Splunk IMのサブセクション ワークショップ環境へのアクセス 5 分 各自に割り当てられたAWS/EC2インスタンスのIPアドレスを確認します SSH、Putty クラウド上にある AWS/EC2 インスタンスへの接続を確認します 1. AWS/EC2 の IP アドレス ワークショップの準備として、Splunk は AWS/EC2 に Ubuntu Linux インスタンスを用意しています。
ワークショップで使用するインスタンスにアクセスするには、ワークショップの講師が提供する Google Sheets のURLにアクセスしてください。
AWS/EC2 インスタンスの検索には、本ワークショップの登録時にご記入いただいたお名前を入力してください。
ワークショップのインスタンスに接続するためのIPアドレス、SSHコマンド(Mac OS、Linux、最新のWindowsバージョン用)、パスワードが表示されています。
また、ssh や putty で接続できない場合に使用するブラウザアクセスのURLも記載されています。「ブラウザ経由でEC2に接続する 」を参照してください。
可能であれば、SSH または Putty を使用してEC2インスタンスにアクセスしてください。
ワークショップで必要になるので、IPアドレスをメモしておいてください。
2. SSH (Mac OS/Linux/Windows 10) Mac や Linux、または Windows10 以上の端末から SSH を使ってワークショップに接続することができます。
SSH を使用するには、お使いのシステムでターミナルを開き、ssh ubuntu@x.x.x.xと入力してください(x.x.x.xをステップ1で見つけたIPアドレスに置き換えてください)。
Are you sure you want to continue connecting (yes/no/[fingerprint])?yes
ステップ1の Google Sheets に記載されているパスワードを入力してください。
ログインに成功すると、Splunk のロゴと Linux のプロンプトが表示されます。
これで データを取り込む に進む準備が整いました。
3. SSH (Windows 10以降) 上記の手順はWindows 10でも同様で、コマンドはコマンドプロンプトかPowerShellで実行できます。
しかしWindowsはSSHを「オプション機能」として用意しているため、場合によっては有効化が必要です。
SSHが有効化されているかどうか確認するには単純に ssh を実行してください。
sshコマンドに関するヘルプテキスト(下のスクリーンショット)が表示されれば、実行可能です。
もしこのスクリーンショットとは異なる結果が表示された場合は「OpenSSH クライアント」機能の有効化が必要です。
「設定」メニューを開き「アプリ」をクリックします。「アプリと機能」セクションの「オプション機能」をクリックします。
ここでインストール済みの機能の一覧が表示されます。上部にプラスアイコンが付いた「機能の追加」ボタンがあるためクリックします。
検索欄で「OpenSSH」と入力し「OpenSSH クライアント」を探し、チェックし、インストールボタンをクリックします。
これで設定作業完了です。もしOpenSSH機能を有効にしてもインスタンスにアクセスできない場合、講師までご連絡ください
これで データを取り込む 準備が整いました。
4. Putty (Windows 10以前の場合) ssh がプリインストールされていない場合や、Windows システムを使用している場合、putty がおすすめです。Putty は こちら からダウンロードできます。
Putty を開き、Host Name (or IP address) の欄に、Google Sheets に記載されているIPアドレスを入力してください。
名前を入力して Save を押すと、設定を保存することができます。
インスタンスにログインするには、Open ボタンをクリックします。
初めて AWS/EC2 ワークショップインスタンスに接続する場合は、セキュリティダイアログが表示されますので、Yes をクリックしてください。
接続されたら、ubuntu としてログインし、パスワードは Google Sheets に記載されているものを使用します。
接続に成功すると、以下のような画面が表示されます。
これで データを取り込む 準備が整いました。
5. ブラウザ経由でEC2に接続する SSH(ポート22) の使用が禁止されている場合や、Putty がインストールできない場合は、Webブラウザを使用してワークショップのインスタンスに接続することができます。
ここでは、6501番ポートへのアクセスが、ご利用のネットワークのファイアウォールによって制限されていないことを前提としています。
Webブラウザを開き、http:/x.x.x.x:6501 (X.X.X.Xは Google Sheetsに記載されたIPアドレス)と入力します。
接続されたら、ubuntu としてログインし、パスワードは Google Sheets に記載されているものを使用します。
接続に成功すると、以下のような画面が表示されます。
通常のSSHを使用しているときとは異なり、ブラウザセッションを使用しているときは、コピー&ペースト を使うための手順が必要です。これは、クロスブラウザの制限によるものです。
ワークショップで指示をターミナルにコピーするように言われたら、以下のようにしてください。
通常通り指示をコピーし、ウェブターミナルにペーストする準備ができたら、以下のように Paste from browser を選択します 。
すると、ウェブターミナルに貼り付けるテキストを入力するダイアログボックスが表示されます。
表示されているテキストボックスにテキストを貼り付け、OK を押すと、コピー&ペーストができます。
通常のSSH接続とは異なり、Webブラウザには60秒のタイムアウトがあり、接続が解除されると、Webターミナルの中央に Connect ボタンが表示されます。
この Connect ボタンをクリックするだけで、再接続され、次の操作が可能になります。
これで データを取り込む に進む準備が整いました。
6. Multipass (全員) AWSへはアクセスできないが、ローカルにソフトウェアをインストールできる場合は、「Multipassを使用する 」の手順に従ってください。
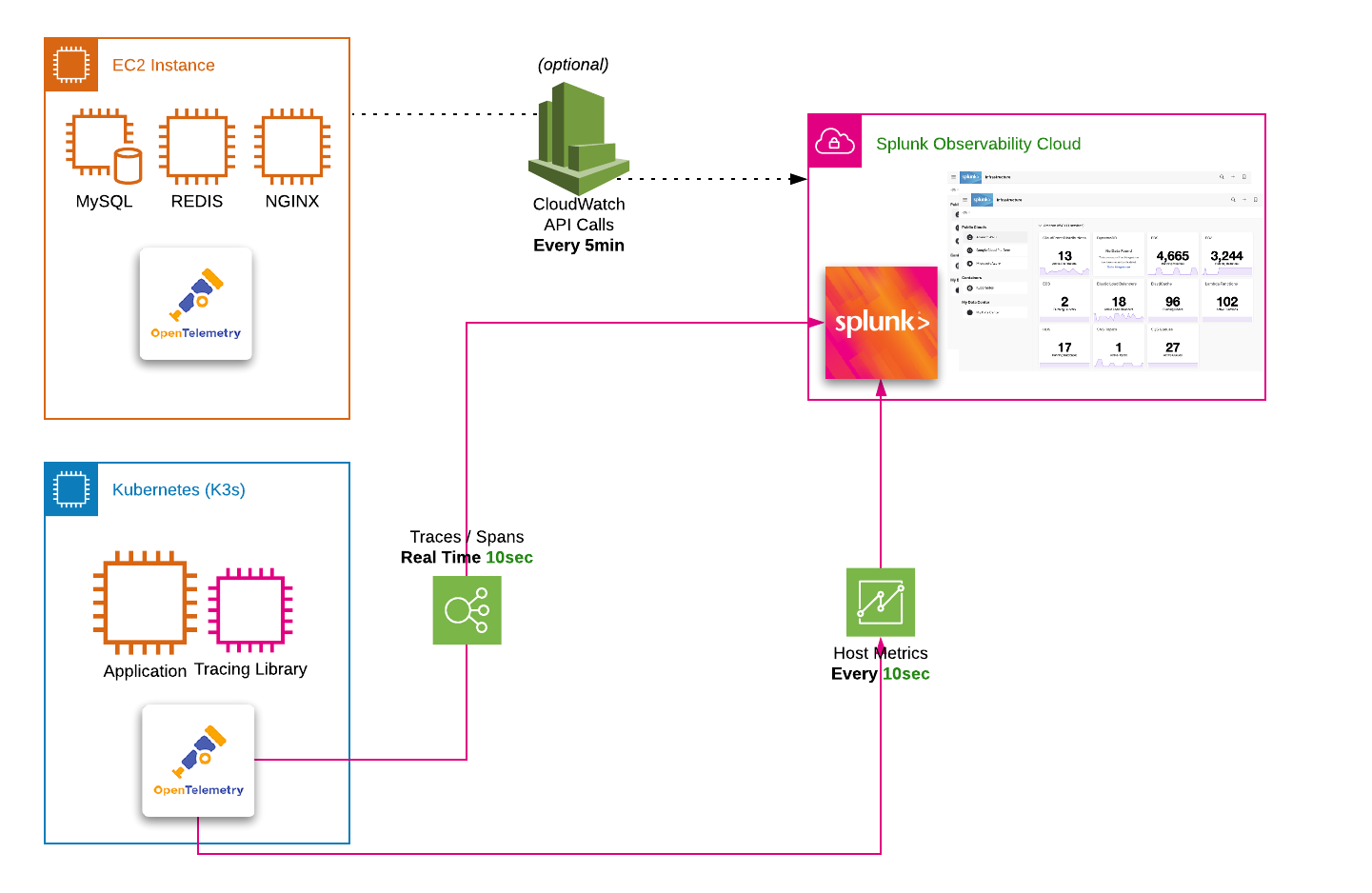
OpenTelemetry Collector を Kubernetes に導入する 15分 Splunk Helm chartを使用して、K3s に OpenTelemetry Collector をインストールします Kubernetes Navigatorでクラスタを探索します 1. Access Tokenの取得 Kubernetes が起動したら、Splunk の UI から Access Token» を開き、 Settings → Access Tokens を選択すると表示されます。
主催者が指示したワークショップトークン(例: O11y-Workshop-ACCESS 等)を開き、 Show Token をクリックしてトークンを公開します。Copy Default のトークンは使用しないでください。
独自のトークンを新たに作成しないようにしてください
このワークショップのために設定のトークンを作成し、IngestとAPIの両方の権限を割り当てています。実運用でのベストプラクティスは、1つのTokenにはIngestまたはAPIまたはRUMのような単一のパーミッションを割り当て、必要な場合は複数のトークンを使用することです。
また、Splunk アカウントの RealmAccount Settings ページに移動します。Organizations タブをクリックします。Realm はページの中央に表示されています。 この例では「us0」となっています。
2. Helmによるインストール 環境変数 ACCESS_TOKEN と REALM を作成して、進行中の Helm のインストールコマンドで使用します。例えば、Realm が us1 の場合は、export REALM=us1 と入力し、eu0 の場合は、export REALM=eu0 と入力します。
export ACCESS_TOKEN = "<replace_with_O11y-Workshop-ACCESS_TOKEN>" export REALM = "<replace_with_REALM>" Splunk Helm チャートを使って OpenTelemetry Collector をインストールします。まず、Splunk Helm chart のリポジトリを Helm に追加してアップデートします。
Helm Repo Add
Helm Repo Add Output helm repo add splunk-otel-collector-chart https://signalfx.github.io/splunk-otel-collector-chart && helm repo update Using ACCESS_TOKEN={REDACTED}
Using REALM=eu0
“splunk-otel-collector-chart” has been added to your repositories
Using ACCESS_TOKEN={REDACTED}
Using REALM=eu0
Hang tight while we grab the latest from your chart repositories…
…Successfully got an update from the “splunk-otel-collector-chart” chart repository
Update Complete. ⎈Happy Helming!⎈
以下のコマンドでOpenTelemetry Collector Helmチャートをインストールします。これは 変更しないでください 。
Helm Install
Helm Install Output helm install splunk-otel-collector --version 0.111.0 \
= "splunkObservability.realm= $REALM " \
= "splunkObservability.accessToken= $ACCESS_TOKEN " \
= "clusterName= $( hostname) -k3s-cluster" \
= "splunkObservability.logsEnabled=true" \
= "splunkObservability.profilingEnabled=true" \
= "splunkObservability.infrastructureMonitoringEventsEnabled=true" \
= "environment= $( hostname) -workshop" \
\
Using ACCESS_TOKEN={REDACTED}
Using REALM=eu0
NAME: splunk-otel-collector
LAST DEPLOYED: Fri May 7 11:19:01 2021
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
約30秒程度待ってから kubectl get pods を実行すると、新しいポッドが稼働していることが報告され、デプロイメントの進捗を監視することができます。
続行する前に、ステータスがRunningと報告されていることを確認してください。
Kubectl Get Pods
Kubectl Get Pods Output NAME READY STATUS RESTARTS AGE
splunk-otel-collector-agent-2sk6k 0/1 Running 0 10s
splunk-otel-collector-k8s-cluster-receiver-6956d4446f-gwnd7 0/1 Running 0 10s OpenTelemetry Collector podのログを確認して、エラーがないことを確認します。出力は、以下の出力例にあるログに似ているはずです。
ログを確認するには、helm のインストールで設定したラベルを使用してください(終了するには ctrl+c を押します)。もしくは、インストールされている k9s ターミナル UI を使うとボーナスポイントがもらえます!
Kubectl Logs
Kubectl Logs Output kubectl logs -l app = splunk-otel-collector -f --container otel-collector 2021-03-21T16:11:10.900Z INFO service/service.go:364 Starting receivers...
2021-03-21T16:11:10.900Z INFO builder/receivers_builder.go:70 Receiver is starting... {"component_kind": "receiver", "component_type": "prometheus", "component_name": "prometheus"}
2021-03-21T16:11:11.009Z INFO builder/receivers_builder.go:75 Receiver started. {"component_kind": "receiver", "component_type": "prometheus", "component_name": "prometheus"}
2021-03-21T16:11:11.009Z INFO builder/receivers_builder.go:70 Receiver is starting... {"component_kind": "receiver", "component_type": "k8s_cluster", "component_name": "k8s_cluster"}
2021-03-21T16:11:11.009Z INFO k8sclusterreceiver@v0.21.0/watcher.go:195 Configured Kubernetes MetadataExporter {"component_kind": "receiver", "component_type": "k8s_cluster", "component_name": "k8s_cluster", "exporter_name": "signalfx"}
2021-03-21T16:11:11.009Z INFO builder/receivers_builder.go:75 Receiver started. {"component_kind": "receiver", "component_type": "k8s_cluster", "component_name": "k8s_cluster"}
2021-03-21T16:11:11.009Z INFO healthcheck/handler.go:128 Health Check state change {"component_kind": "extension", "component_type": "health_check", "component_name": "health_check", "status": "ready"}
2021-03-21T16:11:11.009Z INFO service/service.go:267 Everything is ready. Begin running and processing data.
2021-03-21T16:11:11.009Z INFO k8sclusterreceiver@v0.21.0/receiver.go:59 Starting shared informers and wait for initial cache sync. {"component_kind": "receiver", "component_type": "k8s_cluster", "component_name": "k8s_cluster"}
2021-03-21T16:11:11.281Z INFO k8sclusterreceiver@v0.21.0/receiver.go:75 Completed syncing shared informer caches. {"component_kind": "receiver", "component_type": "k8s_cluster", "component_name": "k8s_cluster"} インストールに失敗した場合に削除する
OpenTelemetry Collectorのインストールに失敗した場合は、次のようにしてインストールを削除することで、最初からやり直すことができます。
helm delete splunk-otel-collector 3. UI でメトリクスを確認する Splunk の UI で左下の » を開いて Infrastructure をクリックします。
Containers の下にある Kubernetes をクリックして Kubernetes Navigator Cluster Map を開き、メトリクスが送信されていることを確認します。
クラスタが検出され、レポートされていることを確認するには、自分のクラスタを探します(ワークショップでは、他の多くのクラスタが表示されます)。クラスタ名を見つけるには、以下のコマンドを実行し、出力をクリップボードにコピーしてください。
echo $( hostname) -k3s-cluster次に、UIで、Splunkロゴのすぐ下にある「Cluster: - 」メニューをクリックし、先程コピーしたクラスタ名を検索ボックスに貼り付け、チェックボックスをクリックしてクラスタを選択し、最後にメニューのその他の部分をクリックしてフィルタを適用します。
ノードの状態を確認するには、クラスターの淡いブルーの背景にカーソルを置き、左上に表示される青い虫眼鏡をクリックしてください 。
これで、ノードレベルまでドリルダウンできます。 次に、サイドバーボタンをクリックしてサイドバーを開き、Metricsサイドバーを開きます。
サイドのスライダーを使って、CPU、メモリ、ネットワーク、イベントなど、クラスタ/ノードに関連する様々なチャートを見ることができます。
2. データを取り込むのサブセクション K3s に NGINX をデプロイする NGINX ReplicaSet を K3s クラスタにデプロイし、NGINX デプロイメントのディスカバリーを確認します。 負荷テストを実行してメトリクスを作成し、Splunk Observability Cloudにストリーミングすることを確認します! 1. NGINX の起動 Splunk UI で WORKLOADS タブを選択して、実行中の Pod の数を確認します。これにより、クラスタ上のワークロードの概要がわかるはずです。
デフォルトの Kubernetes Pod のうち、ノードごとに実行されている単一のエージェントコンテナに注目してください。この1つのコンテナが、このノードにデプロイされているすべての Pod とサービスを監視します!
次に、MAP タブを選択してデフォルトのクラスタノードビューに戻し、再度クラスタを選択します。
Multipass または AWS/EC2 のシェルセッションで、nginx ディレクトリに移動します。
2. NGINXのデプロイメント作成 NGINX の ConfigMapnginx.conf ファイルを使って作成します。
Kubectl Configmap Create
Kubectl Create Configmap Output kubectl create configmap nginxconfig --from-file= nginx.conf configmap/nginxconfig created 続いて、デプロイメントを作成します。
Kubectl Create Deployment
Kubectl Create Deployment Output kubectl create -f nginx-deployment.yaml deployment.apps/nginx created
service/nginx created
次に、NGINXに対する負荷テストを作成するため、 Locust
Kubectl Create Deployment
Kubectl Create Deployment Output kubectl create -f locust-deployment.yaml deployment.apps/nginx-loadgenerator created
service/nginx-loadgenerator created デプロイメントが成功し、Locust と NGINX Pod が動作していることを確認しましょう。
Splunk UI を開いていれば、新しい Pod が起動し、コンテナがデプロイされているのがわかるはずです。
Pod が実行状態に移行するまでには 20 秒程度しかかかりません。Splunk UIでは、以下のようなクラスタが表示されます。
もう一度 WORKLOADS タブを選択すると、新しい ReplicaSet と NGINX 用のデプロイメントが追加されていることがわかります。
これをシェルでも検証してみましょう。
Kubectl Get Pods
Kubectl Get Pods Output NAME READY STATUS RESTARTS AGE
splunk-otel-collector-k8s-cluster-receiver-77784c659c-ttmpk 1/1 Running 0 9m19s
splunk-otel-collector-agent-249rd 1/1 Running 0 9m19s
svclb-nginx-vtnzg 1/1 Running 0 5m57s
nginx-7b95fb6b6b-7sb9x 1/1 Running 0 5m57s
nginx-7b95fb6b6b-lnzsq 1/1 Running 0 5m57s
nginx-7b95fb6b6b-hlx27 1/1 Running 0 5m57s
nginx-7b95fb6b6b-zwns9 1/1 Running 0 5m57s
svclb-nginx-loadgenerator-nscx4 1/1 Running 0 2m20s
nginx-loadgenerator-755c8f7ff6-x957q 1/1 Running 0 2m20s 3. Locust の負荷テストの実行 Locust はオープンソースの負荷テストツールで、EC2 インスタンスの IP アドレスの8083番ポートで Locust が利用できるようになりました。Webブラウザで新しいタブを開き、http://{==EC2-IP==}:8083/にアクセスすると、Locust が動作しているのが確認できます。
Spawn rate を 2 に設定し、Start Swarming をクリックします。
これにより、アプリケーションに緩やかな連続した負荷がかかるようになります。
上記のスクリーンショットからわかるように、ほとんどのコールは失敗を報告しています。これはアプリケーションをまだデプロイしていないため予想されることですが、NGINXはアクセス試行を報告しており、これらのメトリックも見ることができます。
サイドメニューから Dashboards → Built-in Dashboard Groups → NGINX → NGINX Servers を選択して、UIにメトリクスが表示されていることを確認します。さらに Overrides フィルターを適用して、 k8s.cluster.name: に、ターミナルの echo $(hostname)-k3s-cluster で返されるクラスタの名前を見つけます。
ダッシュボードを利用する 20分 ダッシュボードとチャートの紹介 チャートの編集と作成 フィルタリングと分析関数 数式の使用 ダッシュボードでのチャートの保存 SignalFlowの紹介 1. ダッシュボード ダッシュボードとは、チャートをグループ化し、メトリクスを視覚化したものです。適切に設計されたダッシュボードは、システムに関する有益で実用的な洞察を一目で提供します。ダッシュボードは複雑なものもあれば、見たいデータだけを掘り下げたいくつかのチャートだけのものもあります。
このモジュールでは、次のようなチャートとダッシュボードを作成し、それをチームページに接続します。
2. あなたのチームのページ 左のナビゲーションから
ここでは、チーム Example Team
このページには、チームメンバーの総数、チームのアクティブなアラートの数、チームに割り当てられているすべてのダッシュボードが表示されます。現在、ダッシュボードは割り当てられていませんが、この後で、あなたが作成する新しいダッシュボードをチームページに追加していきます。
3. サンプルチャート 続けて、画面右上の All Dashboards をクリックします。事前に作成されたもの(プレビルドダッシュボード)も含め、利用可能なすべてのダッシュボードが表示されます。
すでにSplunk Agentを介してCloud APIインテグレーションや他のサービスからメトリクスを受信している場合は、これらのサービスに関連するダッシュボードが表示されます。
4. サンプルデータの確認 ダッシュボードの中に、 Sample Data というダッシュボードグループがあります。Sample Data ダッシュボードグループをクリックして展開し、Sample Charts ダッシュボードをクリックします。
Sample Charts ダッシュボードでは、ダッシュボードでチャートに適用できる様々なスタイル、色、フォーマットのサンプルを示すチャートが表示されます。
このダッシュボードグループのすべてのダッシュボード(PART 1 、PART 2 、PART 3 、INTRO TO SPLUNK OBSERVABILITY CLOUD )に目を通してみてください。
3. ダッシュボードのサブセクション チャートを編集する 1. チャートの編集 Sample Data ダッシュボードにある Latency histogram チャートの3点 ...Open をクリックします(または、チャートの名前をクリックしてください、ここでは Latency histogram です)。
チャートエディターのUIには、Latency histogram チャートのプロットオプション、カレントプロット、シグナル(メトリック)が表示されます。
Plot Editor タブの Signal には、現在プロットしている demo.trans.latency
いくつかの Line プロットが表示されます。18 ts
異なるチャートタイプのアイコンをクリックして、それぞれの表示を確認してください。スワイプしながらその名前を確認してください。例えば、ヒートマップのアイコンをクリックします。
チャートがヒートマップに変わります。
様々なチャートを使用してメトリクスを視覚化することができます。自分が望む視覚化に最も適したチャートタイプを選択してください。
各チャートタイプの詳細については、 Choosing a chart type を参照してください。
チャートタイプの Line をクリックすると、線グラフが表示されます。
2. タイムウィンドウの変更 また、Time ドロップダウンから Past 15 minutes に変更することで、チャートの時間枠を変更することができます。
3. データテーブルの表示 Data Table タブをクリックします。
18行が表示され、それぞれがいくつかの列を持つ時系列メトリックを表しています。これらの列は、メトリックのディメンションを表しています。demo.trans.latency のディメンジョンは次のとおりです。
demo_datacenterdemo_customerdemo_hostdemo_datacenterParis と Tokyo があることがわかります。
グラフの線上にカーソルを横に移動させると、それに応じてデータテーブルが更新されるのがわかります。チャートのラインの1つをクリックすると、データテーブルに固定された値が表示されます。
ここでもう一度 Plot editor をクリックしてデータテーブルを閉じ、このチャートをダッシュボードに保存して、後で使用しましょう。
チャートを保存する 1. チャートの保存 チャートの保存するために、名前と説明をつけましょう。チャートの名前 Copy of Latency Histogram をクリックして、名前を “現在のレイテンシー” に変更します。
説明を変更するには、 Spread of latency values across time. をクリックし、 リアルタイムでのレイテンシー値 に変更します。
Save As 現在のレイテンシー という名前が使用されますが、必要に応じてここで編集することができます。
Ok
2. ダッシュボードの作成 Choose dashboard ダイアログでは、新しいダッシュボードを作成する必要があります。New Dashboard
これで、New Dashboard ダイアログが表示されます。ここでは、ダッシュボードの名前と説明を付け、Write Permissions で書き込み権限を設定します。
ダッシュボードの名前には、自分の名前を使って YOUR_NAME-Dashboard の形式で設定してください。
YOUR_NAME を自分の名前に置き換えてから、編集権限をEveryone can Read or Write からRestricted Read and Write access に変更してみてください。
ここには、自分のログイン情報が表示されます。つまり、このダッシュボードを編集できるのは自分だけということになります。もちろん、ダッシュボードやチャートを編集できる他のユーザーやチームを下のドロップボックスから追加することもできますが、今回は、Everyone can Read or Write に 再設定 して制限を解除し、Save
新しいダッシュボードが利用可能になり、選択されましたので、チャートを新しいダッシュボードに保存することができます。
ダッシュボードが選択されていることを確認して、Ok
すると、下図のようにダッシュボードが表示されます。左上に、YOUR_NAME-DASHBOARD がダッシュボードグループ YOUR_NAME-Dashboard の一部であることがわかります。このダッシュボードグループに他のダッシュボードを追加することができます。
3. チームページへの追加 チームに関連するダッシュボードは、チームページにリンクさせるのが一般的です。そこで、後で簡単にアクセスできるように、ダッシュボードをチームページに追加してみましょう。
ナビバーのアイコンを再びクリックします。
これでチームダッシュボードに遷移します。ここでは、チーム Example Team
Add Dashboard Group ボタンを押して、チームページにダッシュボードを追加します。
すると、 Select a dashboard group to link to this team ダイアログが表示されます。
検索ボックスにご自身のお名前(上記で使用したお名前)を入力して、ダッシュボードを探します。ダッシュボードがハイライトされるように選択し、Ok ボタンをクリックしてダッシュボードを追加します。
ダッシュボードグループがチームページの一部として表示されます。ワークショップを進めていくと、さらに多くのダッシュボードがここに表示されていくはずです。
次のモジュールでは、ダッシュボードのリンクをクリックして、チャートをさらに追加していきます!
3.3 フィルタと数式の使い方 1 新しいチャートの作成 それでは、新しいチャートを作成し、ダッシュボードに保存してみましょう。
UIの右上にある + アイコンを選択し、ドロップダウンから Chart を選択します。
または、
これで、以下のようなチャートのテンプレートが表示されます。
プロットするメトリックを入力してみましょう。ここでは、demo.trans.latency
Plot Editor タブの Signal に demo.trans.latency
すると、折れ線グラフが表示されるはずです。時間を15分に切り替えてみてください。
2. フィルタリングと分析 次に、Paris データセンターを選択して分析を行ってみましょう。そのためにはフィルタを使用します。
Plot Editor タブに戻り、Add Filter demo_datacenterParis
F(x) 欄に分析関数 Percentile:Aggregation95
Percentile 関数やその他の関数の情報は、Chart Analytics を参照してください。
3. タイムシフト分析を追加 それでは、以前のメトリックと比較してみましょう。...Clone をクリックし、Signal A をクローンします。
A と同じような新しい行が B という名前で表示され、プロットされているのがわかります。
シグナル B に対して、F(x) 列に分析関数 Timeshift を追加し、1w7d でも同じ意味です)と入力し、外側をクリックして反映させます。
右端の歯車をクリックして、Plot Color を選択(例:ピンク)すると、 B のプロットの色を変更できます。
Close をクリックして、設定を終えます。
シグナル A (過去15分)のプロットが青、1週間前のプロットがピンクで表示されています。
より見やすくするために、Area chart アイコンをクリックして表示方法を変更してみましょう。
これで、前週にレイテンシーが高かった時期を確認することができます。
次に、Override バーの Time の隣にあるフィールドをクリックし、ドロップダウンから Past Hour
4. 計算式を使う ここでは、1日と7日の間のすべてのメトリック値の差をプロットしてみましょう。
Enter Formula A-BC を除くすべてのシグナルを隠します(目アイコンの選択を解除します)。
これで、 A と B のすべてのメトリック値の差だけがプロットされているのがわかります。B のメトリック値が、その時点での A のメトリック値よりも何倍か大きな値を持っているためです。
次のモジュールで、チャートとディテクターを動かすための SignalFlow を見てみましょう。
3.4 SignalFlow 1. はじめに ここでは、Observability Cloud の分析言語であり、Monitoring as Codeを実現するために利用する SignalFlow について見てみましょう。
Splunk Infrastructure Monitoring の中心となるのは、Python ライクな、計算を実行する SignalFlow 分析エンジンです。SignalFlow のプログラムは、ストリーミング入力を受け取り、リアルタイムで出力します。SignalFlow には、時系列メトリック(MTS)を入力として受け取り、計算を実行し、結果の MTS を出力する分析関数が組み込まれています。
過去の基準との比較する(例:前週との比較) 分布したパーセンタイルチャートを使った母集団の概要を表示する 変化率(またはサービスレベル目標など、比率で表されるその他の指標)が重要な閾値を超えたかどうか検出する 相関関係にあるディメンジョンの発見する(例:どのサービスの挙動がディスク容量不足の警告と最も相関関係にあるかの判断する) Infrastructure Monitoring は、Chart Builder ユーザーインターフェイスでこれらの計算を行い、使用する入力 MTS とそれらに適用する分析関数を指定できます。また、SignalFlow API を使って、SignalFlow のプログラムを直接実行することもできます。
SignalFlow には、時系列メトリックを入力とし、そのデータポイントに対して計算を行い、計算結果である時系列メトリックを出力する、分析関数の大規模なライブラリが組み込まれています。
2. SignalFlow の表示 チャートビルダーで View SignalFlow をクリックします。
作業していたチャートを構成する SignalFlow のコードが表示されます。UI内で直接 SignalFlow を編集できます。ドキュメントには、SignalFlow の関数やメソッドの 全てのリスト が掲載されています。
また、SignalFlow をコピーして、API や Terraform とやり取りする際に使用して、Monitoring as Code を実現することもできます。
A = data ( 'demo.trans.latency' , filter = filter ( 'demo_datacenter' , 'Paris' )) . percentile ( pct = 95 ) . publish ( label = 'A' , enable = False )
B = data ( 'demo.trans.latency' , filter = filter ( 'demo_datacenter' , 'Paris' )) . percentile ( pct = 95 ) . timeshift ( '1w' ) . publish ( label = 'B' , enable = False )
C = ( A - B ) . publish ( label = 'C' ) View Builder をクリックすると、Chart Builder の UI に戻ります。
この新しいチャートをダッシュボードに保存してみましょう!
ダッシュボードにチャートを追加する 1. 既存のダッシュボードに保存する 右上に YOUR_NAME-Dashboard と表示されていることを確認しましょう
これは、あなたのチャートがこのダッシュボードに保存されることを意味します。
チャートの名前を Latency History とし、必要に応じてチャートの説明を追加します。
Save And Close
2. チャートのコピー&ペースト ダッシュボードの Latency History チャート上の3つのドット ...Copy をクリックします。
ページ左上の + の横に赤い円と白い1が表示されていれば、チャートがコピーされているということになります。
ページ上部の Paste Charts をクリックしてください (また、右側に 1 が見える赤い点があるはずです)。
これにより、先程のチャートのコピーがダッシュボードに配置されます。
3. 貼り付けたチャートを編集する ダッシュボードの Latency History チャートの3つの点 ...Open をクリックします(または、チャートの名前(ここでは Latency History )をクリックすることもできます)。
すると、再び編集できる環境になります。
まず、チャートの右上にあるタイムボックスで、チャートの時間を -1h(1時間前から現在まで) に設定します。そして、シグナル「A 」の前にある目のアイコンをクリックして再び表示させ、「C 」 を非表示にし、Latency history の名前を Latency vs Load に変更します。
Add Metric Or Event D に demo.trans.count と入力・選択します。
これにより、チャートに新しいシグナル D が追加され、アクティブなリクエストの数が表示されます。demo_datacenter:Paris のフィルタを追加してから、 Configure Plot ボタンをクリックしロールアップを Auto (Delta) から Rate/sec に変更します。名前を demo.trans.count から Latency vs Load に変更します。
最後に Save And Close
次のモジュールでは、「説明」のメモを追加して、チャートを並べてみましょう!
ノートの追加とダッシュボードのレイアウト 1. メモの追加 ダッシュボードには、ダッシュボードの利用者を支援するための短い「説明」ペインを配置することがよくあります。
ここでは、New Text Note
すると、ノートエディターが開きます。
ノートに単なるテキスト以外のものを追加できるように、Splunk ではこれらのノート/ペインで Markdown を使用できるようにしています。
Markdown は、ウェブページでよく使われるプレーンテキストを使ってフォーマットされたテキストを作成するための軽量なマークアップ言語です。
たとえば、以下のようなことができます (もちろん、それ以外にもいろいろあります)。
ヘッダー (様々なサイズで) 強調スタイル リストとテーブル リンク: 外部の Web ページ (ドキュメントなど) や他の Splunk IM ダッシュボードへの直接リンクできます 以下は、ノートで使用できる上記のMarkdownオプションの例です。
# h1 Big headings
###### h6 To small headings
##### Emphasis
**This is bold text** , *This is italic text* , ~~Strikethrough~~
##### Lists
Unordered
+ Create a list by starting a line with `+` , `-` , or `*`
- Sub-lists are made by indenting 2 spaces:
- Marker character change forces new list start:
* Ac tristique libero volutpat at
+ Facilisis in pretium nisl aliquet
* Very easy!
Ordered
1. Lorem ipsum dolor sit amet
2. Consectetur adipiscing elit
3. Integer molestie lorem at massa
##### Tables
| Option | Description |
| ------ | ----------- |
| chart | path to data files to supply the data that will be passed into templates. |
| engine | engine to be used for processing templates. Handlebars is the default. |
| ext | extension to be used for dest files. |
#### Links
[link to webpage ](https://www.splunk.com )
[link to dashboard with title ](https://app.eu0.signalfx.com/#/dashboard/EaJHrbPAEAA?groupId=EaJHgrsAIAA&configId=EaJHsHzAEAA "Link to the Sample chart Dashboard!" ) 上記をコピーボタンでコピーして、Edit ボックスにペーストしてみてください。
プレビューで、どのように表示されるか確認できます。
2. チャートの保存 ノートチャートに名前を付けます。この例では、Example text chart としました。そして、Save And Close
これでダッシュボードに戻ると、メモが追加されました。
3. チャートの順序や大きさを変更 デフォルトのチャートの順番やサイズを変更したい場合は、ウィンドウをドラッグして、チャートを好きな場所に移動したり、サイズを変更したりすることができます。
チャートの 上側の枠 にマウスポインタを移動すると、マウスポインタがドラッグアイコンに変わります。これで、チャートを任意の場所にドラッグすることができます。
ここでは、 Latency vs Load チャートを Latency History と Example text chart の間に移動してください。
チャートのサイズを変更するには、側面または底面をドラッグします。
最後の練習として、ノートチャートの幅を他のチャートの3分の1程度にしてみましょう。チャートは自動的に、サポートしているサイズの1つにスナップします。他の3つのチャートの幅を、ダッシュボードの約3分の1にします。ノートを他のチャートの左側にドラッグして、他の23個のチャートに合わせてサイズを変更します。
最後に、時間を -1h に設定すると、以下のようなダッシュボードになります。
次は、ディテクターの登場です!
ディテクターを利用する 10 分 チャートからディテクターを作成する アラート条件を設定する プリフライトチェックを実行する ミューティングルールを設定する 1. はじめに Splunk Observability Cloud では、ディテクター(検出器)、イベント、アラート、通知を使用して、特定の条件が満たされたときに情報を提供することができます。たとえば、CPU使用率が95%に達したときや、同時ユーザー数が制限値に近づいてAWSインスタンスを追加で立ち上げなければならない可能性があるときに、Slack チャンネルや Ops チームのメールアドレスにメッセージを送信したいと考えるでしょう。
これらの条件は1つまたは複数のルールとして表現され、ルール内の条件が満たされたときにアラートが発生します。ディテクターに含まれる個々のルールは、重要度に応じてラベル付けされています。Info、Warning、Minor、Major、Criticalとなっています。
2. ディテクターの作成 Dashboards で、前のモジュールで作成した Custom Dashboard Group をクリックし、ダッシュボードの名前をクリックします。
このチャートから、新しいディテクターを作成していきます。Latency vs Load チャート上のベルのアイコンをクリックし、 New Detector From Chart をクリックします。
Detector Name の横にあるテキストフィールドで、提案されたディテクター名の最初に、あなたのイニシャル を追加してください。
提案されたディテクター名の前に自分のイニシャルを追加することをお忘れなく。
次のような名前にしてください: XY’s Latency Chart Detector
Click on Create Alert Rule
Detector ウィンドウの Alert signal の中で、アラートするシグナルは Alert on 欄に青のベルが表示されています。このベルは、どのシグナルがアラートの生成に使用されているかを示しています。
Click on Proceed to Alert Condition
3. アラート条件の設定 Alert condition で、Static Threshold をクリックし、Proceed to Alert Settings
Alert Settings で、 Threshold フィールドに値 290Time を過去1日(-1d )に変更します。
4. プリフライトチェックの警告 5秒後にプリフライトチェックが行われます。Estimated alert count に、アラート回数の目安が表示されます。現在のアラート設定では、1日に受信するアラート量は 3 となります。
アラート条件を設定すると、UIは現在の設定に基づいて、右上に設定された時間枠(ここでは過去1日)の中で、どのくらいのアラートが発生するかを予測します。
すぐに、プラットフォームは現在の設定でシグナルの分析を開始し、「プリフライトチェック」と呼ばれる作業を行います。これにより、プラットフォーム内の過去のデータを使用してアラート条件をテストし、設定が妥当であり、誤って大量のアラートを発生させないようにすることができます。Splunk Observability Cloud を使用してのみ利用できるシンプルかつ非常に強力な方法で、アラートの設定から推測作業を取り除くことができます。
ディテクターのプレビューについての詳細は、こちらのリンクをご覧ください。
Preview detector alerts
Proceed to Alert Message
5. アラートメッセージ Alert message の Severity で Major を選択します。
Proceed to Alert Recipients
Add Recipient (受信者の追加)をクリックし、最初の選択肢として表示されているメールアドレスをクリックします。
これは、そのメールアドレスを入力したときと同じです。または、E-mail… をクリックして別のメールアドレスを入力することもできます。
これは、予め用意されている多くの Notification Services の一例です。全てを確認するには、トップメニューの Integrations タブに移動し、Notification Services を参照してください。
6. アラートの有効化 Proceed to Alert Activation
Activivate… で Activate Alert Rule
アラートをより早く取得したい場合は、Alert Settings をクリックして、値を 290280
Time を -1h に変更すると、過去1時間のメトリクスに基づいて、選択した閾値でどれだけのアラートを取得できるかを確認できます。
ナビバーにある Detectors をクリックすると、ディテクターの一覧が表示されます。あなたのイニシャルでフィルタして、作成したディテクターを確認しましょう。表示されない場合は、ブラウザをリロードしてみてください。
おめでとうございます! 最初のディテクターが作成され、有効化されました。
4 ディテクターのサブセクション ミューティングルールを利用する 1. ミューティングルールの設定 特定の通知をミュートする必要がある場合があります。例えば、サーバーやサーバー群のメンテナンスのためにダウンタイムを設定したい場合や、新しいコードや設定をテストしている場合などがあります。このような場合には、Splunk Observability Cloud でミューティングルールを使用できます。それでは作成してみましょう。
ナビバーにある Detectors を選択します。現在設定されているディテクターの一覧が表示されます。フィルタを使ってディテクターを探すこともできます。
Creating a Detector でディテクターを作成した場合は、右端の3つの点 ...
ドロップダウンから Create Muting Rule… をクリックします。
Muting Rule ウィンドウで、 Mute Indefinitely をチェックし、理由を入力します。
この操作をすると、ここに戻ってきてこのボックスのチェックを外すか、このディテクターの通知を再開するまで、通知が永久的にミュートされます。
Next をクリックして、新しいモーダルウィンドウでミュートルールの設定を確認します。
Mute Indefinitely
これで、通知を再開するまで、ディテクターからのEメール通知は受け取ることがなくなりました。では、再開する方法を見てみましょう。
2. 通知を再開する Muting Rules をクリックして、Detector の見出しの下に、通知をミュートしたディテクターの名前が表示されます。
右端にあるドット ...Resume Notifications をクリックします。
Resume
おめでとうございます! これでアラート通知が再開されました。
Monitoring as Code 10分 Terraform Terraform のSplunk Provider Terraformを実行して、Splunk Terraform Provider を使用してコードからディテクターとダッシュボードを作成します。 Terraformでディテクターやダッシュボードを削除する方法を確認します。 1. 初期設定 Monitoring as Codeは、infrastructure as Codeと同じアプローチを採用しています。アプリケーション、サーバー、その他のインフラコンポーネントと同じようにモニタリングを管理できます。
Monitoring as Codeでは、可視化したり、何を監視するか定義したり、いつアラートを出すかなどを管理します。つまり、監視設定、プロセス、ルールをバージョン管理、共有、再利用することができます。
Splunk Terraform Providerの完全なドキュメントはこちら にあります。
AWS/EC2 インスタンスにログインして、o11y-cloud-jumpstart ディレクトリに移動します
cd observability-content-contrib/integration-examples/terraform-jumpstart必要な環境変数は、Helmによるインストール ですでに設定されているはずです。そうでない場合は、以下の Terraform のステップで使用するために、以下の環境変数を作成してください。
export ACCESS_TOKEN = "<replace_with_O11y-Workshop-ACCESS_TOKEN>" export REALM = "<replace_with_REALM>" Terraform を初期化し、Splunk Terraform Provider を最新版にアップグレードします。
Splunk Terraform Provider の新バージョンがリリースされるたびに、以下のコマンドを実行する必要があります。リリース情報は GitHub で確認できます。
Initialise Terraform
Initialise Output Upgrading modules...
- aws in modules/aws
- azure in modules/azure
- docker in modules/docker
- gcp in modules/gcp
- host in modules/host
- kafka in modules/kafka
- kubernetes in modules/kubernetes
- parent_child_dashboard in modules/dashboards/parent
- pivotal in modules/pivotal
- rum_and_synthetics_dashboard in modules/dashboards/rum_and_synthetics
- usage_dashboard in modules/dashboards/usage
Initializing the backend...
Initializing provider plugins...
- Finding latest version of splunk-terraform/signalfx...
- Installing splunk-terraform/signalfx v6.20.0...
- Installed splunk-terraform/signalfx v6.20.0 (self-signed, key ID CE97B6074989F138)
Partner and community providers are signed by their developers.
If you'd like to know more about provider signing, you can read about it here:
https://www.terraform.io/docs/cli/plugins/signing.html
Terraform has created a lock file .terraform.lock.hcl to record the provider
selections it made above. Include this file in your version control repository
so that Terraform can guarantee to make the same selections by default when
you run "terraform init" in the future.
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary. 2. プランの作成 terraform plan コマンドで、実行計画を作成します。デフォルトでは、プランの作成は以下のように構成されています。
既に存在するリモートオブジェクトの現在の状態を読み込み、Terraform の状態が最新であることを確認します 現在の設定を以前の状態と比較し、相違点を抽出します 適用された場合にリモートオブジェクトと設定とを一致させるための、一連の変更アクションを提案します plan コマンドだけでは、提案された変更を実際に実行はされなません。変更を適用する前に、以下のコマンドを実行して、提案された変更が期待したものと一致するかどうかを確認しましょう。
Execution Plan
Execution Plan Output terraform plan -var= "access_token= $ACCESS_TOKEN " -var= "realm= $REALM " -var= "o11y_prefix=[ $( hostname) ]" Plan: 146 to add, 0 to change, 0 to destroy. プランが正常に実行されれば、そのまま apply することができます。
3. プランの適用 terraform apply コマンドは、上記の Terraform プランで提案されたアクションを実行します。
この場合、新しい実行プランが自動的に作成され(terraform planを実行したときと同様です)、指示されたアクションを実行する前にAccess Token、Realm(プレフィックスのデフォルトはSplunk)の提供とプランの承認を求められます。
このワークショップでは、プレフィックスがユニークである必要があります。以下の terraform apply を実行してください。
Apply Plan
Apply Plan Output terraform apply -var= "access_token= $ACCESS_TOKEN " -var= "realm= $REALM " -var= "o11y_prefix=[ $( hostname) ]" Apply complete! Resources: 146 added, 0 changed, 0 destroyed. 適用が完了したら、 Alerts → Detectors でディテクターが作成されたことを確認してください。ディテクターのプレフィックスには、インスタンスのホスト名が入ります。プレフィックスの値を確認するには以下を実行してください。
新しいディテクターのリストが表示され、上から出力されたプレフィックスを検索することができます。
4. 苦労して作ったもの全てを壊す terraform destroy コマンドは、Terraform の設定で管理されているすべてのリモートオブジェクトを破壊する便利な方法です。
通常、本番環境では長期保存可能なオブジェクトを破棄することはありませんが、Terraformでは開発目的で一時的なインフラを管理するために使用されることがあり、その場合は作業が終わった後に terraform destroy を実行して、一時的なオブジェクトをすべてクリーンアップすることができます。
それでは、ここまでで適用したダッシュボードとディテクターを全て破壊しましょう!
terraform destroy -var= "access_token= $ACCESS_TOKEN " -var= "realm= $REALM " Destroy complete! Resources: 146 destroyed. Alerts → Detectors
管理機能 10分 組織におけるObservability Cloudの利用状況を把握する Subscription Usage(サブスクリプション使用量)インターフェースを使って、使用量を追跡する チームを作成する チームへの通知ルールを管理する 使用量をコントロールする 1. 利用状況を把握する 組織内のObservability Cloudのエンゲージメントを完全に把握するには、左下 » を開き、Settings → Organization Overview を選択すると、Observability Cloud の組織がどのように使用されているかを示す以下のダッシュボードが表示されます。
左側のメニューには、メンバーのリストが表示され、右側には、ユーザー数、チーム数、チャート数、ダッシュボード数、ダッシュボードグループの作成数、様々な成長傾向を示すチャートが表示されます。
現在お使いのワークショップ組織では、ワークショップごとにデータが消去されるため、作業できるデータが少ないかもしれません。
このワークショップインスタンスの Organization Overview にある様々なチャートをじっくりとご覧ください。
2. Subscription Usage 契約に対する使用量を確認したい場合は、 Subscription Usage を選択します。
この画面では、使用量を計算して取り込むため、読み込みに数秒かかることがあります。
3. 使用量を理解する 下図のような画面が表示され、現在の使用量、平均使用量、およびホスト、コンテナ、カスタムメトリクス、高解像度メトリクスの各カテゴリごとの権利の概要が表示されます。
これらのカテゴリの詳細については、Monitor Splunk Infrastructure Monitoring subscription usage を参照してください。
4. 使用状況を詳しく調べる 一番上のチャートには、カテゴリーごとの現在のサブスクリプションレベルが表示されます(下のスクリーンショットでは、上部の赤い矢印で表示されています)。
また、4つのカテゴリーの現在の使用状況も表示されます(チャート下部の赤い線で示されています)。
この例では、「ホスト」が25個、「コンテナ」が0個、「カスタムメトリクス」が100個、「高解像度メトリクス」が0個であることがわかります。
下のグラフでは、現在の期間のカテゴリごとの使用量が表示されています(グラフの右上のドロップダウンボックスに表示されています)。
Average Usage と書かれた青い線は、Observability Cloudが現在のサブスクリプション期間の平均使用量を計算するために使用するものを示しています。
スクリーンショットからわかるように、Observability Cloudはコスト計算には最大値や95パーセンタイル値ではなく、実際の平均時間使用量を使用しています。これにより、超過料金のリスクなしに、パフォーマンステストやBlue/Greenスタイルのデプロイメントなどを行うことができます。
オプションを確認するには、左の Usage Metric ドロップダウンから異なるオプションを選択して表示するメトリックを変更するか、右のドロップダウンで Billing Period を変更します。
また、右側のドロップダウンでサブスクリプション期間を変更することもできます。
最後に、右側のペインには、お客様のサブスクリプションに関する情報が表示されます。
6 管理機能のサブセクション チーム 1. チームの管理 Observability Cloudを使用する際に、ユーザーに関連するダッシュボードやアラートが表示されるようにするために、ほとんどの組織ではObservability Cloudのチーム機能を使用して、メンバーを1つまたは複数のチームに割り当てます。
これは、仕事に関連した役割と一致するのが理想的で、たとえば、DevOpsグループやプロダクトマネジメントグループのメンバーは、Observability Cloudの対応するチームに割り当てられます。
ユーザーがObservability Cloudにログインすると、どのチームダッシュボードをホームページにするかを選択することができ、通常は自分の主な役割に応じたページを選択します。
以下の例では、ユーザーは開発、運用、プロダクトマネジメントの各チームのメンバーであり、現在は運用チームのダッシュボードを表示しています。
このダッシュボードには、NGINX、Infra、K8s用の特定のダッシュボード・グループが割り当てられていますが、どのダッシュボード・グループもチーム・ダッシュボードにリンクすることができます。
左上のメニューを使って割り当てられたチーム間を素早く移動したり、右側の ALL TEAMS ドロップダウンを使って特定のチームのダッシュボードを選択したり、隣のリンクを使って ALL Dashboards に素早くアクセスしたりすることができます。
アラートを特定のチームにリンクすることで、チームは関心のあるアラートだけをモニターすることができます。上記の例では、現在1つのアクティブなクリティカルアラートがあります。
チームダッシュボードの説明文はカスタマイズ可能で、チーム固有のリソースへのリンクを含むことができます(Markdownを使用します)。
2. 新しいチームの作成 Splunk のチーム UI を使用するには、左下の » を開き、 Settings → Teams を選択します。
Team を選択すると、現在のチームのリストが表示されます。
新しいチームを追加するには、Create New Team Create New Team ダイアログが表示されます。
独自のチームを作ってみましょう。チーム名を [あなたのイニシャル]-Team のように入力し、あなた自身のユーザー選んで、Add リンクからチームに追加してみましょう。上手くいくと、次のような表示になるはずです。
選択したユーザーを削除するには、Remove または x を押します。
自分のイニシャルでグループを作成し、自分がメンバーとして追加されていることを確認して、Done
これでチームリストに戻り、自分のチームと他の人が作成したチームが表示されます。
自分がメンバーになっているチームには、グレーの Member アイコンが前に表示されています。
自分のチームにメンバーが割り当てられていない場合は、メンバー数の代わりに青い Add Members のリンクが表示されます。このリンクをクリックすると、Edit Team ダイアログが表示され、自分を追加することができます。
自分のチームの行末にある3つのドット … を押しても、Edit Team と同じダイアログが表示されます。
… メニューでは、チームの編集、参加、離脱、削除を行うことができます(離脱と参加は、あなたが現在メンバーであるかどうかによって異なります)。
3. 通知ルールの追加 チームごとに特定の通知ルールを設定することができます。Notification Policy タブをクリックすると、通知編集メニューが表示されます。
デフォルトでは、システムはチームの一般的な通知ルールを設定する機能を提供します。
Email all team members オプションは、アラートの種類に関わらず、このチームのすべてのメンバーにアラート情報のメールが送信されることを意味します。
3.1 受信者の追加 Add Recipient
Configure separate notification tiers for different severity alerts をクリックすると、各アラートレベルを個別に設定できます。
上の画像のように、異なるアラートレベルに対して異なるアラートルールを設定することができます。
Critical と Major は Splunk On-Call インシデント管理ソリューションを使用しています。Minor のアラートはチームの Slack チャンネルに送信し、Warning と Info はメールで送信する、という管理もできるようになります。
3.2 通知機能の統合 Observability Cloud では、アラート通知をメールで送信するだけでなく、以下のようなサービスにアラート通知を送信するように設定することができます。
チームの事情に合わせて、通知ルールを作成してください。
使用量を管理する 個別のアクセストークンを作成し、制限を設けることで利用を制限する方法を紹介します 1. アクセストークン ホスト、コンテナ、カスタムメトリクス、高解像度メトリクスの使用量をコントロールしたい場合は、複数のアクセストークンを作成し、組織内の異なる部分に割り当てることができます。
左下の » を開いて、General Settings 配下の Settings → Access Tokens を選択します。
Access Tokens インターフェースでは、生成されたアクセストークンのリストで概要が表示されます。すべての組織では、最初のセットアップ時に Default のトークンが生成され、その他のトークンを追加・削除できるようになっています。
各トークンは一意であり、消費できるホスト、コンテナ、カスタムメトリクス、高解像度メトリクスの量に制限を設けることができます。
Usage Status 欄は、トークンが割り当てられた制限値を上回っているか下回っているかを素早く表示します。
2. 新しいトークンの作成 New Token Name Your Access Token ダイアログが表示されます。
ここでは、Ingest Token と API Token の両方のチェックボックスにチェックを入れてください。
OK Access Token のUIに戻ります。ここでは、既存のトークンの中に、あなたの新しいトークンが表示されているはずです。
名前を間違えたり、トークンを無効/有効にしたり、トークンの制限を設定したい場合は、トークンの制限の後ろにある省略記号(… )のメニューボタンをクリックして、トークンの管理メニューを開きます。
タイプミスがあった場合は、Rename Token オプションを使用して、トークンの名前を修正することができます。
3. トークンの無効化 トークンがメトリクスの送信に使用できないようにする必要がある場合は、トークンを無効にすることができます。
Disable ボタンを押すことで、トークンを無効化できます。これにより、トークンがSplunk Observability Cloudへのデータ送信に使用できなくなります。
以下のスクリーンショットのように、トークンの行がグレーになり、無効化されたことを示しています。
省略記号(… )のメニューボタンをクリックして、トークンの無効化と有効化を行ってください。
4. トークンの使用制限の管理 … メニューの Manage Token Limit をクリックして、使用量を制限してみましょう。
トークン制限管理ダイアログが表示されます。
このダイアログでは、カテゴリごとに制限を設定することができます。
先に進み、各使用指標に対して以下のように制限を指定してください。
リミット 値 ホストの制限 5 コンテナ制限 15 カスタムメトリクスの制限 20 高解像度メトリックの制限 0
また、上の表に示すように、ダイアログボックスに正しい数字が表示されていることを再確認してください。
トークンリミットは、5分間の使用量がリミットの90%を超えたときに、1人または複数の受信者に通知するアラートのトリガーとして使用されます。
受信者を指定するには、Add Recipient
トークンアラートの重要度は常に「Critical」です。
Update
トークンが使用カテゴリの上限に達したとき、または上限を超えたとき、その使用カテゴリの新しいメトリクスはObservability Cloudに保存されず、処理されません。これにより、チームが無制限にデータを送信することによる予期せぬコストが発生しないようになります。
90%に達する前にアラートを取得したい場合は、必要な値を使用して追加のディテクターを作成できます。これらのディテクターは、特定のアクセストークンを消費しているチームをターゲットにすることができ、管理者が関与する必要がある前に行動を起こすことができます。
これらの新しいアクセストークンを様々なチームに配布し、Observability Cloudに送信できる情報やデータの量をコントロールできるようになります。
これにより、Observability Cloudの使用量を調整することができ、過剰な使用を防ぐことができます。
おめでとうございます! これで、管理機能のモジュールは終わりです!