Deploy the LLM Application
10 minutesIn the final step of the workshop, we’ll deploy an application to our OpenShift cluster that uses the instruct and embeddings models that we deployed earlier using the NVIDIA NIM operator.
Application Overview
Like most applications that interact with LLMs, our application is written in Python. It also uses LangChain, which is an open-source orchestration framework that simplifies the development of applications powered by LLMs.
Our application starts by connecting to two LLMs that we’ll be using:
meta/llama-3.2-1b-instruct: used for responding to user promptsnvidia/llama-3.2-nv-embedqa-1b-v2: used to calculate embeddings
# connect to a LLM NIM at the specified endpoint, specifying a specific model
llm = ChatNVIDIA(base_url=INSTRUCT_MODEL_URL, model="meta/llama-3.2-1b-instruct")
# Initialize and connect to a NeMo Retriever Text Embedding NIM (nvidia/llama-3.2-nv-embedqa-1b-v2)
embeddings_model = NVIDIAEmbeddings(model="nvidia/llama-3.2-nv-embedqa-1b-v2",
base_url=EMBEDDINGS_MODEL_URL)The URL’s used for both LLMs are defined in the k8s-manifest.yaml file:
- name: INSTRUCT_MODEL_URL
value: "http://meta-llama-3-2-1b-instruct.nim-service:8000/v1"
- name: EMBEDDINGS_MODEL_URL
value: "http://llama-32-nv-embedqa-1b-v2.nim-service:8000/v1"The application then defines a prompt template that will be used in interactions with the LLM:
prompt = ChatPromptTemplate.from_messages([
("system",
"You are a helpful and friendly AI!"
"Your responses should be concise and no longer than two sentences."
"Do not hallucinate. Say you don't know if you don't have this information."
"Answer the question using only the context"
"\n\nQuestion: {question}\n\nContext: {context}"
),
("user", "{question}")
])Note how we’re explicitly instructing the LLM to just say it doesn’t know the answer if it doesn’t know, which helps minimize hallucinations. There’s also a placeholder for us to provide context that the LLM can use to answer the question.
The application uses Flask, and defines a single endpoint named /askquestion to
respond to questions from end users. To implement this endpoint, the application
connects to the Weaviate vector database, and then invokes a chain (using LangChain)
that takes the user’s question, converts it to an embedding, and then looks up similar
documents in the vector database. It then sends the user’s question to the LLM, along
with the related documents, and returns the LLM’s response.
# connect with the vector store that was populated earlier
vector_store = WeaviateVectorStore(
client=weaviate_client,
embedding=embeddings_model,
index_name="CustomDocs",
text_key="page_content"
)
chain = (
{
"context": vector_store.as_retriever(),
"question": RunnablePassthrough()
}
| prompt
| llm
| StrOutputParser()
)
response = chain.invoke(question)Instrument the Application with OpenTelemetry
To capture metrics, traces, and logs from our application, we’ve instrumented it with OpenTelemetry.
This required adding the following package to the requirements.txt file (which ultimately gets
installed with pip install):
splunk-opentelemetry==2.7.0We also added the following to the Dockerfile used to build the
container image for this application, to install additional OpenTelemetry
instrumentation packages:
# Add additional OpenTelemetry instrumentation packages
RUN opentelemetry-bootstrap --action=installThen we modified the ENTRYPOINT in the Dockerfile to call opentelemetry-instrument
when running the application:
ENTRYPOINT ["opentelemetry-instrument", "flask", "run", "-p", "8080", "--host", "0.0.0.0"]Finally, to enhance the traces and metrics collected with OpenTelemetry, we added a
package named OpenLIT to the requirements.txt file:
openlit==1.35.4OpenLIT supports LangChain, and adds additional context to traces at instrumentation time, such as the number of tokens used to process the request, and what the prompt and response were.
To initialize OpenLIT, we added the following to the application code:
import openlit
...
openlit.init(environment="llm-app")Deploy the LLM Application
Use the following command to deploy this application to the OpenShift cluster:
oc apply -f ./llm-app/k8s-manifest.yamlNote: to build a Docker image for this Python application, we executed the following commands:
cd workshop/cisco-ai-pods/llm-app docker build --platform linux/amd64 -t derekmitchell399/llm-app:1.0 . docker push derekmitchell399/llm-app:1.0
Test the LLM Application
Let’s ensure the application is working as expected.
Start a pod that has access to the curl command:
oc run --rm -it -n default curl --image=curlimages/curl:latest -- shThen run the following command to send a question to the LLM:
curl -X "POST" \
'http://llm-app.llm-app.svc.cluster.local:8080/askquestion' \
-H 'Accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"question": "How much memory does the NVIDIA H200 have?"
}'The NVIDIA H200 has 141GB of HBM3e memory, which is twice the capacity of the NVIDIA H100 Tensor Core GPU with 1.4X more memory bandwidth.View Trace Data in Splunk Observability Cloud
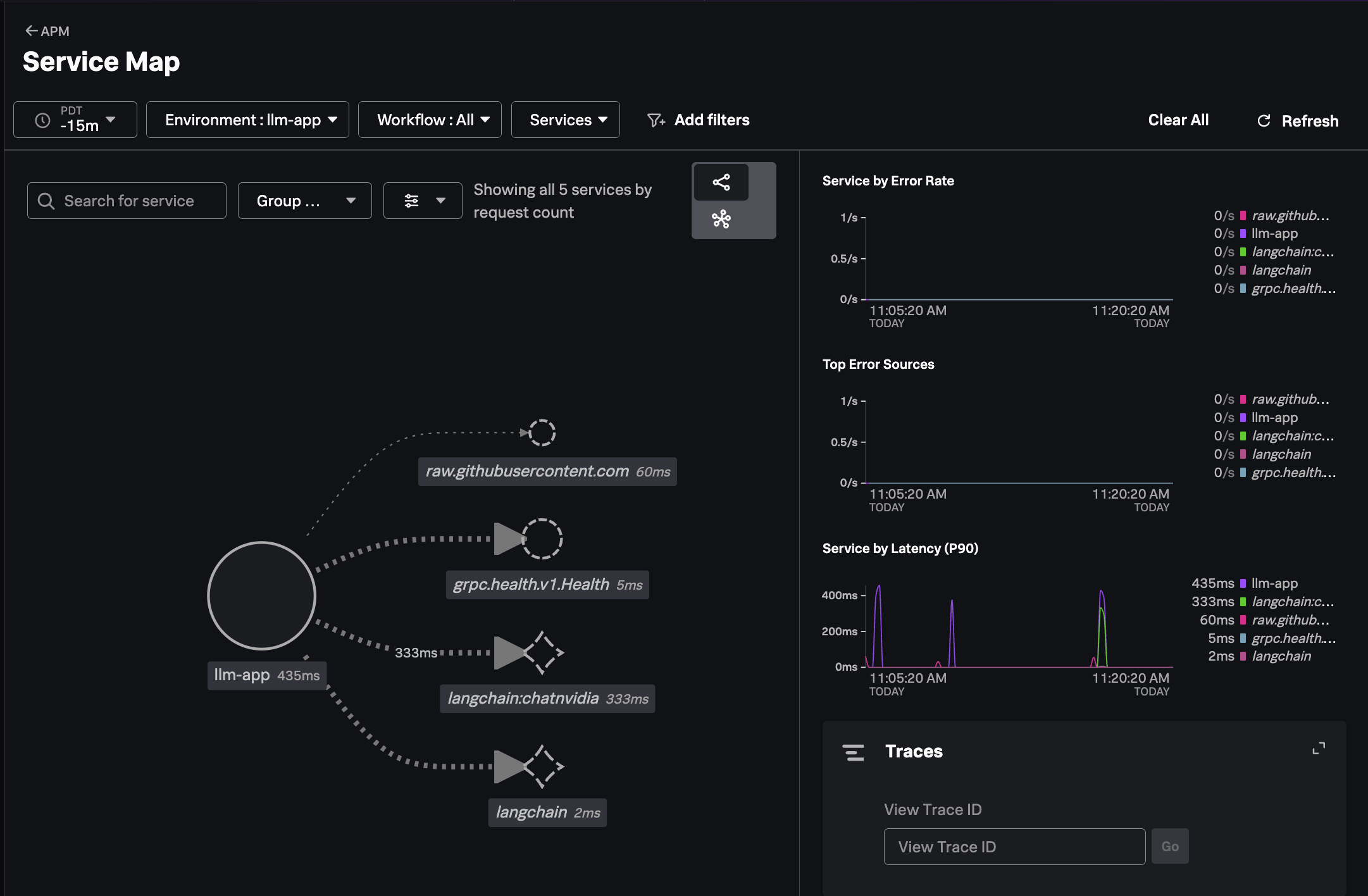
In Splunk Observability Cloud, navigate to APM and then select Service Map.
Ensure the llm-app environment is selected. You should see a service map
that looks like the following:
Click on Traces on the right-hand side menu. Then select one of the slower running
traces. It should look like the following example:
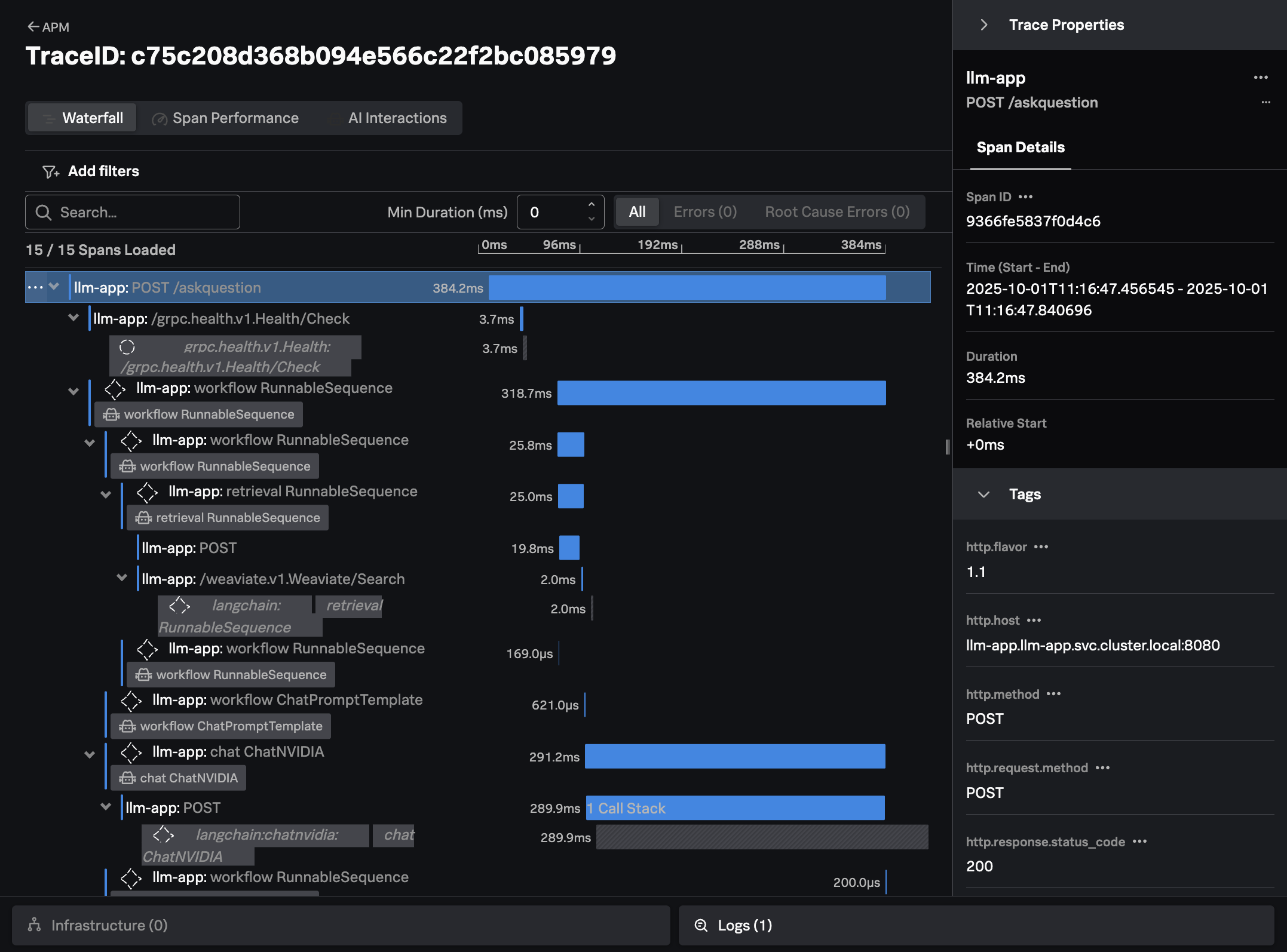
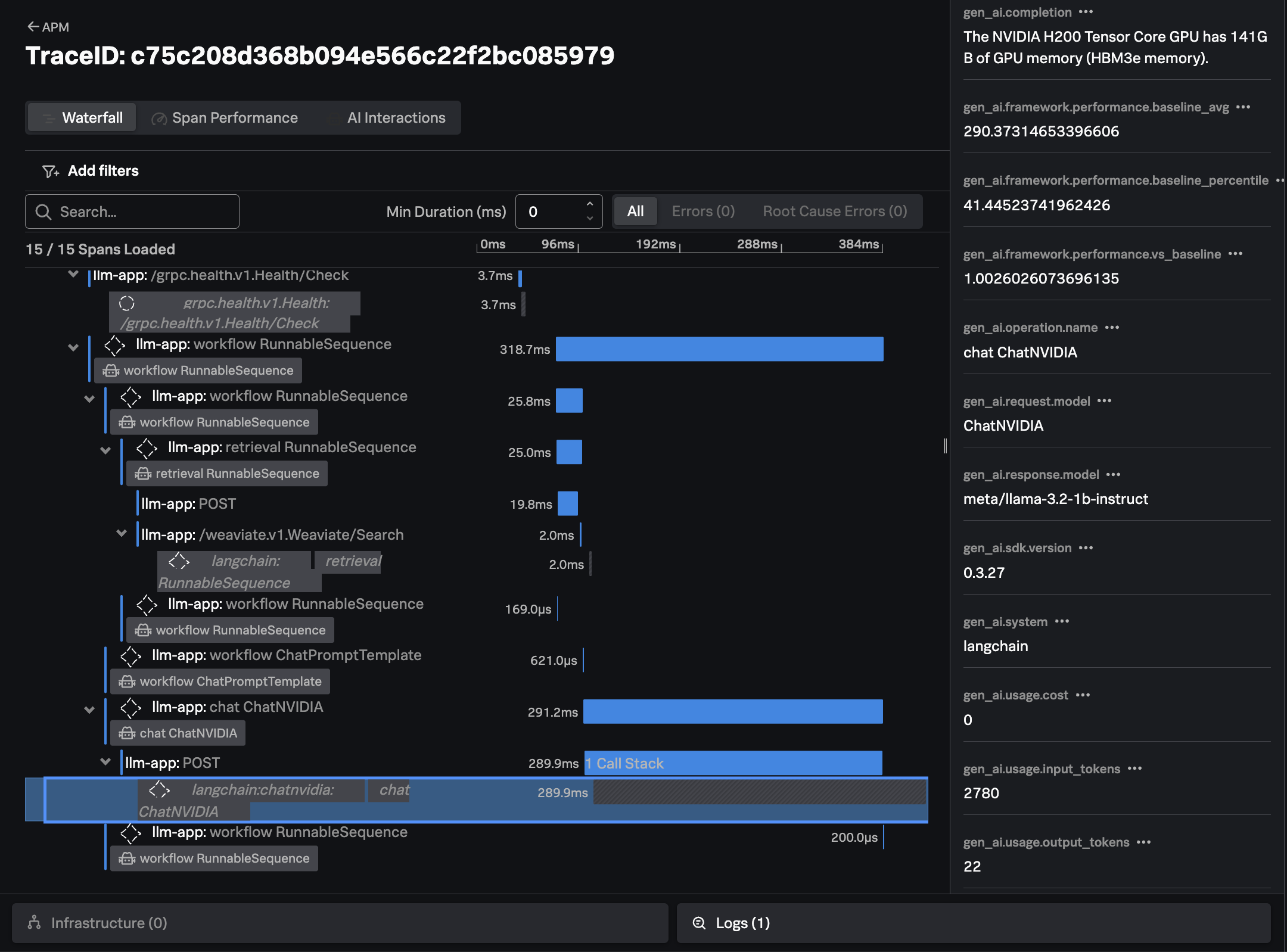
The trace shows all the interactions that our application executed to return an answer to the users question (i.e. “How much memory does the NVIDIA H200 have?”)
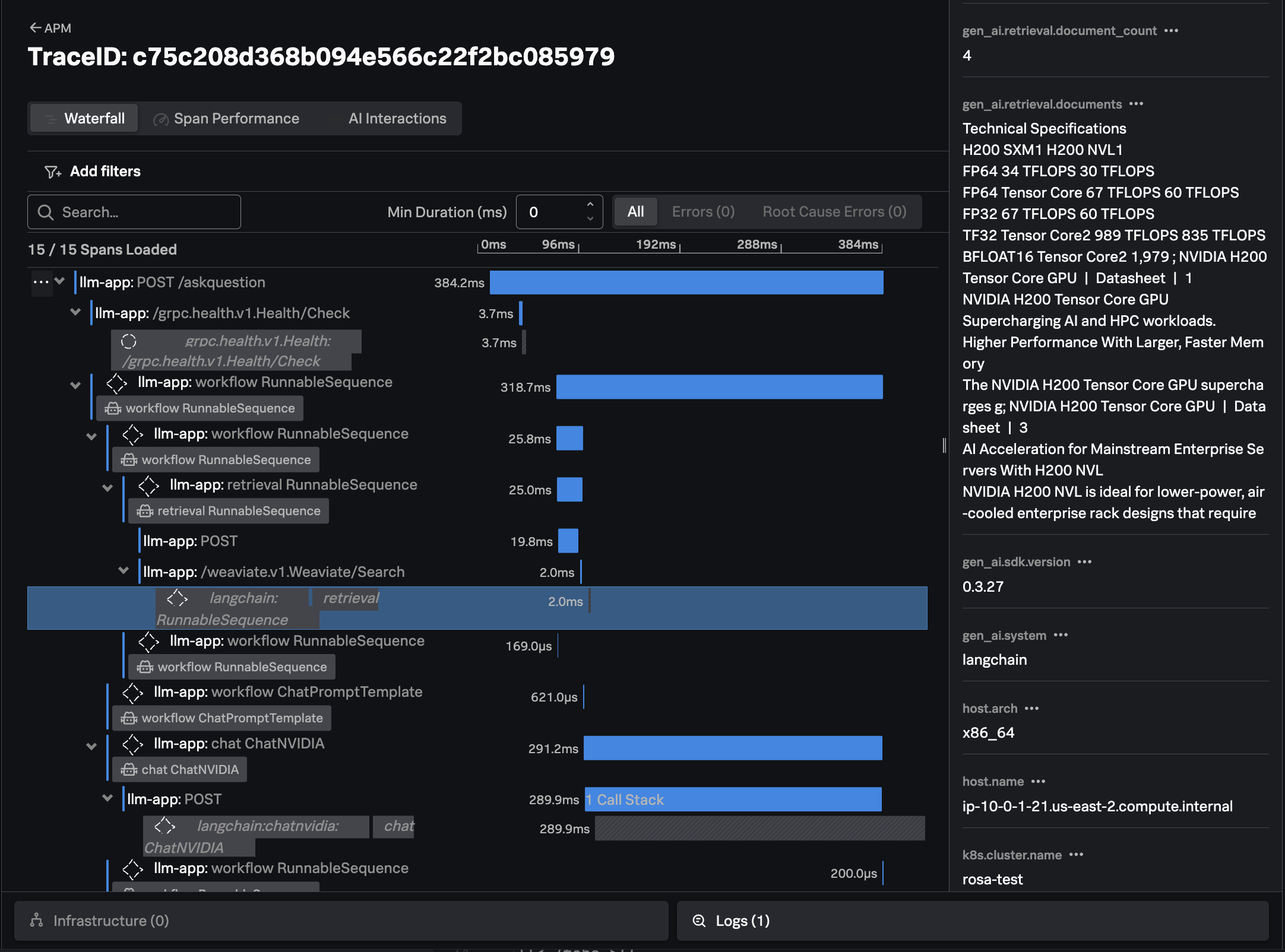
For example, we can see where our application performed a similarity search to look for documents related to the question at hand in the Weaviate vector database:
We can also see how the application created a prompt to send to the LLM, including the context that was retrieved from the vector database:
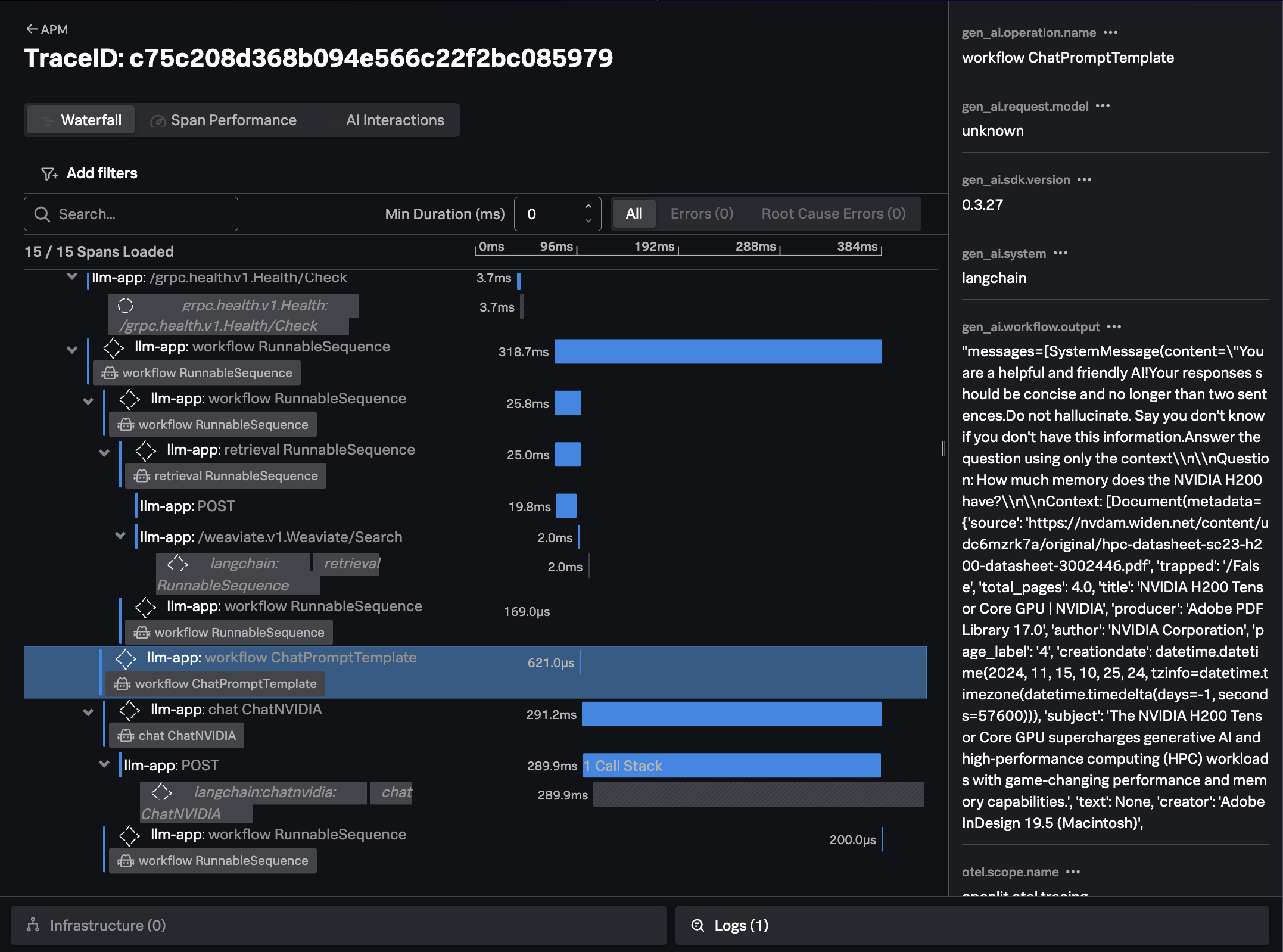
Finally, we can see the response from the LLM, the time it took, and the number of input and output tokens utilized: