APM ホームページ
メインメニューで APM をクリックすると、APM ホームページが表示されます。このページは3つのセクションで構成されています。
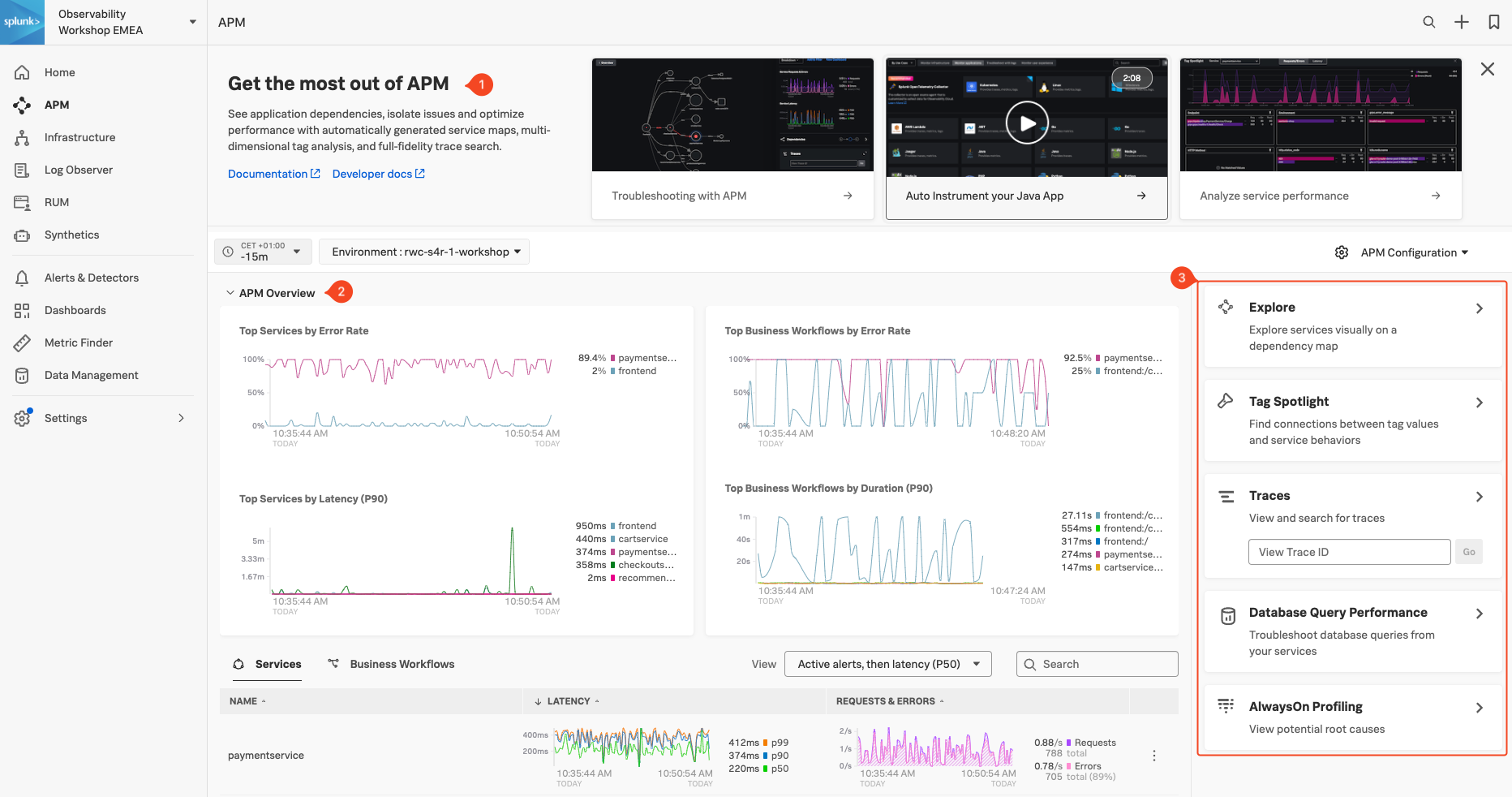
- オンボーディングパネル: Splunk APM を始める際に参考になるトレーニングビデオとドキュメンテーションへのリンク
- APM Overview: 最もエラー率やレイテンシーが高いサービスとビジネスワークフローのリアルタイムメトリクス
- 機能パネル: サービス、タグ、トレース、データベースクエリパフォーマンス、コードプロファイリングの詳細分析を行う際に使用するリンク
APM Overview パネルは、アプリケーションのヘルスステータスに関する概要を示します。これにはアプリケーションのサービス、レイテンシー、エラーのサマリーが含まれています。また、エラーレートが最も高いサービスとビジネスワークフローのリストも含まれています(ビジネスワークフローは、特定の活動やトランザクションに関連する一連のトレースの集合で、エンドツーエンドの KPI を監視し、根本原因とボトルネック特定することができるようになります)。
複数のアプリケーションを簡単に区別するために、Splunk は Environment を使用します。ワークショップ環境の命名規則は [ワークショップの名前]-workshop です。インストラクターが正しい名前を案内します。
- 表示されている画面上の時間枠が過去15分(-15m)に設定されていることを確認してください。
- ドロップダウンボックスからワークショップの Environment を選択してください。そのワークショップ環境名のみが選択されていることを確認してください。
エラーレートが最も高いサービスに関するチャートから、どんなことが分かりますか?
paymentservice が高いエラーレートを持っています
概要ページを下にスクロールすると、一部のサービスに Inferred Service が表示されることに気づくでしょう。
Splunk APM は、リモートサービスを呼び出すスパンに含まれる情報から、存在が推論されるサービス、つまり、Inferred Service を検出することができます。Inferred Service として検出されるサービスの例としては、データベース、HTTPエンドポイント、メッセージキューなどがあります。Inferred Service は計装されていませんが、サービスマップとサービスリストに表示されます。
もうすこし詳細に確認してみましょう。
バックエンドアプリケーションでの問題特定・原因調査を行う方法は、6. Splunk APM で取り組んでいただくことが可能です。
お時間がある方は、更にいくつかの機能を確認してみましょう。
- Service Map をクリックします。
- あわせて Show Legend を開いてみましょう。この Service Map に表示されている内容の凡例です。
- Service Map は、アプリケーションの相関性を表すマップです。APM エージェントを利用すると、アプリケーション間での連携やリクエストから自動的に生成されます。
- 点線の四角や丸のオブジェクトは、Inferred Service です。これらは計装されていませんが、計装済みのアプリケーションが連携先として利用していると推定されたため、サービスマップ上にも表示されています。
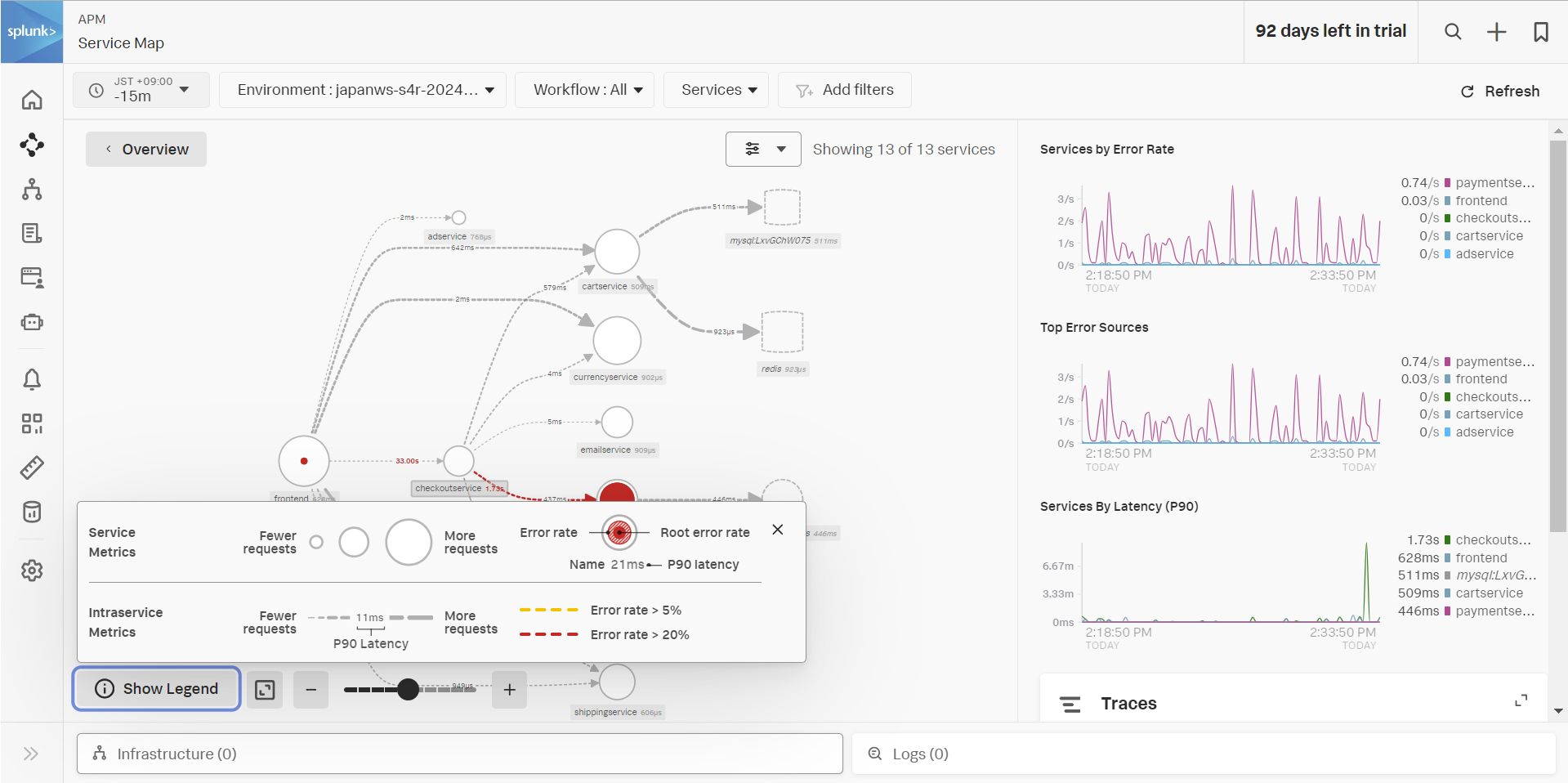
- エラー率が高いと、サービスマップ上ではどのように表示されますか?
- このシステムでは、どのようなDBを使用していますか?
- ヒント: DBは Inferred Service として、四角のオブジェクトで表示されます
- アプリケーションが赤くハイライトされます
- MySQLとRedisを使用しています
- Legend を開いている場合は閉じてください。
- エラーが頻発している paymentservice をクリックしてみましょう。
- 画面右側のメニューの表示が少し変わったはずです。paymentservice に関するメトリクスやメニューが表示されるようになりました。
- Breakdown をクリックし、version を探して、クリックしてみましょう。
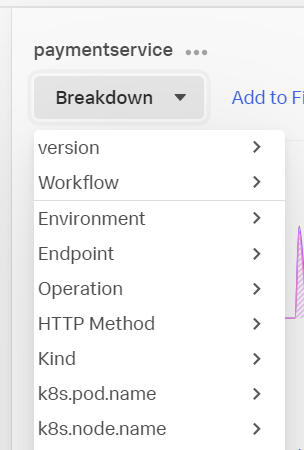
- Service Map の表示が変わり、paymentservice がアプリケーションのバージョンごとに表示されるようになったはずです。
- Splunk APM では、タグ情報に基づいてサービスマップ自体を変化させて分析することができます。非常に視覚的なので、このシステムに詳しくない人でも探索できそうですね!
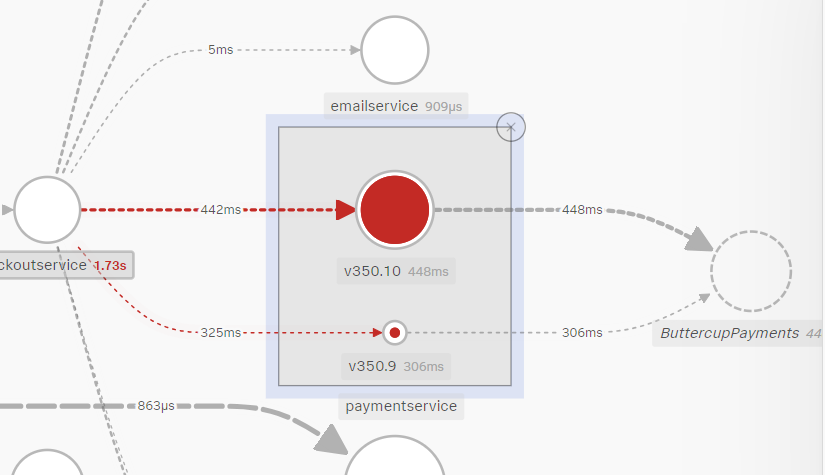
paymentservice を version ごとに分析すると、どういうことが分かりますか?
v350.10バージョンの方がエラー率が高いことが分かります
- v350.10 をクリックして、メニューのTraceを開いてみましょう。
- 画面右上に Switch to TraceAnalyzer というボタンがある場合は、これをクリックしてください。
- アプリケーションに対するリクエストが、どのように処理されたかをトレースし、エラーやボトルネックを特定したり、その処理の詳細を分析することができます
- この画面では、トレースの一覧が表示されます
- Errors Only のトグルを有効化してください。また、Duration をクリックして処理時間が長い順に並べ替えてください。
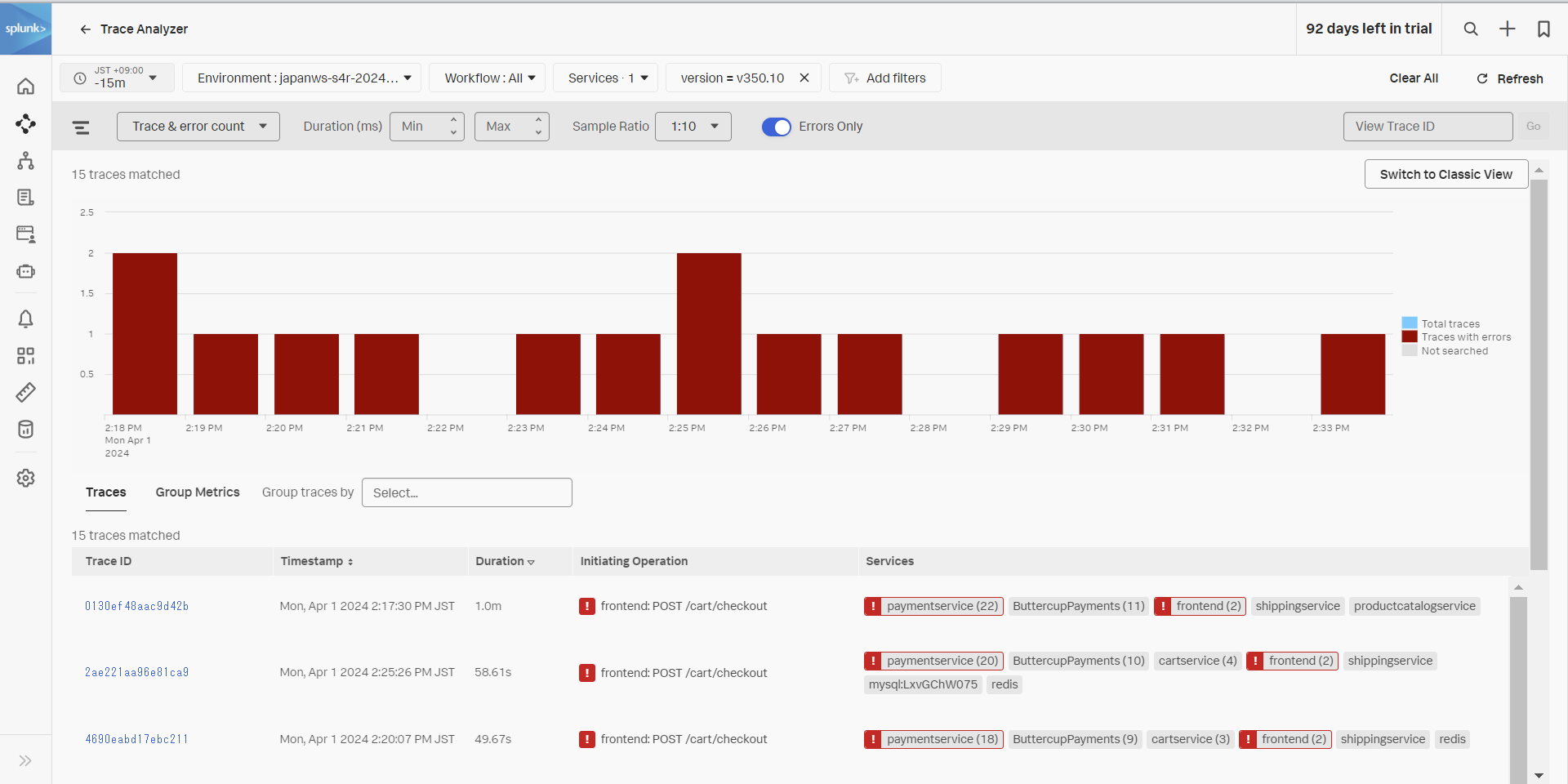
- 最も処理時間が長いトレースの Trace ID をクリックします。
- このトランザクションがどのように処理されたかを確認しましょう。
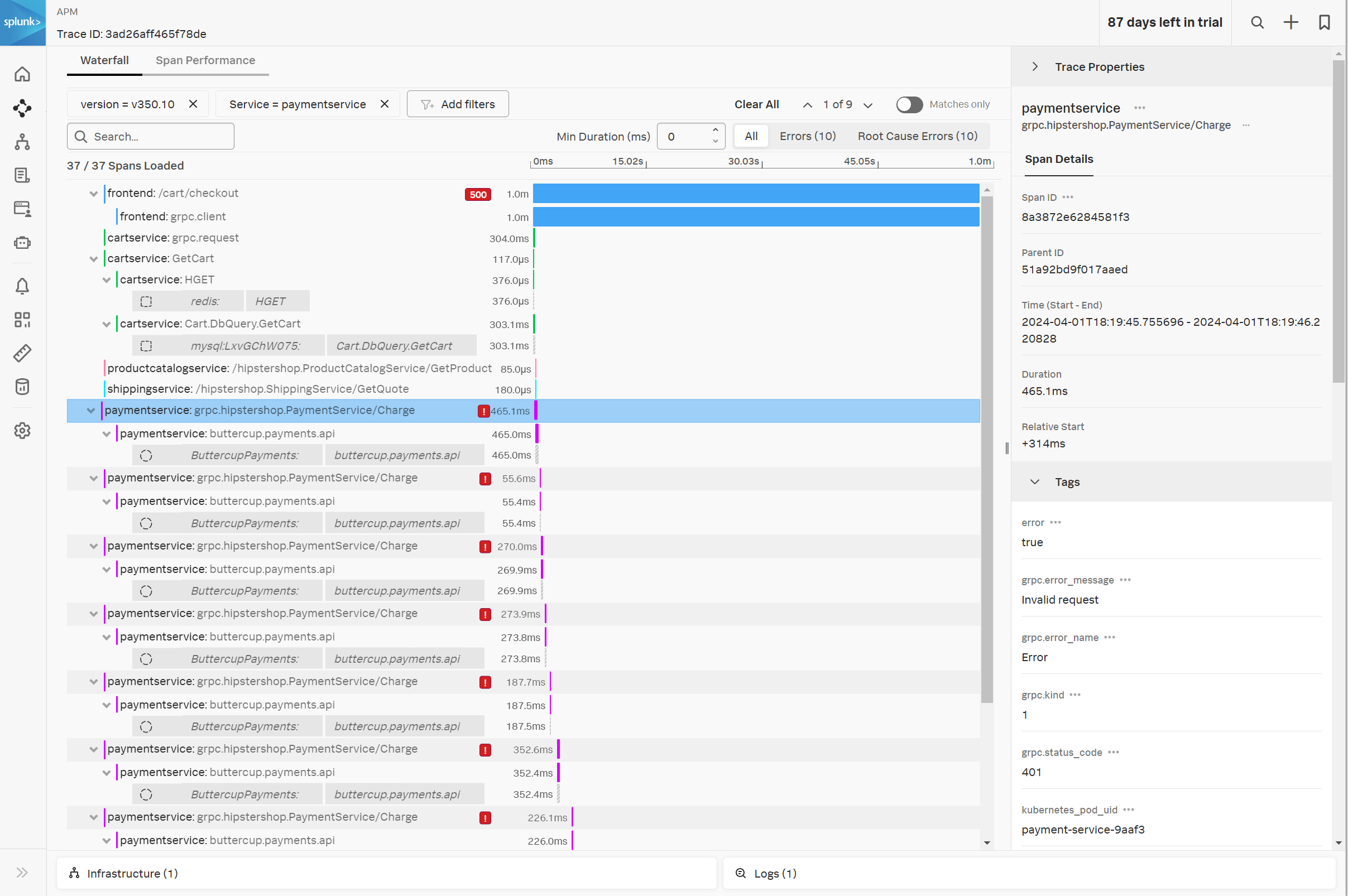
- 各行の処理を スパン(Span)、スパン全体を トレース(Trace) と呼びます。
- 赤とピンクの ! マークアイコンを見つけられますか? これはそれぞれ、一連のトランザクションの中でエラーを発生させたスパン(Root Cause Error)と、その影響で発生したエラーになったスパンとを区別して表示しています。
- 選択されたトレースによっては、ピンクの ! は表示されないかもしれません。
- いずれかのスパンをクリックすると、そのスパンに関連するタグ情報を確認することができます。
- 同じ処理が繰り返されている場合、スパンの左に x6 のように反復回数が表示されることがあります。
- 根本原因のエラーが発生しているサービスは何ですか?そのエラーメッセージは何ですか?
- このトレース処理に時間がかかっている原因として、どういったことが考えられますか?
- paymentserviceです。エラーメッセージは Invalid request を記録しています
- checkoutserviceとpaymentserviceでエラーが発生し、何度もリトライされていることで全体の処理時間が長くなっています
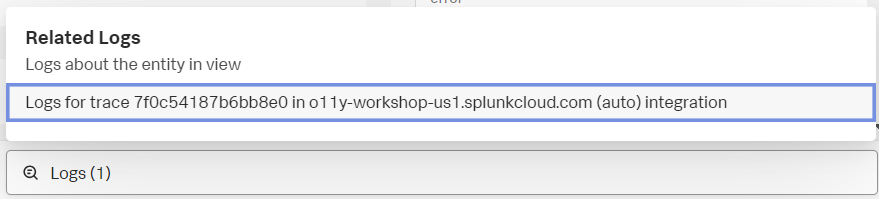
- 画面の最下部には Infrastructure や Logs というボタンが表示されているはずです。これらは、この処理と関連するシステムのコンポーネントやログの存在を教えてくれます。
- Logs をクリックし、Logs for trace … から始まる箇所をクリックしてみましょう。
- Log Observer の画面が表示されます。この画面では、先ほどのトレースに関連するログのみを自動で抽出して提示してくれています。
- Log Observer の使い方は、次のワークショップコースの中で扱います。
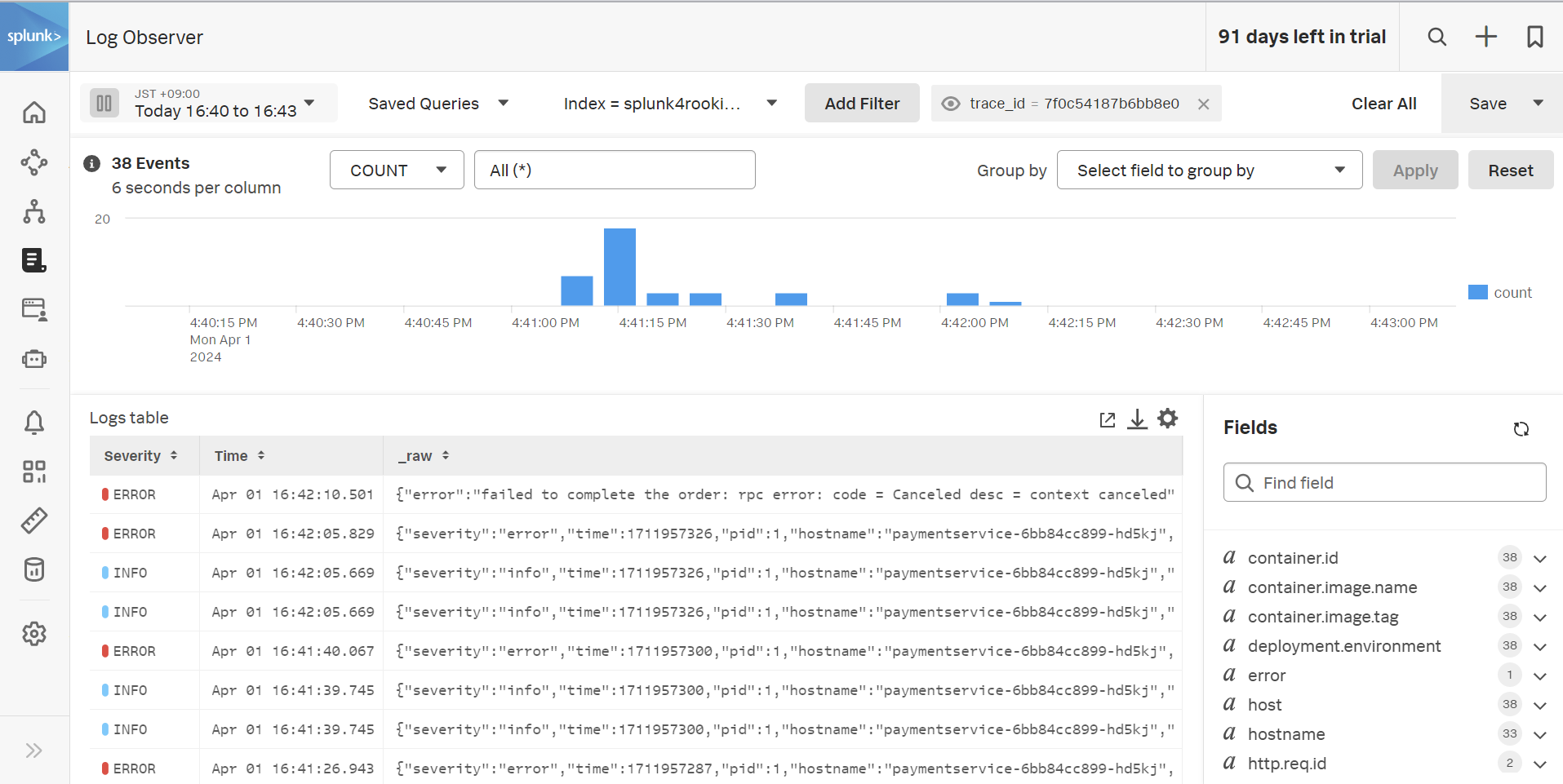
次に、Splunk Log Observer (LO) をチェックしましょう。