメトリーデータに関するメトリクスを提供したりすることができます。
コネクターが解決するビジネスケースは以下の通りです:
Ninjaセクションの一部としてプロセッサーの概要内で簡単に概要が説明されています。
これらのコンポーネントについて考えると、Jenkins に対応する場合はプルベースのレシーバーを開発する必要があることがわかります。
レシーバーによってキャプチャされるメトリクスを定義し、エクスポートするために、コレクターのために開発された mdatagen を使って、yaml で定義したメトリクスをコードに変換していきます。
---
# Type defines the name to reference the component
# in the configuration file
type: jenkins
# Status defines the component type and the stability level
status:
class: receiver
stability:
development: [metrics]
# Attributes are the expected fields reported
# with the exported values.
attributes:
job.name:
description: The name of the associated Jenkins job
type: string
job.status:
description: Shows if the job had passed, or failed
type: string
enum:
- failed
- success
- unknown
# Metrics defines all the pontentially exported values from this receiver.
metrics:
jenkins.jobs.count:
enabled: true
description: Provides a count of the total number of configured jobs
unit: "{Count}"
gauge:
value_type: int
jenkins.job.duration:
enabled: true
description: Show the duration of the job
unit: "s"
gauge:
value_type: int
attributes:
- job.name
- job.status
jenkins.job.commit_delta:
enabled: true
description: The calculation difference of the time job was finished minus commit timestamp
unit: "s"
gauge:
value_type: int
attributes:
- job.name
- job.status// To generate the additional code needed to capture metrics,
// the following command to be run from the shell:
// go generate -x ./...
//go:generate go run github.com/open-telemetry/opentelemetry-collector-contrib/cmd/mdatagen@v0.80.0 metadata.yaml
package jenkinscireceiver
// There is no code defined within this file.
次のセクションに進む前に、これらのファイルをプロジェクトフォルダ内に作成してください。
Factory はソフトウェアデザインパターンの一種で、提供された Configuration を使って、動的にオブジェクト(この場合は jenkinscireceiver)を作成するものです。現実的な例では、携帯電話店に行って、あなたの正確な説明に合った携帯電話を求め、それを提供されるようなものです。
コマンド go generate -x ./... を実行すると、定義されたメトリクスをエクスポートするために必要なすべてのコードを含む新しいフォルダ jenkinscireceiver/internal/metadata が作成されます。生成されるコードは以下の通りです:
package jenkinscireceiver
import (
"errors"
"go.opentelemetry.io/collector/component"
"go.opentelemetry.io/collector/config/confighttp"
"go.opentelemetry.io/collector/receiver"
"go.opentelemetry.io/collector/receiver/scraperhelper"
"splunk.conf/workshop/example/jenkinscireceiver/internal/metadata"
)
func NewFactory() receiver.Factory {
return receiver.NewFactory(
metadata.Type,
newDefaultConfig,
receiver.WithMetrics(newMetricsReceiver, metadata.MetricsStability),
)
}
func newMetricsReceiver(_ context.Context, set receiver.CreateSettings, cfg component.Config, consumer consumer.Metrics) (receiver.Metrics, error) {
// Convert the configuration into the expected type
conf, ok := cfg.(*Config)
if !ok {
return nil, errors.New("can not convert config")
}
sc, err := newScraper(conf, set)
if err != nil {
return nil, err
}
return scraperhelper.NewScraperControllerReceiver(
&conf.ScraperControllerSettings,
set,
consumer,
scraperhelper.AddScraper(sc),
)
}package jenkinscireceiver
import (
"go.opentelemetry.io/collector/config/confighttp"
"go.opentelemetry.io/collector/receiver/scraperhelper"
"splunk.conf/workshop/example/jenkinscireceiver/internal/metadata"
)
type Config struct {
// HTTPClientSettings contains all the values
// that are commonly shared across all HTTP interactions
// performed by the collector.
confighttp.HTTPClientSettings `mapstructure:",squash"`
// ScraperControllerSettings will allow us to schedule
// how often to check for updates to builds.
scraperhelper.ScraperControllerSettings `mapstructure:",squash"`
// MetricsBuilderConfig contains all the metrics
// that can be configured.
metadata.MetricsBuilderConfig `mapstructure:",squash"`
}
func newDefaultConfig() component.Config {
return &Config{
ScraperControllerSettings: scraperhelper.NewDefaultScraperControllerSettings(metadata.Type),
HTTPClientSettings: confighttp.NewDefaultHTTPClientSettings(),
MetricsBuilderConfig: metadata.DefaultMetricsBuilderConfig(),
}
}package jenkinscireceiver
type scraper struct {}
func newScraper(cfg *Config, set receiver.CreateSettings) (scraperhelper.Scraper, error) {
// Create a our scraper with our values
s := scraper{
// To be filled in later
}
return scraperhelper.NewScraper(metadata.Type, s.scrape)
}
func (scraper) scrape(ctx context.Context) (pmetric.Metrics, error) {
// To be filled in
return pmetrics.NewMetrics(), nil
}---
dist:
name: otelcol
description: "Conf workshop collector"
output_path: ./dist
version: v0.0.0-experimental
extensions:
- gomod: github.com/open-telemetry/opentelemetry-collector-contrib/extension/basicauthextension v0.80.0
- gomod: github.com/open-telemetry/opentelemetry-collector-contrib/extension/healthcheckextension v0.80.0
receivers:
- gomod: go.opentelemetry.io/collector/receiver/otlpreceiver v0.80.0
- gomod: github.com/open-telemetry/opentelemetry-collector-contrib/receiver/jaegerreceiver v0.80.0
- gomod: github.com/open-telemetry/opentelemetry-collector-contrib/receiver/prometheusreceiver v0.80.0
- gomod: splunk.conf/workshop/example/jenkinscireceiver v0.0.0
path: ./jenkinscireceiver
processors:
- gomod: go.opentelemetry.io/collector/processor/batchprocessor v0.80.0
exporters:
- gomod: go.opentelemetry.io/collector/exporter/loggingexporter v0.80.0
- gomod: go.opentelemetry.io/collector/exporter/otlpexporter v0.80.0
- gomod: go.opentelemetry.io/collector/exporter/otlphttpexporter v0.80.0
# This replace is a go directive that allows for redefine
# where to fetch the code to use since the default would be from a remote project.
replaces:
- splunk.conf/workshop/example/jenkinscireceiver => ./jenkinscireceiver├── build-config.yaml
└── jenkinscireceiver
├── go.mod
├── config.go
├── factory.go
├── scraper.go
└── internal
└── metadataこれらのファイルがプロジェクトに作成されたら、go mod tidy を実行します。すると、すべての依存ライブラリが取得され、go.mod が更新されます。
この時点では、何も行っていないカスタムコンポーネントが作成されています。ここから、Jenkins からデータを取得するための必要なロジックを追加していきましょう。
ここからのステップは以下の通りです:
変更を scraper.go に加えていきます。
Jenkinsサーバーに接続するために、パッケージ “github.com/yosida95/golang-jenkins” を使用します。これには、Jenkinsサーバーからデータを読み取るために必要な機能が提供されています。
次に、“go.opentelemetry.io/collector/receiver/scraperhelper” ライブラリのいくつかのヘルパー関数を利用して、コンポーネントの起動が完了したらJenkinsサーバーに接続できるようにするスタート関数を作成します。
package jenkinscireceiver
import (
"context"
jenkins "github.com/yosida95/golang-jenkins"
"go.opentelemetry.io/collector/component"
"go.opentelemetry.io/collector/pdata/pmetric"
"go.opentelemetry.io/collector/receiver"
"go.opentelemetry.io/collector/receiver/scraperhelper"
"splunk.conf/workshop/example/jenkinscireceiver/internal/metadata"
)
type scraper struct {
mb *metadata.MetricsBuilder
client *jenkins.Jenkins
}
func newScraper(cfg *Config, set receiver.CreateSettings) (scraperhelper.Scraper, error) {
s := &scraper{
mb : metadata.NewMetricsBuilder(cfg.MetricsBuilderConfig, set),
}
return scraperhelper.NewScraper(
metadata.Type,
s.scrape,
scraperhelper.WithStart(func(ctx context.Context, h component.Host) error {
client, err := cfg.ToClient(h, set.TelemetrySettings)
if err != nil {
return err
}
// The collector provides a means of injecting authentication
// on our behalf, so this will ignore the libraries approach
// and use the configured http client with authentication.
s.client = jenkins.NewJenkins(nil, cfg.Endpoint)
s.client.SetHTTPClient(client)
return nil
}),
)
}
func (s scraper) scrape(ctx context.Context) (pmetric.Metrics, error) {
// To be filled in
return pmetric.NewMetrics(), nil
}これで、Jenkinsレシーバーを初期化するために必要なすべてのコードが完成しました。
ここから先は、実装が必要な scrape メソッドに焦点を当てます。このメソッドは、設定された間隔(デフォルトでは1分)ごとに実行されます。
Jenkins サーバーの負荷状況や、どの程度のプロジェクトが実行されているかを測定するために、Jenkins で設定されているジョブの数をキャプチャしたいと考えています。これを行うために、Jenkins クライアントを呼び出してすべてのジョブをリスト化し、エラーが報告された場合はメトリクスなしでそれを返し、そうでなければメトリクスビルダーからのデータを発行します。
func (s scraper) scrape(ctx context.Context) (pmetric.Metrics, error) {
jobs, err := s.client.GetJobs()
if err != nil {
return pmetric.Metrics{}, err
}
// Recording the timestamp to ensure
// all captured data points within this scrape have the same value.
now := pcommon.NewTimestampFromTime(time.Now())
// Casting to an int64 to match the expected type
s.mb.RecordJenkinsJobsCountDataPoint(now, int64(len(jobs)))
// To be filled in
return s.mb.Emit(), nil
}前のステップにより、すべてのジョブをキャプチャしてジョブの数をレポートできるようになりました。 このステップでは、それぞれのジョブを調査し、レポートされた値を使用してメトリクスをキャプチャしていきます。
func (s scraper) scrape(ctx context.Context) (pmetric.Metrics, error) {
jobs, err := s.client.GetJobs()
if err != nil {
return pmetric.Metrics{}, err
}
// Recording the timestamp to ensure
// all captured data points within this scrape have the same value.
now := pcommon.NewTimestampFromTime(time.Now())
// Casting to an int64 to match the expected type
s.mb.RecordJenkinsJobsCountDataPoint(now, int64(len(jobs)))
for _, job := range jobs {
// Ensure we have valid results to start off with
var (
build = job.LastCompletedBuild
status = metadata.AttributeJobStatusUnknown
)
// This will check the result of the job, however,
// since the only defined attributes are
// `success`, `failure`, and `unknown`.
// it is assume that anything did not finish
// with a success or failure to be an unknown status.
switch build.Result {
case "aborted", "not_built", "unstable":
status = metadata.AttributeJobStatusUnknown
case "success":
status = metadata.AttributeJobStatusSuccess
case "failure":
status = metadata.AttributeJobStatusFailed
}
s.mb.RecordJenkinsJobDurationDataPoint(
now,
int64(job.LastCompletedBuild.Duration),
job.Name,
status,
)
}
return s.mb.Emit(), nil
}最後のステップでは、コミットからジョブ完了までにかかった時間を計算して、DORA メトリクス を推測するのに役立てていきます。
func (s scraper) scrape(ctx context.Context) (pmetric.Metrics, error) {
jobs, err := s.client.GetJobs()
if err != nil {
return pmetric.Metrics{}, err
}
// Recording the timestamp to ensure
// all captured data points within this scrape have the same value.
now := pcommon.NewTimestampFromTime(time.Now())
// Casting to an int64 to match the expected type
s.mb.RecordJenkinsJobsCountDataPoint(now, int64(len(jobs)))
for _, job := range jobs {
// Ensure we have valid results to start off with
var (
build = job.LastCompletedBuild
status = metadata.AttributeJobStatusUnknown
)
// Previous step here
// Ensure that the `ChangeSet` has values
// set so there is a valid value for us to reference
if len(build.ChangeSet.Items) == 0 {
continue
}
// Making the assumption that the first changeset
// item is the most recent change.
change := build.ChangeSet.Items[0]
// Record the difference from the build time
// compared against the change timestamp.
s.mb.RecordJenkinsJobCommitDeltaDataPoint(
now,
int64(build.Timestamp-change.Timestamp),
job.Name,
status,
)
}
return s.mb.Emit(), nil
}これらのステップがすべて完了すると、Jenkins CI レシーバーが完成します!
コンポーネントに必要な機能は、おそらく他にもたくさん思いつくでしょう。例えば:
この時間を使って遊んでみたり、壊してみたり、変更してみたり、ビルドからのログをキャプチャしてみるなどしてください。