APMの概要
5分Splunk APM は、NoSample で End to End ですべてのアプリケーションやその依存性に関する可視性を提供し、モノリシックアプリ、マイクロサービスの両方で問題をより迅速に解決することに寄与します。チームは新しいアプリケーションをデプロイした際にもすぐに問題に気づくことができます。また、問題の発生源を絞り込み、切り分けることでトラブルシューティングに自信を持って取り組むことができます。バックエンドサービスがエンドユーザーとビジネスワークフローに与える影響を理解することを通じて、サービスのパフォーマンスを最適化することができます。
リアルタイムモニタリングとアラート: Splunk は、すぐに利用可能なサービスダッシュボードを提供します。急激な変化があると RED メトリクス(処理量、エラー、遅延)に基づいて自動的に問題を検出・アラートを発します。
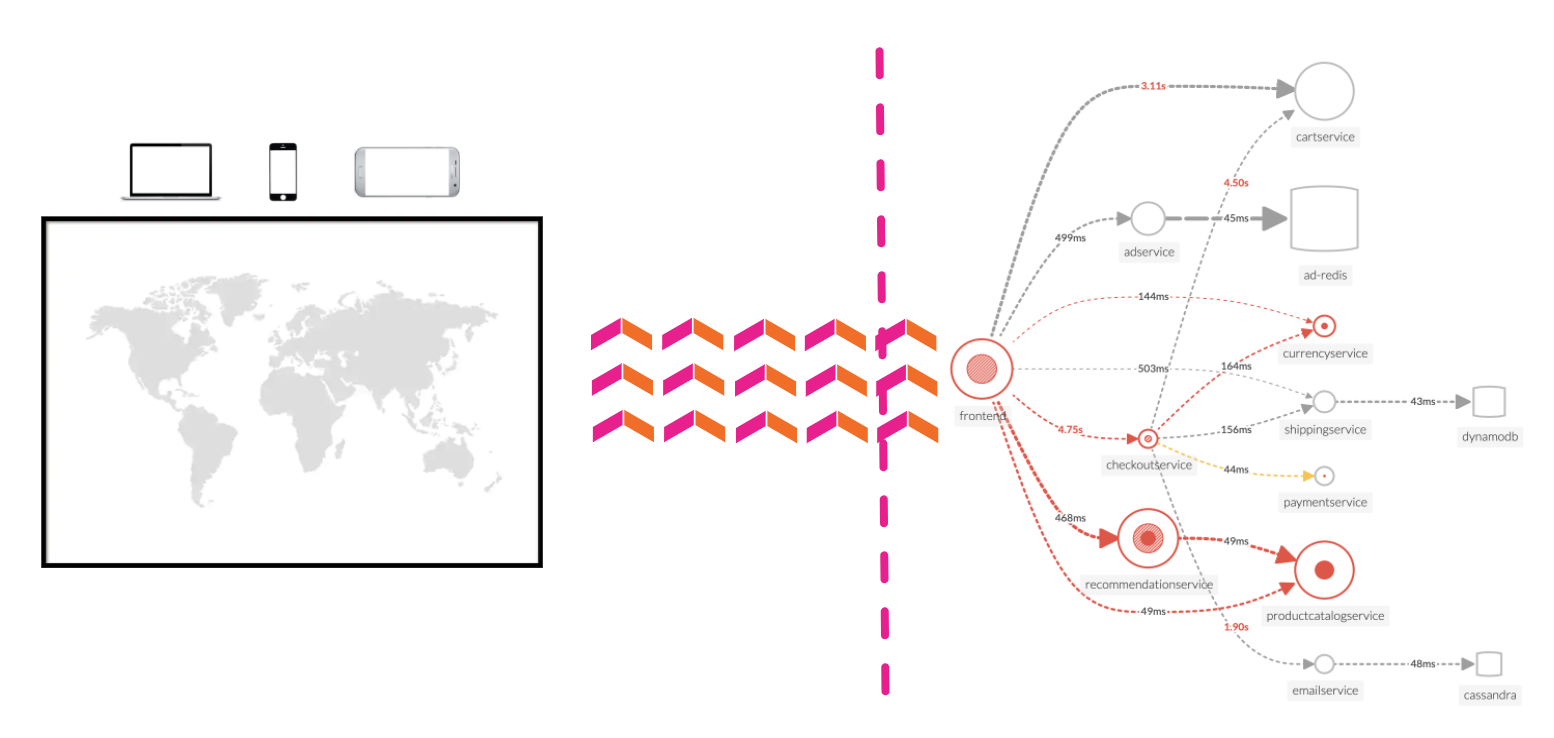
動的なテレメトリーマップ: モダンなプロダクション環境でのサービスパフォーマンスをリアルタイムで簡単に視覚化します。インフラストラクチャ、アプリケーション、エンドユーザー、およびすべての依存関係からサービスパフォーマンスをエンドツーエンドで可視化することで、新しい問題を迅速に絞り込み、より効果的にトラブルシューティングを行うことができるようになります。
インテリジェントなタグ付けと分析: ビジネス、インフラストラクチャ、アプリケーションからのすべてのタグを一か所で表示し、特定のタグに対して遅延やエラーに関する新しい傾向を簡単に比較・理解することができます。
AI を活用したトラブルシューティングによる最も影響の大きい問題を特定: 個々のダッシュボードを手間をかけて掘り下げる必要はありません。問題をより効率的に切り分けることができます。サービスと顧客に最も影響を与える異常とエラーの原因を自動的に特定します。
すべてのトランザクションに対する完全な分散トレーシング分析: クラウドネイティブ環境の問題をより効果的に特定します。Splunk の分散トレーシングは、インフラストラクチャ、ビジネスワークフロー、アプリケーションの特徴を踏まえた上で、バックエンドとフロントエンドからのすべてのトランザクションを視覚化し、その関係性を明らかにします。
フルスタックでの相関性の可視化: Splunk Observability 内で、APM はトレース、メトリクス、ログ、プロファイリングをすべてリンクさせ、スタック全体における各コンポーネントの依存関係やパフォーマンスを簡単に理解できるようにします。
データベースクエリパフォーマンスの監視: SQL および NoSQL データベースからの遅いクエリや高頻度に実行されるクエリが、サービス、エンドポイント、およびビジネスワークフローにどのような影響を与えるかを簡単に特定できるようにします。計装は必要ありません。