主なポイント
ワークショップでは、Splunk Observability Cloud と OpenTelemetry シグナル(メトリクス、トレース、ログ)を組み合わせることで、平均検出時間(MTTD)の短縮、平均解決時間(MTTR)の短縮にどれほど寄与するかを見てきました。
- 主なユーザーインターフェースとそのコンポーネント、ランディングページ、Infrastructure、APM、RUM、Synthetics、ダッシュボードページ および 設定ページの理解を深めました。
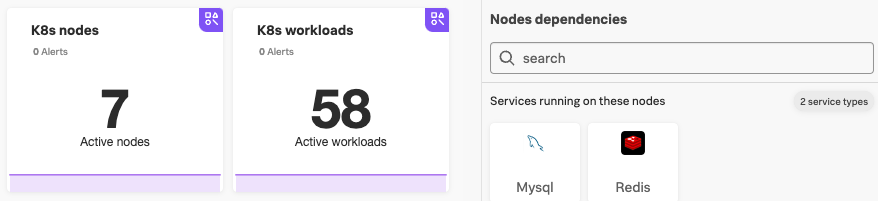
- 時間の許す限り、Infrastructure の演習で Kubernetes ナビゲーターで使用される メトリクス を見て、Kubernetes クラスターで見つかった関連するサービスを確認しました。
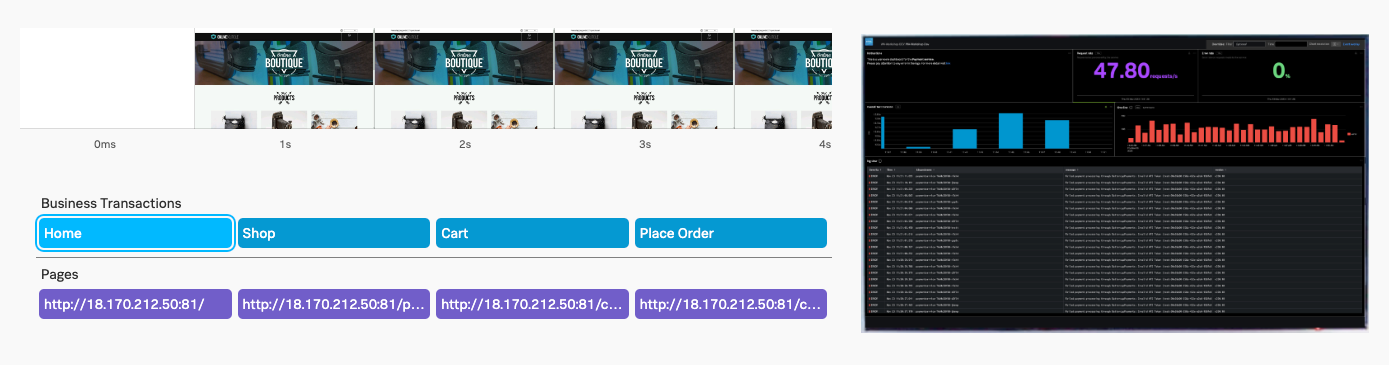
- ユーザーが経験していることを理解し、RUM および APM を使用して特に時間のかかるページ読み込みをトラブルシュートしました。その際には、そのトレースをフロントエンドからバックエンドまで追跡し、ログエントリまで確認しました。 また、RUM Session Replay および APM Dependency map と Breakdown などのツールを使用して、問題の原因を発見しました。
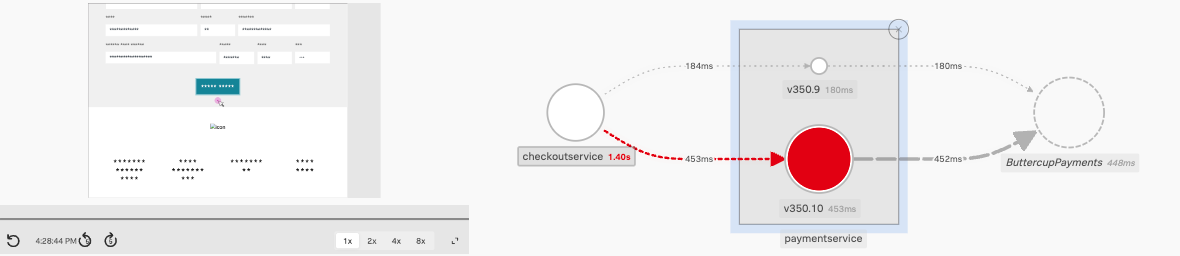
- RUM および APM の両方で Tag Spotlight を使用して問題の影響範囲やパフォーマンス問題とエラーの傾向とコンテキストを理解しました。 APM Trace waterfall の Span を掘り下げて、サービスがどのように相互作用ているかを確認し、エラーを見つけました。

- Related content 機能を使用して、Trace からその Trace に関連する Logs へのリンクを辿り、フィルターを使用して問題の正確な原因まで掘り下げました。

さらに、Synthetics を確認し、ここでウェブおよびモバイルトラフィックをシミュレートしました。 Synthetics テストを活用し、RUM / APM および Log Observer から見つけた内容を確認するとともに、テスト実行での所要時間が SLA を超えた場合に警告を受けられるように Detector を作成しました。
最後の演習では、開発者とSREがTVスクリーンで状態をチェックし続けられるように、ヘルスダッシュボードを作成しました。